







对于DML主要是进行数据库操作使用的语法,在DML之中一共分为两类:查询、更行,对于查询应该已经是了解完其所有基本概念了,而对于更新操作,也是意见非常重要的功能。但是在讲解更行操作之前,为了保证 emp 表中的数据不被破坏。
范例: 将 emp 表复制为 myemp 表,输入以下的命令完成。
CREATE TABLE myemp AS SELECT * FROM emp;
可以发现现在 myemp 表之中所存在的数据与 emp 完全相似,马上要进行的所有的更新操作都要围绕这个 myemp 表进行。对于更新操作主要是分为三类:增加、修改、删除。
1.1、增加数据
如果要为数据表之中增加一条数据,则可以使用如下操作语法完成:
INSERT INTO 表名称 [(字段1,字段2,.....)] VALUES(值1,值2,....); 但是此处需要注意一点的就是数据类型的设置问题:
· 字符串(VARCHAR2):使用 “” 声明,例如:’你好’;
· 数字(NUMBER):直接使用,例如:123;
· 日期(DATE):有三种方式设置:
| - 按照已有的日期格式(17-9 月 - 16), 编写字符串,此时的字符串可以自动变为 DATE;
| - 可以直接使用 SYSDATE 设置为当前的日期时间;
| - 可以使用 TO_DATE() 函数,将一个字符串变为 DATE 型数据。
范例:向 myemp 表之中增加一条新的记录:
· 使用完整语法,写上要增加的字段名称
INSERT INTO myemp(empno,ename,hiredate,mgr,job,sal,comm,deptno)
VALUES(9999,'张三',TO_DATE('1889-09-12','yyyy-mm-dd'),7369,'清洁工',5000,3000,40);· 使用简便语法,不写上要增加数据的字段名称,证明编写数据的顺序要和表字段的顺序一致。
INSERT INTO myemp VALUES(9999,'李四','清洁工',7369,TO_DATE('1889-09-12','yyyy-mm-dd'),5000,3000,40);在以后的任何开发中,都建议编写完整语法,对于简便语法由于其在项目维护的时候难度太高,所以都不肯能去使用。
如果说现在要增加的某些字段的内容为 NULL 的话,也有两种方式可以设置:
· 方式一:直接设置 NULL
INSERT INTO myemp(empno,ename,hiredate,mgr,job,sal,comm,deptno)
VALUES(7777,'王速',NULL,NULL,'清洁工',5000,3000,NULL);· 方式二:不设置内容的字段不写
INSERT INTO myemp(empno,ename,job,sal,comm)
VALUES(6666,'王速','清洁工',5000,3000); 如果设置 NULL,建议使用第二种方式完成,这样比较直观。
1.2、修改数据
如果发现已有的数据需要更新,那么可以通过一下语法完成:
UPDATE 表名称 SET 字段1=值1,字段2=值2,.... [WHERE 更新条件(s)];在更新条件的编写上可以使用之前所给出的限定查询的所有判断方式。
范例:要求将 ALLEN 的工资修改为2000,奖金修改为300,位置修改为 SALESMAN
UPDATE myemp SET sal=2000,comm=300,job='SALESMAN' WHERE ename='ALLEN';范例: 将部门20中的雇员的工资增长 20%
UPDATE myemp SET sal=sal*1.2 WHERE deptno=20;范例: 将低于公司平均工资的雇员工资修改为公司的平均工资
UPDATE myemp SET sal=(SELECT AVG(sal) FROM myemp)
WHERE sal<(SELECT AVG(sal) FROM myemp);范例: 将所有雇员工资修改为 NULL,既然是更新的是全部数据,那么肯定不再需要 WHERE 子句
UPDATE myemp SET sal=NULL;1.3、删除操作
当数据表之中的数据不再使用时,那么就可以进行删除操作,删除操作的语法如下:
DELETE FROM 表名称 [WHERE 删除条件(s)];范例: 删除雇员编号是 7566 和 7902 的雇员信息。
DELETE FROM myemp WHERE empno IN(7566,7902);范例: 删除高于公司平均工资的雇员
DELETE FROM myemp WHERE sal>(SELECT AVG(sal) FROM myemp);范例: 删除表中的全部数据
DELETE FROM myemp;当然,在实际工作之中,删除表中全部记录是不可能出现的功能。
2.1、事物处理
在DML之中的更新与查询两种操作里,很明显查询操作会更加的安全,那么也就意味着,更新是一件非常危险的事情,那么会有着怎样的危险呢?
