








论文网址:MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
论文代码:GitHub - MedARC-AI/MindEyeV2
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3.2. Backbone, Diffusion Prior, & Submodules
2.3.4. Fine-tuning Stable Diffusion XL for unCLIP
2.4.1. fMRI-to-Image Reconstruction
1. 心得
(1)感觉是比较完美的设定,在七个人身上训一个人身上微调,比较实际应用
2. 论文逐段精读
2.1. Abstract
①Advantages: train 7 subjects with just one hours
2.2. Introduction
①Limitations of current works: on single sbject, or high computational cost
②Reconstruction ability during time:

only one hour is enough for MindEye2
2.3. MindEye2
①Pre-training strategy: training 7 subjects with 30~40 hours each and fine tune model by the 8-th subject
②Overall framework of MindEye2:
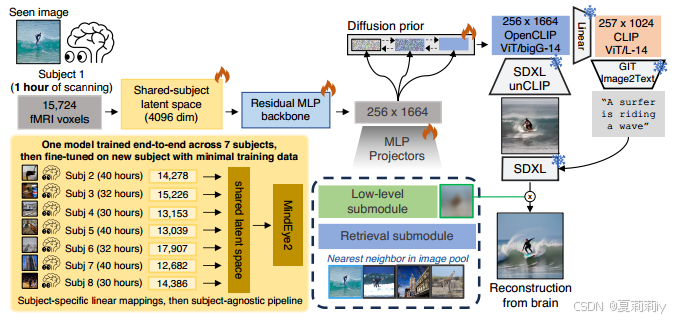
③Equipment: 8xA100 80Gb GPU for singal subject with 150 epoch and 24 batch size, multi-subjects pretraining has a batch size of 63
2.3.1. Shared-Subject Functional Alignment
①Each subject has different linear layer on single subject pretraining
2.3.2. Backbone, Diffusion Prior, & Submodules
①Output dimension of linear layers: 4096
②Linear projection: OpenCLIP ViT bigG/14, changing dimension to 256×1664
③Loss of diffusion prior, retrieval submodule, and low-level submodule:
(1)Diffusion prior
①Inspired by DALL-E 2, they fully trained on diffusion stage
(2)Petrieval submodule
①They designed a two stage loss to balance optimization. Employing MSE loss on diffusion prior and constractive loss after linear layer
②method: maxmize the cosine similarity for positive pairs while minimizing similarity for negative pairs
(3)Low-level submodule
①Low level loss for constrain reconstruction:
2.3.3. Image Captioning
①They use GIT to generate text
2.3.4. Fine-tuning Stable Diffusion XL for unCLIP
①Fine tune of SDXL: resolution of 256 × 256 pixels and a batch size of 8 with offsetnoise set to 0.04
1. SDXL 与 SDXL unCLIP
(1) SDXL(Stable Diffusion XL)
- 定位:Stability AI 推出的高性能文生图扩散模型,是 Stable Diffusion 系列的升级版。
- 核心改进:
- 更大的架构:使用两阶段模型(Base + Refiner),参数量显著增加(约6.6B)。
- 更高分辨率:支持直接生成 1024x1024 图像,无需后期超分。
- 多尺度训练:在低分辨率(256x256)和高分辨率(1024x1024)上联合训练,提升细节生成能力。
- 更强的文本编码器:集成 OpenCLIP ViT-bigG 和 CLIP ViT-L 双文本编码器,增强语义理解。
(2) SDXL unCLIP
- 定位:SDXL 的扩展版本,结合了 unCLIP 技术(源自 DALL·E 2 的图像生成范式)。
- 核心特点:
- 图像条件生成:支持以图像为输入(如图像编辑、修复、超分),而不仅是文本。
- 两阶段流程:
- CLIP 图像编码器:将输入图像编码为隐空间特征(类似 DALL·E 2 的 prior 模型)。
- 扩散解码器:基于编码特征生成新图像(SDXL 作为解码器 backbone)。
- 应用场景:图像到图像转换(如风格迁移、局部重绘)、多模态生成。
2. OpenCLIP ViT 与 CLIP ViT 的区别
两者均为 CLIP(Contrastive Language-Image Pretraining)模型的视觉编码器变体,但有以下关键差异:
特性 CLIP ViT (官方版) OpenCLIP ViT 开发团队 OpenAI LAION 社区(开源实现) 训练数据 私有数据集(4亿图文对) 公开数据集(如 LAION-5B,58亿图文对) 模型规模 ViT-L/14, ViT-B/32 等固定规模 支持更大模型(如 ViT-bigG,80层) 训练目标 对比损失(Image-Text Matching) 同 CLIP,但可能扩展多任务学习 性能表现 通用性强,但数据封闭 在部分任务上超越官方 CLIP(依赖数据) 可访问性 仅提供 API 或有限权重 完全开源,支持自定义训练 关键区别:
- 数据规模与多样性:OpenCLIP 使用 LAION-5B 等公开数据集,覆盖更广的领域(含多语言),而官方 CLIP 数据未公开。
- 模型灵活性:OpenCLIP 提供更大的 ViT 架构(如
ViT-bigG),适合需要高语义精度的任务(如 SDXL 的文本编码)。- 生态支持:OpenCLIP 集成到 Hugging Face、Stable Diffusion 等开源工具链中,便于扩展。
2.3.5. Model Inference
①Imperfect mapping:

