







文章目录
一、前情提要
Open Set Learning
Open Set Learning是一种机器学习的问题设置,它主要关注在实际应用中,测试阶段可能会出现训练阶段未见过的类别的情况。
相比于传统的监督学习,Open Set Learning更接近现实世界的情况,因为现实世界中总是有可能出现新的、我们从未见过的类别。
原理
在传统的分类问题中,我们假设所有的类别都是已知的,并且在训练数据中已经出现过。
然而,在Open Set Learning中,我们允许在测试阶段出现新的、训练阶段未见过的类别。
为了解决Open Set Learning问题,我们需要设计一个模型,这个模型不仅可以对已知的类别进行分类,还能够识别出属于未知类别的样本。这通常需要模型具有一定的异常检测能力。
- 一种常见的解决Open Set Learning问题的方法是,将其转化为一个二元分类问题:已知类别 vs. 未知类别。在这个设置下,模型需要学习一个决策边界,能够区分已知类别的样本和未知类别的样本。
- 另一种方法是,使用一种叫做OpenMax的算法。OpenMax首先会计算一个样本属于各个已知类别的概率,然后它会使用这些概率来估计这个样本属于未知类别的概率。
举例
假设你正在开发一个图像分类模型,用于识别图像中的动物。
- 在你的训练数据中,只包含狗、猫和鸟的图像。
- 然后,在测试阶段,你收到了一个包含鱼的图像。
在这个例子中,"鱼"就是一个未知类别,因为模型在训练阶段未见过鱼。
如果你的模型是一个传统的分类模型,它可能会错误地将鱼的图像分类为狗、猫或鸟。但如果你的模型是一个Open Set Learning模型,它应该能够识别出鱼的图像属于一个未知类别。
总的来说,Open Set Learning是一个非常重要而且有挑战性的问题。
在设计Open Set Learning模型时,我们需要考虑到未知类别的存在,并设计相应的方法来处理这些未知类别。
二、CDFSOD简介
一般的深度学习方法都需要大量数据进行训练,而通常收集大量数据是困难的。
小样本目标检测(FSOD):希望使用在A数据集上学习到的先验知识来解决B数据集,且B任务的可用数据很少。其中A数据集和B数据集之间几乎没有域跨度。
跨域小样本目标检测(CDFSOD):希望使用在A数据集上学习到的先验知识来解决B数据集,且B数据集的可用数据很少。其中A数据集和B数据集之间有不同程度的域跨度。
