







前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
关于数据库的一些基本概念
Schema(模式)
数据库 Schema 有两种含义。
一种是概念上的 Schema,指的是一组 DDL 语句集,该语句集完整地描述了数据库的结构。
还有一种是物理上的 Schema,指的是数据库中的一个名字空间,它包含一组表、视图和存储过程等命名对象。
物理 Schema 可以通过标准SQL语句来创建、更新和修改。
Catalog(目录)
数据库实例的数据库 Catalog 由元数据组成,其中存储了数据库对象的定义,例如基表、视图(虚拟表)、同义词、值范围、索引、用户和用户组。
SQL标准指定了访问 Catalog 的统一方法,称为INFORMATION_SCHEMA ,但并非所有数据库都遵循此方法,即使它们实现了 SQL 标准的其他方面。
在Spark SQL 系统中,Catalog 主要用于各种函数资源信息和元数据信息(数据库、数据表、数据视图、数据分区与函数等)的统一管理。
Namespace(命名空间)
Namespace 是一个逻辑实体。
Namespace 提供对数据和代码的访问,这些数据和代码(通常)存储在多个数据库中。
Spark 2.x 的 Catalog 体系
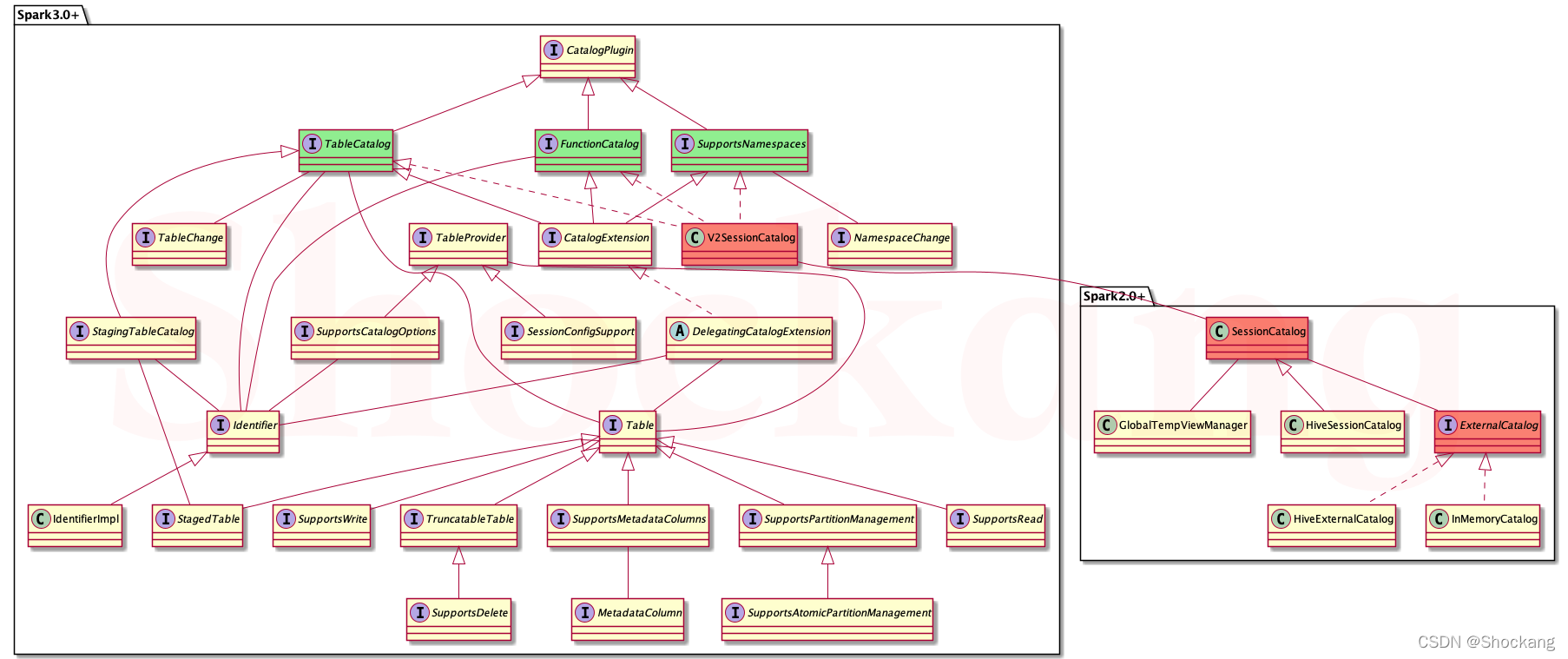
SessionCatalog
WHAT
在 Spark 2.x 中,Spark SQL中的 Catalog 体系实现以 SessionCatalog 为主体,通过SparkSession (Spark程序入口)提供给外部调用。
一般一个SparkSession对应一个SessionCatalog。
本质上, SessionCatalog起到了一个代理的作用,对底层的元数据信息、临时表信息、视图信息和函数信息进行了封装。
SessionCatalog的构造参数包括 6 部分,除传入 Spark SQL 和Hadoop 配置信息的CatalystConf与Configuration外,还涉及以下4个方面的内容。
构造参数
GlobalTempViewManager(全局的临时视图管理)
对应DataFrame中常用的createGlobalTempView方法,进行跨Session 的视图管理。
GlobalTempViewManager是一个线程安全的类,提供了对全局视图的原子操作,包括创建、更新、删除和重命名等。
在GlobalTempViewManager内部实现中,主要功能依赖一个mutable类型的HashMap来对视图名和数据源进行映射,其中的key是视图名的字符串,value是视图所对应的LogicalPlan(一般在创建该视图时生成)。
需要注意的是,GlobalTempViewManager对视图名是大小写敏感的。
FunctionResourceLoader(函数资源加载器)
在 Spark SQL 中除内置实现的各种函数外,还支持用户自定义的函数和Hive中的各种函数。
这些函数往往通过Jar包或文件类型提供, FunctionResourceLoader主要就是用来加载这两种类型的资源以提供函数的凋用。
需要注意的是,对于 Archive 类型的资源,目前仅支持在 YARN 模式下以spark-submit 方式提交时进行加载。
FunctionRegistry(函数注册接口)
用来实现对函数的注册(Register)、查找(Lookup)和删除(Drop)等功能。
一般来讲,FunctionRegistry 的具体实现需要是线程安全的,以支持并发访问。
