







M.1 — Introduction to smart pointers and move semantics
Even if you do remember to delete ptr at the end of the function, there are a myriad of ways that ptr may not be deleted if the function exits early.
At heart, these kinds of issues occur because pointer variables have no inherent mechanism to clean up after themselves.
Smart pointer classes to the rescue?
Such a class is called a smart pointer. A Smart pointer is a composition class that is designed to manage dynamically allocated memory and ensure that memory gets deleted when the smart pointer object goes out of scope. (Relatedly, built-in pointers are sometimes called “dumb pointers” because they can’t clean up after themselves).
Now let’s go back to our someFunction() example above, and show how a smart pointer class can solve our challenge:
#include <iostream>
template <typename T>
class Auto_ptr1
{
T* m_ptr;
public:
// Pass in a pointer to "own" via the constructor
Auto_ptr1(T* ptr=nullptr)
:m_ptr(ptr)
{
}
// The destructor will make sure it gets deallocated
~Auto_ptr1()
{
delete m_ptr;
}
// Overload dereference and operator-> so we can use Auto_ptr1 like m_ptr.
T& operator*() const { return *m_ptr; }
T* operator->() const { return m_ptr; }
};
// A sample class to prove the above works
class Resource
{
public:
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
void sayHi() { std::cout << "Hi!\n"; }
};
void someFunction()
{
Auto_ptr1<Resource> ptr(new Resource()); // ptr now owns the Resource
int x;
std::cout << "Enter an integer: ";
std::cin >> x;
if (x == 0)
return; // the function returns early
// do stuff with ptr here
ptr->sayHi();
}
int main()
{
someFunction();
return 0;
}
If the user enters a non-zero integer, the above program will print:
Resource acquired
Hi!
Resource destroyed
If the user enters zero, the above program will terminate early, printing:
Resource acquired
Resource destroyed
Note that even in the case where the user enters zero and the function terminates early, the Resource is still properly deallocated.
Because the ptr variable is a local variable, ptr will be destroyed when the function terminates (regardless of how it terminates). And because the Auto_ptr1 destructor will clean up the Resource, we are assured that the Resource will be properly cleaned up.
A critical flaw
Move semantics
What if, instead of having our copy constructor and assignment operator copy the pointer (“copy semantics”), we instead transfer/move ownership of the pointer from the source to the destination object? This is the core idea behind move semantics. Move semantics means the class will transfer ownership of the object rather than making a copy.
Let’s update our Auto_ptr1 class to show how this can be done:
#include <iostream>
template <typename T>
class Auto_ptr2
{
T* m_ptr;
public:
Auto_ptr2(T* ptr=nullptr)
:m_ptr(ptr)
{
}
~Auto_ptr2()
{
delete m_ptr;
}
// A copy constructor that implements move semantics
Auto_ptr2(Auto_ptr2& a) // note: not const
{
m_ptr = a.m_ptr; // transfer our dumb pointer from the source to our local object
a.m_ptr = nullptr; // make sure the source no longer owns the pointer
}
// An assignment operator that implements move semantics
Auto_ptr2& operator=(Auto_ptr2& a) // note: not const
{
if (&a == this)
return *this;
delete m_ptr; // make sure we deallocate any pointer the destination is already holding first
m_ptr = a.m_ptr; // then transfer our dumb pointer from the source to the local object
a.m_ptr = nullptr; // make sure the source no longer owns the pointer
return *this;
}
T& operator*() const { return *m_ptr; }
T* operator->() const { return m_ptr; }
bool isNull() const { return m_ptr == nullptr; }
};
class Resource
{
public:
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
};
int main()
{
Auto_ptr2<Resource> res1(new Resource());
Auto_ptr2<Resource> res2; // Start as nullptr
std::cout << "res1 is " << (res1.isNull() ? "null\n" : "not null\n");
std::cout << "res2 is " << (res2.isNull() ? "null\n" : "not null\n");
res2 = res1; // res2 assumes ownership, res1 is set to null
std::cout << "Ownership transferred\n";
std::cout << "res1 is " << (res1.isNull() ? "null\n" : "not null\n");
std::cout << "res2 is " << (res2.isNull() ? "null\n" : "not null\n");
return 0;
}
This program prints:
Resource acquired
res1 is not null
res2 is null
Ownership transferred
res1 is null
res2 is not null
Resource destroyed
Note that our overloaded operator= gave ownership of m_ptr from res1 to res2! Consequently, we don’t end up with duplicate copies of the pointer, and everything gets tidily cleaned up.
A reminder
Deleting a nullptr is okay, as it does nothing.
std::auto_ptr, and why it was a bad idea
Now would be an appropriate time to talk about std::auto_ptr. std::auto_ptr, introduced in C++98 and removed in C++17, was C++’s first attempt at a standardized smart pointer. std::auto_ptr opted to implement move semantics just like the Auto_ptr2 class does.
However, std::auto_ptr (and our Auto_ptr2 class) has a number of problems that makes using it dangerous.
First, because std::auto_ptr implements move semantics through the copy constructor and assignment operator, passing a std::auto_ptr by value to a function will cause your resource to get moved to the function parameter (and be destroyed at the end of the function when the function parameters go out of scope). Then when you go to access your auto_ptr argument from the caller (not realizing it was transferred and deleted), you’re suddenly dereferencing a null pointer. Crash!
Second, std::auto_ptr always deletes its contents using non-array delete. This means auto_ptr won’t work correctly with dynamically allocated arrays, because it uses the wrong kind of deallocation. Worse, it won’t prevent you from passing it a dynamic array, which it will then mismanage, leading to memory leaks.
Finally, auto_ptr doesn’t play nice with a lot of the other classes in the standard library, including most of the containers and algorithms. This occurs because those standard library classes assume that when they copy an item, it actually makes a copy, not a move.
Because of the above mentioned shortcomings, std::auto_ptr has been deprecated in C++11 and removed in C++17.
