







前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
正文
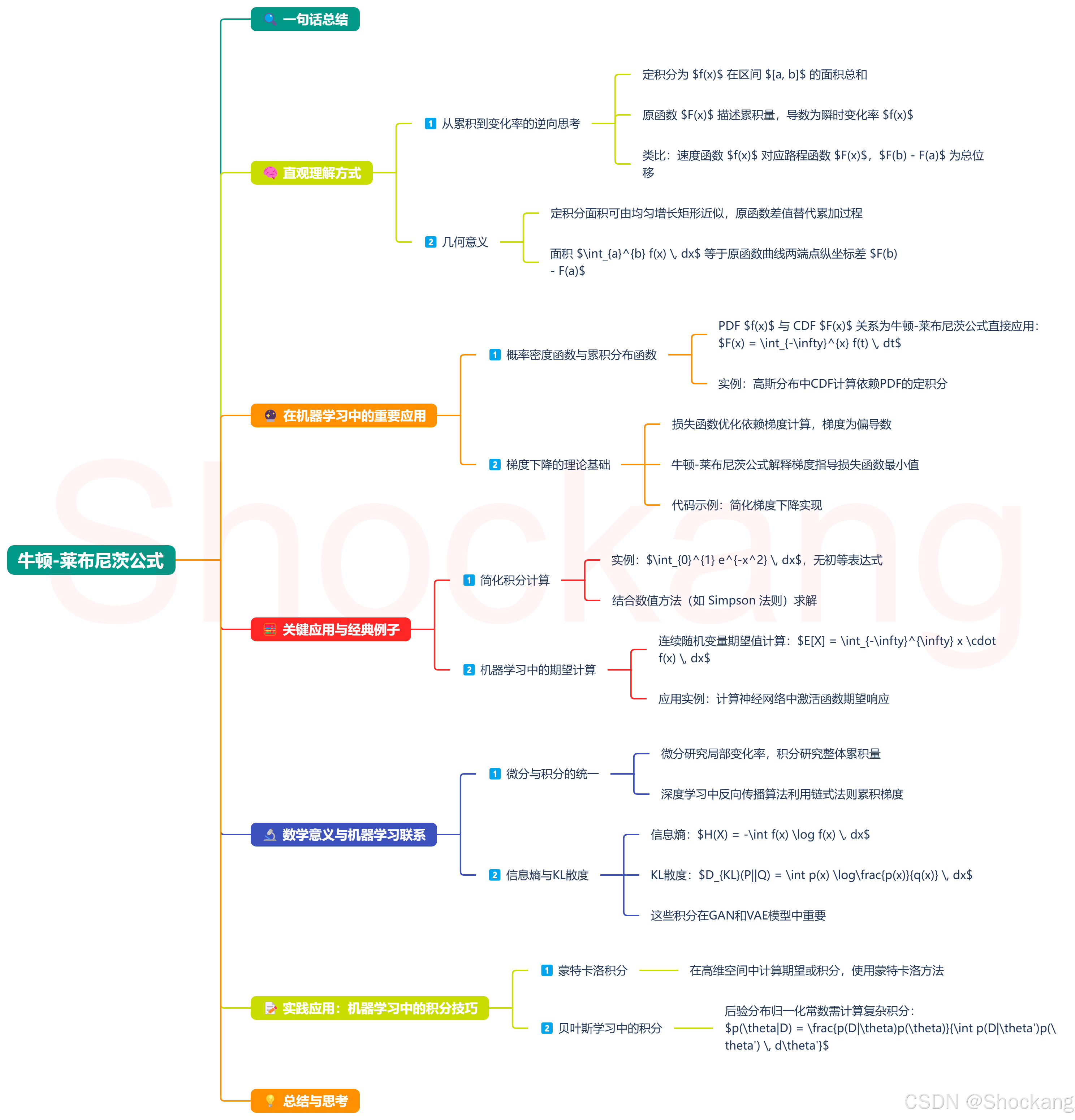
🔍 一句话总结
∫ a b f ( x ) d x = F ( b ) − F ( a ) \int_{a}^{b} f(x) \, dx = F(b) - F(a) ∫abf(x)dx=F(b)−F(a)
其中, F ( x ) F(x) F(x) 是 f ( x ) f(x) f(x) 的一个原函数(即 F ′ ( x ) = f ( x ) F'(x) = f(x) F′(x)=f(x))。
🧠 直观理解方式
1️⃣ 从累积到变化率的逆向思考
- 定积分 ∫ a b f ( x ) d x \int_{a}^{b} f(x) \, dx ∫abf(x)dx 本质是求函数 f ( x ) f(x) f(x) 在区间 [ a , b ] ] [a, b]] [a,b]] 上与 x 轴围成的"面积"总和。
- 原函数 F ( x ) F(x) F(x) 是描述这一累积量的函数,其导数恰好是瞬时变化率 f ( x ) f(x) f(x)。
- 生动类比:若 f ( x ) f(x) f(x) 是速度函数,则原函数 F ( x ) F(x) F(x) 是路程函数, F ( b ) − F ( a ) F(b) - F(a) F(b)−F(a) 就是总位移(即"速度的累积"等于"路程的变化")。
2️⃣ 几何意义
- 定积分(面积)可由高度均匀增长的矩形面积近似,通过原函数的差值精确替代了无限细分矩形的累加过程。
- 几何上,面积 ∫ a b f ( x ) d x \int_{a}^{b} f(x) \, dx ∫abf(x)dx 恰好等于原函数曲线在两端点的纵坐标之差 F ( b ) − F ( a ) F(b) - F(a) F(b)−F(a)。
🔮 在机器学习中的重要应用
1️⃣ 概率密度函数与累积分布函数
- 在机器学习模型中,概率密度函数(PDF)
f
(
x
)
f(x)
f(x) 与累积分布函数(CDF)
F
(
x
)
F(x)
F(x) 的关系正是牛顿-莱布尼茨公式的直接应用:
F ( x ) = ∫ − ∞ x f ( t ) d t F(x) = \int_{-\infty}^{x} f(t) \, dt F(x)=∫−∞xf(t)dt - 实例:在高斯分布中,CDF无法直接计算,但可通过概率密度函数的定积分获得,为预测分布和量化不确定性提供基础。
2️⃣ 梯度下降的理论基础
- 机器学习中的损失函数优化依赖于梯度计算,而梯度本质上是函数对参数的偏导数。
- 牛顿-莱布尼茨公式解释了为什么梯度(局部变化率)能指导我们找到损失函数的最小值(累积效应)。
- 代码示例:简化梯度下降实现
def gradient_descent(f, df, x0, learning_rate=0.01, iterations=1000):
"""
f: 损失函数
df: 损失函数的导数(梯度)
x0: 初始参数
"""
x = x0
history = [x]
for i in range(iterations):
# 使用导数(梯度)指导参数更新方向
x = x - learning_rate * df(x)
history.append(x)
return x, history
🧮 关键应用与经典例子
1️⃣ 简化积分计算
- 实例:计算
∫
0
1
e
−
x
2
d
x
\int_{0}^{1} e^{-x^2} \, dx
∫01e−x2dx
- 此积分无初等函数表达式,在机器学习中可用来计算高斯函数在特定区间的概率
- 通过数值方法(如Simpson法则)结合牛顿-莱布尼茨思想求解