下面模拟这样一个场景,更新操作如下:
A、 从杨X的帐户上减少2000W;
B、 本人的帐户上增加2000W; -> 出现了错误
C、 本人给郭X汇款6000;
D、 郭X还杨X3000;
E、 收取手续费50元。
以上的操作把它理解为一个完整的操作业务,这个业务应该是一个整体,如果说本业务之中,B操作出现了问题,那么A、C、D、E是否应该继续?
那么为了保证所有的数据都是具备完整性的,所以在Oracle数据库之中提供了一种事务处理的概念:所谓的事务指的是一组更新操作,要么一起成功,要么一起失败。
在Oracle数据库里面把每一个连接到数据库上的用户,都称为一个SESSION,即:一个数据库上会有多个SESSION连接,每一个SESSION都将具备自己的独立的事务处理能力,针对于每一个SESSION都会提供两个操作命令:
- 事务提交:COMMIT;
- 事务回滚:ROLLBACK;
由于每一个SESSION拥有独立的事务,所以当用户针对于数据表发出的更新更新操作后,实际上这些操作并不会立刻影响到原始数据,而是将所有的更新命令保存在一个缓冲区之中,如果发现此时更新有问题,则可以利用ROLLBACK回滚,如果发现此时的数据更新没有问题,则可以使用 COMMIT 真正提交;
当然,在事务处理操作过程之中也会存在一个问题:如果说现在不同的SESSION更新同一条数据呢?
当一个SESSION更新一条数据的时候,在未提交之前,其他的SESSION是不允许更新此条数据的,需要等待。
3.1、两个重要的伪列
在之前学习过了一个SYSDATE的伪列,但是在Oracle之中还有两个最为重要的伪列,ROWNUM、ROWID。
3.1.1、 ROWNUM
ROWNUM表示一个行编号,这个是在查询时自动分配的数据。
范例: 观察 ROWNUM
SELECT ROWNUM,empno,ename,job,hiredate,sal,comm,deptno FROM emp;所有的 ROWNUM 都是动态生成的。每一个 ROWNUM 和数据不是绝对性的对应关系。
范例: 继续观察 ROWNUM
SELECT ROWNUM,empno,ename,job,hiredate,sal,comm,deptno
FROM emp WHERE deptno=20;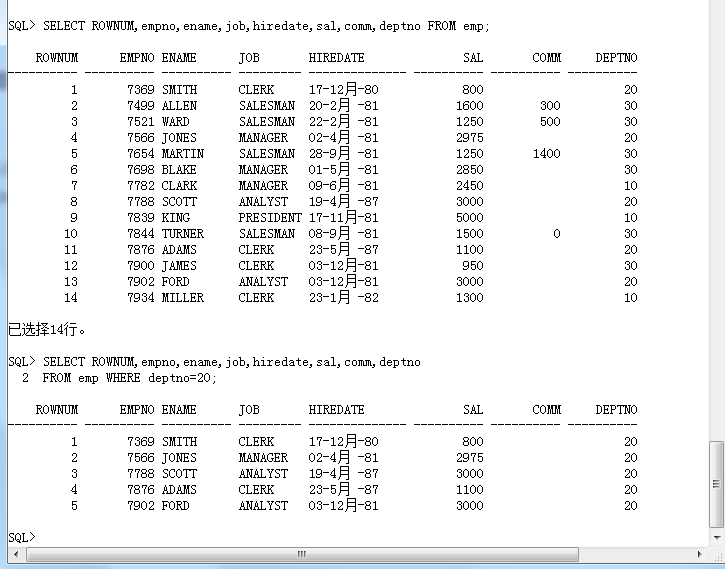
在 Oracle 之中,ROWNUM 可以做两件事情:
· 可以取得第一行数据;
· 可以取得前N行数据。
范例: 取得第一行数据
SELECT ROWNUM,empno,ename,job,hiredate,sal,comm,deptno
FROM emp WHERE ROWNUM=1;范例: 取得前三行数据
SELECT ROWNUM,empno,ename,job,hiredate,sal,comm,deptno
FROM emp WHERE ROWNUM<=3;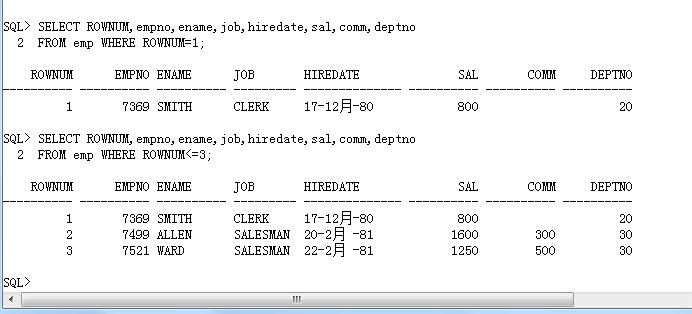
范例: 取得 4~6 行数据
应该习惯性的做法是做一个范围的验证,使用 BETWEEN AND
SELECT ROWNUM , empno ,ename ,job,hiredate,sal,comm,deptno
FROM emp WHERE ROWNUM BETWEEN 4 AND 6 ; 语法上感觉没问题
这个时候没有任何的数据返回,因为 ROWNUM 是随机生成的,不是生来就有的。
如果想要解决这个问题只能够利用子查询完成,首先查询出前6行记录,而后再查询出后3行记录。
SELECT ROWNUM rn , empno ,ename ,job,hiredate,sal,comm,deptno
