







一、HTTP 协议基础
(一)什么是 HTTP 协议
HTTP(HyperText Transfer Protocol,超文本传输协议)是互联网上应用层协议之一,主要用于客户端(如浏览器)与服务器之间进行通信,以交换或传输超文本(如 HTML 文档)。在互联网世界中,HTTP 协议至关重要,它规定了客户端与服务器之间通信的规则和数据格式,使得双方能够准确地发送和接收信息。
(二)HTTP 协议的特点
-
无连接 :每次请求都需要建立新的连接,一个请求完成后连接就会关闭。这意味着客户端与服务器之间的通信是基于单次请求 - 响应的模式,每次交互都是独立的,不保留连接状态。
-
无状态 :服务器不会保存客户端的状态信息。每一次请求对于服务器来说都是全新的,服务器不会根据之前的操作对当前请求进行处理上的改变。例如,当用户登录网站后,服务器并不会自动记住用户的登录状态,除非通过其他机制(如 Cookie 或 Session)来实现状态管理。
二、认识 URI
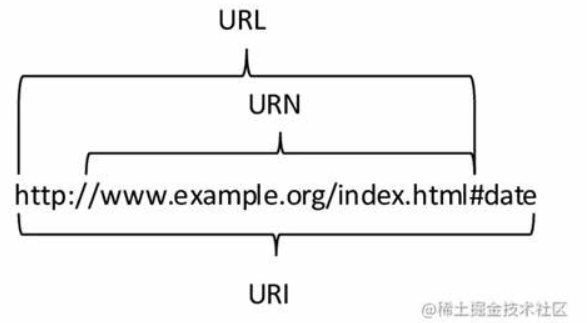
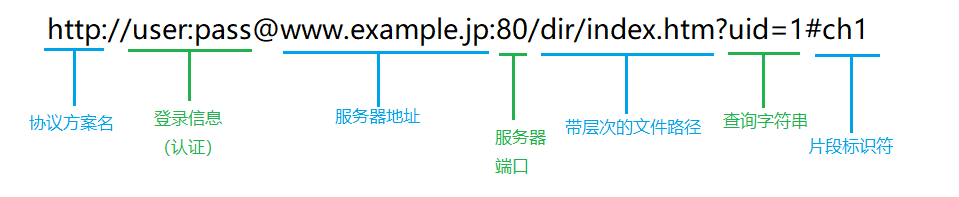

URL(Uniform Resource Locator,统一资源定位符),俗称 “网址”,用于标识网络上资源的位置。其一般格式为:协议名称:// 主机名:端口号 / 路径名 / 文件名。例如,在 “https://www.runoob.com/html/html - forms.html” 中:
http://www.runoob.com:80/html/html - forms.html“https” 表示协议,“www.runoob.com” 是主机名,“80”(默认情况下省略)是端口号,“/html/html - forms.html” 为路径名和文件名,用于定位具体的资源。
三、urlencode 和 urldecode

在 URL 中,像 “/”“?”“:” 等字符已经被赋予了特殊意义,用于表示路径分隔、查询参数开始等。因此,当这些字符需要作为普通文本数据出现在 URL 的参数中时,必须进行转义。转义规则是:将需要转码的字符转为 16 进制,然后从右到左,取 4 位(不足 4 位直接处理),每 2 位做一位,前面加上 “%”,编码成 “%XY” 格式。例如,“+” 被转义成了 “%2B”。而 urldecode 就是 urlencode 的逆过程,用于将编码后的字符串还原为原始字符串。
也就是说,请求的时候,URI中但凡有特殊的字符,客户端(一般是浏览器)会自动给我们进行对特殊字符进行编码urlencode,后台服务器接收到浏览器发送来的请求报文,自己要进行urldecode!
HTTP就是一个协议了,我们前几篇自己实现了一个为了网络计算器的协议,我们当下就不需要再自己定制具体的协议了,因为我们不需要写客户端了,浏览器已经是非常OK的了,所以也就是我们自己在服务器端实现一个HttpResponse就可以了,不过我们需要添加HttpRequest来实现反序列化,看看对端浏览器给我们服务器发来了什么请求,不然怎们知道浏览器要求服务器做什么呢?下面,我们就通过在服务端写出对应的简单的HTTP协议来理解HTTP!
还有双方的请求与相应,这本质也是客户端和服务器之间的I/O操作,我们之前说过这种是C/S模式,但是对于HTTP协议,我们更使用的场景其实是客户端等价于浏览器(Browser)了,我们称之为B/S模式!!!
