






Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通过简单的key:value对的方式,通过配置中的Dependencies 来设置依赖关系。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
一、多个job任务
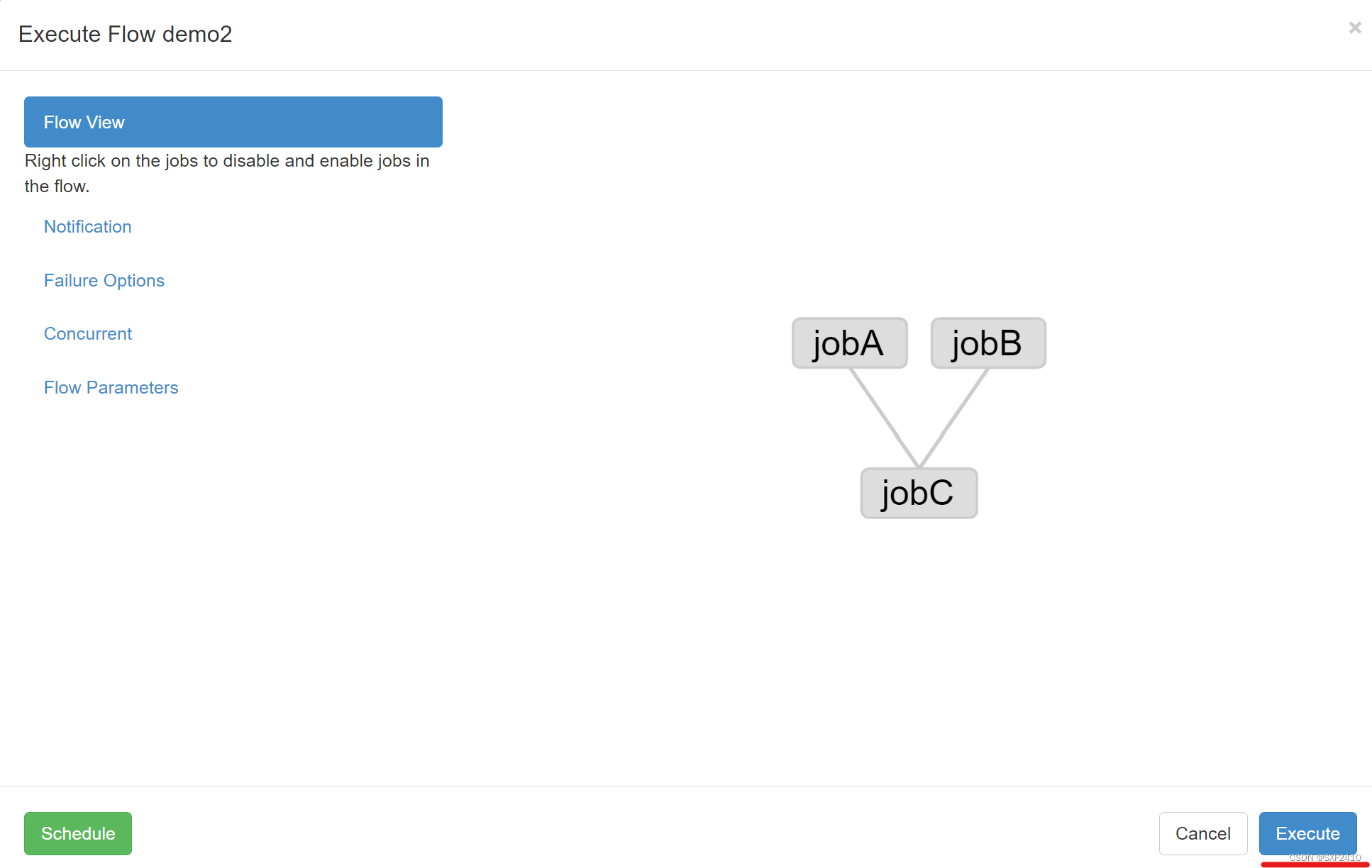
JobA,JobB并行,JobC依赖A,B;
创建工作流:
1、创建azkaban.project
azkaban-flow-version: 2.02、创建demo2.flow
参数含义:(任务失败,可再尝试3次,每次间隔5秒)
retries: 3
