







写在前面
本文隶属于专栏《100个问题搞定大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和文献引用请见100个问题搞定大数据理论体系
解答
在批处理中追求吞吐量,所以对CPU的利用率要求很高,这里有2种可以提高CPU利用率的技术。
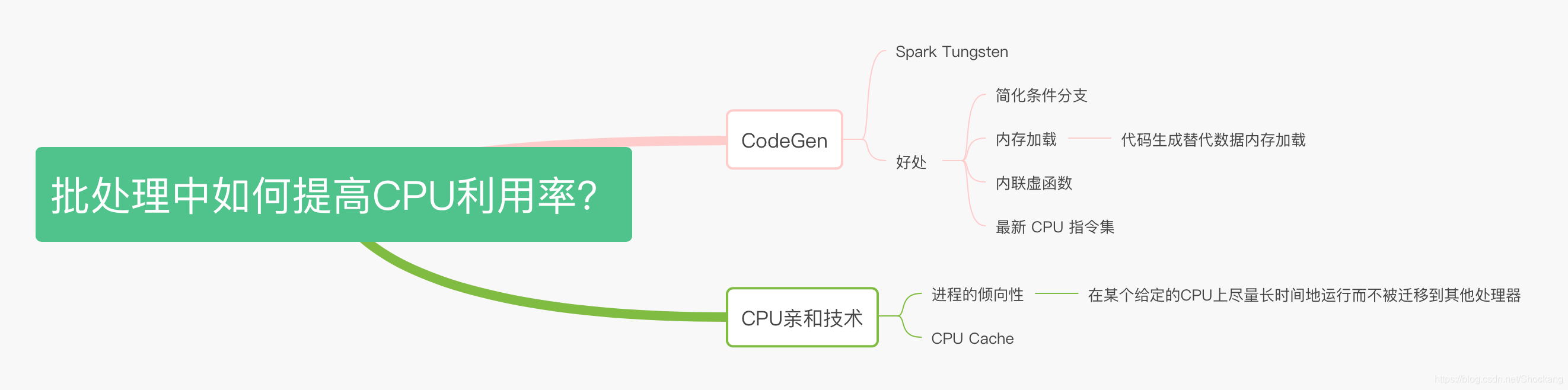
一是代码生成技术(CodeGen),二是CPU亲和技术。
补充
CodeGen
拿 Spark 举例说明,Spark1.5版本中更新较大的是DataFrame执行后端的优化,引入了 CodeGen技术( Tungsten项目的一部分)。
Spark通过 CodeGen在运行前将逻辑计划生成对应的机器执行代码,由Tungsten backend执行。
以Spark为代表的基于内存的计算引擎使得I/O性能比传统的基于硬盘的计算引擎有10倍左右的提升,但与此同时,CPU的瓶颈会更明显。
以传统 Postgresql的引擎为例,操作数据都被缓存到内存的Page Cache上面,执行最简单的Count()统计只能勉强达到每秒400万行左右,而真正需要的操作其实是很少的。
传统的数据库处理引擎有四大短板:
- 其一是条件逻辑冗余,数据处理引擎代码非常烦琐;
- 其二是虚函数的调用;
- 其三是需要不断地从内存中调用数据,而无法一次性将数据从内存加载至 Cache;
- 其四是为了保证数据引擎能跨不同的硬件平台,数据引擎很少支持一些扩展的指令集,这就导致本来可以提升的性能没有得到支持。
为了解决上述瓶颈,Google研发的Tenzing技术里面提出基于LVM编译框架实现动态生成代码的CodeGen技术,并且通过这个技术,基于MapReduce分布式框架下的类SQL系统的性能也能接近商业收费并行数据库的水准。
使用CodeGen的好处有:
- 其一是简化了条件分支;
- 其二是内存加载,可以使用代码生成来替代数据加载,从而极大地减少了内存的读取,增加了 CPU Cache的利用率;
- 其三是内联虚函数的调用;
- 其四是能利用最新的指令集。
CPU亲和技术
简单地说,CPU亲和性(Affinity)是指进程要在某个给定的CPU上尽量长时间地运行而不被迁移到其他处理器的倾向性。
Linux内核进程调度器天生就具有被称为软CPU亲和性(Affinity)的特性,这就意味着进程通常不会在处理器之间频繁迁移。
2.6版本的 Linux内核还包含一种机制,它让开发人员可以编程实现硬CPU亲和性(Affinity),这意味着应用程序可以显式地指定进程在哪台(或哪些)处理器上运行。
什么是Linux内核硬亲和性(Affinity)?
在 Linux内核中,所有的进程都有一个相关的数据结构,称为 task_struct。其中与亲和性(Affinity)相关度最高的是 cpus_allowed位掩码。
这个位掩码由n位组成,与系统中的n台逻辑处理器一一对应。具有4个物理CPU的系统可以有4位。如果这些CPU都启用了超线程,那么这个系统就有一个8位的位掩码。
如果为给定的进程设置了给定的位,那么这个进程就可以在相关的CPU上运行。因此,如果一个进程可以在任何CPU上运行, 并且能够根据需要在处理器之间进行迁移,那么位掩码就全是1。
实际上,这就是 Linux中进程的默认状态。
Linux内核API提供了一些方法,如 sched_set_affinity(用来修改位掩码)和sched_get_affinity (用来查看当前的位掩码),让用户可以修改位掩码或查看当前的位掩码。
注意, cpu_affinity会被传递给子线程,因此应该适当地调用 sched_set_affinity
为什么应该使用硬亲和性(Affinity)?
- 充分利用 CPU Cache。
- 保障时间敏感的、决定性的进程的CPU利用。















 2231
2231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









