








ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
📢 推特前安全总监举报:Twitter在撒谎!内部管理混乱,机器人账号远不止5%
https://www.washingtonpost.com/technology/interactive/2022/twitter-whistleblower-sec-spam/
Peiter Zatko 是一位广受推崇的黑客,江湖名号 Mudge,2020 年 11 月入职 Twitter 担任安全主管,2022 年 1 月被解雇。官方给出的解雇理由是『领导不力和表现不佳』,然而 Zatko 声称这是公司对他的报复,『因为他拒绝对公司的漏洞保持沉默』。

Zatko 上个月向美国证券交易委员会 (SEC) 提起诉讼,共计 200 多页,指控 Twitter 欺骗股东并违反与联邦贸易委员会 (FTC) 达成的某些安全标准的维护协议。CNN和华盛顿邮23日以删节的形式发表了这份投诉,共 84 页。
投诉将 Twitter 描述为一家陷入内讧的混乱无舵的公司,一半服务器运行的是过时且易受攻击的软件,数千名员工能够广泛且缺乏跟踪地访问公司内部核心软件,对垃圾邮件和机器人管控不利等等。这个庞大且充满风险的平台,已经无法妥善保护其 2.38 亿日常用户,包括政府机构、国家元首和其他有影响力的公众人物。

工具&框架
🚧 『Wilderness Scavenger』基于3D开放世界 FPS 游戏的智能体学习开发平台
https://github.com/inspirai/wilderness-scavenger
https://sites.google.com/view/inspirai-wildscav-cog2022/home
Wilderness Scavenger是一个基于 Inspir.AI 开发的 3D 开放世界 FPS 游戏的智能代理学习平台。


🚧 『AlphaStar』DeepMind 提供的训练星际II智能体的工具平台
https://github.com/deepmind/alphastar
AlphaStar 是 DeepMind 一个软件包,提供了具平台用于掌握『星际争霸II』的智能体。DeepMind 在这个包中提供了一些关键产品:
