






Abstract
Few-shot object detection (FSOD) aims to transfer knowledge from base classes to novel classes, which receives widespread attention recently. The performance of current techniques is, however, limited by the poor classification ability and the improper features in the detection head. To circumvent this issue, we propose a Multi-level Feature Enhancement (MFE) model to improve the feature for classification from three different perspectives, including the spatial level, the task level and the regularization level. First, we revise the classifier's input feature at the spatial level by using information from the regression head. Secondly, we separate the RoI-Align feature into two different feature distributions in order to improve features at the task level. Finally, taking into account the overfitting problem in FSOD, we design a simple but efficient regularization enhancement module to sample features into various distributions and enhance the regularization ability of classification. Extensive experiments show that our method achieves competitive results on PASCAL VOC datasets, and exceeds current state-of-the-art methods in all shot settings on challenging MS-COCO datasets.
少样本目标检测(FSOD)旨在将基础类别的知识转移到新颖类别中,最近受到了广泛关注。然而,当前技术的性能受到分类能力差和检测头部特征不恰当的限制。为了解决这个问题,我们提出了一个多层次特征增强(MFE)模型,从三个不同的角度改进分类特征,包括空间级别、任务级别和正则化级别。首先,我们通过使用回归头部的信息修正分类器在空间级别上的输入特征。其次,我们将RoI-Align特征分成两个不同的特征分布,以提高任务级别上的特征。最后,考虑到FSOD中的过拟合问题,我们设计了一个简单但有效的正则化增强模块,将特征采样到不同的分布中,并增强分类的正则化能力。大量实验表明,我们的方法在PASCAL VOC数据集上取得了竞争性结果,并在具有挑战性的MS-COCO数据集的所有少样本设置上超过了当前的最先进方法。
1.介绍
One widely held belief has emerged with the development of few-shot object detection, which is that the classifier's performance is the main bottleneck for this task. Some works have been proposed recently to improve the classification performance in FSOD[25, 13]. Despite focusing on addressing the classification problem for few-shot object detection, these new methods ignore that the input of the classifier was based on the original proposal features. The following issues could arise if original features are used:
随着少样本目标检测的发展,人们普遍认为分类器的性能是这项任务的主要瓶颈。最近一些工作提出了一些方法来提高FSOD中的分类性能[25, 13]。尽管专注于解决少样本目标检测中的分类问题,但这些新方法忽视了分类器的输入是基于原始提案特征的事实。如果使用原始特征,则可能出现以下问题:
Spatial shift. In the widely used Faster R-CNN architecture, the regressor and classifier use the same feature from the stem representation of the RoI-Align feature to perform regression and classification simultaneously. In the general object detection task, there are many annotated examples used in the training stage and the model is robust for the diversity between the proposal feature and accurate bounding box feature. However, low-quality proposal features limit classification performance in few-shot settings. The classifier's performance is irreparably harmed by the discrepancy between accurate bounding box features and proposal features. As shown in Figure 1a, the features used in classification are inaccurate, which causes poorer classifier performance in the few-shot setting.
空间偏移。在广泛使用的Faster R-CNN架构中,回归器和分类器使用来自RoI-Align特征的相同特征来同时执行回归和分类。在一般的物体检测任务中,训练阶段使用了许多标注示例,模型对于提案特征和精确边界框特征之间的多样性具有鲁棒性。然而,在少样本设置中,低质量的提案特征限制了分类性能。分类器的性能因精确边界框特征和提案特征之间的差异而受到不可挽回的损害。如图1a所示,用于分类的特征是不准确的,这导致了少样本设置中较差的分类器性能。

表示空间移位问题。绿色边界框:对象的正确坐标。红色边界框:RPN生成的对象坐标。黄色边界框:基于提案的 R-CNN 生成的坐标
Task conflict. The goals of classification and regression are not the same because they are two distinct tasks. Regressor focuses on locating objects meanwhile classifier tries to distinguish different categories. Therefore, Faster R-CNN architecture suffers from the conflicting objectives of classification and regression during training, and features generated by the RoI-Align operation cannot consider this conflict. The ability of the model to locate and classify simultaneously in object detection is generally enabled by sufficient training data, which mitigates this phenomenon. However, in the few-shot setting, the struggle between location and classification is more intense.
