







工具&框架
🚧 『Lexica』Stable Diffusion 文本生成图像搜索引擎
Lexica 是一个在线文本生成图像检索的平台,包含 500W+ 张由 Stable Diffusion 模型生成的网络图片,仅需输入描述文本语句,就可以查看它相关的网络用户创作艺术图。

以『月亮』为关键词,可以检索到8400余张图片,风格迥异。选了几张放在这里,与大家共赏明月。


🚧 『Stable Diffusion Image Generator』文本图像生成器
https://creator.nightcafe.studio/stable-diffusion-image-generator
Stable Diffusion 是一个先进的AI文本到图像生成器,可以从文本提示中创建令人难以置信的连贯图像,并提供了Matte、Cosmic、Cyberpunk等多种风格可以选择。
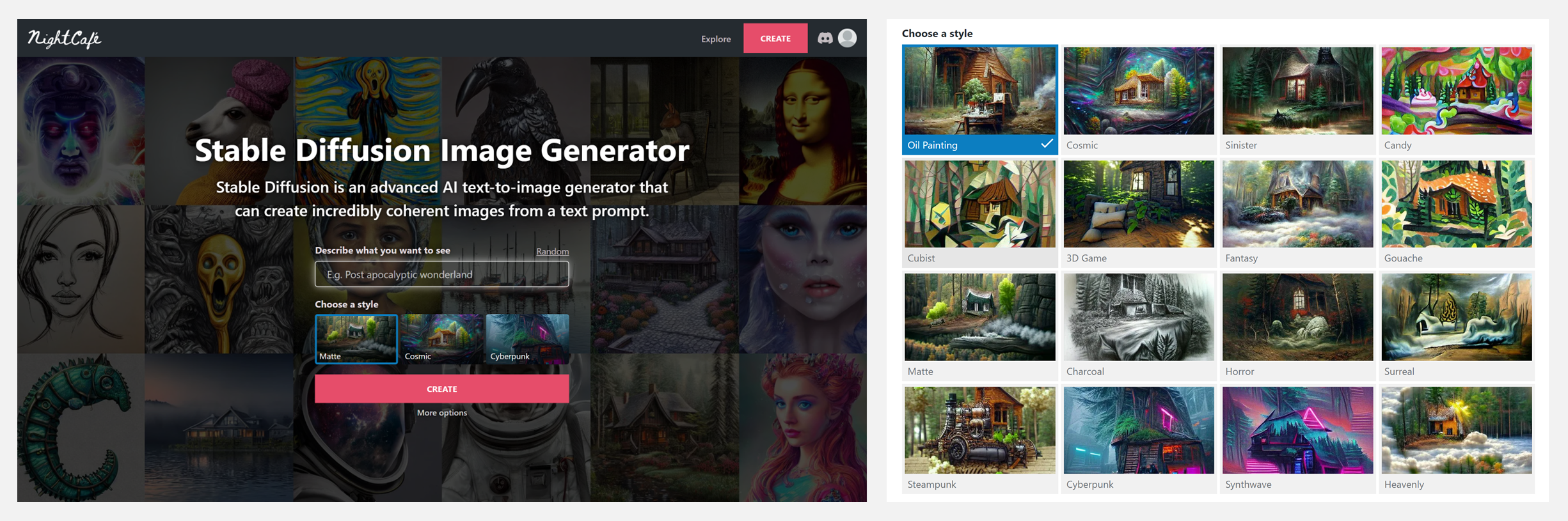
以李白的『静夜思』为提示文字,选择赛博朋克风格,看看AI是如何理解和表达『床前明月光、疑是地上霜。举头望明月,低头思故乡』这首一千三百多年前的古诗的。

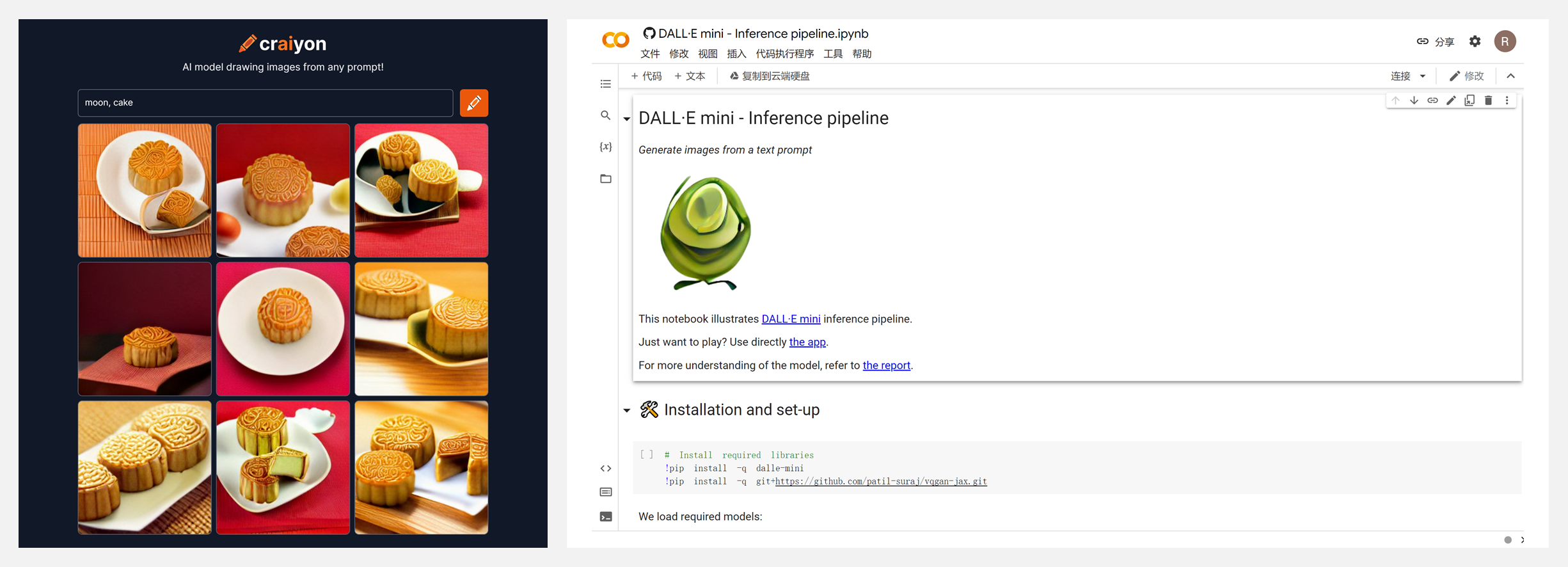
🚧 『DALL·E mini』一个用文本生成图像的项目
https://github.com/borisdayma/dalle-mini
Craiyon(原名DALL·E mini),是一款可以根据任意提示文字进行绘画的AI模型!在网站输入提示文字(这里是『月饼』),等待约2分钟后,系统会生成9张绘制的图片。可以点击某张图片放大观看,也可以使用网站提供的『截图』功能生成卡片。
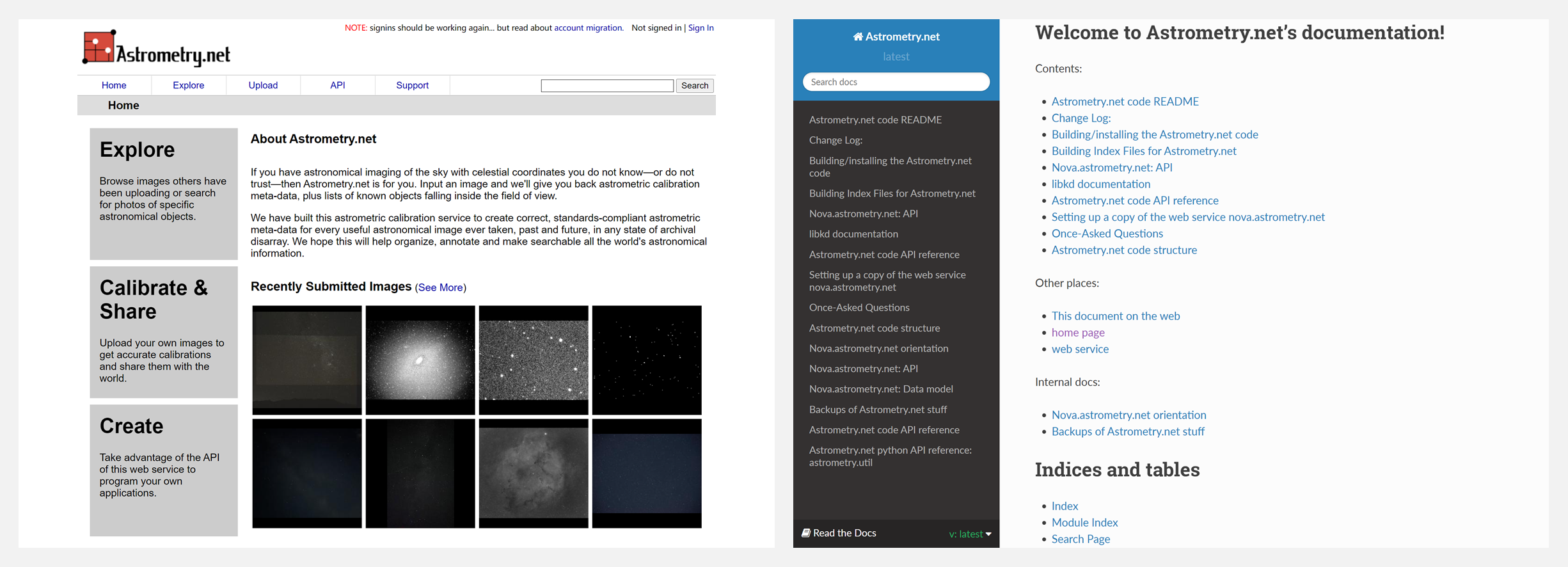
🚧 『Astrometry.net』天体图像自动识别