retry.backoff: 5000
nodes:
- name: jobA
type: command
config:
command: sh /not_aa.sh
retries: 3
retry.backoff: 5000
- name: jobB
type: command
config:
command: echo "JOB B"
- name: jobC
type: command
dependsOn:
- jobA
- jobB
config:
command: echo "JOB C"
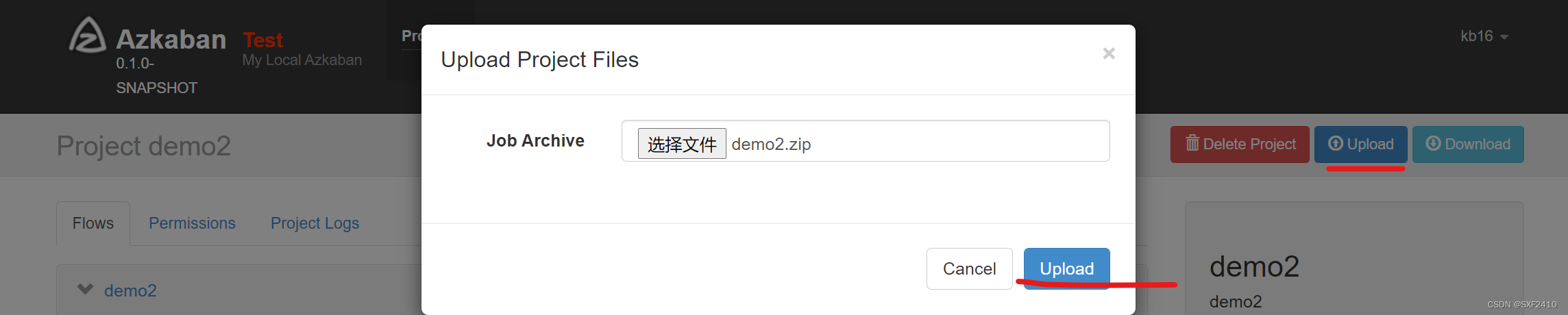
3.打包azkaban.project,demo2.flow成zip格式的压缩包;