Moving forward
The core problem with the design of std::auto_ptr is that prior to C++11, the C++ language simply had no mechanism to differentiate “copy semantics” from “move semantics”. Overriding the copy semantics to implement move semantics leads to weird edge cases and inadvertent bugs. For example, you can write res1 = res2 and have no idea whether res2 will be changed or not!
Because of this, in C++11, the concept of “move” was formally defined, and “move semantics” were added to the language to properly differentiate copying from moving. Now that we’ve set the stage for why move semantics can be useful, we’ll explore the topic of move semantics throughout the rest of this chapter. We’ll also fix our Auto_ptr2 class using move semantics.
In C++11, std::auto_ptr has been replaced by a bunch of other types of “move-aware” smart pointers: std::unique_ptr, std::weak_ptr, and std::shared_ptr. We’ll also explore the two most popular of these: unique_ptr (which is a direct replacement for auto_ptr) and shared_ptr.
M.2 — R-value references
L-value references recap

L-value references to const objects can be initialized with modifiable and non-modifiable l-values and r-values alike. However, those values can’t be modified.

L-value references to const objects are particularly useful because they allow us to pass any type of argument (l-value or r-value) into a function without making a copy of the argument.
R-value references
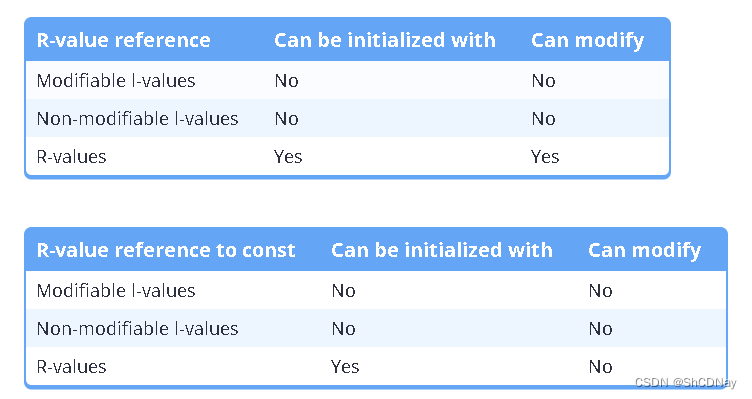
C++11 adds a new type of reference called an r-value reference. An r-value reference is a reference that is designed to be initialized with an r-value (only). While an l-value reference is created using a single ampersand, an r-value reference is created using a double ampersand:
int x{ 5 };
int& lref{ x }; // l-value reference initialized with l-value x
int& &rref{ 5 }; // r-value reference initialized with r-value 5
R-values references cannot be initialized with l-values.
#include <iostream>
class Fraction
{
private:
int m_numerator;
int m_denominator;
public:
Fraction(int numerator = 0, int denominator = 1) :
m_numerator{ numerator }, m_denominator{ denominator }
{
}
friend std::ostream& operator<<(std::ostream& out, const Fraction& f1)
{
out << f1.m_numerator << '/' << f1.m_denominator;
return out;
}
};
int main()
{
auto&& rref{ Fraction{ 3, 5 } }; // r-value reference to temporary Fraction
// f1 of operator<< binds to the temporary, no copies are created.
std::cout << rref << '\n';
return 0;
} // rref (and the temporary Fraction) goes out of scope here
#include <iostream>
int main()
{
int&& rref{ 5 }; // because we're initializing an r-value reference with a literal, a temporary with value 5 is created here
rref = 10;
std::cout << rref << '\n';
return 0;
}
R-value references are not very often used in either of the manners illustrated above.
R-value references as function parameters
R-value references are more often used as function parameters. This is most useful for function overloads when you want to have different behavior for l-value and r-value arguments.
#include <iostream>
void fun(const int &lref) // l-value arguments will select this function
{
std::cout << "l-value reference to const: " << lref << '\n';
}
void fun(int &&rref) // r-value arguments will select this function
{
std::cout << "r-value reference: " << rref << '\n';
}
int main()
{
int x{ 5 };
fun(x); // l-value argument calls l-value version of function
fun(5); // r-value argument calls r-value version of function
return 0;
}
This prints:
l-value reference to const
r-value reference
As you can see, when passed an l-value, the overloaded function resolved to the version with the l-value reference. When passed an r-value, the overloaded function resolved to the version with the r-value reference (this is considered a better match than a l-value reference to const).
Why would you ever want to do this? We’ll discuss this in more detail in the next lesson. Needless to say, it’s an important part of move semantics.
Rvalue reference variables are lvalues
Consider the following snippet:
int&& ref{ 5 };
fun(ref);
Which version of fun would you expect the above to call: fun(const int&) or fun(int&&)?
The answer might surprise you. This calls fun(const int&).
Although variable ref has type int&&, when used in an expression it is an lvalue (as are all named variables). The type of an object and its value category are independent.
You already know that literal 6 is an rvalue of type int, and int x is an lvalue of type int. Similarly, int&& ref is an lvalue of type int&&.
So not only does fun(ref) call fun(const int&), it does not even match fun(int&&), as rvalue references can’t bind to lvalues.
Returning an r-value reference
You should almost never return an r-value reference, for the same reason you should almost never return an l-value reference. In most cases, you’ll end up returning a hanging reference when the referenced object goes out of scope at the end of the function.
M.3 — Move constructors and move assignment
Recapping copy constructors and copy assignment
#include <iostream>
template<typename T>
class Auto_ptr3
{
T* m_ptr;
public:
Auto_ptr3(T* ptr = nullptr)
:m_ptr(ptr)
{
}
~Auto_ptr3()
{
delete m_ptr;
}
// Copy constructor
// Do deep copy of a.m_ptr to m_ptr
Auto_ptr3(const Auto_ptr3& a)
{
m_ptr = new T;
*m_ptr = *a.m_ptr;
}
// Copy assignment
// Do deep copy of a.m_ptr to m_ptr
Auto_ptr3& operator=(const Auto_ptr3& a)
{
// Self-assignment detection
if (&a == this)
return *this;
// Release any resource we're holding
delete m_ptr;
// Copy the resource
m_ptr = new T;
*m_ptr = *a.m_ptr;
return *this;
}
T& operator*() const { return *m_ptr; }
T* operator->() const { return m_ptr; }
bool isNull() const { return m_ptr == nullptr; }
};
class Resource
{
public:
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
};
Auto_ptr3<Resource> generateResource()
{
Auto_ptr3<Resource> res{new Resource};
return res; // this return value will invoke the copy constructor
}
int main()
{
Auto_ptr3<Resource> mainres;
mainres = generateResource(); // this assignment will invoke the copy assignment
return 0;
}
When this program is run, it prints:
Resource acquired
Resource acquired
Resource destroyed
Resource acquired
Resource destroyed
Resource destroyed
However, with move semantics, we can do better.