- ① 训练『星际争霸II』智能体(architectures/目录下)可以在在线和离线环境下使用不同的学习算法。
- ② 数据读取器、离线训练和评估脚本,用于完全离线强化学习,在unplugged/目录下以行为克隆为代表实例。
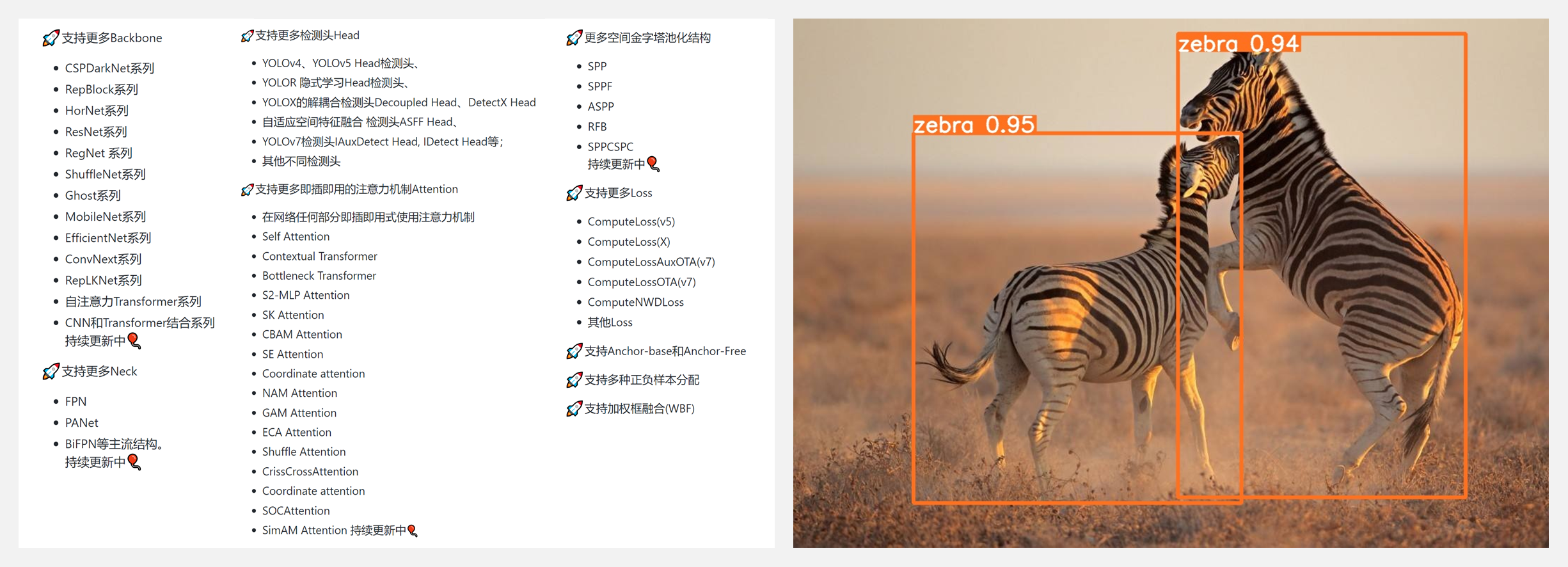
🚧 『YOLOAir』基于 PyTorch 的一系列 YOLO 检测算法组合工具箱
https://github.com/iscyy/yoloair
YOLOAir 算法库是一个基于 PyTorch 的一系列 YOLO 检测算法组合工具箱,用来组合不同模块构建不同网络,内置了 YOLOv5、YOLOv7、YOLOX、YOLOR、Transformer、Scaled_YOLOv4、YOLOv3、YOLOv4、YOLO-Facev2、TPH-YOLOv5、YOLOv5Lite、PicoDet 等模型网络结构。
YOLOAir 具备模块组件化的特点:① 帮助用户自定义快速组合Backbone、Neck、Head,② 使得网络模型多样化,③ 助力科研改进检测算法、模型改进,④ 网络排列组合,⑤ 构建强大的网络模型。
🚧 『Uni-Core』高性能分布式PyTorch框架
https://github.com/dptech-corp/Uni-Core
Uni-Core 是为快速创建高性能的 PyTorch 模型而建立的,尤其针对大型的 Transfromer 类模型,具备诸多功能特点:
- 通过多GPU和多节点进行分布式训练
- 使用fp16和bf16的混合精度训练
- 高性能的融合型CUDA内核
- 模型存储检查点管理
- 友好的日志记录
- 缓冲数据加载器
- 梯度累加
- 常用的优化器和学习率调度器
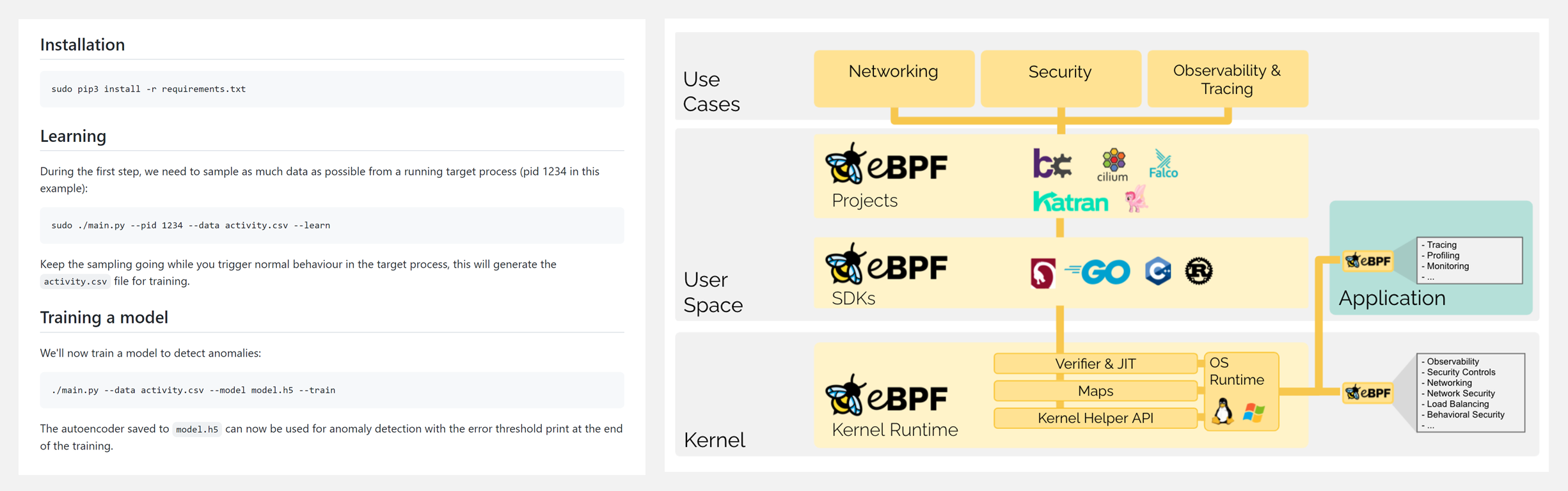
🚧 『ebpf process anomaly detection』使用 eBPF 和无监督学习自编码器的过程行为异常检测
https://github.com/evilsocket/ebpf-process-anomaly-detection
ebpf-process-anomaly-detection 使用eBPF系统调用跟踪和无监督学习自动编码器的过程行为异常检测。
博文&分享