so they skip the first 50% of denoising diffusion timesteps and diffuse
②Retrieval: compare the cosine similarity
2.4. Results
①Dataset: NSD(NSD所有人的介绍都一样就不再赘述了,大家没什么删改)
②Single-subject fine tune just comes from the first session (750 stimuli)
2.4.1. fMRI-to-Image Reconstruction
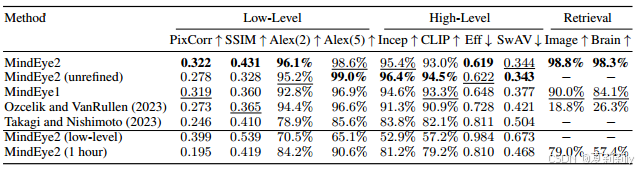
①Reconstruction performance:
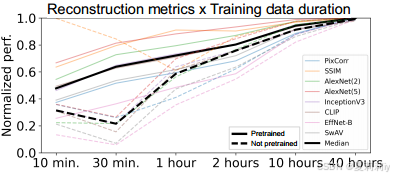
②Reconstruction performance at different training of signle subject:
③Reconstruction performance on just one hour:

2.4.2. Image Captioning
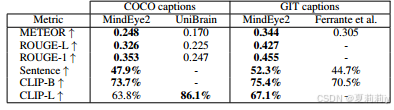
①Caption prediction performance:
2.4.3. Image/Brain Retrieval
①结果在重建那个表里面
2.4.4. Brain Correlation
①By GNet encoding model, they measured the importance of each visional region:
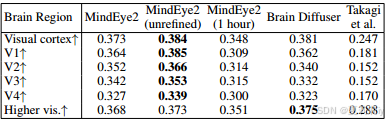
2.4.5. Ablations
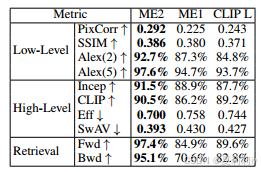
①They change MLP to linear and CLIP to OpenCLIP in MindEye2 compared with MindEye. There is the comparison table of the two model:
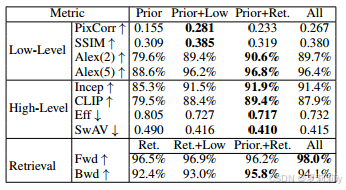
②Loss ablation:
2.5. Related Work
①Align function or anatomy of brain is not very feasible due to different distribution, so the authors only align mapping
2.6. Conclusion
~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