https://github.com/dstndstn/astrometry.net
astrometry.net 是一个用于天文图像的自动识别的工具,也可以用于从原始数据中抽取符合标准的天体测量元数据。
如果你有天空的天文成像,但不知道或不信任天体坐标,那么在 Astrometry.net 输入一张图像,网站会反馈天体测量校准元数据,以及落在视场内的已知物体清单。
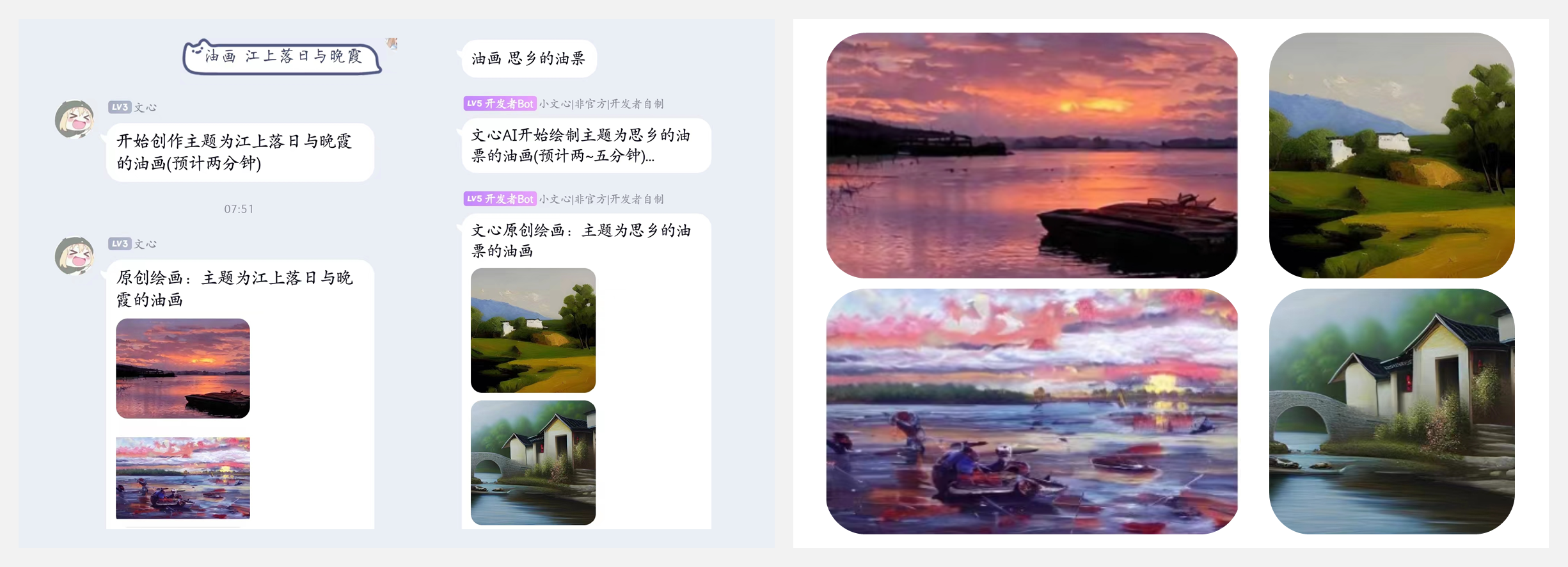
🚧 『nonebot plugin drawer 』基于文心大模型的AI机器人画画插件
https://github.com/CrazyBoyM/nonebot-plugin-drawer
nonebot plugin drawer 是一个基于文心大模型的AI机器人画画插件,通过简单的安装配置后,可以构建一个用于基于文字绘画的自动化应用。看看AI绘画是如何表达『思乡』的!