4.登录webserver,在上面执行任务
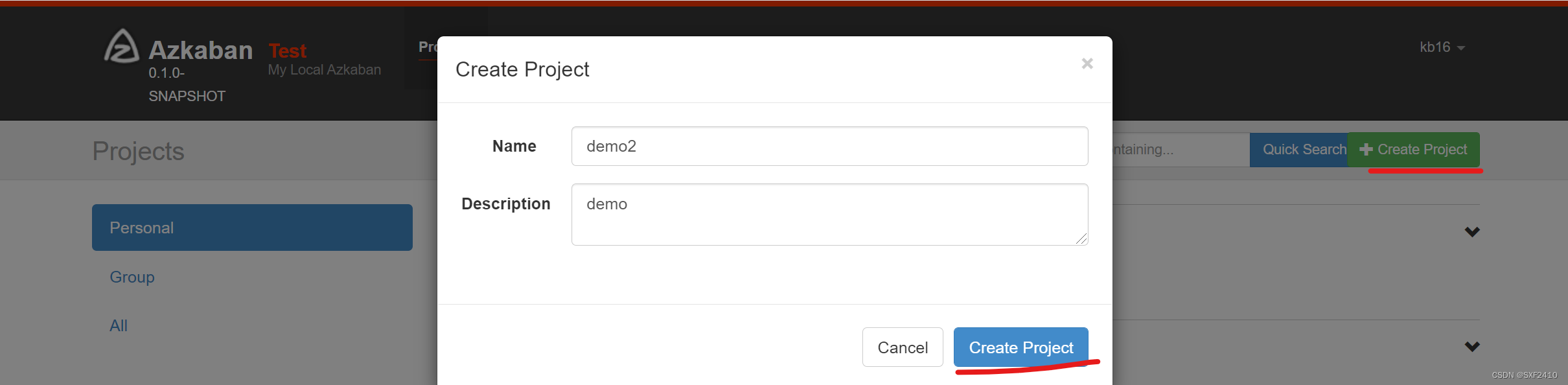
4.1创建Project
4.2加载前面的zip压缩包
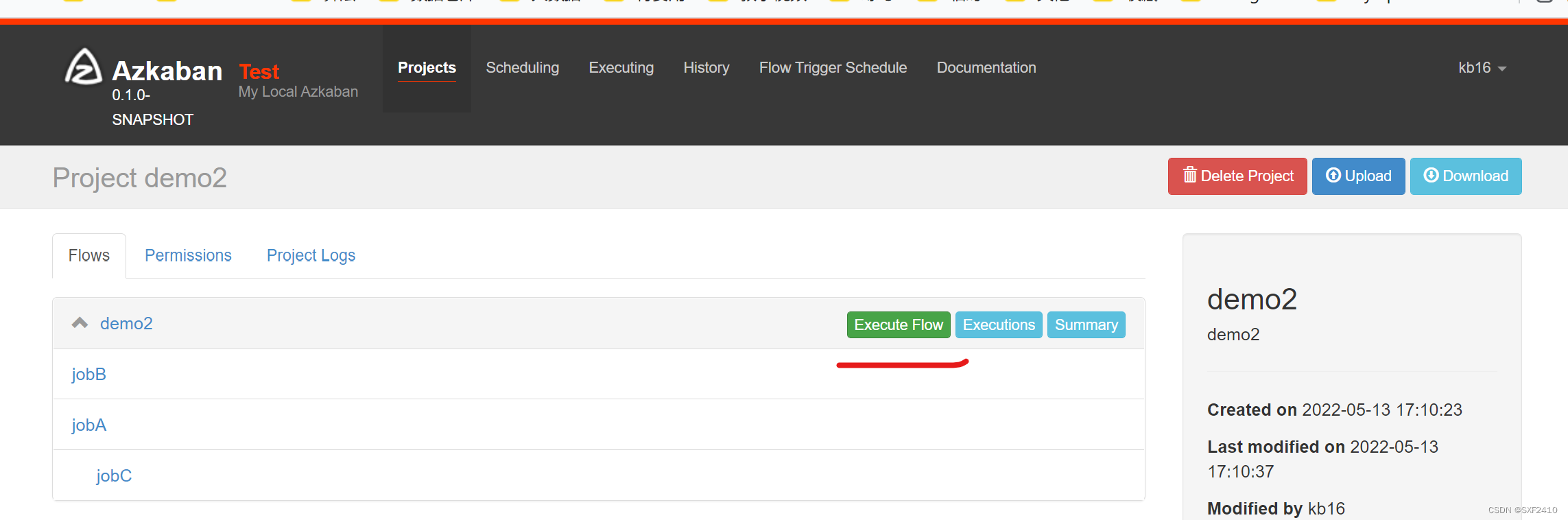
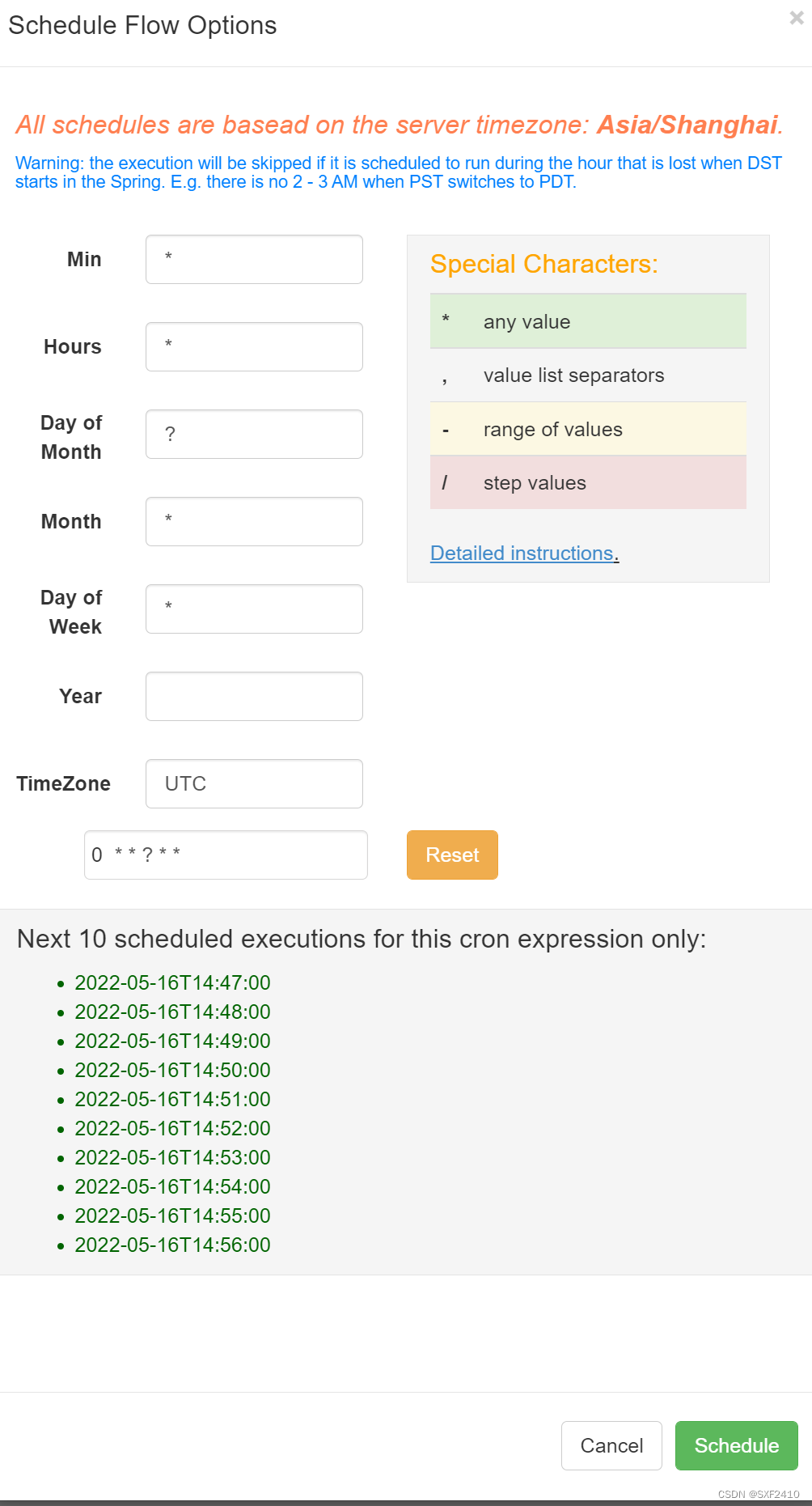
4.3执行工作流(设置调度时间)
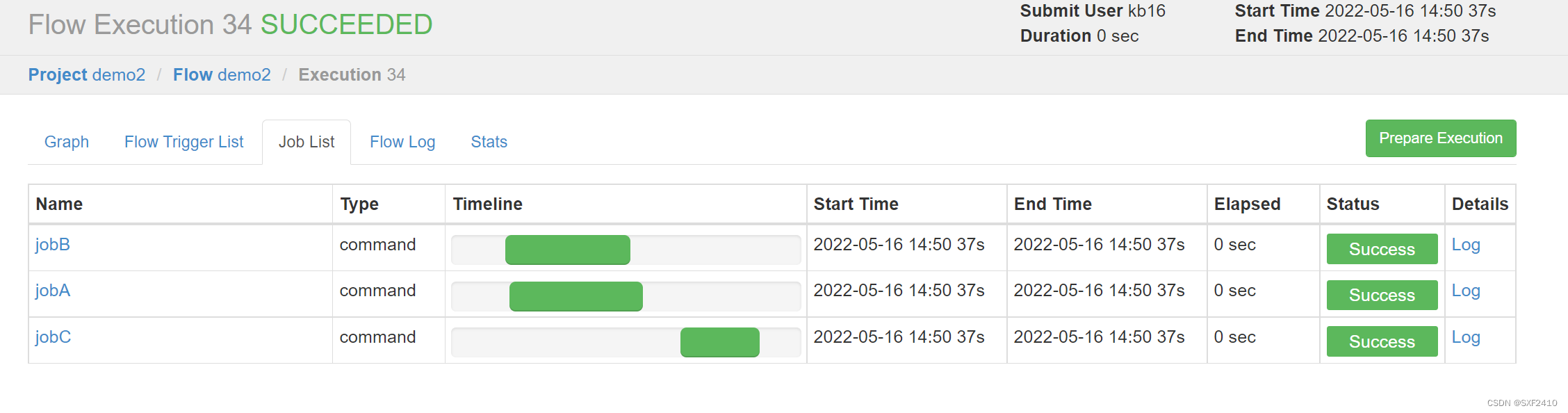
4.4查看执行情况
二、条件工作流,多脚本任务
条件:任务在周一执行
1、创建azkaban.project
2、创建条件工作流condition.flow
nodes:
- name: JobA
type: command
config:
command: sh JobA.sh
- name: JobB
type: command
dependsOn:
- JobA
config:
command: sh JobB.sh
condition: ${JobA:wk} == 13、创建JobA,JobB脚本(JobA.sh,JobB.sh)
#!/bin/bash
echo "do JobA"
wk=`date +%w`
echo "{\"wk\":$wk}" > $JOB_OUTPUT_PROP_FILE#!/bin/bash
echo "do JobB"
4、把以上文件打成zip格式压缩包,上传到webservet上。
5、登录webserver,在上面执行任务!