任务冲突。分类和回归的目标不同,因为它们是两个独立的任务。回归器专注于定位对象,而分类器则试图区分不同的类别。因此,Faster R-CNN架构在训练过程中遭受分类和回归目标冲突的影响,而由RoI-Align操作生成的特征无法考虑这种冲突。在目标检测中,模型同时进行定位和分类的能力通常依赖于充足的训练数据,这可以减轻这种现象。然而,在少样本设置中,定位和分类之间的冲突更加激烈。
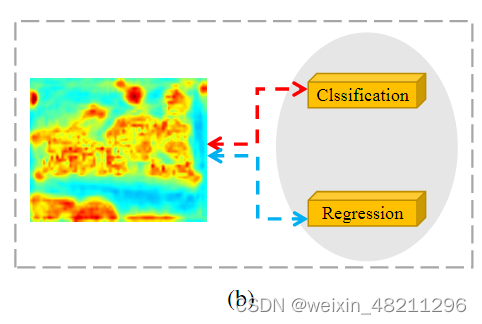
表示任务级问题。相同的提议特征很难同时表示分类和回归任务,反向传播阶段任务之间可能存在冲突。
Severely overfitting. Few-shot object detection expects to learn all representations of a class with very little training data, which is difficult for general classifiers. Particularly in the case of few-shot settings, it is very simple for the model to overfit the training data, and it is challenging to discriminate objects in the feature space that are far from the training data. As a result, the model has trouble differentiating between classes like horse and zebra which are similar.
严重的过拟合。少样本目标检测期望用极少的训练数据学习一个类别的所有表示,这对于一般的分类器来说是很困难的。尤其在少样本设置的情况下,模型很容易对训练数据产生过拟合,并且在特征空间中区分远离训练数据的对象非常具有挑战性。结果,模型在区分类似的类别(如马和斑马)时会遇到困难。
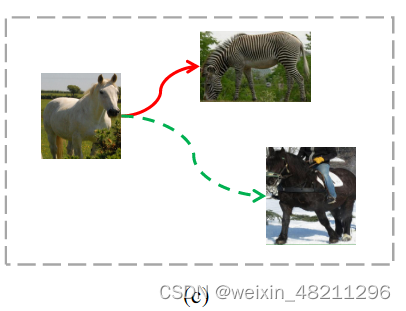
表示过拟合问题。在few-shot设置中,很难精确定马的特征分布,因此马被错误地识别为斑马。
Severely overfitting. Few-shot object detection expects to learn all representations of a class with very little training data, which is difficult for general classifiers. Particularly in the case of few-shot settings, it is very simple for the model to overfit the training data, and it is challenging to discriminate objects in the feature space that are far from the training data. As a result, the model has trouble differentiating between classes like horse and zebra which are similar.
In this paper, we focus on improving the quality of classification features in few-shot object detection model. With few-shot setting, it is difficult for features to be greatly enhanced by a single level, so we propose a Multi-Level Feature Enhancement (MFE) method to enhance classification features on three specific levels, including spatiallevel, task-level, and regularization-level, in light of the phenomenon we described above. By altering the spatial locations of the classification features, the spatial-level module enhances the features of classification. By focusing on different channels of features, the task-level module decouples the tasks of localization and classification. The regularization-level module improves the classifier's regularization capabilities, which resolves the issue of inconsistency between training and inference in few-shot setting. Through the fusion of three feature enhancement modules, MFE enhances the original proposal features into features adapted for classification. The experimental results show that MFE greatly enhances the performance of the twostage few-shot detector.
在本文中,我们专注于改善少样本目标检测模型中分类特征的质量。在少样本设置下,很难通过单一级别显著增强特征,因此我们提出了一种多级特征增强(MFE)方法,针对我们上面描述的现象,在空间级别、任务级别和正则化级别上增强分类特征。通过改变分类特征的空间位置,空间级别模块增强分类特征。通过专注于特征的不同通道,任务级别模块解耦了定位和分类的任务。正则化级别模块提高了分类器的正则化能力,解决了少样本设置下训练和推断之间的不一致问题。通过三个特征增强模块的融合,MFE将原始的提议特征增强为适用于分类的特征。实验结果表明,MFE极大地提高了两阶段少样本检测器的性能。
The main contributions of our approaches are three-fold:
• We point out the existing problems in few-shot object detection in the view of imperfect features for the classifier, which are not crucial in general object detection.
• We propose the Multi-level Feature Enhancement(MFE) to improve detection features from spatial, task, and regularization levels.