👍 『Python Data Science Handbook』Python 数据科学·电子书
英文原版:https://jakevdp.github.io/PythonDataScienceHandbook/
非官方中文翻译:https://github.com/wangyingsm/Python-Data-Science-Handbook
这是一本介绍数据科学和应用的书籍。内容覆盖:
- ① 数据科学家需要的计算环境:IPython和Jupyter
- ② NumPy工具库与科学计算
- ③ Pandas与数据处理
- ④ Matplotlib与数据可视化
- ⑤ Scikit-Learn与机器学习

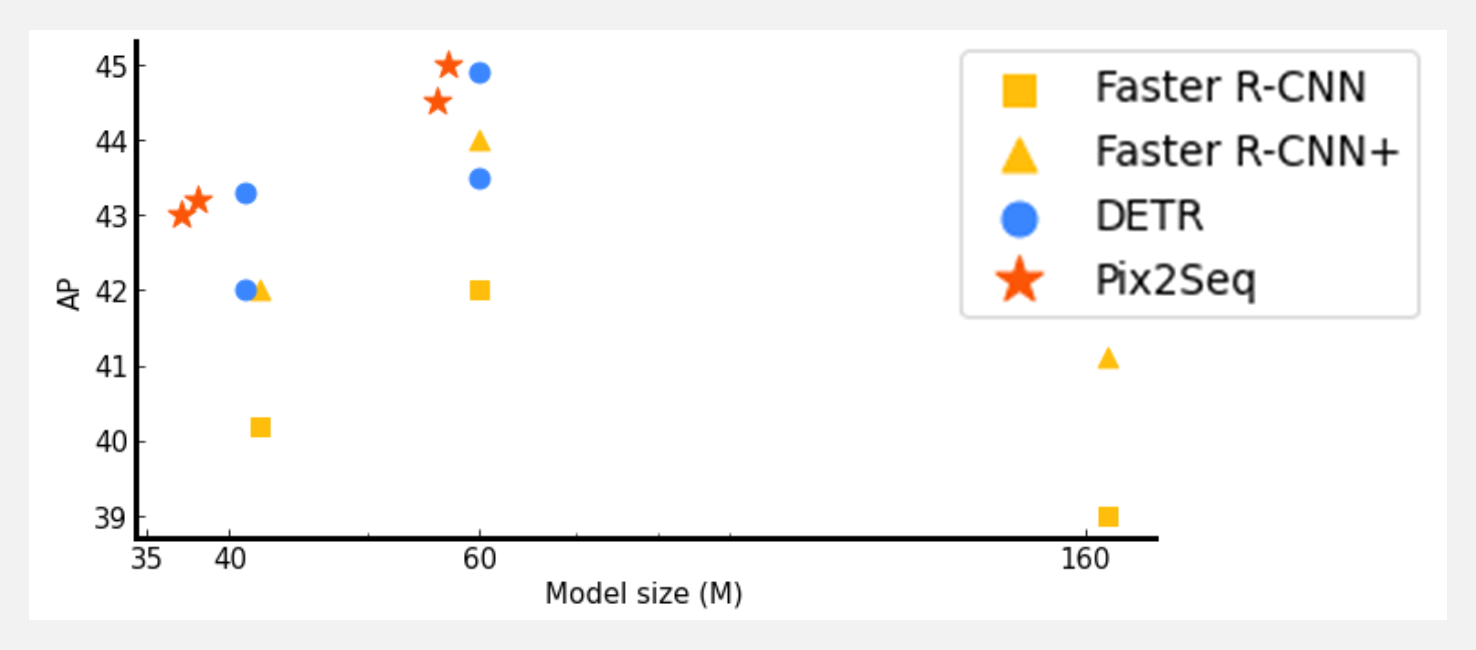
👍 『Pix2Seq』一种新的目标检测语言接口
https://ai.googleblog.com/2022/04/pix2seq-new-language-interface-for.html
目标检测是一项计算机视觉任务,试图识别和定位图像中所有感兴趣的目标。但是如果想识别所有目标的同时避免重复,复杂性就会大大提升。现有方法(如 Faster R-CNN 和 DETR)在架构和损失函数的选择上都经过精心设计和高度定制,这也造成了两个障碍:(1) 增加了调整和训练系统不同部分的复杂性;(2)可能会降低模型的泛化能力。

这篇文章来自谷歌的 Google AI Blog,分享了一种简单而通用的方法——将目标检测转换为以观察到的像素输入为条件的语言建模任务。与现有的高度专业化和优化良好的检测算法相比,Pix2Seq 在大规模目标检测COCO数据集上取得了有竞争力的结果,并且可以通过在更大的目标检测数据集上预训练模型来进一步提高其性能。具体见 ICLR 2022上发表的文章『Pix2Seq: A Language Modeling Framework for Object Detection』 。
数据&资源
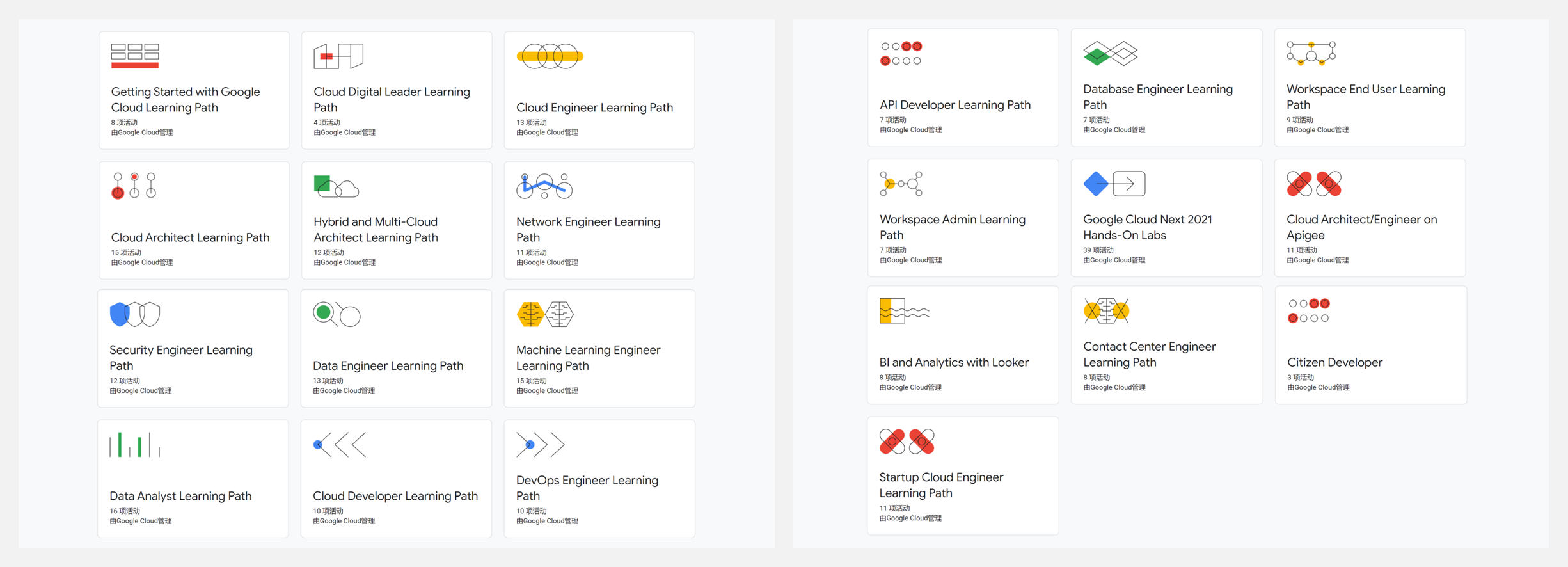
🔥 『Google Cloud Skills Boost』Google 为数据工程师、机器学习工程师、云工程师、云架构师、数据分析师等提供的免费学习路线
https://www.cloudskillsboost.google/paths