所以我们下面通过代码的方式来理解HTTP协议:
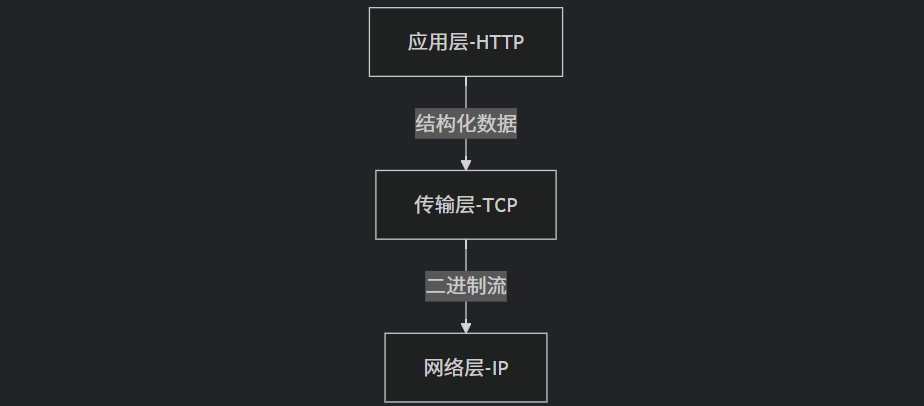
知道协议分层,而且HTTP是基于网络连接后的,层层之间是需要完成各自的工作的:
-
TCP层专注解决网络丢包/乱序问题:发送
GET /index.html和乱码字符串对TCP没有区别 -
HTTP层专注定义业务逻辑(缓存控制、认证等):HTTP协议赋予这些二进制数据语义和规则
我们之前就实现了建立连接,所以我们今天可以复用我们之前TCP的代码,实现第一步:建立连接,后面,我们就可以专注与HTTP协议了:我们的基本的代码在后面的附录当中
[浏览器] --HTTP请求--> [TCP数据流] --> [服务器]
<-HTTP响应-- [TCP数据流] <--四、HTTP 协议请求与响应格式
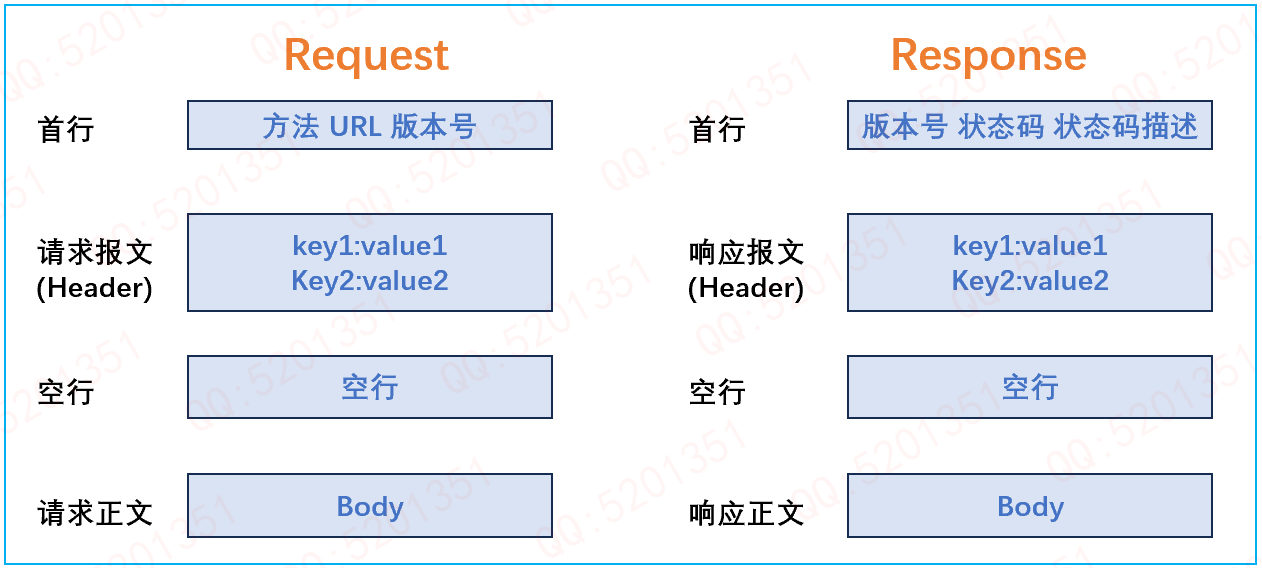
(一)HTTP 请求
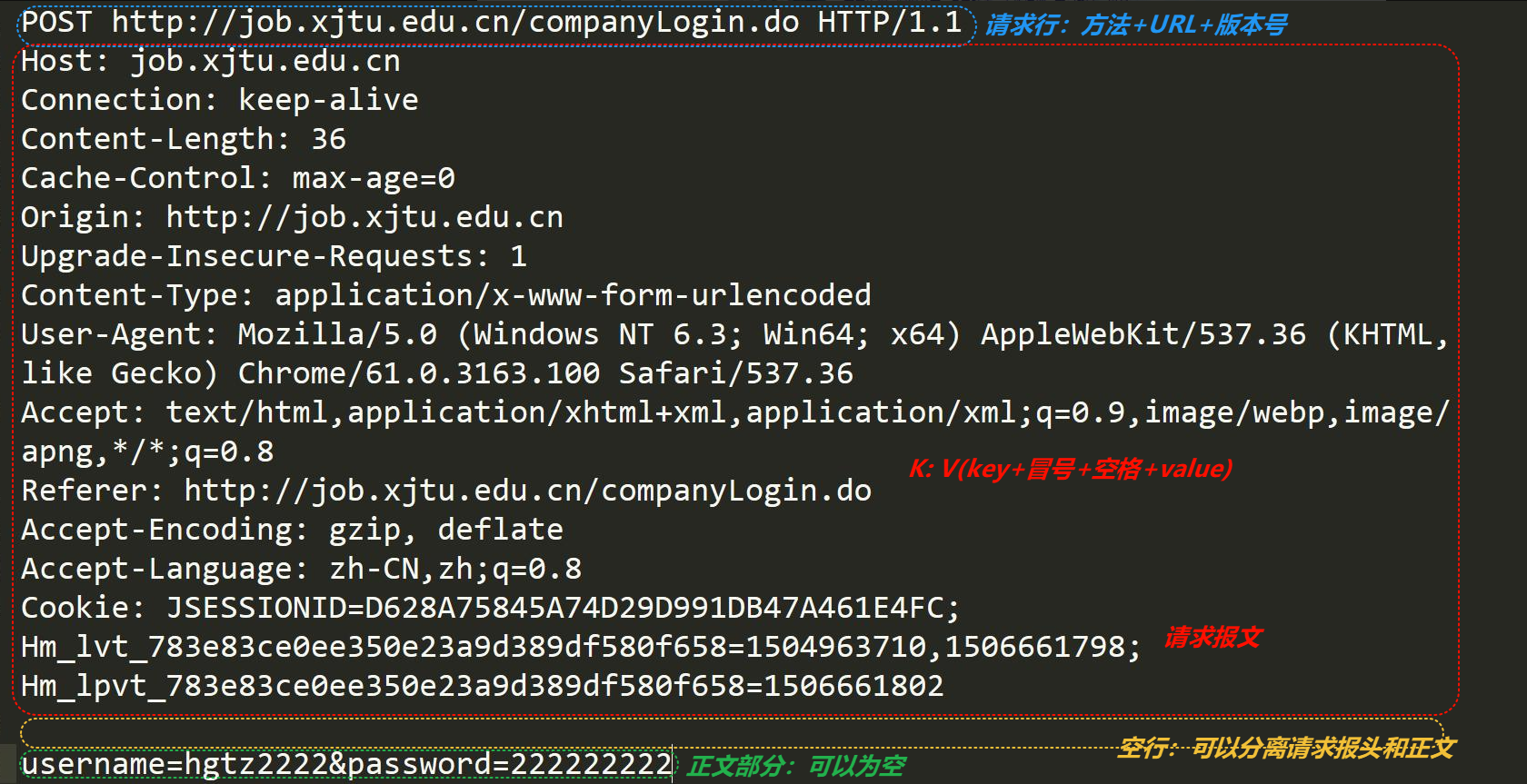
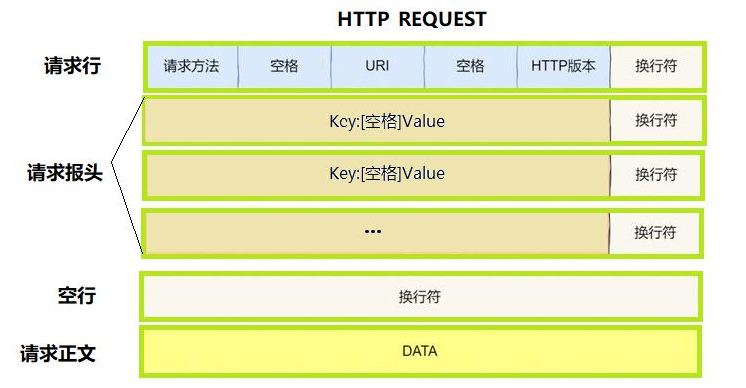
-
首行 :格式为 “[方法] + [url] + [版本]”。方法常见的有 GET、POST、PUT、HEAD、DELETE、OPTIONS 等,用于指定对服务器的操作类型。URL 表示请求的资源路径,版本表明使用的 HTTP 协议版本,如 HTTP/1.1。
-
Header :请求的属性,以冒号分割的键值对形式存在,每组属性之间使用 “\r\n” 分隔。例如,“Host: www.example.com” 表示请求的主机名,“User - Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36” 用于标识客户端的软件环境信息。我们在编程上就可以利用STL的相关K-V容器,比如说unordered_map来通过": "来分割取值,并存放报文的key值和value值!当遇到空行时,表示 Header 部分结束。
-
空行:我们可不要忽略空行!HTTP如何做到报头和有效载荷的分离,其实就是以空行作为分隔符的!
-
Body :空行后面的内容都是 Body,Body 允许为空字符串。如果 Body 存在,则在 Header 中会有一个 “Content - Length” 属性来标识 Body 的长度,用于告知服务器请求主体的大小。
(二)HTTP 响应

-
首行 :格式为 “[版本号] + [状态码] + [状态码解释]”。版本号对应请求中使用的 HTTP 协议版本,状态码是三位数字,用于表示服务器对请求的处理结果,如 200 表示成功,404 表示未找到资源等,状态码解释是对状态码的简短文字说明。
-
Header :与请求的 Header 类似,也是以冒号分割的键值对形式存在,用于传递响应的属性信息,如 “Content - Type: text/html” 表示响应的内容类型为 HTML,“Date: Sun, 16 Jun 2024 08:38:04 GMT” 表示服务器发送响应的日期和时间。遇到空行表示 Header 部分结束。
-
空行:我们可不要忽略空行!HTTP如何做到报头和有效载荷的分离,其实就是以空行作为分隔符的!