什么是域:一个域通常表示一组共享某种属性或特征的数据点。每个域表示一类数据的一个特定方面,例如不同的风格、纹理、光照等因素。这些因素会影响数据的外观和感觉,但不一定与数据本身的类别有关。因此,一个域不能简单地看作是一个类,但它确实反映了数据在某些方面的变化。
例如:假设这张图片是一辆汽车,那么不同的域可能表示不同的照明条件、天气状况、拍摄角度等等。例如,一个域可能表示晴天下的汽车,另一个域可能表示阴雨天下的汽车,还有一个域可能表示从正面拍摄的汽车。这些域共同构成了汽车这一类数据的不同方面,但它们本身并不是汽车的类别。
三、论文研读
3.1 提出问题
现在CDFSOD存在的问题:
1)FSOD相对于CDFSOD更加成熟,那么对于FSOD的比较好的方法,如基于 Transformer 的开集检测器(例如 DE-ViT),是否适用于CDFSOD。
2)如果不适用,面对巨大的领域差距时如何增强模型。
3.2 作者提出的解决方法:
问题1的解决方法:
- 提出新的评价指标理解领域差距。
- 建立了一个名为 CD-FSOD 的数据集来评估目标检测方法来验证模型的效果,包含COCO(源数据集)、六个不同风格的数据集(目标数据集)。
数据集
我们的基准测试使用 COCO [29] 作为源训练集,并包含六个附加数据集,即 ArTaxOr [2]、Clipart1K [18]、DIOR [26]、DeepFish [36]、NEU-DET [37] 和 UODD [20] ,作为新颖的目标数据集。
六个目标数据集
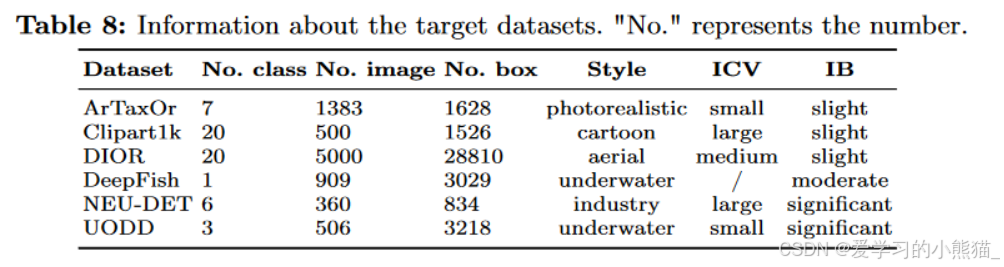
Style、ICV、IB指标
引入了风格、类间方差 (ICV) 和不可定义边界 (IB) 等指标来衡量领域差异。
模型学习目标:针对三个指标
作者方法的核心思路:
设计一种方法来解决小 ICV、大 IB 和跨域场景中风格变化的问题。
例如“cup”和“cat”,可以轻松转换为类似的域内概念,例如“bird”和“dog”。然而,跨领域的案例,例如“包含”和“补丁”等工业缺陷类型,对较小的 ICV、更重要的 IB 和不同的风格提出了挑战。
Style
常见的风格有写实、卡通、素描等。
inter-class variance(ICV)
ICV的理解:
PS:方差是描述数据离散程度的统计量,值越大代表数据的离散程度越大,即数据点分布越分散。 具体来说,方差是每个数据点与平均值的差的平方的平均数。 如果方差较大,则说明数据点之间的差异较大,数据分布较为分散。
ICV 用于衡量类别之间的差异。 ICV 值越高表示语义标签的识别越容易。像 COCO 这样的粗数据集通常具有较高的 ICV,而更细粒度的数据集则表现出较小的 ICV 值。