Move constructors and move assignment
When are the move constructor and move assignment called?
The move constructor and move assignment are called when those functions have been defined, and the argument for construction or assignment is an r-value. Most typically, this r-value will be a literal or temporary value.
Implicit move constructor and move assignment
The compiler will create an implicit move constructor and move assignment operator if all of the following are true:
- There are no user-declared copy constructors or copy assignment operators.
- There are no user-declared move constructors or move assignment operators.
- There is no user-declared destructor.
The key insight behind move semantics
You now have enough context to understand the key insight behind move semantics.
If we construct an object or do an assignment where the argument is an l-value, the only thing we can reasonably do is copy the l-value. We can’t assume it’s safe to alter the l-value, because it may be used again later in the program. If we have an expression “a = b” (where b is an lvalue), we wouldn’t reasonably expect b to be changed in any way.
However, if we construct an object or do an assignment where the argument is an r-value, then we know that r-value is just a temporary object of some kind. Instead of copying it (which can be expensive), we can simply transfer its resources (which is cheap) to the object we’re constructing or assigning. This is safe to do because the temporary will be destroyed at the end of the expression anyway, so we know it will never be used again!
C++11, through r-value references, gives us the ability to provide different behaviors when the argument is an r-value vs an l-value, enabling us to make smarter and more efficient decisions about how our objects should behave.
Move functions should always leave both objects in a valid state
In the above examples, both the move constructor and move assignment functions set a.m_ptr to nullptr. This may seem extraneous – after all, if a is a temporary r-value, why bother doing “cleanup” if parameter a is going to be destroyed anyway?
The answer is simple: When a goes out of scope, the destructor for a will be called, and a.m_ptr will be deleted. If at that point, a.m_ptr is still pointing to the same object as m_ptr, then m_ptr will be left as a dangling pointer. When the object containing m_ptr eventually gets used (or destroyed), we’ll get undefined behavior.
When implementing move semantics, it is important to ensure the moved-from object is left in a valid state, so that it will destruct properly (without creating undefined behavior).
Automatic l-values returned by value may be moved instead of copied
In the generateResource() function of the Auto_ptr4 example above, when variable res is returned by value, it is moved instead of copied, even though res is an l-value. The C++ specification has a special rule that says automatic objects returned from a function by value can be moved even if they are l-values. This makes sense, since res was going to be destroyed at the end of the function anyway! We might as well steal its resources instead of making an expensive and unnecessary copy.
Although the compiler can move l-value return values, in some cases it may be able to do even better by simply eliding the copy altogether (which avoids the need to make a copy or do a move at all). In such a case, neither the copy constructor nor move constructor would be called.
Disabling copying
In the Auto_ptr4 class above, we left in the copy constructor and assignment operator for comparison purposes. But in move-enabled classes, it is sometimes desirable to delete the copy constructor and copy assignment functions to ensure copies aren’t made. In the case of our Auto_ptr class, we don’t want to copy our templated object T – both because it’s expensive, and whatever class T is may not even support copying!
Here’s a version of Auto_ptr that supports move semantics but not copy semantics:
#include <iostream>
template<typename T>
class Auto_ptr5
{
T* m_ptr;
public:
Auto_ptr5(T* ptr = nullptr)
:m_ptr(ptr)
{
}
~Auto_ptr5()
{
delete m_ptr;
}
// Copy constructor -- no copying allowed!
Auto_ptr5(const Auto_ptr5& a) = delete;
// Move constructor
// Transfer ownership of a.m_ptr to m_ptr
Auto_ptr5(Auto_ptr5&& a) noexcept
: m_ptr(a.m_ptr)
{
a.m_ptr = nullptr;
}
// Copy assignment -- no copying allowed!
Auto_ptr5& operator=(const Auto_ptr5& a) = delete;
// Move assignment
// Transfer ownership of a.m_ptr to m_ptr
Auto_ptr5& operator=(Auto_ptr5&& a) noexcept
{
// Self-assignment detection
if (&a == this)
return *this;
// Release any resource we're holding
delete m_ptr;
// Transfer ownership of a.m_ptr to m_ptr
m_ptr = a.m_ptr;
a.m_ptr = nullptr;
return *this;
}
T& operator*() const { return *m_ptr; }
T* operator->() const { return m_ptr; }
bool isNull() const { return m_ptr == nullptr; }
};
If you were to try to pass an Auto_ptr5 l-value to a function by value, the compiler would complain that the copy constructor required to initialize the function argument has been deleted. This is good, because we should probably be passing Auto_ptr5 by const l-value reference anyway!
Auto_ptr5 is (finally) a good smart pointer class. And, in fact the standard library contains a class very much like this one (that you should use instead), named std::unique_ptr. We’ll talk more about std::unique_ptr later in this chapter.
Another example
Now let’s run the same program again, replacing the copy constructor and copy assignment with a move constructor and move assignment.
On the same machine, this program executed in 0.0056 seconds.
Comparing the runtime of the two programs, 0.0056 / 0.00825559 = 67.8%. The move version was 47.4% faster!