-
Body :空行后面的内容是 Body,Body 允许为空字符串。如果服务器返回了一个 html 页面,那么 html 页面内容就在 body 中,客户端可以根据 Content - Type 来解析和展示响应内容。
所以,现在我们该如何理解HTTP协议呢?
其实HTTP协议不就是一个结构化数据吗?!有其对应的class HttpRequest和class HttpResponse,两者之间的规则就是通过序列化和反序列化。在报文中的空格,": ","\r\n",空行。使用这些特使字符来区分区域,这不就是序列化和反序列化的依据吗,HTTP简单的规定了这样的规则,不就也没有必要通过特定的第三方库JSON等来做序列化和反序列化了。
需要知道的是HTTP在多数情况下是构成短连接(源于我们自己的实现的代码,其实HTTP本身是无连接,无状态的!!!:我们后续谈到cookie和session就明白了!),服务器是向客户端提供短服务的!不过浏览器有时候会反复请求服务端,但这也就看成是进行了多次短服务了,其实浏览器有时候需要访问多次的原因是需要访问多个资源等原因!!!
Util.hpp
我们接下就需要根据HTTP的协议格式,我们需要做一些准备!
我们需要定义了一个名为 Util 的工具类,用于处理一些文件操作和字符串操作,以支持HTTP协议格式的处理。具体来说,这个类提供了以下几个功能:
读取文件内容 (ReadFileContent 方法):
-
该方法用于读取指定文件的内容,并将其存储在提供的
std::string引用中。 -
支持以二进制方式读取文件,这对于处理非文本文件(如图片)非常有用。(使用文本读取的话,我们不就对图片等这些长连接不起作用了嘛!!!)
-
首先检查文件大小,如果文件大小大于0,则打开文件,读取内容,并关闭文件。
-
如果文件无法打开或文件大小为0,则返回
false表示失败。
读取一行 (ReadOneLine 方法):
-
该方法用于从一个大字符串中读取一行,直到遇到指定的分隔符(默认为
\r\n)。 -
如果找到分隔符,它将提取并返回该行,同时更新原始字符串以排除已读取的部分。
-
如果未找到分隔符,返回
false表示失败。
获取文件大小 (FileSize 方法):
-
该方法用于获取指定文件的大小(以字节为单位)。
-
它以二进制模式打开文件,移动到文件末尾以获取文件大小,然后关闭文件。
-
如果文件无法打开,返回
-1表示失败。
这些功能的实现为处理HTTP协议中的数据提供了基础支持,例如:
-
读取HTTP请求和响应:可以读取包含HTTP请求或响应的文件,这些文件可能包含二进制数据(如图片)。
-
解析HTTP消息:通过逐行读取HTTP消息,可以解析请求行、头部字段和消息体。
-
处理文件上传和下载:在处理文件上传时,需要读取客户端发送的文件内容;在处理文件下载时,需要读取服务器上的文件内容。
通过这些工具类方法,可以更轻松地处理HTTP协议中的数据,实现HTTP服务器或客户端的功能。
#pragma once
#include <iostream>
#include <fstream>
#include <string>
// 工具类
class Util
{
public:
static bool ReadFileContent(const std::string &filename /*std::vector<char>*/, std::string *out)
{
// version1: 默认是以文本方式读取文件的. 图片是二进制的.
// std::ifstream in(filename);
// if (!in.is_open())
// {
// return false;
// }
// std::string line;
// while(std::getline(in, line))
// {
// *out += line;
// }
// in.close();
// version2 : 以二进制方式进行读取
int filesize = FileSize(filename);
if(filesize > 0)
{
std::ifstream in(filename);
if(!in.is_open())
return false;
out->resize(filesize);
in.read((char*)(out->c_str()), filesize);
in.close();
}
else
{
return false;
}
return true;
}
static bool ReadOneLine(std::string &bigstr, std::string *out, const std::string &sep/*\r\n*/)
{
auto pos = bigstr.find(sep);
if(pos == std::string::npos)
return false;
*out = bigstr.substr(0, pos);
bigstr.erase(0, pos + sep.size());
return true;
}
static int FileSize(const std::string &filename)
{
std::ifstream in(filename, std::ios::binary);
if(!in.is_open())
return -1;
in.seekg(0, in.end);
int filesize = in.tellg();
in.seekg(0, in.beg);
in.close();
return filesize;
}
};
协议构建
有了相关报文解析工具Util,我们就可以定义并简单封装HTTP的Request和Response:
五、HTTP 的方法(GET/POST重要!!!)
| 方法 | 说明 | 支持的HTTP协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINK | 断开连接关系 | 1.0 |
(一)GET 方法
-
用途 :用于请求 URL 指定的资源,通常用于获取网页内容、查询数据等操作。例如,当用户在浏览器地址栏输入网址访问网页,或者通过表单的 get 方式提交查询参数时,会使用 GET 方法。
-
特性 :指定资源经服务器端解析后返回响应内容。它的请求参数会附在 URL 后面,以 “?” 分隔,参数之间用 “&” 连接,如 “https://www.example.com/search?q=keyword&page=1”。但这种方式会使 URL 过长,且参数会暴露在浏览器地址栏中,可能带来安全风险。同时,GET 请求对数据量有一定限制,因为 URL 的长度有限。
-
与表单的关系 :在 HTML 表单中,当 method 属性设置为 “get” 时,表单提交会使用 GET 方法。例如:
<!-- 带哈希的搜索分页 -->
<form action="/search#results" method="GET">
<input type="text" name="query" placeholder="输入关键词">
<input type="number" name="page" value="1" hidden>
<button type="submit">智能搜索</button>
</form> 我们可以输入参数!!!也就是提交表单,我们也就是可以实现登录注册等操作了!!!
(二)POST 方法
-
用途 :用于传输实体的主体,通常用于提交表单数据,如用户注册、登录、提交订单等操作。它可以发送大量的数据给服务器,并且数据包含在请求体中,相对 GET 方法更安全,因为参数不会暴露在 URL 中。
-
特性 :POST 方法会将请求参数放在请求体中发送,因此可以传输较多的数据,而且数据不会显示在浏览器地址栏中。但 POST 方法通常会触发服务器上的某些处理逻辑,可能会产生副作用(如修改服务器上的数据),因此不应该被重复提交。
-
与表单的关系 :在 HTML 表单中,当 method 属性设置为 “post” 时,表单提交会使用 POST 方法。例如:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>用户注册(POST方法演示)</title>
<style>
body { font-family: 'Arial', sans-serif; line-height: 1.6; max-width: 500px; margin: 0 auto; padding: 20px; }
form { background: #f4f4f4; padding: 20px; border-radius: 8px; }
input, button { width: 100%; padding: 10px; margin: 8px 0; border: 1px solid #ddd; border-radius: 4px; }
button { background: #4285f4; color: white; cursor: pointer; }
button:hover { background: #3367d6; }
</style>
</head>
<body>
<h1>用户注册</h1>
<!--
POST方法表单关键点:
1. method="post" 声明使用POST方法
2. action="/register" 指定提交目标URL
3. enctype 默认为 application/x-www-form-urlencoded
-->
<form action="/register" method="post">
<div>
<label for="username">用户名:</label>
<input type="text" id="username" name="username" required>
</div>
<div>
<label for="password">密码:</label>
<input type="password" id="password" name="password" required>
</div>
<div>
<label for="email">邮箱:</label>
<input type="email" id="email" name="email">
</div>
<button type="submit">注册</button>
</form>
<div id="result"></div>
<script>
// 现代JavaScript的Fetch API示例(替代传统表单提交)
document.querySelector('form').addEventListener('submit', async (e) => {
e.preventDefault();
const formData = new FormData(e.target);
try {
const response = await fetch('/register', {
method: 'POST',
body: formData
// 如需JSON格式:
// headers: { 'Content-Type': 'application/json' },
// body: JSON.stringify(Object.fromEntries(formData))
});
const result = await response.json();
document.getElementById('result').innerHTML =
`<p style="color: green;">注册成功!用户ID: ${result.userId}</p>`;
} catch (error) {
document.getElementById('result').innerHTML =
`<p style="color: red;">错误: ${error.message}</p>`;
}
});
</script>
</body>
</html>(三)其他方法
-
PUT 方法 :用于传输文件,将请求报文主体中的文件保存到请求 URL 指定的位置。例如,用于上传文件到服务器的特定路径。但它不太常用,在某些情况下,如 RESTful API 中,用于更新资源。
-
HEAD 方法 :与 GET 方法类似,但不返回报文主体部分,仅返回响应头。它可用于确认 URL 的有效性及资源更新的日期时间等,有助于客户端判断资源是否需要更新,而无需下载整个资源内容。
-
DELETE 方法 :用于删除文件,是 PUT 的相反方法。按请求 URL 删除指定的资源,例如删除服务器上的某个文件或数据记录。
-
OPTIONS 方法 :用于查询针对请求 URL 指定的资源支持的方法。服务器会返回该资源允许的 HTTP 方法列表,如 “[GET, POST, OPTIONS]” 等。
六、HTTP 的状态码(重要的!!!)