FROM emp WHERE ROWNUM <= 6 ; 以上返回的是一个多行多列的数据,而且发现 ROWNUM 是以一个列的形式存在的,既然是列的形式存在,就可以直接进行操作,在外部套一个子查询。
SELECT *
FROM (
SELECT ROWNUM rn, empno ,ename ,job,hiredate,sal,comm,deptno
FROM emp WHERE ROWNUM <= 6) temp
WHERE temp.rn>3;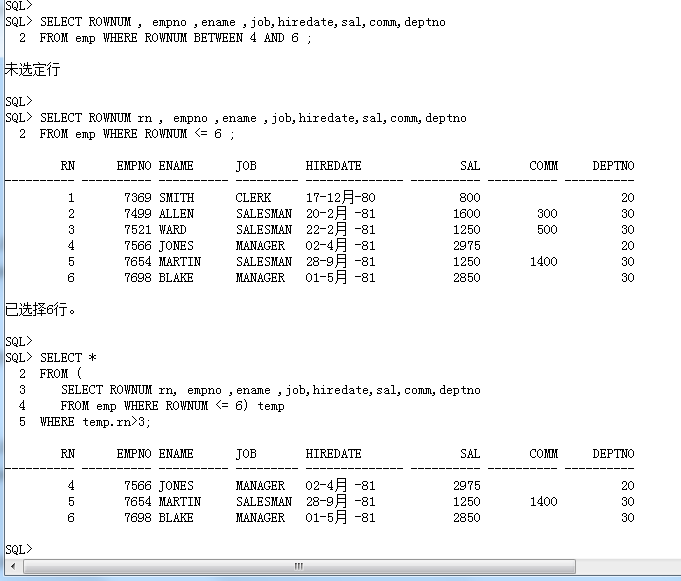
范例:要求显示7~9条记录
SELECT *
FROM (
SELECT ROWNUM rn, empno ,ename ,job,hiredate,sal,comm,deptno
FROM emp WHERE ROWNUM <= 9) temp
WHERE temp.rn>6;范例:要求显示1~3条记录
SELECT *
FROM (
SELECT ROWNUM rn, empno ,ename ,job,hiredate,sal,comm,deptno
FROM emp WHERE ROWNUM <= 3) temp
WHERE temp.rn>0; 通过以上的操作可以发现,当进行数据的部分显示的时候实际上控制的只是两个数字,那么现在回归到程序开发思路之中:
• 如果现在在第1页(currentPage = 1),每页显示3条记录(lineSize = 3):
SELECT *
FROM ( SELECT ROWNUM rn , empno ,ename ,job,hiredate,sal,comm,deptno
FROM emp WHERE ROWNUM<=3) temp currentPage * lineSize
WHERE temp.rn>0; (currentPage - 1) * lineSize
• 如果现在在第3页(currentPage = 3),每页显示3条记录(lineSize = 3):
SELECT *
FROM ( SELECT ROWNUM rn , empno ,ename ,job,hiredate,sal,comm,deptno
FROM emp WHERE ROWNUM<=9) temp currentPage * lineSize
WHERE temp.rn>6; (currentPage - 1) * lineSize
所以,根据以上的分析,可以得出一下分页显示结构语法:
SELECT *
FROM ( SELECT ROWNUM rn , 字段 [别名]
FROM 表名称 WHERE ROWNUM<=(currentPage * lineSize)) temp
WHERE temp.rn>(currentPage-1)*lineSize;
Oracle和DB2的分页利用ROWNUM完成,SQL Server利用TOP完成,MySQL利用LIMIT完成。
3.1.2、 ROWID
ROWID 实际上是指一条数据对应的物理存储(磁盘上保存)地址,用户可以直接查询 ROWID。
范例:观察ROWID
SELECT ROWID,deptno,dname,loc FROM dept;
每个数据的 ROWID是 100% 不可能重复的,以其中一个ROWID(AAAR3qAAEAAAACHAAA)举例进行说明:
• 数据对象号:AAAR3q;
• 相对文件号:AAE;
• 数据块号:AAAACH;
• 数据对应的行号:AAA。
面试题:请删除掉表中的重复记录,重复记录只保留一条
首先为了方便,将dept表复制一份为mydept表。