ICV评定
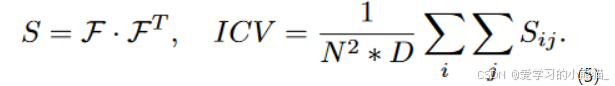
这个公式描述了一个计算指标(ICV)的方法,该方法用于衡量不同类别之间的距离。
首先,给定一个目标数据集DT,其中包含了N个不同的类别{c1, c2, …, cN},每个ci表示一类,如“cat”等。然后使用预训练的CLIP模型提取每类文本特征fi。将所有f1, f2, …, fN堆叠在一起构成文本特征矩阵F∈RN*D,D代表每个文本特征的维度。
接着,通过计算矩阵S = F·FT得到得分矩阵S,并根据公式(5)计算出ICV值。具体来说,对得分矩阵中的元素Si,j进行求和并除以N² * D来得到ICV值。
最后,为了将ICV值分为三个等级,需要计算下界ICVlow和上界ICVhigh。对于ICVlow,选择每个得分矩阵的最小值,并计算它们的平均值;对于ICVhigh,则考虑得分矩阵的最大值。这样就可以将ICV值划分为三类(small、lmedium、arge):低于ICVlow、介于ICVlow与ICVhigh之间以及高于ICVhigh。
indefinable boundaries(IB)
IB 反映了目标物体与其背景之间的混淆程度。更大的混乱给物体检测器带来了挑战。例如,在干净的背景下检测一个人相对简单,但识别珊瑚礁中的鱼则更具挑战性。
IB值评定
- 获取三个等级的概率p
我们设计了一份调查问卷来估计从背景中检测目标对象的难度,从而表明 IB 的水平。对于每个目标数据集,我们随机选择 10 张图像,总共创建 60 张图像。然后,我们让 100 名用户将 IB 级别分为三类:轻微(易于检测)、中等(有些挑战性)和显着(难以检测)。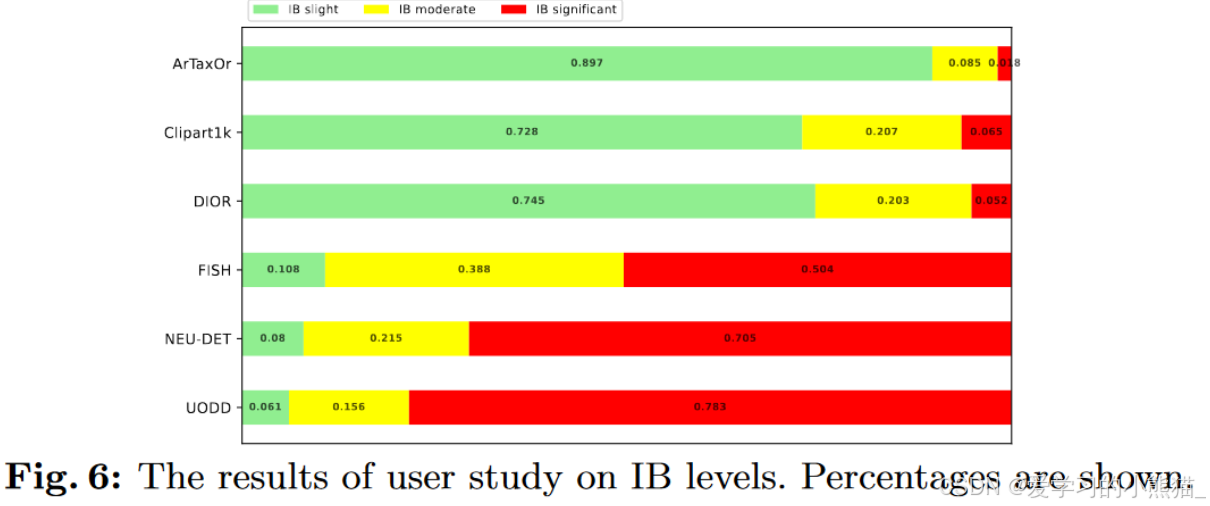
- 加权求和得到IB
由于IB反映了区分前景和背景的难度,因此我们将轻微wsli、中等wmod和显着wsig的权重分配为0、2和6。通过计算加权百分比,我们得到IB为:
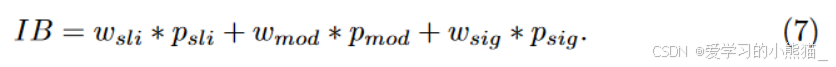

问题2 性能下降问题的解决方法
升级 vanilla DE-ViT 以提高开集检测器的性能。
3.3 创新点
- learnable instance features(LIF)
- instance reweighting module(IR)
- domain prompter(DP).