| 类别 | 原因短语 | 描述 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
这个表格概述了HTTP状态码的五个主要类别,每个类别都对应着一种特定的响应情况。
(一)常见状态码
-
200 OK :表示请求成功,服务器已成功处理了客户端的请求,并返回了请求的资源。例如,正常访问网站首页时,服务器返回网页内容并附带 200 状态码。
-
404 Not Found :表示服务器无法找到请求的资源,可能是由于输入的 URL 错误、资源已被删除等原因导致。例如,当用户尝试访问一个不存在的网页链接时,服务器会返回 404 状态码。
-
403 Forbidden :表示服务器拒绝执行请求,客户端没有足够的权限访问请求的资源。例如,当用户尝试访问一个需要管理员权限的页面,但未登录或登录的用户不具备相应权限时,服务器会返回 403 状态码。
-
302 Redirect(重定向) :表示请求的资源临时被移动到新的位置。服务器会在响应中添加一个 “Location” 头部,用于指定资源的新位置。浏览器会自动重定向到该地址,但不会缓存这个重定向。例如,用户登录成功后,服务器返回 302 状态码,将用户重定向到用户首页。
-
504 Bad Gateway :表示网关或代理服务器在尝试从上游服务器(如后端应用服务器)获取数据时,没有及时收到响应。这可能是由于后端服务器故障、网络连接问题等原因导致。
(二)关于重定向的状态码
-
301 Moved Permanently :表示请求的资源已经被永久移动到新的位置。服务器会在响应中添加 “Location” 头部,指定新的 URL 地址。浏览器会自动重定向到该地址,并且在后续对该资源的请求中,会直接使用新的 URL,而无需再次向服务器请求原始 URL。例如,当网站换域名后,为了保证用户能通过旧域名访问到新域名下的内容,会设置 301 重定向。
-
302 Found 或 See Other :表示请求的资源临时被移动到新的位置。浏览器会暂时使用新的 URL 进行后续的请求,但不会缓存这个重定向,下次请求原始 URL 时仍会向服务器发送请求。例如,用户登录成功后,服务器返回 302 状态码,将用户重定向到用户首页,但下次用户访问时仍需重新登录或通过其他方式获取首页内容。
-
307 Temporary Redirect :与 302 类似,也是临时重定向,但客户端在后续请求中应继续使用原始 URL 来访问资源,除非再次收到新的重定向指令。它主要用于一些需要明确区分临时和永久重定向的场景。
-
308 Permanent Redirect :类似于 301,表示永久重定向,客户端在后续请求中应一直使用新的 URL 来访问资源。它在某些特定情况下使用,如服务器希望强制客户端更新缓存中的 URL。
七、HTTP 常见 Header
(一)请求头
-
Host :客户端告知服务器,所请求的资源是在哪个主机的哪个端口上。这对于在一台服务器上托管多个网站(通过不同的域名访问)非常重要。例如,“Host: www.example.com:8080”,其中 “www.example.com” 是主机名,“8080” 是端口号。
-
User - Agent :声明用户的操作系统和浏览器版本信息。服务器可以根据 User - Agent 来判断客户端的类型,从而返回适配的页面内容。例如,“User - Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36” 表示客户端是 Windows 10 系统、64 位架构,使用 Chrome 浏览器(版本 91.0.4472.124)等信息。
-
Referer :用于标识请求的来源 URL。当用户从一个页面链接到另一个页面时,Referer 头会记录上一个页面的 URL。这有助于网站分析流量来源、计算广告点击率等。例如,“Referer: https://www.a.com/page1.html”,表示当前请求是从 “https://www.a.com/page1.html” 页面链接过来的。
-
Cookie :用于在客户端存储少量信息,通常用于实现会话(session)的功能。服务器通过设置 Cookie 将一些数据存储在客户端,客户端在后续请求中会将这些 Cookie 发送给服务器,服务器可以根据 Cookie 来识别客户端的身份和状态。例如,“Cookie: session_id=abcdefg12345; user_id=123” 表示客户端的会话 ID 是 “abcdefg12345”,用户 ID 是 “123”。
(二)响应头
-
Content - Type :表示实体主体的媒体类型,即响应内容的类型。例如,“Content - Type: text/html” 表示响应内容是 HTML 文档,“Content - Type: application/json” 表示响应内容是 JSON 格式的数据。客户端可以根据 Content - Type 来正确解析和展示响应内容。
-
Content - Length :表示实体主体的字节大小,即响应内容的长度。服务器通过这个头告诉客户端响应体的大小,客户端可以据此预估下载时间、分配内存等。
-
Location :搭配 3xx 状态码使用,告诉客户端接下来要去哪里访问。例如,在 301 或 302 重定向响应中,“Location: https://www.new-url.com/page.html” 表示客户端应重定向到 “https://www.new-url.com/page.html” 这个新的 URL 地址。
-
Server :表示服务器类型,用于标识处理请求的服务器软件名称和版本。例如,“Server: Apache/2.4.41 (Unix)” 表示服务器使用的是 Apache 2.4.41 版本的服务器软件,在 Unix 操作系统上运行。
-
Last - Modified :表示资源的最后修改时间。客户端可以根据这个时间来判断资源是否已经更新,从而决定是否需要重新获取资源。例如,“Last - Modified: Wed, 21 Oct 2023 07:20:00 GMT” 表示资源最后在 2023 年 10 月 21 日 7 点 20 分(格林尼治时间)被修改。
-
ETag :表示资源的唯一标识符,用于缓存。与 Last - Modified 配合使用,可以更精确地判断资源是否发生变化。例如,“ETag: “3f80f-1b6-5f4e2512a4100”” 表示资源的 ETag 值为 “3f80f-1b6-5f4e2512a4100”,当客户端再次请求时,可以通过 If - None - Match 头将这个 ETag 值发送给服务器,服务器根据这个值判断资源是否被修改,若未修改则返回 304 状态码,告知客户端可以直接使用缓存内容。
-
Cache - Control :缓存控制指令。在请求时,可以设置 “Cache - Control: no - cache” 表示不使用缓存,或者 “Cache - Control: max - age=3600” 表示缓存的最大有效时间为 3600 秒。在响应时,可以设置 “Cache - Control: public, max - age=3600” 表示响应内容可以被缓存,并且缓存的最大有效时间为 3600 秒。
-
Connection :用于控制和管理客户端与服务器之间的连接状态。在 HTTP/1.1 中,默认使用持久连接(keep - alive),即连接在请求 / 响应完成后不立即关闭,以便在同一个连接上发送多个请求和接收多个响应。如果希望在 HTTP/1.0 上实现持久连接,需要在请求头中显式设置 “Connection: keep - alive”。而 “Connection: close” 表示请求 / 响应完成后,应该关闭 TCP 连接。
八、深入解析HTTP服务器实现:从静态资源到动态交互
有了上面的知识,我们下面来更好的应用,将理论和代码相结合:
在现代Web开发中,HTTP服务器是处理客户端请求和提供服务的核心组件。本文将通过一个简单的HTTP服务器实现,详细解析其工作原理,并探讨如何通过Cookie和Session实现VIP资源的访问控制。
1. 静态资源处理
静态资源包括HTML文件、CSS样式表、JavaScript脚本、图片和视频等。这些资源通常存储在服务器的文件系统中,服务器根据请求的URL直接返回相应的文件内容。
默认资源
在提供的代码中,当用户访问根目录(/)时,服务器会自动重定向到index.html页面。这是通过以下代码实现的:
if (_uri == "/")
_uri = webroot + _uri + homepage; // ./wwwroot/index.html
else
_uri = webroot + _uri; // ./wwwroot/a/b/c.html404页面
如果请求的资源不存在,服务器会返回一个404错误页面。这是通过检查请求的文件是否存在来实现的:
if (!res)
{
_text = "";
LOG(LogLevel::WARNING) << "client want get : " << _targetfile << " but not found";
SetCode(404);
_targetfile = webroot + page_404;
filesize = Util::FileSize(_targetfile);
Util::ReadFileContent(_targetfile, &_text);
std::string suffix = Uri2Suffix(_targetfile);
SetHeader("Content-Type", suffix);
SetHeader("Content-Length", std::to_string(filesize));
}2. 动态交互
除了静态资源,HTTP服务器还支持动态交互,如用户登录和注册。这通常涉及到处理POST请求和使用数据库。
GET和POST方法
-
GET方法:通常用于请求数据。在提供的代码中,GET请求的参数通过URL传递,如