Do not implement move semantics using std::swap
Since the goal of move semantics is to move a resource from a source object to a destination object, you might think about implementing the move constructor and move assignment operator using std::swap(). However, this is a bad idea, as std::swap() calls both the move constructor and move assignment on move-capable objects, which would result in an infinite recursion. You can see this happen in the following example:
#include <iostream>
#include <string>
class Name
{
private:
std::string m_name; // std::string is move capable
public:
Name(std::string name) : m_name{ name }
{
}
Name(const Name& name) = delete;
Name& operator=(const Name& name) = delete;
Name(Name&& name)
{
std::cout << "Move ctor\n";
std::swap(*this, name); // bad!
}
Name& operator=(Name&& name)
{
std::cout << "Move assign\n";
std::swap(*this, name); // bad!
return *this;
}
const std::string& get() { return m_name; }
};
int main()
{
Name n1{ "Alex" };
n1 = Name{"Joe"}; // invokes move assignment
std::cout << n1.get() << '\n';
return 0;
}
This prints:
Move assign
Move ctor
Move ctor
Move ctor
Move ctor
And so on… until the stack overflows.
You can implement the move constructor and move assignment using your own swap function, as long as your swap member function does not call the move constructor or move assignment. Here’s an example of how that can be done:
#include <iostream>
#include <string>
class Name
{
private:
std::string m_name;
public:
Name(std::string name) : m_name{ name }
{
}
Name(const Name& name) = delete;
Name& operator=(const Name& name) = delete;
// Create our own swap friend function to swap the members of Name
friend void swap(Name& a, Name& b) noexcept
{
// We avoid recursive calls by invoking std::swap on the std::string member,
// not on Name
std::swap(a.m_name, b.m_name);
}
Name(Name&& name)
{
std::cout << "Move ctor\n";
swap(*this, name); // Now calling our swap, not std::swap
}
Name& operator=(Name&& name)
{
std::cout << "Move assign\n";
swap(*this, name); // Now calling our swap, not std::swap
return *this;
}
const std::string& get() { return m_name; }
};
int main()
{
Name n1{ "Alex" };
n1 = Name{"Joe"}; // invokes move assignment
std::cout << n1.get() << '\n';
return 0;
}
This works as expected, and prints:
Move assign
Joe
Deleting the move constructor and move assignment
You can delete the move constructor and move assignment using the = delete syntax in the exact same way you can delete the copy constructor and copy assignment.
#include <iostream>
#include <string>
class Name
{
private:
std::string m_name;
public:
Name(std::string name) : m_name{ name }
{
}
Name(const Name& name) = delete;
Name& operator=(const Name& name) = delete;
Name(Name&& name) = delete;
Name& operator=(Name&& name) = delete;
const std::string& get() { return m_name; }
};
int main()
{
Name n1{ "Alex" };
n1 = Name{ "Joe" }; // error: move assignment deleted
std::cout << n1.get() << '\n';
return 0;
}
A good rule of thumb is to delete the move constructor and move assignment operator whenever you delete the copy constructor and copy assignment operator.
Key insight
The rule of five says that if the copy constructor, copy assignment, move constructor, move assignment, or destructor are defined or deleted, then all of those functions should be similarly defined or deleted.
While deleting only the move constructor and move assignment may seem like a good idea if you want a copyable but not movable object, this has the unfortunate consequence of making the class not returnable by value in cases where mandatory copy elision does not apply. This happens because a deleted move constructor is still declared, and thus is eligible for overload resolution. And return by value will favor a deleted move constructor over a non-deleted copy constructor. This is illustrated by the following program:
#include <iostream>
#include <string>
class Name
{
private:
std::string m_name;
public:
Name(std::string name) : m_name{ name }
{
}
Name(const Name& name) = default;
Name& operator=(const Name& name) = default;
Name(Name&& name) = delete;
Name& operator=(Name&& name) = delete;
const std::string& get() { return m_name; }
};
Name getJoe()
{
Name joe{ "Joe" };
return joe; // error: Move constructor was deleted
}
int main()
{
Name n{ getJoe() };
std::cout << n.get() << '\n';
return 0;
}
M.4 — std::move
In C++11, std::move is a standard library function that casts (using static_cast) its argument into an r-value reference, so that move semantics can be invoked. Thus, we can use std::move to cast an l-value into a type that will prefer being moved over being copied. std::move is defined in the utility header.
Here’s the same program as above, but with a myswapMove() function that uses std::move to convert our l-values into r-values so we can invoke move semantics:
#include <iostream>
#include <string>
#include <utility> // for std::move
template<class T>
void myswapMove(T& a, T& b)
{
T tmp { std::move(a) }; // invokes move constructor
a = std::move(b); // invokes move assignment
b = std::move(tmp); // invokes move assignment
}
int main()
{
std::string x{ "abc" };
std::string y{ "de" };
std::cout << "x: " << x << '\n';
std::cout << "y: " << y << '\n';
myswapMove(x, y);
std::cout << "x: " << x << '\n';
std::cout << "y: " << y << '\n';
return 0;
}
This prints the same result as above:
x: abc
y: de
x: de
y: abc
But it’s much more efficient about it. When tmp is initialized, instead of making a copy of x, we use std::move to convert l-value variable x into an r-value. Since the parameter is an r-value, move semantics are invoked, and x is moved into tmp.
With a couple of more swaps, the value of variable x has been moved to y, and the value of y has been moved to x.
Another example
We can also use std::move when filling elements of a container, such as std::vector, with l-values.
In the following program, we first add an element to a vector using copy semantics. Then we add an element to the vector using move semantics.
#include <iostream>
#include <string>
#include <utility> // for std::move
#include <vector>
int main()
{
std::vector<std::string> v;
// We use std::string because it is movable (std::string_view is not)
std::string str { "Knock" };
std::cout << "Copying str\n";
v.push_back(str); // calls l-value version of push_back, which copies str into the array element
std::cout << "str: " << str << '\n';
std::cout << "vector: " << v[0] << '\n';
std::cout << "\nMoving str\n";
v.push_back(std::move(str)); // calls r-value version of push_back, which moves str into the array element
std::cout << "str: " << str << '\n'; // The result of this is indeterminate
std::cout << "vector:" << v[0] << ' ' << v[1] << '\n';
return 0;
}
On the author’s machine, this program prints:
Copying str
str: Knock
vector: Knock
Moving str
str:
vector: Knock Knock
In the first case, we passed push_back() an l-value, so it used copy semantics to add an element to the vector. For this reason, the value in str is left alone.