博文&分享
👍 『Approximation Algorithms』哥本哈根大学·近似算法·Spring 2021课程
https://rasmuspagh.net/courses/APX21/
https://www.designofapproxalgs.com/
课程有大量的数学内容,用来理解和证明算法的良好性能,学习者应该适应这一点。课程假设学生已经完成了一门算法课程,并且能够自如地使用数学证明来分析算法。课程包含以下主题:
- Greedy algorithms and local search / 贪婪算法和局部搜索
- Rounding data and dynamic programming / 舍入数据和动态编程
- Linear programming and deterministic rounding / 线性程序和确定性舍入
- Random sampling and randomized rounding of linear programs / 线性程序的随机抽样和随机舍入
- Randomized rounding of semidefinite programs / 半定约程序的随机舍入
- The primal-dual method / 原始二元法
- The multiway cut problem / 多路切割问题
- Random sampling, priority sampling / 随机抽样、优先抽样
- Cardinality estimation / 心数估计
- Summaries for multisets / 多数据集的总结
- Summaries for ordered data / 有序数据的总结
- Multiplicative weights / 乘法权重
- On-line algorithms / 在线算法

David P. Williamson 和 David B. Shmoys 还初版了『Approximation Algorithms』一书,由剑桥大学出版社出版,电子版获取地址见上方第二个网址。
书籍围绕设计近似算法的几个核心算法技术展开,包括贪婪和局部搜索算法、动态编程、线性和半无限编程以及随机化。本书第一部分的每一章都专门讨论一种算法技术,然后将其应用于几个不同的问题。第二部分重温了这些技术,但对它们进行了更复杂的处理。

数据&资源
🔥 『Awesome AI image synthesis』AI图像合成相关资源大列表
https://github.com/altryne/awesome-ai-art-image-synthesis

研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.07.09 『生成模型』 Improving Diffusion Model Efficiency Through Patching
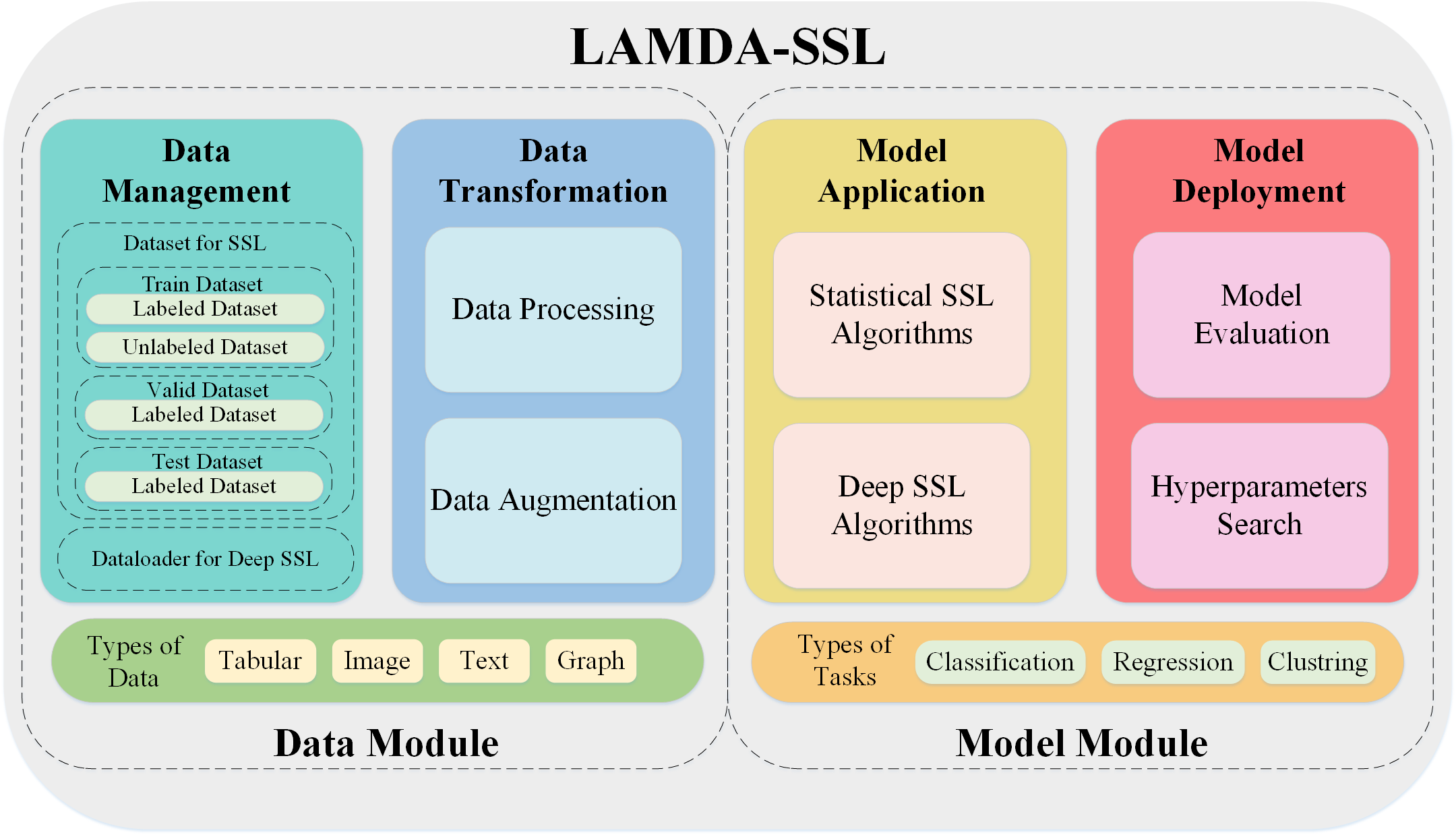
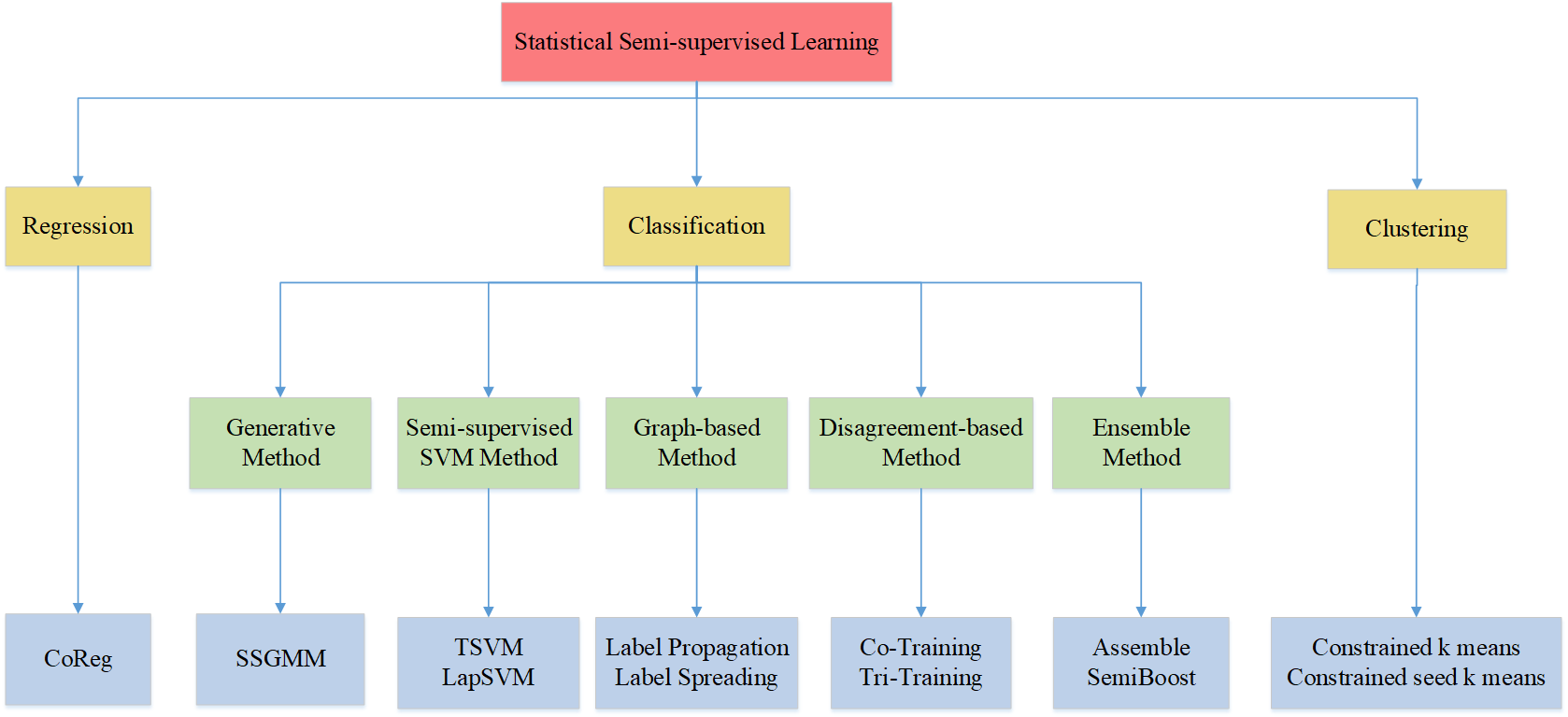
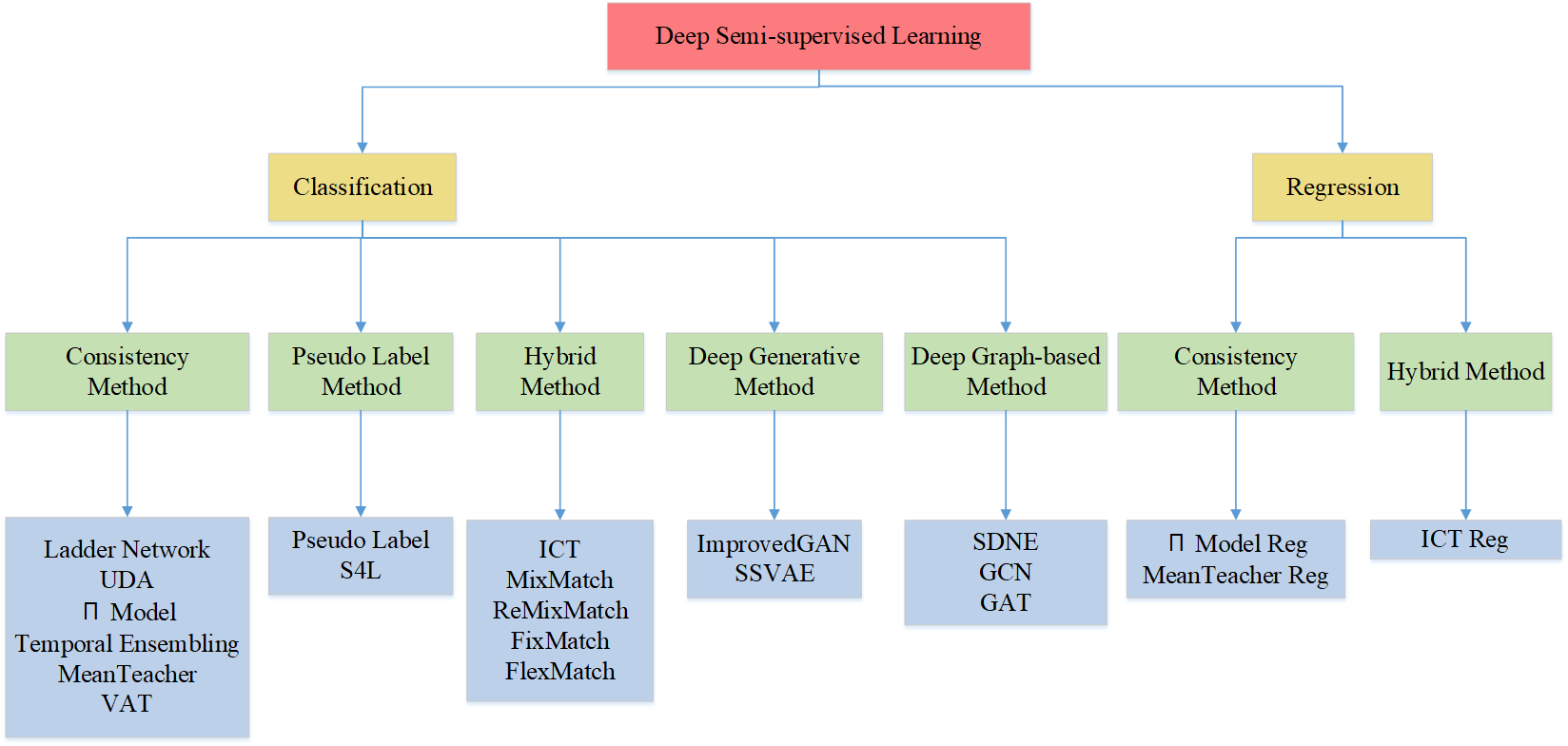
- 2022.08.09 『机器学习』 LAMDA-SSL: Semi-Supervised Learning in Python
- 2022.08.25 『3D点云分类』 Pix4Point: Image Pretrained Transformers for 3D Point Cloud Understanding