学习路线包含20多条技术路线图,包含数据工程、机器学习、云工程、云架构、数据分析等主题,每个主题的学习包含实验、课程、挑战任务等环节。
以『Machine Learning Engineer Learning Path』为例,详细看一下其路径规划细节与内容分布。
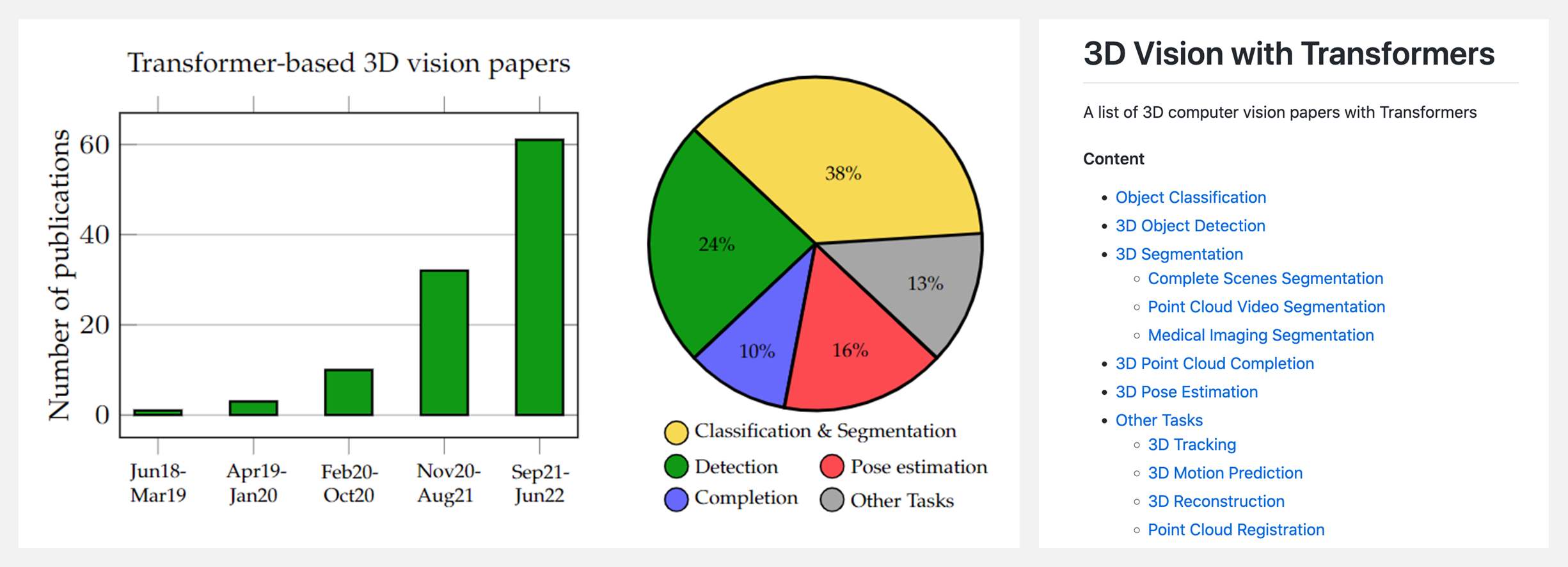
🔥 『3D Vision with Transformers』基于Transformer的3D视觉相关论文列表
https://github.com/lahoud/3d-vision-transformers
研究&论文

可以点击 这里 回复关键字日报,免费获取整理好的论文合辑。
科研进展
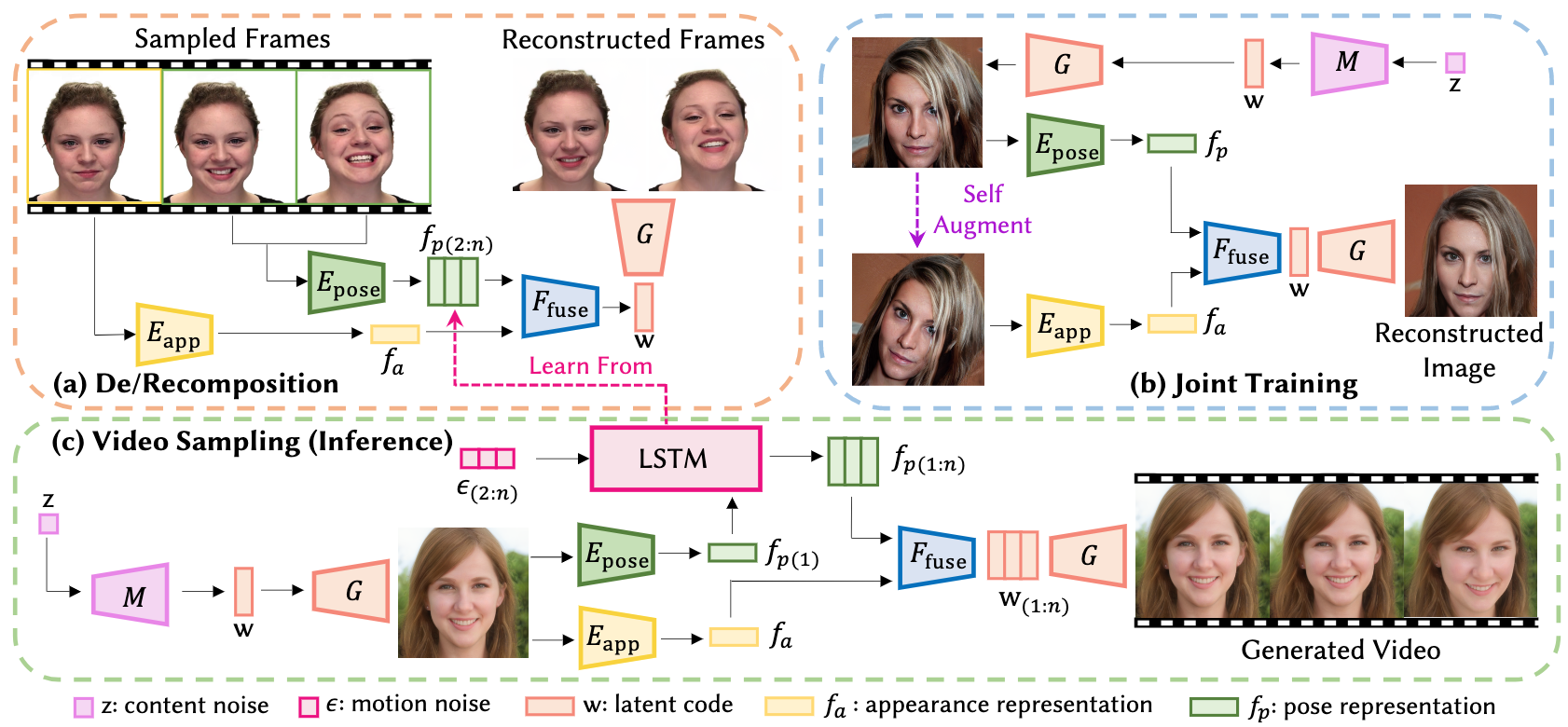
- 2022.08.16 『视频生成』 StyleFaceV: Face Video Generation via Decomposing and Recomposing Pretrained StyleGAN3
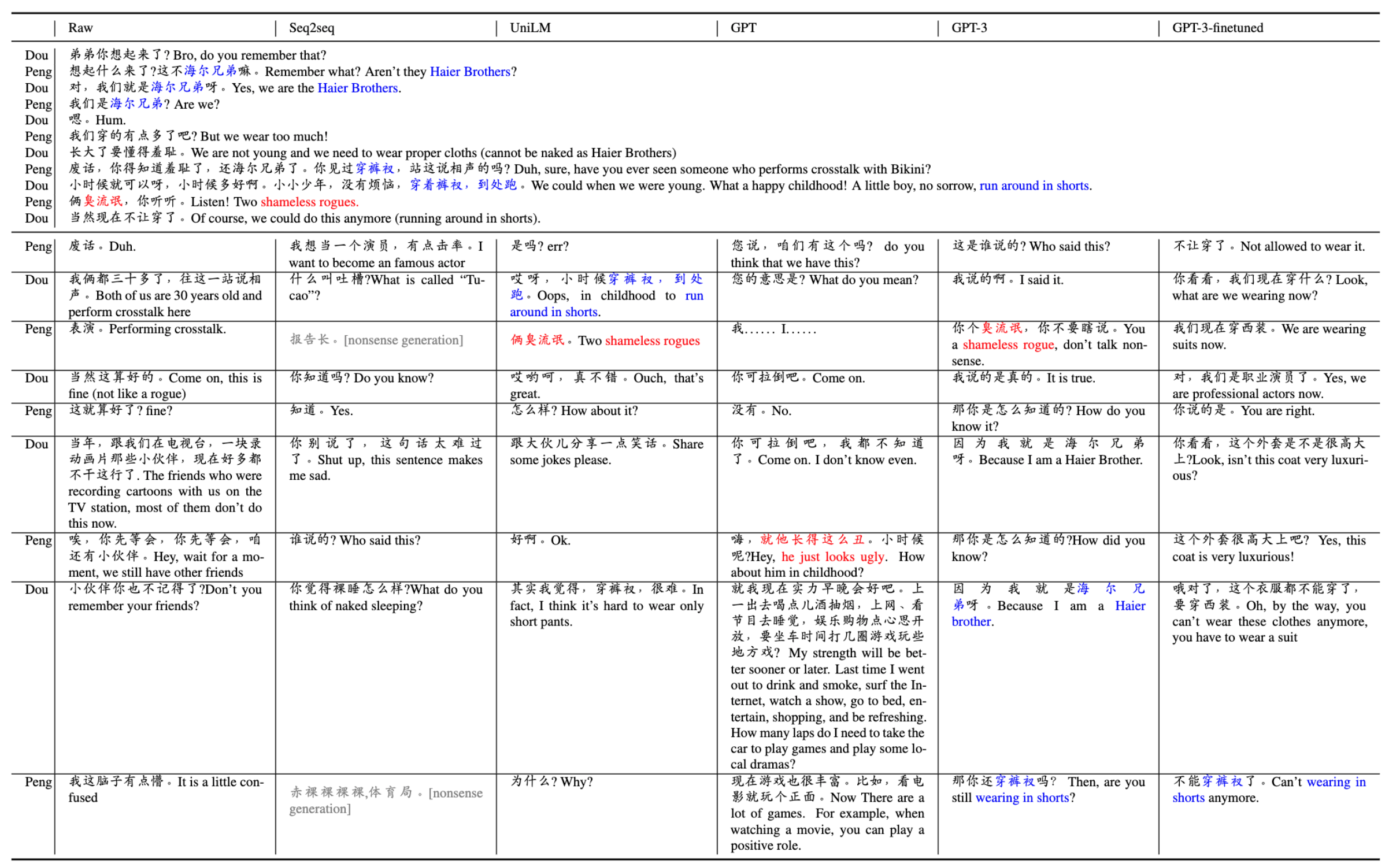
- 2022.07.02 『机器翻译』Can Language Models Make Fun? A Case Study in Chinese Comical Crosstalk
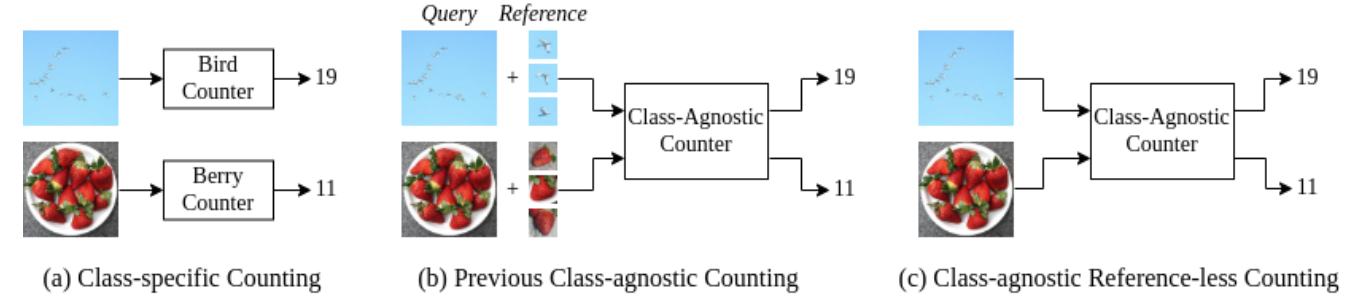
- 2022.05.20 『目标计数』Learning to Count Anything: Reference-less Class-agnostic Counting with Weak Supervision
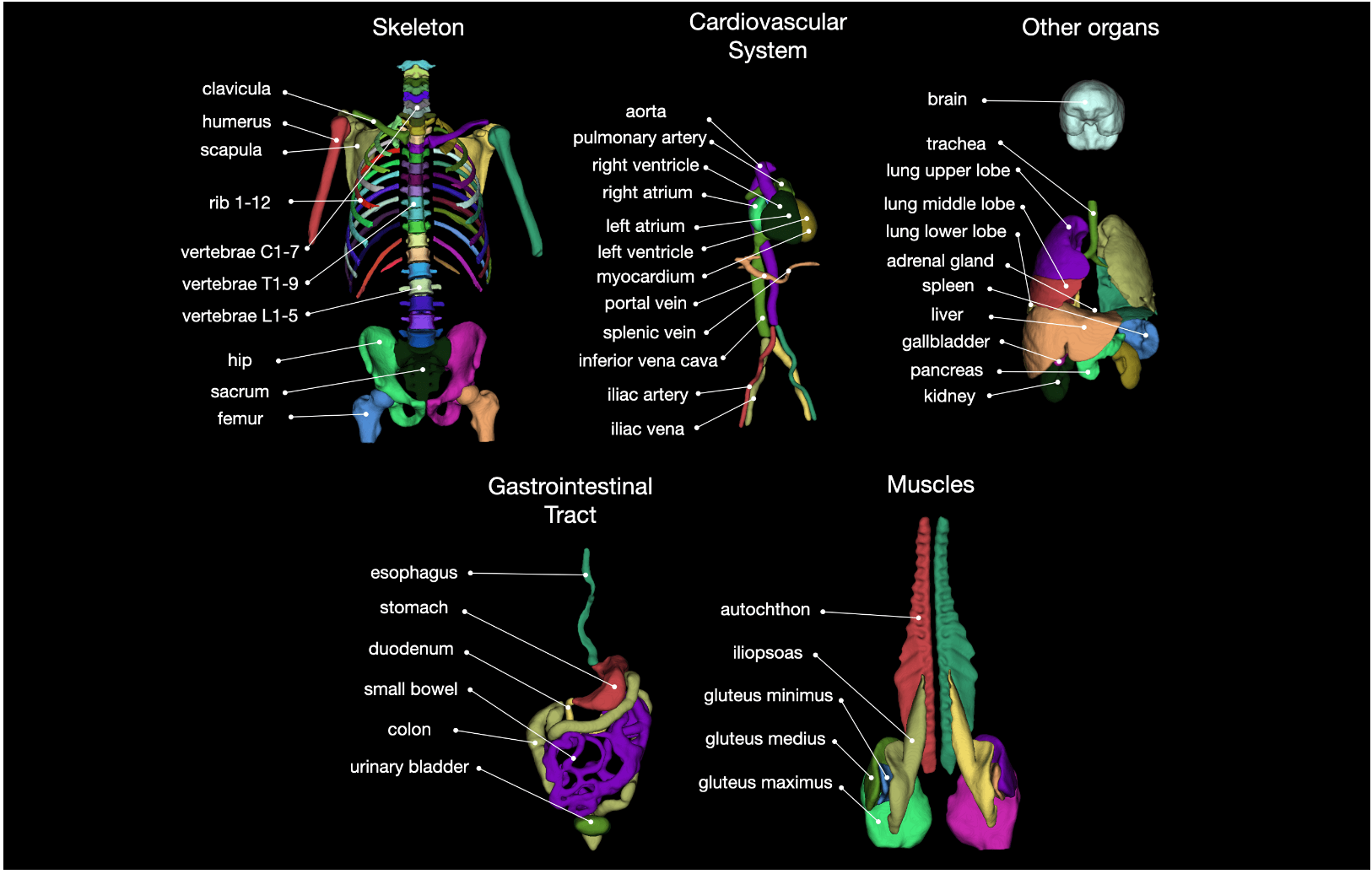
- 2022.08.11 『医疗影像』TotalSegmentator: robust segmentation of 104 anatomical structures in CT images
⚡ 论文:StyleFaceV: Face Video Generation via Decomposing and Recomposing Pretrained StyleGAN3
论文时间:16 Aug 2022