In the second case, we passed push_back() an r-value (actually an l-value converted via std::move), so it used move semantics to add an element to the vector. This is more efficient, as the vector element can steal the string’s value rather than having to copy it.
Moved from objects will be in a valid, but possibly indeterminate state
Key insight
std::move() gives a hint to the compiler that the programmer doesn’t need the value of an object any more. Only use std::move() on persistent objects whose value you want to move, and do not make any assumptions about the value of the object beyond that point. It is okay to give a moved-from object a new value (e.g. using operator=) after the current value has been moved.
Where else is std::move useful?
std::move can also be useful when sorting an array of elements. Many sorting algorithms (such as selection sort and bubble sort) work by swapping pairs of elements. In previous lessons, we’ve had to resort to copy-semantics to do the swapping. Now we can use move semantics, which is more efficient.
It can also be useful if we want to move the contents managed by one smart pointer to another.
Conclusion
std::move can be used whenever we want to treat an l-value like an r-value for the purpose of invoking move semantics instead of copy semantics.
M.5 — std::move_if_noexcept
The move constructors exception problem
std::move_if_noexcept to the rescue
Key insight
std::move_if_noexcept will return a movable r-value if the object has a noexcept move constructor, otherwise it will return a copyable l-value. We can use the noexcept specifier in conjunction with std::move_if_noexcept to use move semantics only when a strong exception guarantee exists (and use copy semantics otherwise).
Warning
If a type has both potentially throwing move semantics and deleted copy semantics (the copy constructor and copy assignment operator are unavailable), then std::move_if_noexcept will waive the strong guarantee and invoke move semantics. This conditional waiving of the strong guarantee is ubiquitous in the standard library container classes, since they use std::move_if_noexcept often.
M.6 — std::unique_ptr
C++11 standard library ships with 4 smart pointer classes: std::auto_ptr (removed in C++17), std::unique_ptr, std::shared_ptr, and std::weak_ptr. std::unique_ptr is by far the most used smart pointer class, so we’ll cover that one first. In the following lessons, we’ll cover std::shared_ptr and std::weak_ptr.
std::unique_ptr
std::unique_ptr is the C++11 replacement for std::auto_ptr. It should be used to manage any dynamically allocated object that is not shared by multiple objects. That is, std::unique_ptr should completely own the object it manages, not share that ownership with other classes. std::unique_ptr lives in the header.
Unlike std::auto_ptr, std::unique_ptr properly implements move semantics.
#include <iostream>
#include <memory> // for std::unique_ptr
#include <utility> // for std::move
class Resource
{
public:
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
};
int main()
{
std::unique_ptr<Resource> res1{ new Resource{} }; // Resource created here
std::unique_ptr<Resource> res2{}; // Start as nullptr
std::cout << "res1 is " << (res1 ? "not null\n" : "null\n");
std::cout << "res2 is " << (res2 ? "not null\n" : "null\n");
// res2 = res1; // Won't compile: copy assignment is disabled
res2 = std::move(res1); // res2 assumes ownership, res1 is set to null
std::cout << "Ownership transferred\n";
std::cout << "res1 is " << (res1 ? "not null\n" : "null\n");
std::cout << "res2 is " << (res2 ? "not null\n" : "null\n");
return 0;
} // Resource destroyed here when res2 goes out of scope
This prints:
Resource acquired
res1 is not null
res2 is null
Ownership transferred
res1 is null
res2 is not null
Resource destroyed
Because std::unique_ptr is designed with move semantics in mind, copy initialization and copy assignment are disabled. If you want to transfer the contents managed by std::unique_ptr, you must use move semantics. In the program above, we accomplish this via std::move (which converts res1 into an r-value, which triggers a move assignment instead of a copy assignment).
Accessing the managed object
std::unique_ptr has an overloaded operator* and operator-> that can be used to return the resource being managed. Operator* returns a reference to the managed resource, and operator-> returns a pointer.
std::unique_ptr and arrays
Unlike std::auto_ptr, std::unique_ptr is smart enough to know whether to use scalar delete or array delete, so std::unique_ptr is okay to use with both scalar objects and arrays.
However, std::array or std::vector (or std::string) are almost always better choices than using std::unique_ptr with a fixed array, dynamic array, or C-style string.
Best practice
Favor std::array, std::vector, or std::string over a smart pointer managing a fixed array, dynamic array, or C-style string.
std::make_unique
Best practice
Use std::make_unique() instead of creating std::unique_ptr and using new yourself.
The exception safety issue in more detail
For those wondering what the “exception safety issue” mentioned above is, here’s a description of the issue.
Consider an expression like this one:
some_function(std::unique_ptr<T>(new T), function_that_can_throw_exception());
The compiler is given a lot of flexibility in terms of how it handles this call. It could create a new T, then call function_that_can_throw_exception(), then create the std::unique_ptr that manages the dynamically allocated T. If function_that_can_throw_exception() throws an exception, then the T that was allocated will not be deallocated, because the smart pointer to do the deallocation hasn’t been created yet. This leads to T being leaked.
std::make_unique() doesn’t suffer from this problem because the creation of the object T and the creation of the std::unique_ptr happen inside the std::make_unique() function, where there’s no ambiguity about order of execution.
Returning std::unique_ptr from a function
std::unique_ptr can be safely returned from a function by value:
#include <memory> // for std::unique_ptr
std::unique_ptr<Resource> createResource()
{
return std::make_unique<Resource>();
}
int main()
{
auto ptr{ createResource() };
// do whatever
return 0;
}
In the above code, createResource() returns a std::unique_ptr by value. If this value is not assigned to anything, the temporary return value will go out of scope and the Resource will be cleaned up. If it is assigned (as shown in main()), in C++14 or earlier, move semantics will be employed to transfer the Resource from the return value to the object assigned to (in the above example, ptr), and in C++17 or newer, the return will be elided. This makes returning a resource by std::unique_ptr much safer than returning raw pointers!