可学习的实例特征、实例重新加权模块和领域提示器。
任务设置:
N-way-K-shot设置:
具体来说,对于 CT 中的每个新类,提供 K 个标记实例,也称为支持集 S,其他未标记实例用作查询集 Q。形式上,我们有 |S| = N × K,N = |CT |。
评价指标:
ICV 水平分为大、中和小,IB 水平分为轻微、中等和显着。
3.4 模型框架:
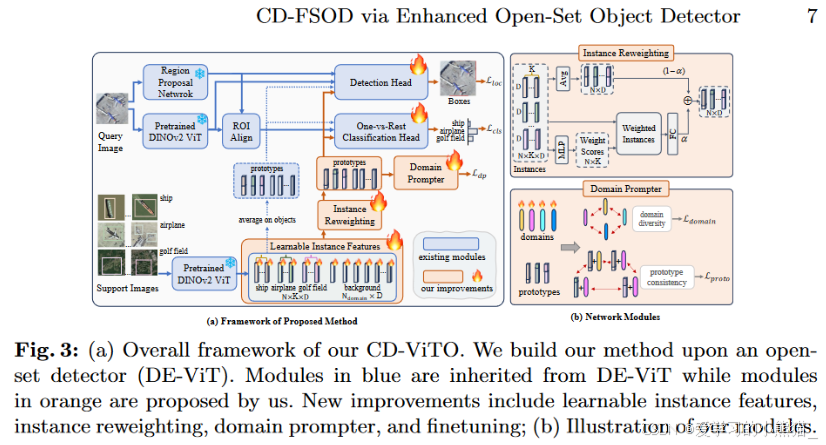
它主要包含DE-ViT的模块:预训练的 DINOv2 ViT、区域提议网络(MRPN)、ROI 对齐模块(MROI)、检测头(MDET)和一对一分类头(MCLS)。
工作流简介:
我们采用“预训练、微调和测试”流程。
(1) 开始,为了应对小 ICV 的负面影响,我们的目标是提高特征辨别力,使目标类别更具可区分性。这是通过我们的可学习实例特征来实现的,这些特征使用目标标签调整固定的初始实例特征,使特征与语义概念对齐。通过明确的类别作为监督,优化后的特征自然会比直接提取的特征表现出更大的分散性。
(2)接下来,我们引入实例重新加权模块,为实例分配不同的权重,优先考虑具有轻微IB的实例。通过强调形成类原型的高质量实例,我们减轻了 IB 带来的挑战。
(3)此外,为了提高模型跨领域的鲁棒性,我们提出了一个领域提示器来合成虚拟“领域”并确保原型特征在领域扰动下保持稳定。
为了鼓励每个合成域的独特性,提出了域多样性损失。同时,结合对比学习损失和分类损失,以在存在域扰动的情况下保持语义内容的一致性。
新提出的模块:
提出了新颖的可学习实例特征(MLIF)、实例重新加权(MLR)和领域提示器(MDP)来分别解决小ICV、显着IB和变化风格。
三个新模块分别处理三个新指标。
工作流程:
给定一个查询图像 q 和一组支持图像 S,DE-ViT 首先使用 DINOv2 提取实例特征 Fins = {F ob ins, F bg ins},其中 F ob ins 表示来自S 的目标特征和 F bg ins 表示背景实例的特征。然后我们首先利用 MLIF 使预先计算的 Fins 可学习,并通过执行解缠的检测任务来调整它们。
同时,查询图片通过MRPN 和 MROI 来生成区域建议 Rq、视觉特征 Fq 和 ROI 特征 Fqroi 。之后,MDET 将 Rq、Fq 和 Fpro 作为生成 Lloc 的本地化任务的输入。同时,MCLS根据Fqroi和Fpro执行分类任务,得到Lcls。网络通过 Lloc 和 Lcls 进行优化。