• Our approach achieves competitive results on COCO and PASCAL VOC benchmark, which demonstrate the effectiveness of our framework.
我们的方法主要有以下三个贡献:
- 我们指出了少样本目标检测中分类器特征不完善的问题,这在一般目标检测中并不关键。
- 我们提出了多级特征增强(MFE)方法,从空间、任务和正则化三个层次提升检测特征。
- 我们的方法在 COCO 和 PASCAL VOC 基准上取得了有竞争力的结果,证明了我们框架的有效性
2 Related Work
Another stream is the transfer learning based approach. Chen et al.[1] involved this problem in a transfer learning way by combining SSD[16] and Faster R-CNN fashion [22]. Wang et al. [29] pointed out that fine-tune only the last layer of the existing detector is crucial to the FSOD task. Wu et al. [32] proposed a multi-scale positive sample refinement to enrich object scales. Recently, more and more works focus on improving classification performance. Sun et al.[25] applied the contrasted loss to distinguish similar class meanwhile Li et al.[13] leveraged a class margin loss technique to balance inter and intra class margins. Qiao et al.[20] captured the conflicts between RPN and RCNN module and introduced a decouple module to solve this problem.
另一类方法是基于迁移学习的方法。Chen 等人 [1] 通过结合 SSD [16] 和 Faster R-CNN [22] 的方式,以迁移学习的方式解决了这个问题。Wang 等人 [29] 指出,仅微调现有检测器的最后一层对于少样本目标检测任务至关重要。Wu 等人 [32] 提出了多尺度正样本细化方法以丰富目标尺度。最近,越来越多的工作集中在提高分类性能上。Sun 等人 [25] 应用了对比损失来区分相似的类别,同时 Li 等人 [13] 利用了类边距损失技术来平衡类间和类内边距。Qiao 等人 [20] 发现了 RPN 和 RCNN 模块之间的冲突,并引入了解耦模块来解决这个问题。
3. Methods
3.1. Problem Definition
We first give a formal few-shot object detection definition followed by Kang[12]. Given two sets of data Cbaseand Cnovel, Cbase denotes the abundant annotated instances in base classes, and Cnovel denotes the few annotated instances in novel classes. The intersection categories between Cbase and Cnovel are ∅. We aim to obtain a fewshot object detection model by sufficiently exploiting generalized knowledge from base classes and transferring them into novel classes. Usually, there are only k instances inCnovel per class, mentioned as k-shot object detection.
首先,我们遵循 Kang [12] 给出了正式的少样本目标检测定义。给定两个数据集 Cbase 和 Cnovel,Cbase 表示基础类中大量标注的实例,Cnovel 表示新类中少量标注的实例。Cbase 和 Cnovel 之间的类别交集为 ∅。我们的目标是通过充分利用基础类中的通用知识并将其转移到新类中,来获得一个少样本目标检测模型。通常,在每个类的 Cnovel 中只有 k 个实例,这被称为 k-shot 目标检测。
We mainly employ transfer learning approaches for our model training and testing, the same as previous transfer learning based approaches[29, 20]. Model training can be summarized as two stages: in the first stage, our model is trained on base classes and learns generalized knowledge such as foreground bounding box features and basic information to distinguish objects. In the second stage, also called the novel training stage, to utilize the knowledge learning from the first stage, we further fine-tune this model based on novel categories. In the testing stage, our model aims to detect objects belonging to novel categories.
我们主要采用迁移学习方法进行模型训练和测试,这与之前的基于迁移学习的方法相同[29, 20]。模型训练可以总结为两个阶段:在第一阶段,我们的模型在基础类上进行训练,学习通用知识,如前景边界框特征和区分物体的基本信息。在第二阶段,也称为新类训练阶段,为了利用第一阶段学习的知识,我们进一步在新类的基础上微调这个模型。在测试阶段,我们的模型旨在检测属于新类的物体。
3.2. Spatial-level Enhancement
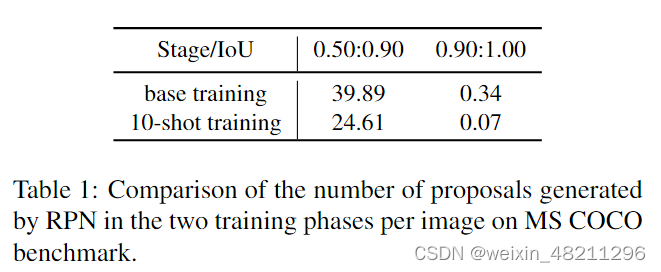
For few-shot object detection, we observe that there is a general problem: The proposal features utilized in classification are not reliable, as illustrated in Figure 1a, which is the major cause for inferior classifier results in the fewshot setting. To demonstrate this opinion, we counted the number of proposals generated by RPN in the two training phases of FSOD in Table 1. Although more low-quality positive sample proposals were generated in the base training phase than in the 10-shot training phase, the difference was not significant. However, for high-quality proposals that have IoU greater than 0.9 with gt, there is a nearly fivefold difference in the number of proposals generated in the two phases. As a result, compared to the base training stage, the high-quality proposals are much less in 10-shot training stage. The low-quality proposal features damage the performance of the classifier in the detection head irreversibly.