/login?username=zhangsan&password=123456。 -
POST方法:用于提交数据。在POST请求中,数据通常包含在请求体中,而不是URL中。这可以通过
HttpRequest类的Deserialize方法解析请求体来实现。
安全性
在处理GET和POST请求时,安全性是一个重要考虑因素。例如,避免SQL注入、XSS攻击和CSRF攻击。在代码中,可以通过验证和清理输入数据来提高安全性。
我们可以再上一层定义一个functional,注册相关的登录认证操作等等。我们后面代码要好好看看!!!
3. 重定向
重定向是HTTP服务器的另一个重要功能,它允许服务器将客户端请求从一个URL重定向到另一个URL。
临时重定向(302)
临时重定向通常用于告诉客户端资源暂时位于不同的位置。在代码中,这可以通过设置状态码302和Location头部来实现:
SetCode(302);
SetHeader("Location", "http://example.com/newlocation");永久重定向(301)
永久重定向用于告诉客户端资源已经永久移动到新位置。这可以通过设置状态码301来实现:
SetCode(301);
SetHeader("Location", "http://example.com/newlocation");Cookie和Session管理
在网络安全领域,保护用户账号免受黑客攻击是一个重要议题。黑客盗号通常利用的是Web应用的漏洞,而保护用户账号的一个关键环节是管理用户会话。让我们从HTTP协议的特性开始,逐步探讨为什么需要使用Cookie和Session来增强安全性。
HTTP协议的无连接和无状态特性
HTTP(超文本传输协议)是构建Web应用的基础协议。它被设计为无连接(connectionless)和无状态(stateless):
-
无连接:这意味着每个HTTP请求都是独立的,客户端和服务器之间的通信在每次请求后就会关闭。服务器不保留任何关于客户端状态的信息。这种设计简化了服务器的设计,使其可以快速响应请求,但同时也意味着服务器无法识别连续的请求是否来自同一个客户端。
-
无状态:与无连接特性相关,无状态意味着每个请求从客户端发送到服务器时,服务器都无法知道客户端之前做过什么操作。这会导致比如说我们登入输入相关字段后想以登入状态访问对应权限的资源!这种特性使得HTTP协议非常灵活,但也给维护用户状态带来了挑战。
黑客盗号的威胁
黑客盗号通常利用Web应用的漏洞,如跨站脚本(XSS)、跨站请求伪造(CSRF)或会话劫持等。在没有适当会话管理的情况下,一旦黑客获取了用户的会话标识(如Cookie中的会话ID),他们就可以冒充用户身份进行操作。
Cookie的引入
为了解决HTTP的无状态问题,引入了Cookie机制。Cookie是服务器发送给客户端的一小段数据,客户端随后在每次请求时都会将这些数据发送回服务器。最初,Cookie被用来存储简单的用户偏好设置,但很快它们就被用于存储会话标识符,以跟踪用户会话。
-
第一版Cookie方式:最初的Cookie仅用于在客户端保存少量数据,如会话ID。这种方式简单但存在安全风险,因为Cookie可以被客户端的任何脚本访问,容易被恶意脚本窃取。
Session的引入
为了增强安全性,引入了Session机制。Session在服务器端存储会话数据,而客户端仅存储一个会话ID(通常存储在Cookie中)。这样,即使会话ID被窃取,没有服务器端的会话数据,攻击者也无法冒充用户身份。
-
Session的工作方式:当用户登录时,服务器创建一个Session,生成一个唯一的会话ID,并将其发送给客户端(通常通过Set-Cookie头部)。客户端在随后的请求中携带这个会话ID,服务器通过会话ID来查找对应的会话数据,从而识别用户。
为什么需要Cookie和Session
-
维护状态:尽管HTTP协议本身是无状态的,但通过使用Cookie和Session,Web应用可以维护用户状态,识别连续的请求。
-
增强安全性:通过在服务器端存储会话数据,而不是在客户端,减少了会话被劫持的风险。同时,通过设置Cookie属性(如HttpOnly和Secure),可以进一步增强安全性。
总之,Cookie和Session的结合使用是为了在无连接和无状态的HTTP协议之上,实现用户状态的维护和安全管理,从而保护用户账号免受黑客攻击。
Cookie
Cookie是服务器发送到客户端的小型数据片段,客户端会在后续请求中将其发送回服务器。Cookie通常用于存储会话信息,如用户偏好设置、会话标识符等。
在会话管理中,session ID 是一个唯一的标识符,用于标识一个客户端的会话。服务器通过这个ID来识别客户端并检索与之关联的数据。session ID 通常存储在服务器端,而客户端则通过Cookie来保存这个ID。
Path 是一个与会话Cookie相关的属性,它指定了可以访问该Cookie的URL路径。例如,如果设置Path=/,则表示整个网站的所有页面都可以访问这个Cookie。如果设置为Path=/user,则只有/user路径下的页面可以访问这个Cookie。
-
设置Cookie:
SetHeader("Set-Cookie", "username=zhangsan; Path=/; HttpOnly");这行代码设置了名为
username的Cookie,其值为zhangsan,并且只能通过HTTP请求头访问(HttpOnly属性)。 -
读取Cookie: 服务器可以在后续请求中读取客户端发送的Cookie,以识别用户或恢复会话状态。
Session
Session是服务器端存储的用户会话信息。与Cookie不同,Session数据存储在服务器端,客户端只知道Session ID。
-
创建Session: 当用户登录成功后,服务器创建一个新的Session,并生成一个唯一的Session ID。
-
存储Session: 服务器将Session ID存储在数据库或内存中,并与用户信息关联。
-
发送Session ID: 服务器通过Cookie将Session ID发送给客户端。
-
验证Session: 在后续请求中,服务器通过Cookie中的Session ID查找对应的Session信息,以验证用户身份和会话状态。
实现VIP资源访问控制
用户登录:用户通过POST请求提交登录信息。服务器验证用户名和密码。
创建Session:如果验证成功,服务器创建一个Session,并生成一个唯一的Session ID。
设置Cookie:服务器将Session ID存储在Cookie中,并发送回客户端。
访问VIP资源:用户访问VIP资源时,服务器检查Cookie中的Session ID。如果Session有效且用户有权限访问VIP资源,则返回资源内容;否则,返回403禁止访问错误。
Session过期:服务器可以设置Session的过期时间,过期后需要用户重新登录。
通过这种方式,服务器可以有效地管理用户会话,并控制对敏感资源的访问。这不仅提高了系统的安全性,还为用户提供了更好的个性化服务体验。
结论
通过上述分析,我们可以看到HTTP服务器不仅能够处理静态资源请求,还能支持动态交互、重定向、Cookie和Session等高级功能。这些功能使得HTTP服务器成为构建现代Web应用的基础。随着技术的发展,HTTP服务器的功能也在不断扩展,以满足更复杂的Web开发需求。
通过实现Cookie和Session管理,我们可以有效地控制对VIP资源的访问,确保只有经过验证的用户才能访问这些资源。这种访问控制机制在实际应用中非常重要,可以保护敏感数据和提供个性化服务。
Http.hpp
#pragma once
#include "Socket.hpp"
#include "TcpServer.hpp"
#include "Util.hpp"
#include "Log.hpp"
#include <iostream>
#include <string>
#include <memory>
#include <sstream>
#include <functional>
#include <unordered_map>
using namespace SocketModule;
using namespace LogModule;
const std::string gspace = " ";
const std::string glinespace = "\r\n";
const std::string glinesep = ": ";
const std::string webroot = "./wwwroot";
const std::string homepage = "index.html";
const std::string page_404 = "/404.html";
class HttpRequest
{
public:
HttpRequest() : _is_interact(false)
{
}
std::string Serialize()
{
return std::string();
}
void ParseReqLine(std::string &reqline)
{
// GET / HTTP/1.1
std::stringstream ss(reqline);
ss >> _method >> _uri >> _version;
}
// 实现, 我们今天认为,reqstr是一个完整的http request string
bool Deserialize(std::string &reqstr)
{
// 1. 提取请求行
std::string reqline;
bool res = Util::ReadOneLine(reqstr, &reqline, glinespace);
LOG(LogLevel::DEBUG) << reqline;
// 2. 对请求行进行反序列化
ParseReqLine(reqline);
if (_uri == "/")
_uri = webroot + _uri + homepage; // ./wwwroot/index.html