⚡ 论文:Improving Diffusion Model Efficiency Through Patching
论文时间:9 Jul 2022
领域任务:计算机视觉,生成模型
论文地址:https://arxiv.org/abs/2207.04316
代码实现:https://github.com/ericl122333/patchdiffusion-pytorch , https://github.com/ericl122333/patchdiffusion-tf , https://github.com/crowsonkb/k-diffusion
论文作者:Troy Luhman, Eric Luhman
论文简介:Diffusion models are a powerful class of generative models that iteratively denoise samples to produce data./扩散模型是一类强大的生成模型,它通过迭代去噪样本来产生数据。
论文摘要:扩散模型是一类强大的生成模型,它通过迭代去噪样本来生成数据。虽然许多工作都关注这个采样过程的迭代次数,但很少有人关注每个迭代的成本。我们发现,添加一个简单的ViT风格的修补转换可以大大减少扩散模型的采样时间和内存使用。我们通过对扩散模型目标的分析,以及对LSUN Church、ImageNet 256和FFHQ 1024的实证实验来证明我们的方法。我们提供了Tensorflow和Pytorch中的实现。

⚡ 论文:LAMDA-SSL: Semi-Supervised Learning in Python
论文时间:9 Aug 2022
领域任务:机器学习
论文地址:https://arxiv.org/abs/2208.04610
代码实现:https://github.com/ygzwqzd/lamda-ssl