因此通过这种优化会将查询图片的实例特征与其相应的类别对齐,从而增加特征的可区分性并增大ICV。
一般来说,MLR 会为IB值为轻微的高质量的实例分配更高的值,这样,高质量的实例就可以为其类原型做出更多贡献。
MDP和Ldp用来解决style
MDP 的目标是引入此类域扰动并迫使我们的特征与不同域保持一致。为了保证引入域的多样性并约束域不会影响特征的语义,引入了额外的损失Ldp。 MDP 建立在对象原型 F ob pro 的基础上,Ldp 与 Lloc 和 Lcls 一起工作。
微调阶段,我们对最上面的两个模块进行微调,即 MDET 和 MCLS。

Learnable Instance Features (LIF)
MLIF定义了一个新的可学习特征矩阵Fleains,其大小与Fins相同,并使用Fins进行初始化。形式上,我们有 Fleains ∈ R(N ×K+Nbg)×D,Fleains = Fins。通过优化 Fleains 的值,我们获得了更符合目标语义的实例特征。
可学习实例特征的想法与视觉提示学习一致,其目的是修改输入以更好地适应下游任务。
我们通过将关键实例特征设置为可学习参数来优化它们。最重要的是,我们的模块可以作为使特征更具辨别力的解决方案,增大数据的ICV。
Instance Reweighting Module(IR)
我们的 MIR 建议重新加权实例,以实现高质量的对象实例,例如,具有轻微 IB 的对象对类原型贡献更多。
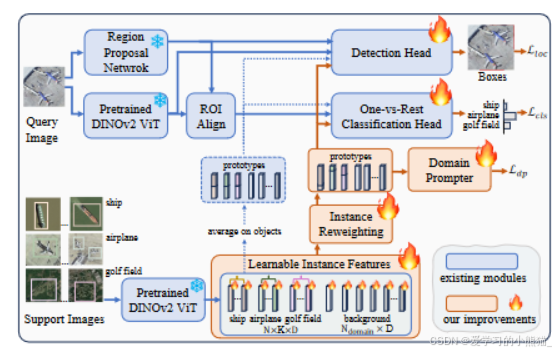
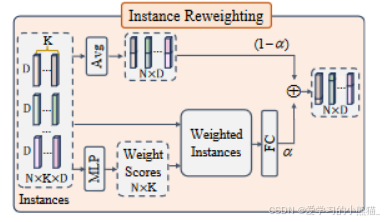
具体:
给定来自 MLIF 的可学习实例特征Fleains ,我们首先从Fleains 获得一部分对象实例特征,并将其表示为F0ins ∈ RN×KxD,这部分特征主要是来自物体实例,而不是背景实例。
MIR 有两条以残差方式连接的路径。更具体地,
下路径
将F 0 ins 送到MLP模块以获得加权分数,该加权分数进一步用于对初始F 0 ins 执行加权和,从而产生变形原型Fattins ∈ RN×D。
上路径
将F0 ins∈ RN×KxD沿着K维度求平均得到Favgins∈ RN×D。
消除不同Kshot对模型的影响,提高泛化能力。
最后将上下路径的到的特征原型加权求和得到F ob pro。
Domain Prompter(DP)
解决的问题:
1)综合多个具有多样性的“域”; 2)限制合成域的扰动特征不会导致语义偏移。