对于少样本目标检测,我们观察到一个普遍问题:用于分类的提案特征不可靠,如图1a所示,这是少样本设置中分类器效果较差的主要原因。为了证明这一观点,我们统计了表1中RPN在FSOD两个训练阶段生成的提案数量。虽然在基础训练阶段生成的低质量正样本提案比在10次训练阶段多,但差异并不显著。然而,对于与gt的IoU大于0.9的高质量提案,在两个阶段生成的提案数量存在近五倍的差异。因此,与基础训练阶段相比,10次训练阶段的高质量提案要少得多。低质量的提案特征不可逆地损害了检测头中分类器的性能。

To solve the above problem, we exploit R-CNN as a stronger RPN to provide more accurate candidate bounding boxes, and the Spatial Enhancement Module(SEM) is proposed to improve the final classification results, which is illustrated in Figure 2. We first modify the regression module of R-CNN in a class-agnostic manner before incorporating the SEM model. Our regression module in MFE only recognizes the foreground object and does not produce a bounding box for each category. Although this setting slightly lowers performance, it helps us recognize various categories and better adapt to our spatial module. Then, to provide a stronger RPN for the classification task, we sequentially connect the modules for regression and classification. The classification module performs better with such a framework in place.
为了解决上述问题,我们利用R-CNN作为更强的RPN,以提供更准确的候选边界框,并提出了空间增强模块(SEM)来改善最终的分类结果,如图2所示。我们首先在整合SEM模型之前,以类别无关的方式修改了R-CNN的回归模块。MFE中的回归模块仅识别前景对象,不为每个类别生成边界框。虽然这种设置稍微降低了性能,但它有助于我们识别各种类别,并更好地适应我们的空间模块。然后,为了为分类任务提供更强的RPN,我们依次连接回归和分类模块。在这样的框架下,分类模块的表现更好。
Beyond our SEM, we also discuss variants of SEM. One simple thought is that we can also get classification results from the original proposal as additional supervision. Similarly, another regression loss can be calculated by the updated bounding boxes feature. We refer to these two vari- ants of SEM as SEM-c and SEM-r. Experimental analysis in Section 4.4 demonstrates that these two auxiliary heads are not necessary and SEM outperforms these two variants.
除了我们的SEM之外,我们还讨论了SEM的变体。一个简单的想法是,我们也可以从原始提案中获得分类结果,作为额外的监督。同样,可以通过更新后的边界框特征计算另一个回归损失。我们将这两种SEM的变体称为SEM-c和SEM-r。第4.4节的实验分析表明,这两个辅助头并不是必要的,而且SEM的表现优于这两个变体。
3.3. Task-level Enhancement
In standard R-CNN, classifier and regressor employ the same feature to classify and locate. Classification and regression, however, serve different purposes. While the classifier tries to distinguish between various categories, the regressor focuses on locating the boundary of objects. During training, they suffer from the conflict between the classification and regression objectives, and the features generated by RoI-Align cannot take this conflict into account.
在标准的R-CNN中,分类器和回归器使用相同的特征进行分类和定位。然而,分类和回归的目的不同。分类器试图区分不同的类别,而回归器则专注于定位物体的边界。在训练过程中,它们受到分类和回归目标之间冲突的影响,而由RoI-Align生成的特征无法考虑到这种冲突。
We created a task enhancement module (TEM) to decompose the features in the original space into a unique space for each task to address the aforementioned problems. Our primary goal is to more effectively address the classification and regression tasks, avoiding conflicts between these two distinct tasks. As shown in Eq 1, we employ a channel-wise attention mechanism to achieve this.
