







来源:NLP中的 POS Tagging 和Chunking_Sirow的博客-CSDN博客_pos tagging
词性标注(POS-Tagging)
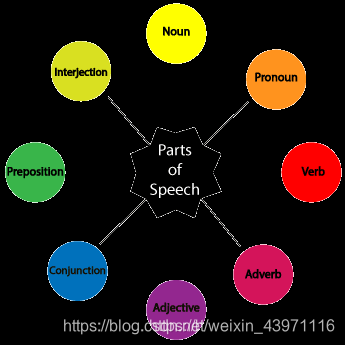
这里的例子主要针对英文,词性标注的作用便是给输入的句子的每个单词分割开然后去除功能词,再给每一个单词标注他们的词性,词性有八个主要组成部分:名词、代词、形容词、动词、副词、介词、连词和感叹词。
例子:
- Noun (N)- Daniel, London, table, dog, teacher, pen, city, happiness, hope
- Verb (V)- go, speak, run, eat, play, live, walk, have, like, are, is
- Adjective(ADJ)- big, happy, green, young, fun, crazy, three
- Adverb(ADV)- slowly, quietly, very, always, never, too, well, tomorrow
- Preposition §- at, on, in, from, with, near, between, about, under
- Conjunction (CON)- and, or, but, because, so, yet, unless, since, if
- Pronoun(PRO)- I, you, we, they, he, she, it, me, us, them, him, her, this
- Interjection (INT)- Ouch! Wow! Great! Help! Oh! Hey! Hi!
例如下面例子中,输入 She sells seashells on the seashore. 则输出每个词对应的词性。
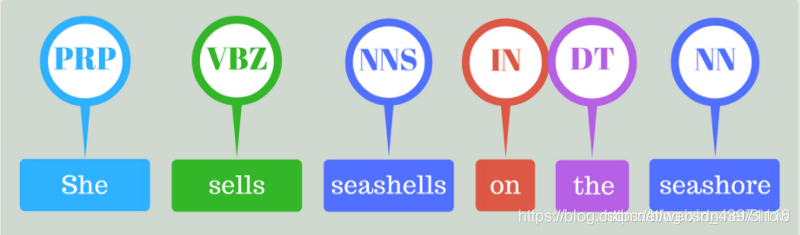
在python中有最流行的标签集,Penn Treebank标签集。大多数已经训练过的英文标签都是在这个标签集上训练的。
组块分析(Chunking)
组块分析就是从非结构化的文本中提取短语的过程。相对于POS-Tagging来说,POS-Tagging返回了解析树的最底层,就是一个个单词。但是有时候你需要的是几个单词构成的名词短语,而非个个单词,在这种情况下,您可以使用chunker获取您需要的信息,而不是浪费时间为句子生成完整的解析树。举个例子(中文):与其要单个字,不如要一个词,例如,将“南非”之类的短语作为一个单独的词,而不是分别拆成“南”和“非”去理解。
组块分析是可以接着词性标注工作继续完成,它使用词性标注作为输入,并提供分析好的组块做为输出。与词性标注的标签类似,它也有一组标准的组块标签,如名词短语(np)、动词短语(vp)等,当你想从诸如位置,人名等文本中提取信息时,分块是非常重要的。在NLP中,称为命名实体识别,举个例子‘李雷的杯子’是分块分出的一个短语,而抽取’李雷’这个人名,就是命名体识别。所以,组块分析也是命名体识别的基础。
(将句子生成如下面一样的树,既是在树中的每一层代表着不同的层次语义,然后可以通过语句输出)
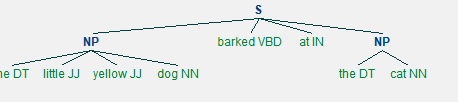
总结:
输入句子 -> 将每个词分割开 -> 去除停用词如<CLS> -> 进行词性标注 -> 进行组块分析 -> 命名实体识别

















 1512
1512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