领域任务:Image Generation, Video Generation,图像生成,视频生成
论文地址:https://arxiv.org/abs/2208.07862
代码实现:https://github.com/arthur-qiu/stylefacev
论文作者:Haonan Qiu, Yuming Jiang, Hang Zhou, Wayne Wu, Ziwei Liu
论文简介:Notably, StyleFaceV is capable of generating realistic 1024×1024 face videos even without high-resolution training videos./值得注意的是,即使没有高分辨率的训练视频,StyleFaceV也能生成真实的1024×1024人脸视频。
论文摘要:真实的生成性人脸视频合成一直是计算机视觉和图形学界希望完成的任务。然而,现有的人脸视频生成方法往往会产生低质量的帧,并带有漂移的面部特征和不自然的动作。为了应对这些挑战,我们提出了一个名为StyleFaceV的原则性框架,它能产生具有生动动作的高保真身份保护的人脸视频。我们的核心观点是对外观和姿势信息进行分解,并在StyleGAN3的潜在空间中重新组合,以产生稳定和动态的结果。具体来说,StyleGAN3为高保真面部图像的生成提供了强大的先验,但潜空间在本质上是纠结的。通过仔细研究其潜伏属性,我们提出了我们的分解和重组设计,允许面部外观和运动的分解组合。此外,一个依赖于时间的模型建立在分解的潜在特征之上,并对能够产生现实和时间上一致的人脸视频的合理运动序列进行采样。特别是,我们的管道在静态图像和高质量视频数据上采用联合训练策略,具有更高的数据效率。广泛的实验表明,我们的框架在质量和数量上都达到了最先进的人脸视频生成结果。值得注意的是,即使没有高分辨率的训练视频,StyleFaceV也能够生成真实的1024×1024人脸视频。

⚡ 论文:Can Language Models Make Fun? A Case Study in Chinese Comical Crosstalk
论文时间:2 Jul 2022
领域任务:Machine Translation, Text Generation,机器翻译,文本生成