为了应对上述问题,我们创建了任务增强模块(Task Enhancement Module, TEM),将原始空间中的特征分解到每个任务的独特空间中。我们的主要目标是更有效地处理分类和回归任务,避免这两个不同任务之间的冲突。正如方程1所示,我们采用了通道注意力机制来实现这一目标。
如方程1所示,在前向传播过程中,每个proposal的卷积特征通过最大池化(max pooling)被压缩成一个向量,从而丢失空间信息。然后这些特征通过一个线性层 𝑊1 转换为一个较小的特征空间
。接下来通过一个ReLU层和另一个线性层 𝑊2 将特征的维度提升到
,并通过sigmoid函数 𝜎计算注意力得分 𝐷(𝑧)。 𝜙和 𝜃分别表示 𝑊1 和 𝑊2中的参数。因此,我们在图像的高度和宽度方向上得到了一个注意力得分 𝑠。然后,通过结合通道注意力和原始特征,我们为RoI特征输出一个新的表示。这里, ⊗ 表示元素级别的乘法, 𝜎表示sigmoid激活函数。
Are there better transform layers?
We explore several kinds of modules to achieve our TEM, including linear transform, spatial-wise attention and channel-wise attention. The experiment results show that channel-wise attention outperforms other designs by a large margin. Furthermore, We attempt to use channel-wise attention without the task-specific adaptor, and the results show that the idea of task-specific adaptor is the primary element that can improve performance. The detail of the experiments is discussed in Section 4.4.
我们探索了几种模块来实现我们的任务增强模块(TEM),包括线性变换、空间注意力和通道注意力。实验结果表明,通道注意力的性能远远优于其他设计。此外,我们尝试使用没有任务特定适配器的通道注意力,结果表明,任务特定适配器的概念是提高性能的主要因素。实验的详细内容在第4.4节中讨论。
3.4. Regularization-level Enhancement
The fundamental cause of few-shot object detection difficulty is a serious shortage of data. When only one instance of a class has been observed, the detector is unable to acquire the necessary information about features to distinguish between related classes.
Few-shot物体检测难点的根本原因是数据严重短缺。当仅观察到一个类别的一个实例时,检测器无法获取区分相关类别所需的特征信息.
To reduce the overfitting problem, we expect to enhance the regularization ability of the model and guide the model to identify classes based on part of the information of features. To achieve this, we design a simple but efficient regularized feature enhancement module with a Regularized Consistent (RC) Loss as follows:
为了减少过拟合问题,我们期望增强模型的正则化能力,并引导模型基于部分特征信息来识别类别。为此,我们设计了一个简单但有效的正则化特征增强模块,并采用了一个正则化一致性 (RC) 损失,具体如下:
where g1 and g2 are different samples of the same feature.F is a measure function of whether g1 and g2 are consistent. We sample g1 and g2 using dropout technique and we use Kullback-Leibler (KL) divergence to implement F. Therefore, the total loss of MFE can be summarized as:
其中,g1 和 g2 是同一特征的不同样本。F 是一个度量函数,用于判断 g1 和 g2 是否一致。我们使用 dropout 技术对 g1 和 g2 进行采样,并使用 Kullback-Leibler (KL) 散度来实现 F。因此,MFE 的总损失可以总结如下:
LSEM includes a regression loss and two classification loss for g1 and g2. α is the hyperparameter that controls the weight of RC loss. By adding such regularization-level enhancement, our model augment the data from the feature level, while being robust to the different distribution of data. The method can be easily applied to different model structures, while more complex sampling methods can also be considered.
其中,包含一个回归损失和两个用于 𝑔1和 𝑔2的分类损失。α 是控制 RC 损失权重的超参数。通过添加这样的正则化级别增强,我们的模型在特征层面上扩充了数据,同时对不同数据分布具有鲁棒性。该方法可以轻松应用于不同的模型结构,同时也可以考虑更复杂的采样方法
4. Experiments
In this section, we first introduce more implementation details and extensive experiment results. Then we give additional ablation studies and visualizations to evidence the effectiveness of our work.
Implementation Details We use Faster R-CNN as our detection model and choose standard ResNet-101 [11] pretrained on ImageNet[23] as the backbone. We re-implement DeFRCN[20] based on detectron2 as the baseline. Specifically, we modify the regression head into a class-agnostic fashion. Both the base training stage and fine-tune stage adopt SGD optimizer with a mini-batch size of 16 and the batch size in proposal sampling is 512. The initial learning rates are 0.02 and 0.01 for base training and fine-tune training stage respectively. α in RC Loss is 1. We observed that the model on MS COCO requires more iteration to convergence due to more categories compared to PASCAL VOC, so the model is trained for 110000 iterations in COCO and 20000 iterations in PASCAL VOC in total.