语义偏移(Semantic Drift)是指在模型训练过程中,由于噪声、干扰等因素的影响,导致模型学习到了错误的模式或者特征,使得模型的预测结果偏离了真实情况。
DP具体方法:
为了实现这些,我们的 MDP 首先引入几个可学习的向量FDomain ∈ RNdom×D 作为虚拟域,然后提出几个损失函数作为监督。
PS:原型(Prototype)通常指代某种物体或概念的代表性特征,而领域(Domain)则可以看作是特定环境或条件下的特征集合。
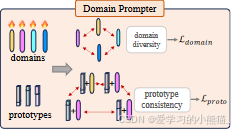
给定 FDomain 和Fobpro,我们首先提出域多样性损失 Ldomain 来迫使不同的域(例如 f di 和 f dj)彼此远离。其次,对于Fobpro中的原型fpi ,我们用从 FDomain 采样的两个不同的域 f dk 和 f dm 对其进行随机扰动,形成两个扰动原型fdkpi 、fdmpi 。扰动是通过添加特征来完成的,例如fdkpi = fpi + f dk 。域 f dm 也被添加到其他对象原型中,形成fdmpj ,其中 j = 1,…, N 。通过Lproto我们限制fdkpi和fdmpi 应该彼此接近,同时远离不同类原型生成的扰动原型。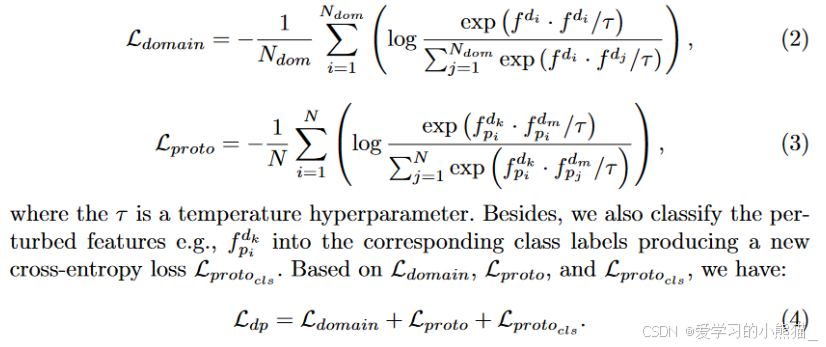 >“InfoNCE” 代表Normalized Categorical Cross-Entropy,是一种用于无监督学习和自监督学习的损失函数。InfoNCE损失函数通常用于训练对比学习模型,例如自编码器或者学习表示的模型,以学习数据中的结构和特征。InfoNCE损失函数的核心思想是通过最大化正确对应的样本与其他样本之间的相似性,来学习有意义的数据表示。它基于信息论的概念,通过最大化目标样本与其他样本之间的条件熵来实现这一目标。通过最小化负对数似然损失(Negative Log-Likelihood, NLL)来实现这一目标。
>“InfoNCE” 代表Normalized Categorical Cross-Entropy,是一种用于无监督学习和自监督学习的损失函数。InfoNCE损失函数通常用于训练对比学习模型,例如自编码器或者学习表示的模型,以学习数据中的结构和特征。InfoNCE损失函数的核心思想是通过最大化正确对应的样本与其他样本之间的相似性,来学习有意义的数据表示。它基于信息论的概念,通过最大化目标样本与其他样本之间的条件熵来实现这一目标。通过最小化负对数似然损失(Negative Log-Likelihood, NLL)来实现这一目标。