论文作者:Lin-Han Jia, Lan-Zhe Guo, Zhi Zhou, Yu-Feng Li
论文简介:The second part shows the usage of LAMDA-SSL by abundant examples in detail./第二部分通过丰富的例子详细介绍了LAMDA-SSL的使用。
论文摘要:LAMDA-SSL在GitHub上是开源的,它的详细使用文档在 https://ygzwqzd.github.io/LAMDA-SSL/ 该文档从多个方面详细介绍了LAMDA-SSL,可以分为四个部分。第一部分介绍了LAMDA-SSL的设计思想、特点和功能。第二部分通过丰富的例子详细介绍了LAMDA-SSL的使用方法。第三部分介绍了LAMDA-SSL实现的所有算法,帮助用户快速了解和选择SSL算法。第四部分展示了LAMDA-SSL的API。这些详细的文档大大降低了用户熟悉LAMDA-SSL工具包和SSL算法的成本。
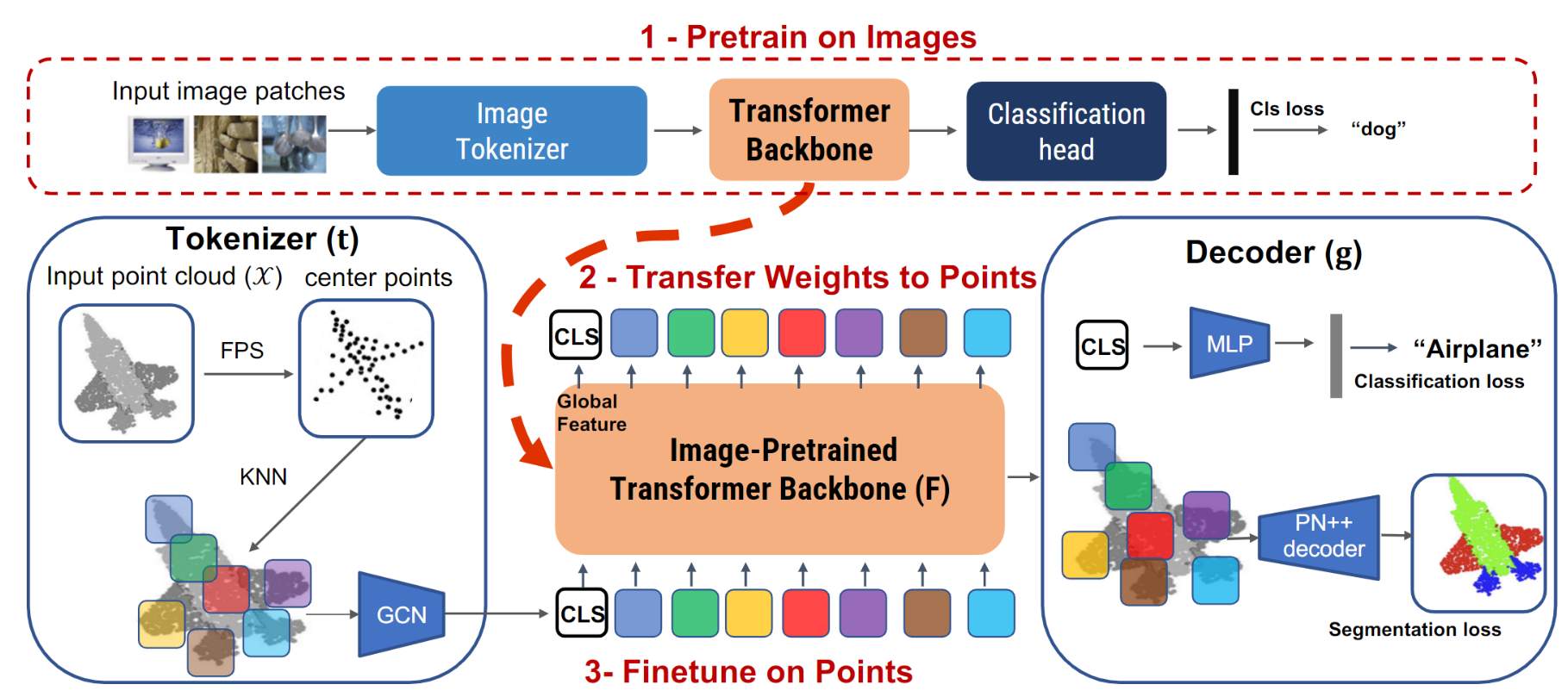
⚡ 论文:Pix4Point: Image Pretrained Transformers for 3D Point Cloud Understanding
论文时间:25 Aug 2022
领域任务:3D Point Cloud Classification, Natural Language Processing, 3D点云分类
论文地址:https://arxiv.org/abs/2208.12259
代码实现:https://github.com/guochengqian/pix4point
论文作者:Guocheng Qian, Xingdi Zhang, Abdullah Hamdi, Bernard Ghanem
论文简介:In the realm of 3D point clouds, the availability of large datasets is a challenge, which exacerbates the issue of training Transformers for 3D tasks./在三维点云领域,大型数据集的可用性是一个挑战,这加剧了为三维任务训练Transformers的问题。
论文摘要:纯Transformer模型在自然语言处理和计算机视觉方面取得了令人印象深刻的成功。然而,Transformer的一个限制是它们需要大量的训练数据。在三维点云领域,大型数据集的可用性是一个挑战,这加剧了为三维任务训练Transformer的问题。在这项工作中,我们实证研究并调查了利用大量图像的知识来理解点云的效果。我们制定了一个被称为Pix4Point的管道,允许利用图像域中预训练的变形器来改善下游的点云任务。这是通过一个与模式无关的纯转化器主干,以及在三维领域专门的标记器和解码器层的帮助下实现的。使用图像解释的Transformer,我们观察到Pix4Point在三维点云分类、部件分割和语义分割等任务上的显著性能提升,这些任务分别在ScanObjectNN、ShapeNetPart和S3DIS基准上进行。我们的代码和模型见 https://github.com/guochengqian/Pix4Point

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。



















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}