







这篇文章将使用NLTK向您解释NLP中的词性标注 (POS-Tagging)和组块分析(Chunking)过程。词袋模型(Bag-of-Words)无法捕捉句子的结构,有时也无法给出适当的含义。词性标注和组块分析帮助我们克服了这个弱点。
NLTK多用于英文文本,所以这篇以英文解释。

词性标注(POS-Tagging)
词性可以解释为一个词在句子中的使用方式。词性有八个主要组成部分:名词、代词、形容词、动词、副词、介词、连词和感叹词。

- Noun (N)- Daniel, London, table, dog, teacher, pen, city, happiness, hope
- Verb (V)- go, speak, run, eat, play, live, walk, have, like, are, is
- Adjective(ADJ)- big, happy, green, young, fun, crazy, three
- Adverb(ADV)- slowly, quietly, very, always, never, too, well, tomorrow
- Preposition §- at, on, in, from, with, near, between, about, under
- Conjunction (CON)- and, or, but, because, so, yet, unless, since, if
- Pronoun(PRO)- I, you, we, they, he, she, it, me, us, them, him, her, this
- Interjection (INT)- Ouch! Wow! Great! Help! Oh! Hey! Hi!

词性标注是一种监督学习解决方案,它使用前一个单词,下一个单词,首字母大写等功能.NLTK具有获取词性标注的功能,并且在断句分词(Tokenization)过程之后开始处理单词词性。
import nltk
sentence = "My name is Jocelyn"
token = nltk.word_tokenize(sentence) #分词
token
结果:
['My', 'name', 'is', 'Jocelyn']
------------------------华丽分割线--------------------
nltk.pos_tag(token) #词性标注
结果:
[('My', 'PRP$'), ('name', 'NN'), ('is', 'VBZ'), ('Jocelyn', 'NNP')]
------------------------华丽分割线--------------------
# We can get more details about any POS tag using help funciton of NLTK as follows.
nltk.help.upenn_tagset("PRP$")
结果:
PRP$: pronoun, possessive
her his mine my our ours their thy your
------------------------华丽分割线--------------------
nltk.help.upenn_tagset("NN")
结果:
NN: noun, common, singular or mass
common-carrier cabbage knuckle-duster Casino afghan shed thermostat
investment slide humour falloff slick wind hyena override subhumanity
machinist ...
最流行的标签集是Penn Treebank标签集。大多数已经训练过的英语标签都是在这个标签上训练的。要查看完整列表,请使用此链接。
组块分析(Chunking)
组块分析是从非结构化文本中提取短语的过程。相对于POS-Tagging来说,POS-Tagging返回了解析树的最底层,就是一个个单词。但是有时候你需要的是几个单词构成的名词短语,而非个个单词,在这种情况下,您可以使用chunker获取您需要的信息,而不是浪费时间为句子生成完整的解析树。举个例子(中文):与其要单个字,不如要一个词,例如,将“南非”之类的短语作为一个单独的词,而不是分别拆成“南”和“非”去理解。
组块分析是可以接着词性标注工作继续完成,它使用词性标注作为输入,并提供分析好的组块做为输出。与词性标注的标签类似,它也有一组标准的组块标签,如名词短语(np)、动词短语(vp)等,当你想从诸如位置,人名等文本中提取信息时,分块是非常重要的。在NLP中,称为命名实体识别,举个例子‘李雷的杯子’是分块分出的一个短语,而抽取’李雷’这个人名,就是命名体识别。所以,组块分析也是命名体识别的基础。
有很多库提供现成的短语,如spacy或textblob。NLTK只是提供了一种使用正则表达式生成块的机制。为了创建NP块(名词模式),我们将使用一个正则表达式规则来定义分块的语法。通常我们认为,一个名词词组由一个可选的限定词(dt),后跟任意数量的形容词(jj),然后是一个名词(nn),那么它就应该是名词短语NP(Noun Phrase)区块。
# Example of a simple regular expression based NP chunker.
import nltk
sentence = "the little yellow dog barked at the cat"
#Define your grammar using regular expressions#Define
grammar = ('''
NP: {<DT>?<JJ>*<NN>} # NP
''')
chunkParserchunkPar = nltk.RegexpParser(grammar)
tagged = nltk.pos_tag(nltk.word_tokenize(sentence))
tagged
结果:
[('the', 'DT'),
('little', 'JJ'),
('yellow', 'JJ'),
('dog', 'NN'),
('barked', 'VBD'),
('at', 'IN'),
('the', 'DT'),
('cat', 'NN')]
------------------------华丽分割线--------------------
tree = chunkParser.parse(tagged)
for subtree in tree.subtrees():
print(subtree)
结果:
(S
(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBD
at/IN
(NP the/DT cat/NN))
(NP the/DT little/JJ yellow/JJ dog/NN)
(NP the/DT cat/NN)
------------------------华丽分割线--------------------
tree.draw()
结果:
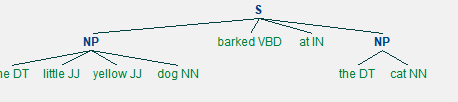
POS-Tagging和Chunking就大概介绍完了。深入理解还要多做实验。
还可以参看下面两个链接:
https://stackoverflow.com/questions/8998979/what-is-the-difference-between-pos-tagging-and-shallow-parsing
https://stackoverflow.com/questions/1598940/in-natural-language-processing-what-is-the-purpose-of-chunking
(简单总结下关系:就是拿英文文本,先断句分词,接着去除停用词,再词性标注,接着组块分析,接着命名体识别。大体就是这个关系,有时候词性标注是非必须的,也可以不标注,看具体情况)















 116
116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