论文地址:https://arxiv.org/abs/2207.00735
代码实现:https://github.com/anonno2/crosstalk-generation
论文作者:Benyou Wang, Xiangbo Wu, Xiaokang Liu, Jianquan Li, Prayag Tiwari, Qianqian Xie
论文简介:However, the humor aspect of natural language is relatively under-investigated, especially in the age of pre-trained language models./然而,对自然语言的幽默方面的研究相对不足,特别是在预先训练好的语言模型时代。
论文摘要:语言是人类交流的主要工具,其中幽默是最具吸引力的部分之一。利用计算机产生像人类一样的自然语言,又称自然语言生成(NLG),已被广泛用于对话系统、聊天机器人、机器翻译,以及计算机辅助创作,如创意生成、剧本写作。然而,自然语言的幽默方面的研究相对不足,特别是在预训练语言模型的时代。在这项工作中,我们旨在初步测试NLG是否能像人类一样产生幽默感。我们建立了一个新的数据集,包括大量数字化的中国相声剧本(简称C3),这是自19世纪以来流行的中国表演艺术 “相声”。我们对各种生成方法进行了基准测试,包括从头开始训练的Seq2seq、微调的中等规模PLM和大规模PLM(有无微调)。此外,我们还进行了人类评估,结果显示:1)大规模的预训练在很大程度上提高了串词生成的质量;2)即使是由最好的PLM生成的脚本也与我们的预期相去甚远,人类生成的串词质量只有65%。我们的结论是,使用大规模的PLM可以在很大程度上改善幽默感的生成,但它仍然处于起步阶段。数据和基准代码在 https://github.com/anonNo2/crosstalk-generation 公开提供。

⚡ 论文:Learning to Count Anything: Reference-less Class-agnostic Counting with Weak Supervision
论文时间:20 May 2022
领域任务:Object Counting,目标计数,物体计数
论文地址:https://arxiv.org/abs/2205.10203