else
_uri = webroot + _uri; // ./wwwroot/a/b/c.html
LOG(LogLevel::DEBUG) << "_method: " << _method;
LOG(LogLevel::DEBUG) << "_uri: " << _uri;
LOG(LogLevel::DEBUG) << "_version: " << _version;
const std::string temp = "?";
auto pos = _uri.find(temp);
if (pos == std::string::npos)
{
return true;
}
// _uri: ./wwwroot/login
// username=zhangsan&password=123456
_args = _uri.substr(pos + temp.size());
_uri = _uri.substr(0, pos);
_is_interact = true;
// ./wwwroot/XXX.YYY
return true;
}
std::string Uri()
{
return _uri;
}
bool isInteract()
{
return _is_interact;
}
std::string Args()
{
return _args;
}
~HttpRequest()
{
}
private:
std::string _method;
std::string _uri;
std::string _version;
std::unordered_map<std::string, std::string> _headers;
std::string _blankline;
std::string _text;
std::string _args;
bool _is_interact;
};
class HttpResponse
{
public:
HttpResponse() : _blankline(glinespace), _version("HTTP/1.0")
{
}
// 实现: 成熟的http,应答做序列化,不要依赖任何第三方库!
std::string Serialize()
{
std::string status_line = _version + gspace + std::to_string(_code) + gspace + _desc + glinespace;
std::string resp_header;
for (auto &header : _headers)
{
std::string line = header.first + glinesep + header.second + glinespace;
resp_header += line;
}
return status_line + resp_header + _blankline + _text;
}
void SetTargetFile(const std::string &target)
{
_targetfile = target;
}
void SetCode(int code)
{
_code = code;
switch (_code)
{
case 200:
_desc = "OK";
break;
case 404:
_desc = "Not Found";
break;
case 301:
_desc = "Moved Permanently";
break;
case 302:
_desc = "See Other";
break;
default:
break;
}
}
void SetHeader(const std::string &key, const std::string &value)
{
auto iter = _headers.find(key);
if (iter != _headers.end())
return;
_headers.insert(std::make_pair(key, value));
}
std::string Uri2Suffix(const std::string &targetfile)
{
// ./wwwroot/a/b/c.html
auto pos = targetfile.rfind(".");
if (pos == std::string::npos)
{
return "text/html";
}
std::string suffix = targetfile.substr(pos);
if (suffix == ".html" || suffix == ".htm")
return "text/html";
else if (suffix == ".jpg")
return "image/jpeg";
else if (suffix == "png")
return "image/png";
else
return "";
}
bool MakeResponse()
{
if (_targetfile == "./wwwroot/favicon.ico")
{
LOG(LogLevel::DEBUG) << "用户请求: " << _targetfile << "忽略它";
return false;
}
if (_targetfile == "./wwwroot/redir_test")
{
SetCode(301);
SetHeader("Location", "https://www.qq.com/");
return true;
}
int filesize = 0;
bool res = Util::ReadFileContent(_targetfile, &_text); // 浏览器请求的资源,一定会存在吗?出错呢?
if (!res)
{
_text = "";
LOG(LogLevel::WARNING) << "client want get : " << _targetfile << " but not found";
SetCode(404);
_targetfile = webroot + page_404;
filesize = Util::FileSize(_targetfile);
Util::ReadFileContent(_targetfile, &_text);
std::string suffix = Uri2Suffix(_targetfile);
SetHeader("Content-Type", suffix);
SetHeader("Content-Length", std::to_string(filesize));
// SetCode(302);
// SetHeader("Location", "http://8.137.19.140:8080/404.html");
// return true;
}
else
{
LOG(LogLevel::DEBUG) << "读取文件: " << _targetfile;
SetCode(200);
filesize = Util::FileSize(_targetfile);
std::string suffix = Uri2Suffix(_targetfile);
SetHeader("Conent-Type", suffix);
SetHeader("Content-Length", std::to_string(filesize));
SetHeader("Set-Cookie", "username=zhangsan;");
// SetHeader("Set-Cookie", "passwd=123456;");
}
return true;
}
void SetText(const std::string &t)
{
_text = t;
}
bool Deserialize(std::string &reqstr)
{
return true;
}
~HttpResponse() {}
// private:
public:
std::string _version;
int _code; // 404
std::string _desc; // "Not Found"
std::unordered_map<std::string, std::string> _headers;
std::vector<std::string> cookie;
std::string _blankline;
std::string _text;
// 其他属性
std::string _targetfile;
};
using http_func_t = std::function<void(HttpRequest &req, HttpResponse &resp)>;
// 1. 返回静态资源
// 2. 提供动态交互的能力
class Http
{
public:
Http(uint16_t port) : tsvrp(std::make_unique<TcpServer>(port))
{
}
void HandlerHttpRquest(std::shared_ptr<Socket> &sock, InetAddr &client)
{
// 收到请求
std::string httpreqstr;
// 假设:概率大,读到了完整的请求
// bug!
int n = sock->Recv(&httpreqstr); // 浏览器给我发过来的是一个大的http字符串, 其实我们的recv也是有问题的。tcp是面向字节流的.
if (n > 0)
{
std::cout << "##########################" << std::endl;
std::cout << httpreqstr;
std::cout << "##########################" << std::endl;
// 对报文完整性进行审核 -- 缺
// 所以,今天,我们就不在担心,用户访问一个服务器上不存在的资源了.