CREATE TABLE mydept AS SELECT * FROM dept;由于此数据表的维护不力,导致表中出现了大量的重复数据,为了模拟重复数据,下面编写几条增加操作:
INSERT INTO mydept(deptno,dname,loc) VALUES(10,'ACCOUNTING','NEW YORK') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(10,'ACCOUNTING','NEW YORK') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(10,'ACCOUNTING','NEW YORK') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(10,'ACCOUNTING','NEW YORK') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(10,'ACCOUNTING','NEW YORK') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(20,'RESEARCH','DALLAS') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(20,'RESEARCH','DALLAS') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(20,'RESEARCH','DALLAS') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(30,'SALES','CHICAGO') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(30,'SALES','CHICAGO') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(30,'SALES','CHICAGO') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(30,'SALES','CHICAGO') ;
INSERT INTO mydept(deptno,dname,loc) VALUES(30,'SALES','CHICAGO') ;
COMMIT ;随后观察现在mydep表中的记录:
SELECT ROWID,deptno,dname,loc FROM mydept; 很明显,现在的数据要保留一个,如果要保留肯定是保留最早增加的数据。删除数据肯定使用DELETE语句完成,但是DELETE语句之中需要删除的条件设置,关键就在于此条件该如何设置。
下面换一个思路,查询出所有最早设置的数据是什么?
SELECT deptno,dname,loc,MIN(ROWID)
FROM mydept
GROUP BY deptno,dname,loc ;以上的数据肯定是要保留的数据,那么既然已经知道了要保留的数据,只要删除时不在此范围内的全部删除即可。
DELETE FROM mydept
WHERE ROWID NOT IN (
SELECT MIN(ROWID)
FROM mydept
GROUP BY deptno,dname,loc) ;
ROWID不管数据是否重复,都可以唯一的标记一行数据。















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









