






需求
计算每一年出现过的最高温度的日期以及温度。
数据
2014010114
2014010216
2014010317
2014010410
2014010506
2012010609
2012010732
2012010812
2012010919
2012011023
2001010116
2001010212
2001010310
2001010411
2001010529
2013010619
2013010722
2013010812
2013010929
2013011023
2008010105
2008010216
2008010337
2008010414
2008010516
2007010619
2007010712
2007010812
2007010999
2007011023
2010010114
2010010216
2010010317
2010010410
2010010506
2015010649
2015010722
2015010812
2015010999
2015011023
数据含义:
2014010114表示在2014年01月01日的气温为14度。
建表以及导入数据:
CREATE TABLE weather (str string);
LOAD data LOCAL inpath '/home/weather.txt' INTO TABLE weather;
确认数据导入成功
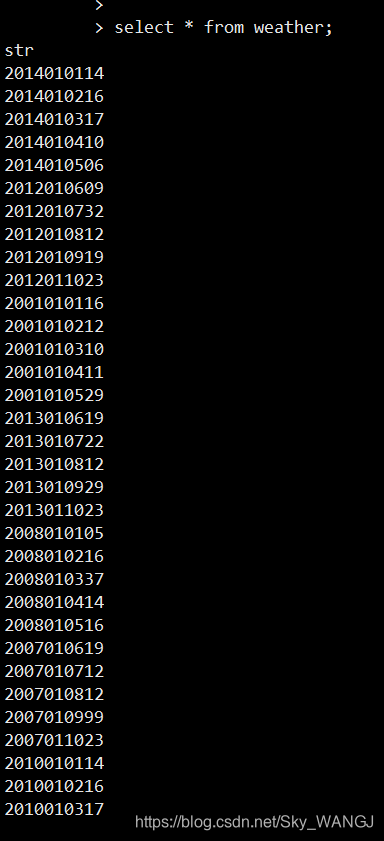
按照格式解析数据,创建一个临时视图
CREATE TEMPORARY VIEW tmp AS
SELECT substring(str, 1, 8) AS dt,
substring(str, 1, 4) year,
substring(str, 9) AS temperature
FROM weather;
查看数据
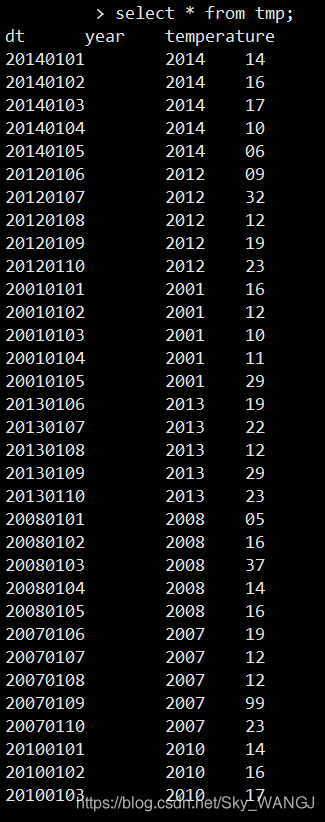
1.使用开窗函数
注:最后的order by排序不影响最终结果,只是方便查看输出结果。
SELECT t.dt,
t.year,
t.temperature
FROM (
SELECT *,
max(temperature) OVER (
PARTITION BY year ORDER BY temperature DESC
) AS max_temp,
rank() OVER (
PARTITION BY year ORDER BY temperature DESC
) AS r
FROM tmp
) t
WHERE t.r = 1
ORDER BY dt;
查看结果
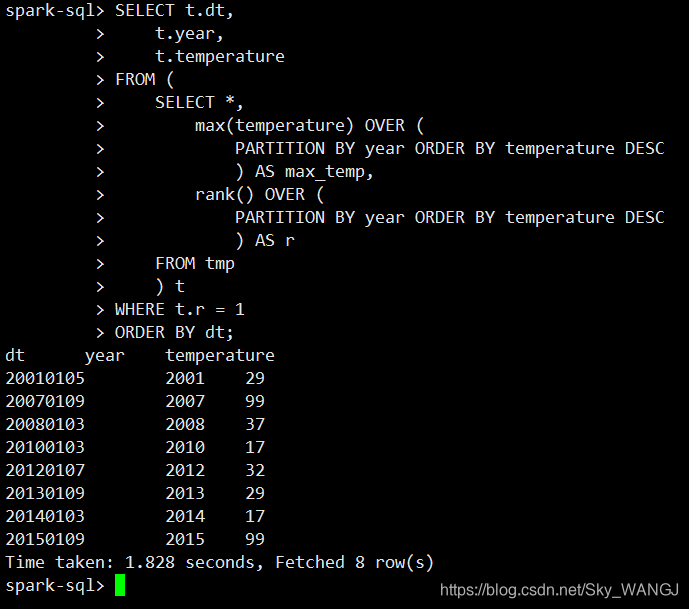
2.使用group by
SELECT DISTINCT a.dt,
a.year,
a.temperature
FROM tmp a
RIGHT JOIN (
SELECT year,
max(temperature) AS max_temp
FROM tmp
GROUP BY year
) b
ON a.temperature = b.max_temp
ORDER BY a.dt;
查看结果
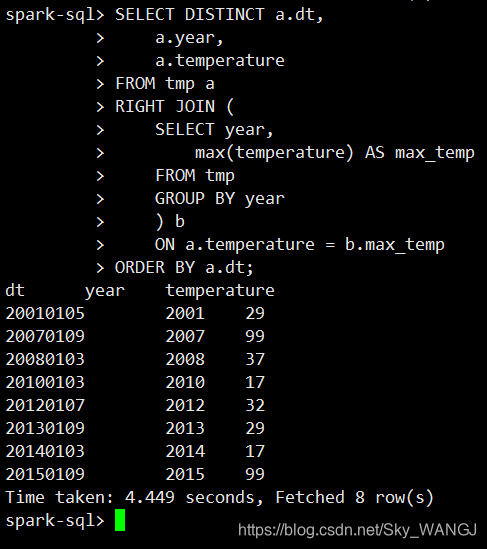
说明
1.博主采用的是spark on hive的模式来运行的sql语句,执行效率会比hive on MR快很多;
2.看time,明显看出来使用over()开窗函数的计算性能明显比使用group by要快很多,差不多快50%;
3.这个题目是博主在其他博客里看到的,觉得很有意思,然后自己写了两种解题思路;
4.受水平所限,若有不对之处,恳请指正,不胜感激。














 8699
8699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