三、预定义宏
Azkaban 中预置了几个特殊的判断条件,称为预定义宏。
预定义宏会根据所有父 Job 的完成情况进行判断,再决定是否执行;
可用的预定义宏如下:
(1)all_success: 表示父 Job 全部成功才执行(默认)
(2)all_done:表示父 Job 全部完成才执行(失败、kill掉终、中止都叫完成)
(3)all_failed:表示父 Job 全部失败才执行
(4)one_success:表示父 Job 至少一个成功才执行
(5)one_failed:表示父 Job 至少一个失败才执行
1、创建azkaban.project
2、创建条件工作流macrodemo.flow
nodes:
- name: JobA
type: command
config:
command: sh JobA.sh
- name: JobB
type: command
config:
command: sh JobB.sh
- name: JobC
type: command
config:
command: sh JobC.sh
- name: JobD
type: command
dependsOn:
- JobA
- JobB
- JobC
config:
command: sh JobD.sh
condition: all_success3、创建shell脚本
JobA.sh
#!/bin/bash
echo "do JobD.sh"JobD.sh
#!/bin/bash
echo "do JobD.sh"4、把以上文件打成zip格式压缩包,上传到webservet上。
5、登录webserver,在上面执行任务!
四、执行hbase shell任务(在hbase上创建一个命名空间)
1、创建azkaban.project
2、创建条件工作流hbasedemo.flow
nodes:
- name: hbase
type: command
config:
command: hbase shell hbshell.sh3、创建shell脚本(hbshell.sh)
create_namespace 'azkabandemo'
list_namespace
exit4、把以上文件打成zip格式压缩包,上传到webservet上。
5、登录Azkaban的webserver,在上面执行任务!
五、在hive中建表(在test01数据库中创建azkabantb表)
1、创建azkaban.project
2、创建条件工作流hivedemo.flow
nodes:
- name: hivedemo
type: command
config:
command: hive -f test.sql3、创建test.sql文件
use test01;
drop table if exists azkabantb;
create table azkabantb(id int,name string) row format delimited fields terminated by ',' ;
load data inpath '/opt/azkaban/stu.txt' into table azkabantb;4、创建stu.txt文件,移动到的到虚拟机/opt目录下,在上传到hdfs上
1,java
2,python
3,scala
4,hbase
5,sparkhdfs dfs -mkdir -p /opt/azkaban/
hdfs dfs -put ./stu.txt /opt/azkaban/
5、把azkaban.project,hivedemo.flow,test.sql打zip格式压缩包,上传到webserver上、
6、登录Azkaban的webserver,在上面执行任务!
六、把spark程序打jar包,执行。
双击package,打jar包。生成:azkaban_spark_20220516-1.0-SNAPSHOT.jar
public class App {
public static void main( String[] args ) {
SparkConf sparkConf = new SparkConf().setAppName("sparkDemo").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
Integer[] ints={1,2,3,4};
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(ints));
List<Integer> collect = rdd.collect();
for (Integer i : collect) {
System.out.println(i);
}
}
}
1、创建azkaban.project,把jar包放在同一目录下;
2、创建条件工作流sparkdemo.flow;
nodes:
- name: jobspark
type: command
config:
command: spark-submit --class cn.kgc.App ./azkaban_spark_20220516-1.0-SNAPSHOT.jar
3、把azkaban.project,sparkdemo.flow和jar包打成zip格式的压缩包;并上传上传到webserver上
4、登录Azkaban的webserver,在上面执行任务!
七、把java程序打jar包,执行
双击package,打jar包。生成:azkaban_spark_20220516-1.0-SNAPSHOT.jar
public class TestJavaProcess {
public static void main(String[] args) {
System.out.println("azkaban java propcess'");
}
}
1、创建azkaban.project,把jar包放在同一目录下;
2、创建条件工作流javademo.flow;
nodes:
- name: testjava
type: javaprocess
config:
Xms: 100M
Xmx: 200M
java.class: cn.kgc.TestJavaProcess3、把azkaban.project,sparkdemo.flow和jar包打成zip格式的压缩包;并上传上传到webserver上
4、登录Azkaban的webserver,在上面执行任务!















 2713
2713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