// 我们更加不担心,给用户返回任何网页资源(html, css, js, 图片,视频)..., 这种资源,静态资源!!
HttpRequest req;
HttpResponse resp;
req.Deserialize(httpreqstr);
if (req.isInteract())
{
// _uri: ./wwwroot/login
if (_route.find(req.Uri()) == _route.end())
{
// SetCode(302)
}
else
{
_route[req.Uri()](req, resp);
std::string response_str = resp.Serialize();
sock->Send(response_str);
}
}
else
{
resp.SetTargetFile(req.Uri());
if (resp.MakeResponse())
{
std::string response_str = resp.Serialize();
sock->Send(response_str);
}
}
// HttpResponse resp;
// resp._version = "HTTP/1.1";
// resp._code = 200; // success
// resp._desc = "OK";
// //./wwwroot/a/b/c.html
// LOG(LogLevel::DEBUG) << "用户请求: " << filename;
// bool res = Util::ReadFileContent(filename, &(resp._text)); // 浏览器请求的资源,一定会存在吗?出错呢?
// (void)res;
}
// #ifndef DEBUG
// #define DEBUG
#ifdef DEBUG
// 收到请求
std::string httpreqstr;
// 假设:概率大,读到了完整的请求
sock->Recv(&httpreqstr); // 浏览器给我发过来的是一个大的http字符串, 其实我们的recv也是有问题的。tcp是面向字节流的.
std::cout << httpreqstr;
// 直接构建http应答. 内存级别+固定
HttpResponse resp;
resp._version = "HTTP/1.1";
resp._code = 200; // success
resp._desc = "OK";
std::string filename = webroot + homepage; // "./wwwroot/index.html";
bool res = Util::ReadFileContent(filename, &(resp._text));
(void)res;
std::string response_str = resp.Serialize();
sock->Send(response_str);
#endif
// 对请求字符串,进行反序列化
}
void Start()
{
tsvrp->Start([this](std::shared_ptr<Socket> &sock, InetAddr &client)
{ this->HandlerHttpRquest(sock, client); });
}
void RegisterService(const std::string name, http_func_t h)
{
std::string key = webroot + name; // ./wwwroot/login
auto iter = _route.find(key);
if (iter == _route.end())
{
_route.insert(std::make_pair(key, h));
}
}
~Http()
{
}
private:
std::unique_ptr<TcpServer> tsvrp;
std::unordered_map<std::string, http_func_t> _route;
};
Main.cc
#include "Http.hpp"
void Login(HttpRequest &req, HttpResponse &resp)
{
LOG(LogLevel::DEBUG) << req.Args() << ", 我们成功进入到了处理数据的逻辑";
std::string username = "zhangsan";
std::string password = "123456";
std::string args = req.Args();
std::istringstream arg_stream(args);
std::string input_username;
std::string input_password;
arg_stream >> input_username >> input_password;
if (input_username == username && input_password == password)
{
resp.SetCode(200);
resp.SetHeader("Content-Type", "text/plain");
std::string text = "登录成功";
resp.SetHeader("Content-Length", std::to_string(text.size()));
resp.SetText(text);
resp.SetHeader("Set-Cookie", "username=" + input_username + "; Path=/; HttpOnly");
}
else
{
resp.SetCode(401);
resp.SetHeader("Content-Type", "text/plain");
std::string text = "用户名或密码错误";
resp.SetHeader("Content-Length", std::to_string(text.size()));
resp.SetText(text);
}
}
void Register(HttpRequest &req, HttpResponse &resp)
{
LOG(LogLevel::DEBUG) << req.Args() << ", 我们成功进入到了处理数据的逻辑";
std::string args = req.Args();
std::istringstream arg_stream(args);
std::string username;
std::string password;
arg_stream >> username >> password;
// 假设注册逻辑成功
std::string text = "注册成功: " + username;
resp.SetCode(200);
resp.SetHeader("Content-Type", "text/plain");
resp.SetHeader("Content-Length", std::to_string(text.size()));
resp.SetText(text);
}
void VipCheck(HttpRequest &req, HttpResponse &resp)
{
LOG(LogLevel::DEBUG) << req.Args() << ", 我们成功进入到了处理数据的逻辑";
std::string text = "hello: " + req.Args();
resp.SetCode(200);
resp.SetHeader("Content-Type", "text/plain");
resp.SetHeader("Content-Length", std::to_string(text.size()));
resp.SetText(text);
}
void Search(HttpRequest &req, HttpResponse &resp)
{
// 搜索功能实现
std::string text = "搜索结果: " + req.Args();
resp.SetCode(200);
resp.SetHeader("Content-Type", "text/plain");
resp.SetHeader("Content-Length", std::to_string(text.size()));
resp.SetText(text);
}
// http port
int main(int argc, char *argv[])
{
if (argc != 2)
{
std::cout << "Usage: " << argv[0] << " port" << std::endl;
exit(USAGE_ERR);
}
uint16_t port = std::stoi(argv[1]);
std::unique_ptr<Http> httpsvr = std::make_unique<Http>(port);
httpsvr->RegisterService("/login", Login); //
httpsvr->RegisterService("/register", Register);
httpsvr->RegisterService("/vip_check", VipCheck);
httpsvr->RegisterService("/s", Search);
// httpsvr->RegisterService("/", Login);
httpsvr->Start();
return 0;
}剩下的就只是下面图示的更上一层的实现了:相关资源的写入:
 我们自己可以根据AI,就可以玩起来了!!!
我们自己可以根据AI,就可以玩起来了!!!
九、HTTP 历史及版本核心技术与时代背景
看看,理解一下就好了,有兴趣的可以下去看看新特性!!!