在本节中,我们首先介绍更多的实现细节和广泛的实验结果。然后,我们给出额外的消融研究和可视化,以证明我们工作的有效性。
实现细节
我们使用 Faster R-CNN 作为检测模型,并选择预训练于 ImageNet 上的标准 ResNet-101 作为主干网络。我们基于 detectron2 重新实现了 DeFRCN,并将其作为基线模型。具体而言,我们将回归头修改为类无关的形式。基础训练阶段和微调阶段均采用 SGD 优化器,最小批次大小为 16,候选框采样中的批次大小为 512。基础训练阶段和微调训练阶段的初始学习率分别为 0.02 和 0.01。RC 损失中的 α 设为 1。我们观察到,由于 MS COCO 相较于 PASCAL VOC 拥有更多的类别,模型在 MS COCO 上需要更多的迭代次数才能收敛,因此在 COCO 上训练了总计 110000 次迭代,而在 PASCAL VOC 上训练了总计 20000 次迭代。
4.1. Experiment Benchmark
MS COCO. MS COCO[15] is a challenging benchmark in object detection, especially in few-shot setting. Following previous works[12, 29], the 80 categories are divided into 60 base categories and 20 novel categories. All training data come from MS COCO 2014 trainval dataset and 5K images from minival dataset are used as testing data. K-shot of novel instances are randomly sampled from unseen novel classes, and here the k = 1,2,3,5,10 and 30 by convention. We evaluate our model on the COCO-style mAP.
MS COCO[15] 是一个在物体检测中尤其是少样本设置下具有挑战性的基准测试。按照之前的工作[12, 29],80 个类别被划分为 60 个基础类别和 20 个新类别。所有训练数据来自 MS COCO 2014 的 trainval 数据集,并使用 5000 张 minival 数据集中的图像作为测试数据。从未见过的新类别中随机抽取 K 个样本实例进行训练,这里 K 的值按惯例设定为 1、2、3、5、10 和 30。我们在 COCO 风格的 mAP(平均精度)上评估我们的模型。
PASCAL VOC. PASCAL VOC 07+12 dataset[5] consists of 20 categories. Following existing works[12, 29], there are three random splits used for few-shot object detection, referred to as novel split 1,2, and 3. Each split includes 15 base classes and 5 novel classes. All base categories come from PASCAL VOC 07+12 trainval sets and we report AP50 for novel classes on PASCAL VOC test set.
PASCAL VOC 07+12 数据集[5] 包含 20 个类别。按照现有的工作[12, 29],少样本物体检测使用了三个随机拆分,分别称为新类别拆分 1、2 和 3。每个拆分包括 15 个基础类别和 5 个新类别。所有基础类别来自 PASCAL VOC 07+12 的 trainval 集,我们在 PASCAL VOC 测试集中报告新类别的 AP50(平均精度,IoU 为 0.5 时的平均精度)。
5. Conclusion
In this work, we propose a novel architecture for fewshot object detection in the view of features. We point out that the quality of features used in classification is significant for FSOD and involves a novel architecture referred to as MFE to improve it from three orthometric perspectives. With the sequential design of R-CNN, deployment of two task-specific adaptors, and a regularization consistent module, MFE enhances the performance of the classifier principally in spatial, task, and regularization levels respectively. In PASCAL VOC and MS COCO benchmarks, our model achieves competitive results, especially in MS COCO, we achieve the best performance in every setting.
在这项工作中,我们从特征的角度提出了一种新的少镜头目标检测体系结构。我们指出,分类中使用的特征质量对于FSOD具有重要意义,并涉及一种新的体系结构,称为MFE,从三个正交的角度改进它。通过 R-CNN 的顺序设计,部署两个特定于任务的适配器和一个正则化一致模块,MFE 分别主要在空间、任务和正则化级别增强分类器的性能。在 PASCAL VOC 和 MS COCO 基准测试中,我们的模型取得了有竞争力的结果,尤其是在 MS COCO 中,我们在每个设置中实现了最佳性能。















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