In general, you should not return std::unique_ptr by pointer (ever) or reference (unless you have a specific compelling reason to).
Passing std::unique_ptr to a function
If you want the function to take ownership of the contents of the pointer, pass the std::unique_ptr by value. Note that because copy semantics have been disabled, you’ll need to use std::move to actually pass the variable in.
#include <iostream>
#include <memory> // for std::unique_ptr
#include <utility> // for std::move
class Resource
{
public:
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
friend std::ostream& operator<<(std::ostream& out, const Resource &res)
{
out << "I am a resource";
return out;
}
};
void takeOwnership(std::unique_ptr<Resource> res)
{
if (res)
std::cout << *res << '\n';
} // the Resource is destroyed here
int main()
{
auto ptr{ std::make_unique<Resource>() };
// takeOwnership(ptr); // This doesn't work, need to use move semantics
takeOwnership(std::move(ptr)); // ok: use move semantics
std::cout << "Ending program\n";
return 0;
}
The above program prints:
Resource acquired
I am a resource
Resource destroyed
Ending program
Note that in this case, ownership of the Resource was transferred to takeOwnership(), so the Resource was destroyed at the end of takeOwnership() rather than the end of main().
However, most of the time, you won’t want the function to take ownership of the resource. Although you can pass a std::unique_ptr by reference (which will allow the function to use the object without assuming ownership), you should only do so when the called function might alter or change the object being managed.
Instead, it’s better to just pass the resource itself (by pointer or reference, depending on whether null is a valid argument). This allows the function to remain agnostic of how the caller is managing its resources. To get a raw resource pointer from a std::unique_ptr, you can use the get() member function:
#include <memory> // for std::unique_ptr
#include <iostream>
class Resource
{
public:
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
friend std::ostream& operator<<(std::ostream& out, const Resource &res)
{
out << "I am a resource";
return out;
}
};
// The function only uses the resource, so we'll accept a pointer to the resource, not a reference to the whole std::unique_ptr<Resource>
void useResource(Resource* res)
{
if (res)
std::cout << *res << '\n';
else
std::cout << "No resource\n";
}
int main()
{
auto ptr{ std::make_unique<Resource>() };
useResource(ptr.get()); // note: get() used here to get a pointer to the Resource
std::cout << "Ending program\n";
return 0;
} // The Resource is destroyed here
The above program prints:
Resource acquired
I am a resource
Ending program
Resource destroyed
std::unique_ptr and classes
You can, of course, use std::unique_ptr as a composition member of your class. This way, you don’t have to worry about ensuring your class destructor deletes the dynamic memory, as the std::unique_ptr will be automatically destroyed when the class object is destroyed.
However, if the class object is not destroyed properly (e.g. it is dynamically allocated and not deallocated properly), then the std::unique_ptr member will not be destroyed either, and the object being managed by the std::unique_ptr will not be deallocated.
Misusing std::unique_ptr
There are two easy ways to misuse std::unique_ptrs, both of which are easily avoided. First, don’t let multiple classes manage the same resource. For example:
Resource* res{ new Resource() };
std::unique_ptr<Resource> res1{ res };
std::unique_ptr<Resource> res2{ res };
While this is legal syntactically, the end result will be that both res1 and res2 will try to delete the Resource, which will lead to undefined behavior.
Second, don’t manually delete the resource out from underneath the std::unique_ptr.
Resource* res{ new Resource() };
std::unique_ptr<Resource> res1{ res };
delete res;
If you do, the std::unique_ptr will try to delete an already deleted resource, again leading to undefined behavior.
Note that std::make_unique() prevents both of the above cases from happening inadvertently.
M.7 — std::shared_ptr
Unlike std::unique_ptr, which is designed to singly own and manage a resource, std::shared_ptr is meant to solve the case where you need multiple smart pointers co-owning a resource.
This means that it is fine to have multiple std::shared_ptr pointing to the same resource. Internally, std::shared_ptr keeps track of how many std::shared_ptr are sharing the resource. As long as at least one std::shared_ptr is pointing to the resource, the resource will not be deallocated, even if individual std::shared_ptr are destroyed. As soon as the last std::shared_ptr managing the resource goes out of scope (or is reassigned to point at something else), the resource will be deallocated.
Like std::unique_ptr, std::shared_ptr lives in the header.
#include <iostream>
#include <memory> // for std::shared_ptr
class Resource
{
public:
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
};
int main()
{
// allocate a Resource object and have it owned by std::shared_ptr
Resource* res { new Resource };
std::shared_ptr<Resource> ptr1{ res };
{
std::shared_ptr<Resource> ptr2 { ptr1 }; // make another std::shared_ptr pointing to the same thing
std::cout << "Killing one shared pointer\n";
} // ptr2 goes out of scope here, but nothing happens
std::cout << "Killing another shared pointer\n";
return 0;
} // ptr1 goes out of scope here, and the allocated Resource is destroyed
This prints:
Resource acquired
Killing one shared pointer
Killing another shared pointer
Resource destroyed
In the above code, we create a dynamic Resource object, and set a std::shared_ptr named ptr1 to manage it. Inside the nested block, we use the copy constructor to create a second std::shared_ptr (ptr2) that points to the same Resource. When ptr2 goes out of scope, the Resource is not deallocated, because ptr1 is still pointing at the Resource. When ptr1 goes out of scope, ptr1 notices there are no more std::shared_ptr managing the Resource, so it deallocates the Resource.
