






hive基础命令实验
环境 centos7 Hadoop2.6.5 hive 1.x
一. 从普通文本加载数据到hive仓库
1.使用 命令hive 进入hive命令行;
2.创建数据库 create database if not exists hivetest;
3.切换数据库 use hivetest;

4. 创建表
create table if not exists student(
id bigint,
name String
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; —每行数据的字段是用tab(\t)来区分
//lines terminated by ‘\n’ –每条数据用换行区分
//stored as textfile;

4.创建要导入的数据文件
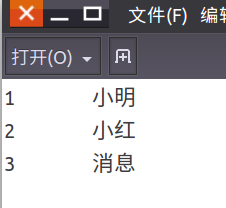
我在/home/hadoop放了一个student文件,文件内容(注意字段之间的空格不能用空格键输入,要用退格键输入!)
1 小明
2 小红
3 消息
5.把student文件(打开文件属性查看具体路径)的数据导入数据到hive
LOAD DATA LOCAL INPATH '/home/hadoop/hadoop/student' INTO TABLE student;(这是本地加载数据)
实验结果:
Loading data to table hivetest.student
OK
Time taken: 0.788 seconds
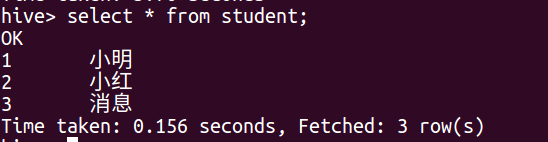
hive> select * from student;
OK
1 小明
2 小红
3 消息
NULL NULL
Time taken: 0.203 seconds, Fetched: 4 row(s)

还可以加载HDFS上的。
先把student文件存储到hdfs上。
[root@localhost data]# hdfs dfs -put /home/hadoop/hadoop/student /user/hadoop
[root@localhost data]# hdfs dfs -ls /
Found 5 items
drwxr-xr-x - root supergroup 0 2018-06-23 19:05 /hdfsapi
-rw-r–r– 1 root supergroup 34 2018-06-19 23:00 /hello.txt
-rw-r–r– 1 root supergroup 28 2018-07-14 13:30 /student
drwx-wx-wx - root supergroup 0 2018-07-11 21:29 /tmp
drwxr-xr-x - root supergroup 0 2018-07-12 23:36 /user
hadoop@dblab-VirtualBox:~$ hdfs dfs -cat /user/hadoop/student
1 小明
2 小红
3 消息

然后把HDFS的数据导入到hive中
hive>use hivetest;
hive> create table if not exists student2(
id bigint,
name String
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';

hive>LOAD DATA INPATH '/user/hadoop/student' INTO TABLE student2;
Loading data to table hivetest.student2
OK
Time taken: 1.05 seconds
hive> select * from student2;
OK
1 小明
2 小红
3 消息
Time taken: 0.434 seconds, Fetched: 3 row(s)

也可以采用插入语句插入记录:
hive> insert into student2(id,name) values(1,'testname1');
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20181021123554_3cf0588b-583f-4f3e-8b55-6a4219005a73
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2018-10-21 12:35:56,763 Stage-1 map = 100%, reduce = 0%
Ended Job = job_local780735299_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://localhost:9000/user/hive/warehouse/hivetest.db/student/.hive-staging_hive_2018-10-21_12-35-54_285_2598622894927685139-1/-ext-10000
Loading data to table hivetest.student
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 209 HDFS Write: 110 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 2.885 seconds
hive> select * from student;
OK
1 testname1
1 小明
2 小红
3 消息
Time taken: 1.252 seconds, Fetched: 10 row(s)















 4826
4826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