import numpy as np
from scipy import integrate
# 计算高斯函数在[0,1]区间的积分
result, error = integrate.quad(lambda x: np.exp(-x**2), 0, 1)
print(f"积分结果: {result:.6f}, 误差估计: {error:.6e}")
2️⃣ 机器学习中的期望计算
- 连续随机变量的期望值计算: E [ X ] = ∫ − ∞ ∞ x ⋅ f ( x ) d x E[X] = \int_{-\infty}^{\infty} x \cdot f(x) \, dx E[X]=∫−∞∞x⋅f(x)dx
- 应用实例:计算神经网络中激活函数的期望响应,帮助分析网络性能
🔬 数学意义与机器学习联系
1️⃣ 微分与积分的统一
- 微分研究"局部变化率",积分研究"整体累积量",二者通过原函数形成完美闭环。
- 在深度学习中,反向传播算法正是利用了这一原理,通过链式法则累积梯度信息。
2️⃣ 信息熵与KL散度
- 信息熵可表示为: H ( X ) = − ∫ f ( x ) log f ( x ) d x H(X) = -\int f(x) \log f(x) \, dx H(X)=−∫f(x)logf(x)dx
- KL散度: D K L ( P ∣ ∣ Q ) = ∫ p ( x ) log p ( x ) q ( x ) d x D_{KL}(P||Q) = \int p(x) \log\frac{p(x)}{q(x)} \, dx DKL(P∣∣Q)=∫p(x)logq(x)p(x)dx
- 这些积分在生成对抗网络(GAN)和变分自编码器(VAE)等模型中至关重要
📝 实践应用:机器学习中的积分技巧
1️⃣ 蒙特卡洛积分
在高维空间中计算期望或积分时,可以使用蒙特卡洛方法:
import numpy as np
# 使用蒙特卡洛方法估计π值
def monte_carlo_pi(samples=1000000):
# 随机生成点
points = np.random.random((samples, 2))
# 计算落在单位圆内的点数
inside = np.sum(np.sum(points**2, axis=1) < 1)
# 根据比例估计π
return (inside / samples) * 4
print(f"π的蒙特卡洛估计值: {monte_carlo_pi()}")
2️⃣ 贝叶斯学习中的积分
贝叶斯推断中的后验分布归一化常数需要计算复杂积分:
p ( θ ∣ D ) = p ( D ∣ θ ) p ( θ ) ∫ p ( D ∣ θ ′ ) p ( θ ′ ) d θ ′ p(\theta|D) = \frac{p(D|\theta)p(\theta)}{\int p(D|\theta')p(\theta') \, d\theta'} p(θ∣D)=∫p(D∣θ′)p(θ′)dθ′p(D∣θ)p(θ)
实践中通常使用MCMC等方法近似计算这些积分。
💡 总结与思考
牛顿-莱布尼茨公式不仅是微积分的核心定理,也是现代机器学习算法的理论基石。它揭示了一个深刻的数学洞见:求总量的"笨办法"(无限累加微小量)可以转化为求变化的"聪明办法"(找原函数计算端点差值)。
在机器学习中,从梯度下降到概率模型,从损失函数优化到信息理论,处处可见牛顿-莱布尼茨公式的应用。掌握这一原理,不仅可以更优雅地解决数学问题,更能深入理解算法背后的原理。
🔔 关键启示:微积分的精髓不仅在于计算技巧,更在于它提供了描述和分析连续变化现象的强大框架——正是机器学习所需要的数学基础。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