Note that we created a second shared pointer from the first shared pointer. This is important. Consider the following similar program:
#include <iostream>
#include <memory> // for std::shared_ptr
class Resource
{
public:
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
};
int main()
{
Resource* res { new Resource };
std::shared_ptr<Resource> ptr1 { res };
{
std::shared_ptr<Resource> ptr2 { res }; // create ptr2 directly from res (instead of ptr1)
std::cout << "Killing one shared pointer\n";
} // ptr2 goes out of scope here, and the allocated Resource is destroyed
std::cout << "Killing another shared pointer\n";
return 0;
} // ptr1 goes out of scope here, and the allocated Resource is destroyed again
This program prints:
Resource acquired
Killing one shared pointer
Resource destroyed
Killing another shared pointer
Resource destroyed
and then crashes (at least on the author’s machine).
The difference here is that we created two std::shared_ptr independently from each other. As a consequence, even though they’re both pointing to the same Resource, they aren’t aware of each other. When ptr2 goes out of scope, it thinks it’s the only owner of the Resource, and deallocates it. When ptr1 later goes out of the scope, it thinks the same thing, and tries to delete the Resource again. Then bad things happen.
Fortunately, this is easily avoided: if you need more than one std::shared_ptr to a given resource, copy an existing std::shared_ptr.
Best practice
Always make a copy of an existing std::shared_ptr if you need more than one std::shared_ptr pointing to the same resource.
std::make_shared
Much like std::make_unique() can be used to create a std::unique_ptr in C++14, std::make_shared() can (and should) be used to make a std::shared_ptr. std::make_shared() is available in C++11.
Here’s our original example, using std::make_shared():
#include <iostream>
#include <memory> // for std::shared_ptr
class Resource
{
public:
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
};
int main()
{
// allocate a Resource object and have it owned by std::shared_ptr
auto ptr1 { std::make_shared<Resource>() };
{
auto ptr2 { ptr1 }; // create ptr2 using copy of ptr1
std::cout << "Killing one shared pointer\n";
} // ptr2 goes out of scope here, but nothing happens
std::cout << "Killing another shared pointer\n";
return 0;
} // ptr1 goes out of scope here, and the allocated Resource is destroyed
The reasons for using std::make_shared() are the same as std::make_unique() – std::make_shared() is simpler and safer (there’s no way to directly create two std::shared_ptr pointing to the same resource using this method). However, std::make_shared() is also more performant than not using it. The reasons for this lie in the way that std::shared_ptr keeps track of how many pointers are pointing at a given resource.
Digging into std::shared_ptr
Unlike std::unique_ptr, which uses a single pointer internally, std::shared_ptr uses two pointers internally. One pointer points at the resource being managed. The other points at a “control block”, which is a dynamically allocated object that tracks of a bunch of stuff, including how many std::shared_ptr are pointing at the resource. When a std::shared_ptr is created via a std::shared_ptr constructor, the memory for the managed object (which is usually passed in) and control block (which the constructor creates) are allocated separately. However, when using std::make_shared(), this can be optimized into a single memory allocation, which leads to better performance.
This also explains why independently creating two std::shared_ptr pointed to the same resource gets us into trouble. Each std::shared_ptr will have one pointer pointing at the resource. However, each std::shared_ptr will independently allocate its own control block, which will indicate that it is the only pointer owning that resource. Thus, when that std::shared_ptr goes out of scope, it will deallocate the resource, not realizing there are other std::shared_ptr also trying to manage that resource.
However, when a std::shared_ptr is cloned using copy assignment, the data in the control block can be appropriately updated to indicate that there are now additional std::shared_ptr co-managing the resource.
Shared pointers can be created from unique pointers
A std::unique_ptr can be converted into a std::shared_ptr via a special std::shared_ptr constructor that accepts a std::unique_ptr r-value. The contents of the std::unique_ptr will be moved to the std::shared_ptr.
However, std::shared_ptr can not be safely converted to a std::unique_ptr. This means that if you’re creating a function that is going to return a smart pointer, you’re better off returning a std::unique_ptr and assigning it to a std::shared_ptr if and when that’s appropriate.
The perils of std::shared_ptr
std::shared_ptr has some of the same challenges as std::unique_ptr – if the std::shared_ptr is not properly disposed of (either because it was dynamically allocated and never deleted, or it was part of an object that was dynamically allocated and never deleted) then the resource it is managing won’t be deallocated either. With std::unique_ptr, you only have to worry about one smart pointer being properly disposed of. With std::shared_ptr, you have to worry about them all. If any of the std::shared_ptr managing a resource are not properly destroyed, the resource will not be deallocated properly.
std::shared_ptr and arrays
In C++17 and earlier, std::shared_ptr does not have proper support for managing arrays, and should not be used to manage a C-style array. As of C++20, std::shared_ptr does have support for arrays.
Conclusion
std::shared_ptr is designed for the case where you need multiple smart pointers co-managing the same resource. The resource will be deallocated when the last std::shared_ptr managing the resource is destroyed.
M.8 — Circular dependency issues with std::shared_ptr, and std::weak_ptr
#include <iostream>
#include <memory> // for std::shared_ptr
#include <string>
class Person
{
std::string m_name;
std::shared_ptr<Person> m_partner; // initially created empty
public:
Person(const std::string &name): m_name(name)
{
std::cout << m_name << " created\n";
}
~Person()
{
std::cout << m_name << " destroyed\n";
}
friend bool partnerUp(std::shared_ptr<Person> &p1, std::shared_ptr<Person> &p2)
{
if (!p1 || !p2)
return false;
p1->m_partner = p2;
p2->m_partner = p1;
std::cout << p1->m_name << " is now partnered with " << p2->m_name << '\n';
return true;
}
};
int main()
{
auto lucy { std::make_shared<Person>("Lucy") }; // create a Person named "Lucy"
auto ricky { std::make_shared<Person>("Ricky") }; // create a Person named "Ricky"
partnerUp(lucy, ricky); // Make "Lucy" point to "Ricky" and vice-versa
return 0;
}
However, this program doesn’t execute as expected:
Lucy created
Ricky created
Lucy is now partnered with Ricky
It turns out that this can happen any time shared pointers form a circular reference.
Circular references
A Circular reference (also called a cyclical reference or a cycle) is a series of references where each object references the next, and the last object references back to the first, causing a referential loop. The references do not need to be actual C++ references – they can be pointers, unique IDs, or any other means of identifying specific objects.