温度超参数(Temperature Hyperparameter)通常用于控制概率分布的平滑程度。在softmax函数中,温度参数τ常用于调节输出的概率分布。随着温度参数τ的增大,softmax函数的输出分布会变得更加平滑,各个类别的概率值会更加接近,而随着τ的减小,softmax函数的输出分布会变得更尖锐,各个类别的概率值会更加集中。
在本文中,温度超参数τ用于控制InfoNCE loss的计算。InfoNCE loss是一种对比损失函数,用于衡量样本之间的相似性。通过调整τ的值,可以改变InfoNCE loss的敏感性,进而影响模型的学习速度和收敛行为。通常,较低的τ值会导致更大的梯度更新,加快模型的训练速度,但可能会导致过拟合;较高的τ值则会使梯度更新变小,降低训练速度,但能减少过拟合的风险。因此,选择合适的τ值对于优化模型的性能至关重要。
简而言之,温度参数τ的增大降低了模型对不同类别的区分度,而减小提高了模型对不同类别的区分度。因此,选择合适的τ值对于优化模型的性能至关重要。### 实验
3.5 实验
shot:1、5、10
就我们的 CD-ViTO 而言,采用在 COCO 上预训练的基本 DE-ViT 模型,然后使用等式 1 中的损失在新类的支持图像 S 上调整 MDET 、 MCLS 、 MLIF 、 MIR 和 MDP 。 1. 微调细节,例如超参数、优化器、学习率和时期将附在补充材料中。
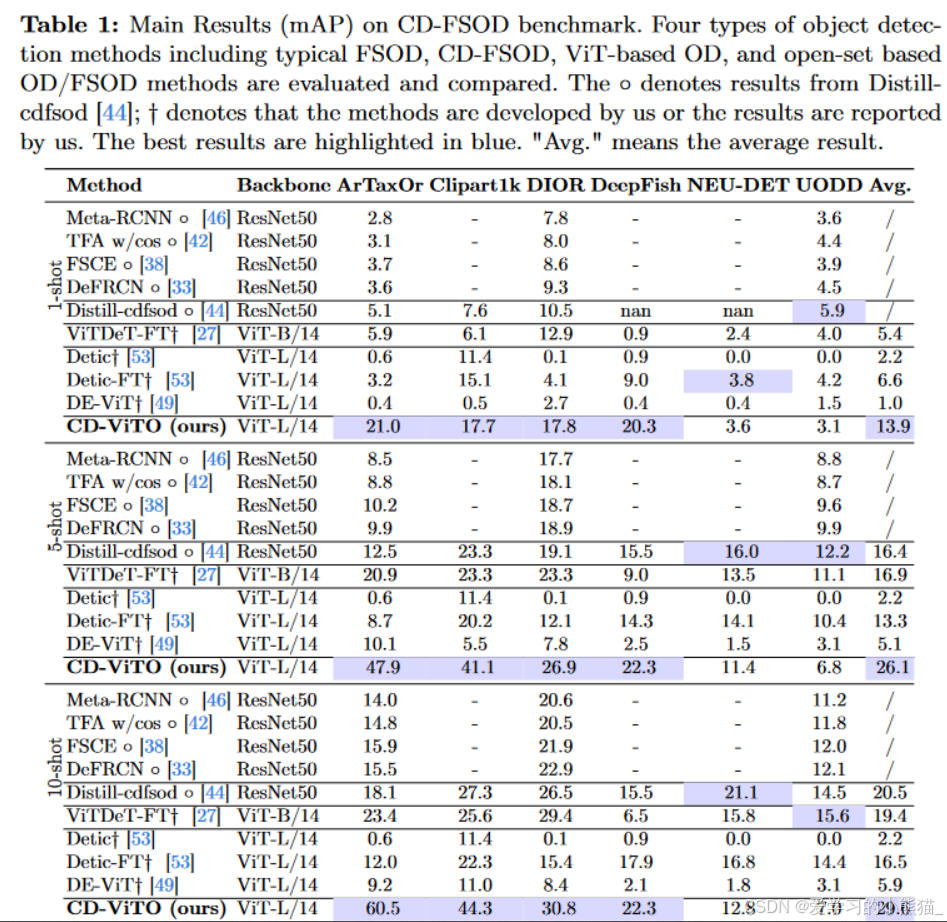
对比实验
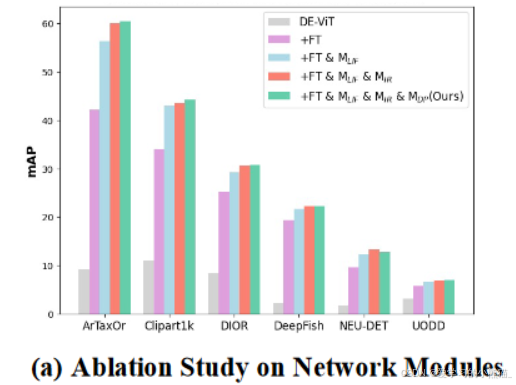
消融实验
LIF 模块验证
我们计算类原型的成对余弦距离,并将 MLIF 生成的可学习类原型的结果与初始固定的结果进行比较。 5 次 NEU-DET的结果如图 4(b)所示,我们观察到类之间的余弦距离持续下降,即特征之间相似度减小,差异性增大。这表明我们的MLIF扩大了ICV。
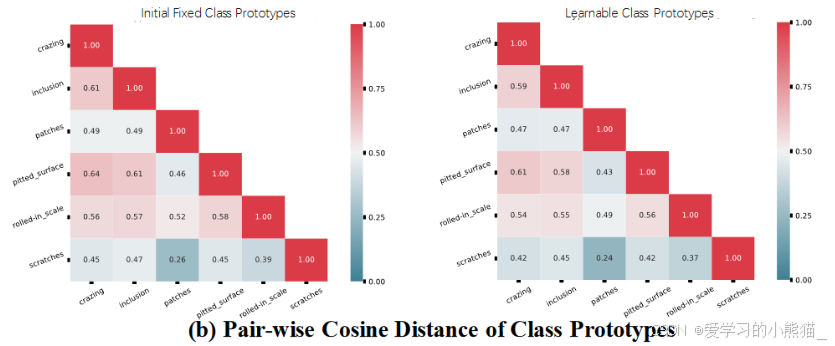
显示了类原型之间的余弦距离。余弦距离是一种度量两个向量方向差异的方法,它在机器学习和计算机视觉中经常用来比较图像特征。在这个图表中,类原型之间的余弦距离展示了不同类别的原型之间的相似性或差异性。
