







前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
JOIN
JOIN是 Apache Spark 中最常用的操作之一。
编写 JOIN 操作的语法很简单,但后面的内容就复杂了。
Apache Spark 会通过几个算法检查,然后从中选出最好的 JOIN 策略。
如果我们不知道这些内部算法并且不知道 Spark 选择了什么,它可能会使简单的 JOIN 操作变得昂贵。
Spark 怎么选择 Join 策略呢?
Spark 选择 Join 策略会考虑到 2 个因素:
- Join 类型
- Join Hints
Spark 中支持的 Join 类型请参考我的这篇博客——Spark SQL 支持哪些类型的 JOIN ?
Join Hints
Spark 中定义的 Join Hints 通过查看org.apache.spark.sql.catalyst.plans.logical.JoinStrategyHint 的源码就可以发现。
sealed abstract class JoinStrategyHint {
// 展示名称
def displayName: String
// hint 别名
def hintAliases: Set[String]
// 字符串方便打印
override def toString: String = displayName
}
JoinStrategyHint 抽象类是 Spark 中支持的所有 Join Hints 的父类。
Spark 中支持的 Join Hints 定义在 object 中:
object JoinStrategyHint {
val strategies: Set[JoinStrategyHint] = Set(
BROADCAST,
SHUFFLE_MERGE,
SHUFFLE_HASH,
SHUFFLE_REPLICATE_NL)
}
从上面可以看到,总共包括 4 种类型
- BROADCAST
- SHUFFLE_MERGE
- SHUFFLE_HASH
- SHUFFLE_REPLICATE_NL
如果可行,Hint 策略将用于与其关联的Join。
如果为Join的每一方指定了相互矛盾的策略Hint,则提示的优先级为BROADCAST优先于SHUFFLE_MERGE优先于SHUFFLE_HASH优先于SHUFFLE_REPLICATE_NL。
BROADCAST
case object BROADCAST extends JoinStrategyHint {
override def displayName: String = "broadcast"
override def hintAliases: Set[String] = Set(
"BROADCAST",
"BROADCASTJOIN",
"MAPJOIN")
}
broadcast hash join(BHJ)或broadcast nested loop join(BNLJ)的 Hint,具体取决于等值 Join Key的可用性。
BHJ/BNLJ 的别名有:
- BROADCAST
- BROADCASTJOIN
- MAPJOIN
SHUFFLE_MERGE
case object SHUFFLE_MERGE extends JoinStrategyHint {
override def displayName: String = "merge"
override def hintAliases: Set[String] = Set(
"SHUFFLE_MERGE",
"MERGE",
"MERGEJOIN")
}
Shuffle sort merge join(SMJ)的 Hint。
SMJ 的别名有:
- SHUFFLE_MERGE
- MERGE
- MERGEJOIN
SHUFFLE_HASH
case object SHUFFLE_HASH extends JoinStrategyHint {
override def displayName: String = "shuffle_hash"
override def hintAliases: Set[String] = Set(
"SHUFFLE_HASH")
}
Shuffle hash join(SHJ)的 Hint。
SHJ 的别名为:SHUFFLE_HASH
SHUFFLE_REPLICATE_NL
case object SHUFFLE_REPLICATE_NL extends JoinStrategyHint {
override def displayName: String = "shuffle_replicate_nl"
override def hintAliases: Set[String] = Set(
"SHUFFLE_REPLICATE_NL")
}
shuffle-and-replicate nested loop join / cartesian product join(CPJ)的 Hint。
CPJ 的别名为:SHUFFLE_REPLICATE_NL
除了上面 4 种以外,Spark 还支持另外 2 种 Join Hint,这两种都是 AQE内部使用的。
- NO_BROADCAST_HASH
- PREFER_SHUFFLE_HASH
关于 AQE 请参考我的博客——Spark SQL 的 AQE 机制
NO_BROADCAST_HASH
case object NO_BROADCAST_HASH extends JoinStrategyHint {
override def displayName: String = "no_broadcast_hash"
override def hintAliases: Set[String] = Set.empty
}
NO_BROADCAST_HASH 是 Spark 内部 AQE 用来阻止选择BHJ策略的 Hint。
PREFER_SHUFFLE_HASH
case object PREFER_SHUFFLE_HASH extends JoinStrategyHint {
override def displayName: String = "prefer_shuffle_hash"
override def hintAliases: Set[String] = Set.empty
}
PREFER_SHUFFLE_HASH 是 Spark 内部 AQE 用来优先选择SHJ策略的 Hint。
Join 策略的类型
1. Broadcast Hash Join(BHJ)
当其中一个 Dataset 很小并且适合内存时,它会被广播给所有的 Executor,并且会进行 Hash Join。