In the context of shared pointers, the references will be pointers.
This is exactly what we see in the case above: “Lucy” points at “Ricky”, and “Ricky” points at “Lucy”. With three pointers, you’d get the same thing when A points at B, B points at C, and C points at A. The practical effect of having shared pointers form a cycle is that each object ends up keeping the next object alive – with the last object keeping the first object alive. Thus, no objects in the series can be deallocated because they all think some other object still needs it!
A reductive case
It turns out, this cyclical reference issue can even happen with a single std::shared_ptr – a std::shared_ptr referencing the object that contains it is still a cycle (just a reductive one). Although it’s fairly unlikely that this would ever happen in practice, we’ll show you for additional comprehension:
#include <iostream>
#include <memory> // for std::shared_ptr
class Resource
{
public:
std::shared_ptr<Resource> m_ptr {}; // initially created empty
Resource() { std::cout << "Resource acquired\n"; }
~Resource() { std::cout << "Resource destroyed\n"; }
};
int main()
{
auto ptr1 { std::make_shared<Resource>() };
ptr1->m_ptr = ptr1; // m_ptr is now sharing the Resource that contains it
return 0;
}
In the above example, when ptr1 goes out of scope, the Resource is not deallocated because the Resource’s m_ptr is sharing the Resource. At that point, the only way for the Resource to be released would be to set m_ptr to something else (so nothing is sharing the Resource any longer). But we can’t access m_ptr because ptr1 is out of scope, so we no longer have a way to do this. The Resource has become a memory leak.
Thus, the program prints:
Resource acquired
and that’s it.
So what is std::weak_ptr for anyway?
std::weak_ptr was designed to solve the “cyclical ownership” problem described above. A std::weak_ptr is an observer – it can observe and access the same object as a std::shared_ptr (or other std::weak_ptrs) but it is not considered an owner. Remember, when a std::shared pointer goes out of scope, it only considers whether other std::shared_ptr are co-owning the object. std::weak_ptr does not count!
Let’s solve our Person-al issue using a std::weak_ptr:
#include <iostream>
#include <memory> // for std::shared_ptr and std::weak_ptr
#include <string>
class Person
{
std::string m_name;
std::weak_ptr<Person> m_partner; // note: This is now a std::weak_ptr
public:
Person(const std::string &name): m_name(name)
{
std::cout << m_name << " created\n";
}
~Person()
{
std::cout << m_name << " destroyed\n";
}
friend bool partnerUp(std::shared_ptr<Person> &p1, std::shared_ptr<Person> &p2)
{
if (!p1 || !p2)
return false;
p1->m_partner = p2;
p2->m_partner = p1;
std::cout << p1->m_name << " is now partnered with " << p2->m_name << '\n';
return true;
}
};
int main()
{
auto lucy { std::make_shared<Person>("Lucy") };
auto ricky { std::make_shared<Person>("Ricky") };
partnerUp(lucy, ricky);
return 0;
}
This code behaves properly:
Lucy created
Ricky created
Lucy is now partnered with Ricky
Ricky destroyed
Lucy destroyed
Functionally, it works almost identically to the problematic example. However, now when ricky goes out of scope, it sees that there are no other std::shared_ptr pointing at “Ricky” (the std::weak_ptr from “Lucy” doesn’t count). Therefore, it will deallocate “Ricky”. The same occurs for lucy.
Using std::weak_ptr
One downside of std::weak_ptr is that std::weak_ptr are not directly usable (they have no operator->). To use a std::weak_ptr, you must first convert it into a std::shared_ptr. Then you can use the std::shared_ptr. To convert a std::weak_ptr into a std::shared_ptr, you can use the lock() member function.
const std::shared_ptr<Person> getPartner() const { return m_partner.lock(); } // use lock() to convert weak_ptr to shared_ptr
Avoiding dangling pointers with std::weak_ptr
The easiest way to test whether a std::weak_ptr is valid is to use the expired() member function, which returns true if the std::weak_ptr is pointing to an invalid object, and false otherwise.
Here’s a simple example showing this difference in behavior:
// h/t to reader Waldo for an early version of this example
#include <iostream>
#include <memory>
class Resource
{
public:
Resource() { std::cerr << "Resource acquired\n"; }
~Resource() { std::cerr << "Resource destroyed\n"; }
};
// Returns a std::weak_ptr to an invalid object
std::weak_ptr<Resource> getWeakPtr()
{
auto ptr{ std::make_shared<Resource>() };
return std::weak_ptr{ ptr };
} // ptr goes out of scope, Resource destroyed
// Returns a dumb pointer to an invalid object
Resource* getDumbPtr()
{
auto ptr{ std::make_unique<Resource>() };
return ptr.get();
} // ptr goes out of scope, Resource destroyed
int main()
{
auto dumb{ getDumbPtr() };
std::cout << "Our dumb ptr is: " << ((dumb == nullptr) ? "nullptr\n" : "non-null\n");
auto weak{ getWeakPtr() };
std::cout << "Our weak ptr is: " << ((weak.expired()) ? "expired\n" : "valid\n");
return 0;
}
This prints:
Resource acquired
Resource destroyed
Our dumb ptr is: non-null
Resource acquired
Resource destroyed
Our weak ptr is: expired
Note that if a std::weak_ptr is expired, then we shouldn’t call lock() on it, because the object being pointed to has already been destroyed, so there is no object to share. If you do call lock() on an expired std::weak_ptr, it will return a std::shared_ptr to nullptr.
Conclusion
std::shared_ptr can be used when you need multiple smart pointers that can co-own a resource. The resource will be deallocated when the last std::shared_ptr goes out of scope. std::weak_ptr can be used when you want a smart pointer that can see and use a shared resource, but does not participate in the ownership of that resource.
M.x — Chapter M comprehensive review
A smart pointer class is a composition class that is designed to manage dynamically allocated memory, and ensure that memory gets deleted when the smart pointer object goes out of scope.














 119
119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