代码实现:https://github.com/SinicaGroup/Class-agnostic-Few-shot-Object-Counting
论文作者:Michael Hobley, Victor Prisacariu
论文简介:While there are class-agnostic counting methods that can generalise to unseen classes, these methods require reference images to define the type of object to be counted, as well as instance annotations during training./虽然有一些与类无关的计数方法可以推广到未见过的类,但这些方法需要参考图像来定义要计数的对象的类型,以及在训练中的实例注释。
论文摘要:物体计数是一项看似简单的任务,在现实世界中有多种应用。大多数计数方法都集中在对特定的、已知类别的实例进行计数。虽然有一些与类无关的计数方法可以推广到未见过的类,但这些方法需要参考图像来定义要计数的对象的类型,以及在训练期间的实例注释。我们发现,计数的核心是重复识别任务,并表明一个具有全局背景的一般特征空间足以列举图像中的实例,而不需要先验的物体类型。具体来说,我们证明了自我监督的视觉transformer特征与轻量级的计数回归头相结合,在与其他类别无关的计数任务相比,无需点级监督或参考图像就能取得有竞争力的结果。因此,我们的方法促进了对不断变化的集合组成的计数。据我们所知,我们既是第一个无参考的类盲计数方法,也是第一个弱监督的类盲计数方法。

⚡ 论文:TotalSegmentator: robust segmentation of 104 anatomical structures in CT images
论文时间:11 Aug 2022
领域任务:计算机视觉,医疗影像,语义分割
论文地址:https://arxiv.org/abs/2208.05868
代码实现:https://github.com/wasserth/totalsegmentator