左边的柱状图表示固定类原型之间的余弦距离,右边的柱状图表示可学习类原型之间的余弦距离。可以看到,可学习类原型之间的余弦距离明显大于固定类原型之间的余弦距离。这说明可学习类原型之间的差异性更大,这可能是因为在训练过程中,模型逐渐学会了区分不同类别的特征,使得类原型之间的差异性增强。
IR模块的验证
实例重新加权模块 MIR 旨在为具有较小IB值的实例分配更高的权重。因此,我们可视化了按权重从高到低排序的几个加权实例。图 4© 展示了三个数据集的 5 个镜头结果。结果表明,边界相对清晰的实例得分较高;相反,那些边界混乱的人得分较低。
DP的验证
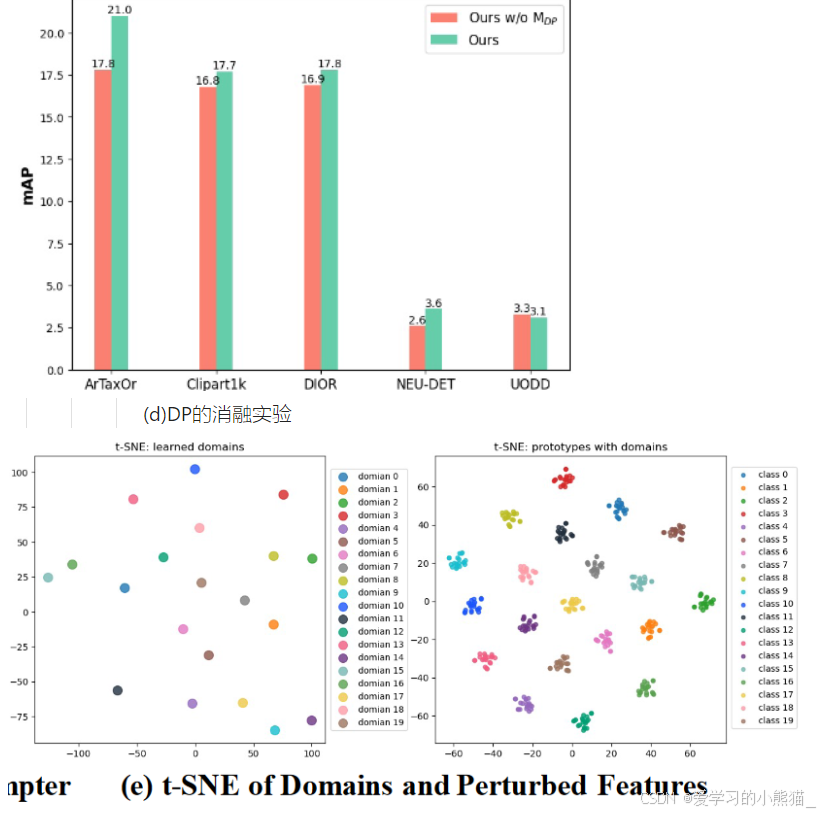
MDP 旨在生成虚拟域作为有用的扰动。MDP 对于低shot很好。图 4(d) 中提供了1-shot 比较结果,表明我们的 MDP 显着改善了除 UODD 之外的目标上的结果。
在图 4(e) 中,将Clipart1K 上的 1-shot 结果是可视化的。我们通过向类原型添加域来提供学习域的 t-SNE 特征和扰动特征。
图 4(e) 中的点在左边表示学习到的域(domains),而在右边表示带有域的类原型(class prototypes)。这是因为左边的点代表了模型学习到的不同数据分布的变化因子,也就是各种不同的域。这些域可以看作是在不同条件下数据的抽象表示,比如不同的风格、纹理、光照等因素。
右边的点则表示带有域的类原型,这些类原型是模型学习到的每个类别的代表性数据点。这些类原型在加入域信息后,可以更好地反映出数据在不同条件下的变化。通过这种方式,模型可以更好地适应不同条件下的数据分布,从而提高其泛化能力。
左右两侧的点在 t-SNE 投影下呈现不同的分布,左边的点表示不同的域,右边的点表示带有域的类原型。这种布局有助于我们理解模型如何学习和利用域信息来增强模型的表现。
结果表明:1)学习领域表现出多样性; 2)向类原型添加域会生成新数据,但会保留语义概念。最后,我们将这些可学习的扰动称为“领域”提示器而不是“风格”提示器,因为在没有明确风格信息的情况下学习有意义的风格具有挑战性。 “域”一词广泛用于涵盖可能引起数据分布变化的因素,包括风格。
end~
本人水平有限,有错的地方还请批评指正。
什么是精神内耗?
简单地说,就是心理戏太多,自己消耗自己。
所谓:
言未出,结局已演千百遍;
身未动,心中已过万重山;
行未果,假想灾难愁不展;
事已闭,过往仍在脑中演。


















 2578
2578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