图 1:没有 Hint 的 BHJ
Spark 配置参数:spark.sql.autoBroadcastJoinThreshold 表示一个 能够广播的 DataFrame 最大字节数。
spark.sql.autoBroadcastJoinThreshold = -1 表示禁止broadcast Join,而默认的配置值为10485760 也就是10M。
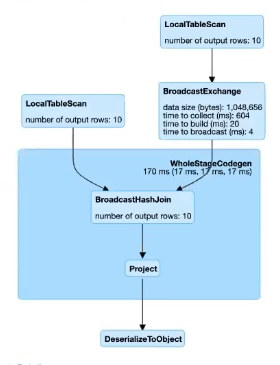
图 2:Broadcast Hash Join
在以下情况下,哪个表将被广播呢?
- 如果在 Join 的任一侧指定了
broadcast hint,则无论autoBroadcastJoinThreshold如何,都将广播带有 Hint 的 Join 侧。 - 如果在 Join 的两侧都指定了
broadcast hint,则将广播具有较小物理数据大小的一侧。 - 如果没有 Hint,并且表的物理大小 <
autoBroadcastJoinThreshold,该表将被广播到所有 Executor 节点。

图 3:Broadcast Hash Join
如果广播端较小,BHJ 可以比其他 Join 算法执行得更快,因为不涉及 Shuffle。
广播的性能一定好吗?
不一定!
广播表是网络密集型操作。
当广播表很大时,可能会导致 OOM 或性能比其他算法差。
如果你给集群更多的资源,非广播版本可能会比广播版本运行得更快,因为广播操作本身是昂贵的。
如果我们增加 executor 的数量,这些 executor 需要接收 table。
通过增加 executor 的数量,我们也在增加广播成本。
现在,假设我们正在广播一张中等大小的 table, 当运行代码时,一切都很好而且超级快。
但是将来当一个中型表不再是“中型”时,代码可能会因 OOM 而中断。
数据倾斜
当我们想要Join两个表时,数据倾斜是开发人员经常面临的难题之一。
当 Join Key 在数据集中分布不均匀时,Join 会出现倾斜。
当 Join 倾斜时,Spark 无法并行执行操作,因为 Join 的负载将不均匀地分布在 Executor 之间。
如果一张表很小,我们可以决定直接广播!
观察执行期间任务发生了什么:其中一项任务花费了更多时间。

图 4:Join 倾斜
2. Shuffle Hash Joins(SHJ)
当表比较大的时候,使用广播可能会导致 Driver 和 Executor 的内存问题。
在这种情况下,将会使用 Shuffle Hash Join(SHJ)。
这是一个昂贵的JOIN,因为它涉及 Shuffle 和 HASH。
此外,它需要内存和计算来维护哈希表。
Shuffle Hash Join 分两步执行:
- Shuffle:来自 Join 表的数据基于 Join Key 进行分区。它确实在分区之间 Shuffle 数据,以将相同 Join Key 的记录分配给相应的分区。
- Hash Join:对每个分区上的数据执行经典的单节点
Hash Join算法。

图 5:Shuffle Hash Join
如果要使用 Shuffle Hash Join,spark.sql.join.preferSortMergeJoin 需要设置为 false,构建 hash map 的成本比对数据排序要少。
Sort-merge Join(SMJ) 是默认的 Join,优先于 Shuffle Hash Join。
当数据与正在 join 的 key 均匀分布并且有足够数量的 key 用于并行处理的时候,Shuffle Hash Join(SHJ) 的性能是最佳的。
3. Shuffle sort-merge Join(SMJ)
Shuffle Sort-merge Join(SMJ)涉及对数据进行 Shuffle 以获得相同的Join key 与相同的 worker,然后在 worker 节点的分区级别执行 Sort-merge Join 操作。
分区在 Join 操作之前按 Join Key 排序。
它有3个阶段:
- Shuffle 阶段:两个大表将根据集群中分区的 Join Key 重新分区。
- Sort 阶段:对每个分区内的数据进行并行排序。
- Merge 阶段:Join 已排序、已分区的数据。它通过迭代元素并 Join 具有相同 Join Key 的数据行来合并数据集。

图 6:Sort-Merge Join
SMJ 在大多数情况下都比其他 Join 执行得更好,并且具有非常可扩展的方法,因为它消除了 HASH 的开销并且不需要整个数据都适合内存。
4. Broadcast Nested Loop Join(BNLJ)
BNLJ 在未超过广播阈值时选择。
它支持等值 Join 和不等值 Join。
它还支持所有其他 Join 类型,但在以下情况下实现会得到优化:
- 左侧在
right outer join中广播。 - 右侧在
left outer join、left semi join和left anti join中广播。 - 在类似
inner join中。
在其他情况下,我们需要多次扫描数据,这可能相当慢。
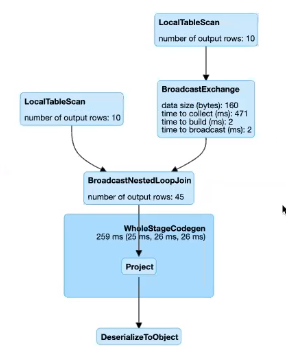
图 7:Broadcast Nested Loop Join
5. Cartesian Product Join(CPJ)
当 Join 类型为类inner join且不存在join key时,将选择 CPJ。
cross join计算两个表的笛卡尔乘积。
如果我们想使用 CPJ,我们必须设置spark.sql.crossJoin.enabled=true,否则 Spark 将引发异常:AnalysisException。

图 8:Cartesian Product Join
Join 类型对 Join 策略的影响

















 2088
2088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









