







一、k-近邻算法概述
1、算法介绍
k-近邻算法(K-Nearest Neighbors,简称KNN)是一种用于分类和回归的统计方法。KNN 可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一。
2、算法原理
k-近邻算法基于某种距离度量来找到输入样本在训练集中的k个最近邻居,并且根据这k个邻居的属性来预测输入样本的属性。

比如我们的输入样本是图中的蓝色,那么k个近邻就是距离绿色小圆最近的k个邻居,然后在这k个邻居中,若黑色小圆的数量多于红色小圆,那么输入样本的属性就与蓝黑色小圆相同,反之则与红色小圆的属性相同,这就是k-近邻算法的算法思想。
3、KNN算法中常用的距离指标
在knn算法中怎样计算输入点与其他向量点之间的距离呢?这里就用到了两种距离公式。
欧几里得距离
欧几里得距离是我们在平面几何中最常用的距离计算方法,即两点之间的直线距离。
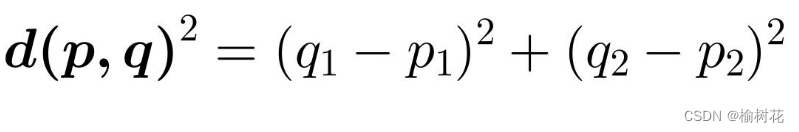
曼哈顿距离
曼哈顿距离是计算两点在一个网格上的路径距离,与上述的直线距离不同,它只允许沿着网格的水平和垂直方向移动。
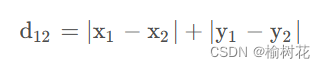
4、算法优缺点
优点:
- 准确度较高:K近邻算法准确度较高为它可以适应不同的数据分布。
- 适用性广泛:K近邻算法可用于分类和回归问题,同时也支持多分类和多回归问题。
- 实现简单:K近邻算法的实现非常简单,特别适用于初学者学习模式识别的入门算法
缺点:
- 计算复杂度高:当数据集很大时,计算距离的时间和空间开销都会很大,影响算法执行效率。
- 受样本分布影响大:K近邻算法对训练集中样本的密度很敏感,对于密度相差很大的数据集,分类精度会受到较大影响。
- 数据不平衡问题:当训练集中某些类别的样本数目远远大于其他类别的样本数目时,K近邻算法的准确度会明显下降。
5、算法流程
1、准备数据集:
收集数据集,包括特征与对应的类别标签
对数据进行预处理,例如数据清洗、归一化等。
2、选择k值:
选择一个合适的k值,即确定最近邻居的个数。
3、选择距离度量方法
确定用于比较样本之间相似性的度量方法,常见的如欧几里得距离、曼哈顿距离等。
4、确定最近邻居
选择与待分类样本距离最近的k个训练样本
5、预测
对于分类任务:查看K个最近邻居中最常见的类别,作为预测结果。
对于回归任务:预测结果可以是K个最近邻居的平均值或加权平均值。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2305
2305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