在 Spark SQL 中默认实现是SimpleFunctionRegistry,其中采用Map数据结构注册了各种内置的函数。
ExternalCatalog(外部系统Catalog)
用来管理数据库(Databases)、数据表(Tables)、数据分区(Partitions)和函数(Functions)的接口。
顾名思义,其目标是与外部系统交互, 并做到上述内容的非临时性存储,同样需要满足线程安全以支持并发访问。
在Spark SQL中,具体实现有InMemoryCatalog和HiveExternalCatalog两种。
前者将上述信息存储在内存中,一般用于测试或比较简单的SQL处理;后者利用Hive原数据库来实现持久化的管理,在生产环境中广泛应用。
小结
总体来看,SessionCatalog是用于管理上述一切基本信息的入口。
SessionCatalog在Spark SQL的整个流程中起着重要的作用, 在逻辑算子阶段和物理算子阶段都会用到。
Spark 3.x 的 Catalog 体系
为什么已经有了现成的以 SessionCatalog 为核心的 Catalog 体系,还要做出重大改进呢?
Spark 3.x 版本的 Catalog 体系和 2.x 版本相比,有什么优势?
在回答上面的 2 个问题前,请先阅读下面的 2 个博客,都是我翻译自官方 SPIP(软件过程改进计划,类似软件开发计划书的意思) 。
读完上面的 2 篇博客,实际上答案就比较明显了,DataSource v1 版本存在诸多问题:
- 由于其输入参数包括 DataFrame / SQLContext,因此 DataSource API 兼容性取决于这些上层的 API。
- 物理存储信息(例如,划分和排序)不会从数据源传播,并且因此,Spark 的优化器无法利用。
- 可扩展性不好,并且算子的下推能力受限。
- 缺少高性能的列式读取接口。
- 写入接口是如此普遍,不支持事务。
DataSource v2 是用来读取和写入数据的新型 API ,旨在支持更多外部数据存储,并且可以更灵活地集成这些存储。
但是,v2 API 目前缺少该集成的一些关键部分:
- 我们需要定义 catalog API 用来 create,alter,load 和 drop 表,于是我们就有了
TableCatalog - 我们需要 定义 catalog API 用来操作函数,于是我们就有了
FunctionCatalog - 我们需要 定义 catalog API 用来操作 Namespace,于是我们就有了
SupportsNamespaces - 我们需要保持向后兼容性,于是我们就有了
V2SessionCatalog,这个类实现了上面的 3 个接口,它实际上是对SessionCatalog的一个封装,这一点从它的构造函数可以清晰看出来:
class V2SessionCatalog(catalog: SessionCatalog)
extends TableCatalog with FunctionCatalog with SupportsNamespaces with SQLConfHelper
上面的
SQLConfHelper只是用来方便获取SQLConf的,和 Catalog 体系无关。
类图
我们将上面提到的类和接口都画到一个类图中,希望大家可以从中体会到 Spark Catalog 体系的设计思想。


















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