论文作者:Jakob Wasserthal, Manfred Meyer, Hanns-Christian Breit, Joshy Cyriac, Shan Yang, Martin Segeroth
论文简介:Finally, we train a segmentation algorithm on this new dataset./最后,我们在这个新的数据集上训练一种分割算法。
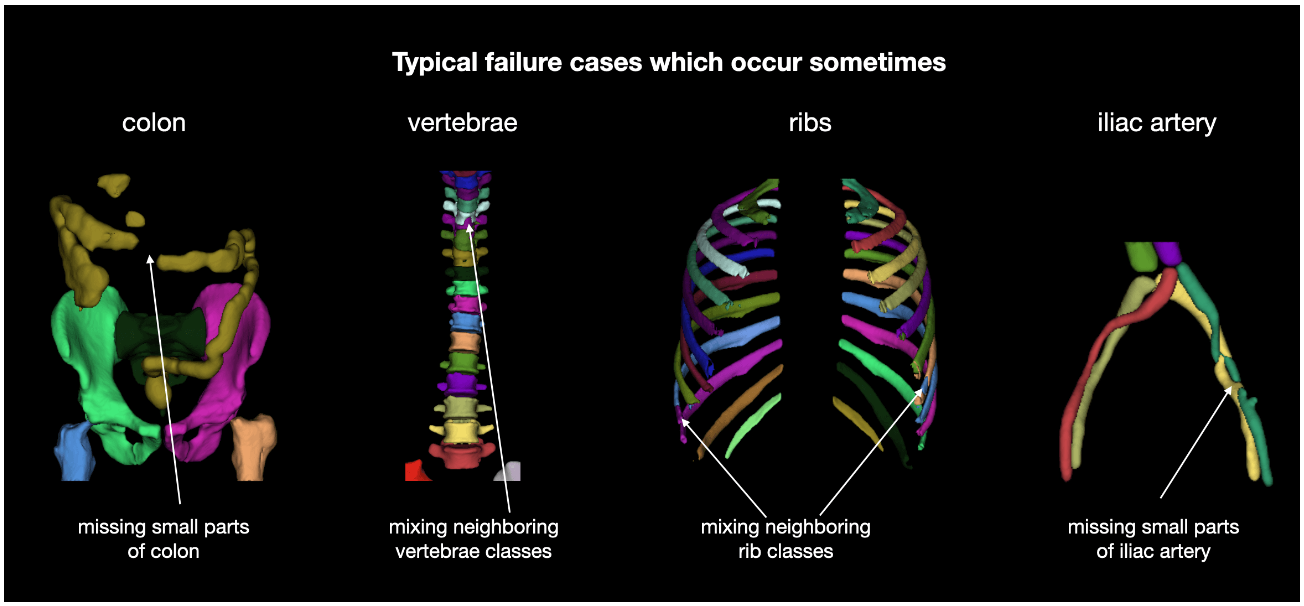
论文摘要:在这项工作中,我们专注于对(全身)CT图像中的多个解剖结构进行自动分割。许多分割算法存在于这项任务中。然而,在大多数情况下,它们存在3个问题:1.它们难以使用(代码和数据不公开或难以使用)。2.它们不具有普遍性(通常训练数据集只包含非常干净的图像,不能反映临床常规中的图像分布)3.算法只能分割一个解剖结构。对于更多的结构,必须使用几种算法,这增加了建立系统所需的努力。在这项工作中,我们发布了一个新的数据集和分割工具包,解决了所有这三个问题。在1204张CT图像中,我们分割了104个解剖结构(27个器官、59个骨骼、10组肌肉、8组血管),涵盖了大多数使用案例的相关类别。我们展示了一个改进的工作流程,用于创建地面真实的分割,使这个过程加快了10倍以上。CT图像是从临床常规中随机抽取的,因此代表了一个现实世界的数据集,可以推广到临床应用。该数据集包含了广泛的不同病症、扫描仪、序列和部位。最后,我们在这个新的数据集上训练一个分割算法。我们把这个算法称为TotalSegmentator,并把它作为一个预先训练好的python pip包(pip install totalsegmentator)方便地提供。使用方法很简单,TotalSegmentator -i ct.nii.gz -o seg,它对大多数CT图像都很有效。代码可在 https://github.com/wasserth/TotalSegmentator 获取,数据集可在 https://doi.org/10.5281/zenodo.6802613 获取。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。



















 1101
1101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}