(一)HTTP/0.9
核心技术 :
-
仅支持 GET 请求方法,只能用于获取资源,功能单一。
-
仅支持纯文本传输,主要是 HTML 格式,无法传输其他类型的数据。
-
无请求和响应头信息,无法传递额外的属性和元数据。
时代背景 :1991 年,HTTP/0.9 版本作为 HTTP 协议的最初版本,用于传输基本的超文本 HTML 内容。当时的互联网还处于起步阶段,网页内容相对简单,主要以文本为主,对协议的要求也不高,这个版本满足了当时最基本的信息传输需求。
(二)HTTP/1.0
核心技术 :
-
引入 POST 和 HEAD 请求方法,扩展了对服务器的操作方式,POST 可用于向服务器发送数据,HEAD 可用于获取资源的头部信息而不获取实体主体。
-
请求和响应头信息,支持多种数据格式(MIME),使得服务器可以返回不同类型的内容,如图片、音频等。
-
支持缓存(cache),客户端可以缓存部分资源,减少对服务器的重复请求,提高访问效率。
-
状态码(status code)、多字符集支持等,丰富了服务器对请求的响应方式和内容的表达。
时代背景 :1996 年,随着互联网的快速发展,网页内容逐渐丰富,用户对网络应用的需求不断增加,HTTP/1.0 版本应运而生,以满足日益增长的网络应用需求。然而,HTTP/1.0 的工作方式是每次 TCP 连接只能发送一个请求,性能上存在一定局限,因为每次请求都需要建立和关闭连接,增加了网络开销和服务器的负担。
(三)HTTP/1.1
核心技术 :
-
引入持久连接(persistent connection),支持管道化(pipelining)。持久连接允许客户端和服务器在请求 / 响应完成后不立即关闭 TCP 连接,以便在同一个连接上发送多个请求和接收多个响应,减少了连接建立和关闭的次数,提高了性能。管道化则允许客户端在等待上一个请求响应的同时发送下一个请求,进一步提高了数据传输效率。
-
允许在单个 TCP 连接上进行多个请求和响应,有效提高了性能,特别是在获取多个资源(如网页中的图片、脚本文件等)时,减少了连接的开销。
-
引入分块传输编码(chunked transfer encoding),将响应体分割成多个部分,每个部分以一个包含部分大小的首行和部分本身的数据块的形式发送,使得服务器可以边生成响应边发送,而无需事先知道整个响应体的大小,这对于动态生成的响应(如根据用户输入实时生成的内容)非常有用。
-
支持 Host 头,允许在一个 IP 地址上部署多个 Web 站点,通过 Host 头中的域名信息,服务器可以将请求路由到不同的网站,提高了服务器资源的利用率。
时代背景 :1999 年,随着网页加载的外部资源越来越多(如图片、样式表、脚本文件等),HTTP/1.0 的性能问题愈发突出。HTTP/1.1 通过引入持久连接和管道化等技术,有效提高了数据传输效率,满足了当时互联网应用多元化、复杂化的趋势。
(四)HTTP/2.0
核心技术 :
-
多路复用(multiplexing),一个 TCP 连接允许多个 HTTP 请求和响应同时传输,多个请求和响应可以在同一个连接上并行交错地传输,避免了 HTTP/1.1 中的 “队头阻塞” 问题(即后发出的请求可能因为前面的请求未完成而被阻塞),大大提高了数据传输效率。
-
二进制帧格式(binary framing),优化了数据传输。将 HTTP 协议的数据封装成二进制帧格式,使得数据的解析更加高效,减少了传输过程中的错误和延迟。
-
头部压缩(header compression),减少传输开销。由于 HTTP 请求和响应的头部通常包含大量重复的信息,通过压缩头部可以减少数据传输量,加快数据传输速度。
-
服务器推送(server push),提前发送资源到客户端。服务器可以主动将客户端可能需要的资源提前推送给客户端,而无需客户端逐一请求,例如在客户端请求 HTML 页面时,服务器可以同时推送该页面引用的 CSS、JavaScript 文件等,减少了客户端获取资源的往返时间。
时代背景 :2015 年,随着移动互联网的兴起和云计算技术的发展,网络应用对性能的要求越来越高。移动设备的网络带宽有限且网络状况不稳定,需要更高效的协议来优化数据传输。HTTP/2.0 通过多路复用、二进制帧格式等技术,显著提高了数据传输效率和网络性能,同时它还支持加密传输(HTTPS),提高了数据传输的安全性。
(五)HTTP/3.0
核心技术 :
-
使用 QUIC 协议替代 TCP 协议,基于 UDP 构建的多路复用传输协议。QUIC 协议在传输层对连接进行了优化,减少了连接建立的时间(如减少了 TCP 的三次握手及 TLS 握手时间),提高了连接建立速度。同时,UDP 是一种无连接的传输层协议,具有较低的开销和延迟,使得 HTTP/3.0 在传输数据时更加高效,特别适用于对实时性要求较高的应用场景,如视频直播、实时游戏等。
-
解决了 TCP 中的线头阻塞问题,提高了数据传输效率。在 TCP 中,当某个数据包丢失时,后续的数据包可能会被阻塞,等待丢失数据包的重传和确认。而 HTTP/3.0 使用的 QUIC 协议基于 UDP,通过在应用层对数据流进行管理,使得即使某个数据包丢失,也不会影响其他数据包的传输和处理,从而提高了数据传输的效率和可靠性。
时代背景 :2022 年,随着 5G、物联网等技术的快速发展,网络应用对实时性、可靠性的要求越来越高。5G 网络提供了更高的带宽和更低的延迟,但同时也对传输协议提出了更高的要求。HTTP/3.0 通过使用 QUIC 协议,充分利用了 5G 网络的优势,提高了连接建立速度和数据传输效率,满足了这些新兴技术下的网络应用需求。同时,HTTP/3.0 也支持加密传输(HTTPS),保证了数据传输的安全性。
附录
下面是我们为更好的理解HTTP,首先建立好的连接!!!😁
Common.hpp
#pragma once
#include <iostream>
#include <functional>
#include <unistd.h>
#include <string>
#include <cstring>
#include <sys/socket.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <netinet/in.h>
enum ExitCode
{
OK = 0,
USAGE_ERR,
SOCKET_ERR,
BIND_ERR,
LISTEN_ERR,
CONNECT_ERR,
FORK_ERR,
OPEN_ERR
};
class NoCopy
{
public:
NoCopy(){}
~NoCopy(){}
NoCopy(const NoCopy &) = delete;
const NoCopy &operator = (const NoCopy&) = delete;
};
#define CONV(addr) ((struct sockaddr*)&addr)
InetAddr.hpp
#pragma once
#include "Common.hpp"
// 网络地址和主机地址之间进行转换的类
class InetAddr
{
public:
InetAddr() {}
InetAddr(struct sockaddr_in &addr)
{
SetAddr(addr);
}
InetAddr(const std::string &ip, uint16_t port) : _ip(ip), _port(port)
{
// 主机转网络
memset(&_addr, 0, sizeof(_addr));
_addr.sin_family = AF_INET;
inet_pton(AF_INET, _ip.c_str(), &_addr.sin_addr);
_addr.sin_port = htons(_port);
// local.sin_addr.s_addr = inet_addr(_ip.c_str()); // TODO
}
InetAddr(uint16_t port) : _port(port), _ip()
{
// 主机转网络
memset(&_addr, 0, sizeof(_addr));
_addr.sin_family = AF_INET;
_addr.sin_addr.s_addr = INADDR_ANY;
_addr.sin_port = htons(_port);
}
void SetAddr(struct sockaddr_in &addr)
{
_addr = addr;
// 网络转主机
_port = ntohs(_addr.sin_port); // 从网络中拿到的!网络序列
// _ip = inet_ntoa(_addr.sin_addr); // 4字节网络风格的IP -> 点分十进制的字符串风格的IP
char ipbuffer[64];
inet_ntop(AF_INET, &_addr.sin_addr, ipbuffer, sizeof(_addr));
_ip = ipbuffer;
}
uint16_t Port() { return _port; }
std::string Ip() { return _ip; }
const struct sockaddr_in &NetAddr() { return _addr; }
const struct sockaddr *NetAddrPtr()
{
return CONV(_addr);
}
socklen_t NetAddrLen()
{
return sizeof(_addr);
}
bool operator==(const InetAddr &addr)
{
return addr._ip == _ip && addr._port == _port;
}
std::string StringAddr()
{
return _ip + ":" + std::to_string(_port);
}
~InetAddr()
{
}
private:
struct sockaddr_in _addr;
std::string _ip;
uint16_t _port;
};
Log.hpp
#ifndef __LOG_HPP__
#define __LOG_HPP__
#include <iostream>
#include <cstdio>
#include <string>
#include <filesystem> //C++17
#include <sstream>
#include <fstream>
#include <memory>
#include <ctime>
#include <unistd.h>
#include "Mutex.hpp"
namespace LogModule
{
using namespace MutexModule;
const std::string gsep = "\r\n";
// 策略模式,C++多态特性
// 2. 刷新策略 a: 显示器打印 b:向指定的文件写入
// 刷新策略基类
class LogStrategy
{
public:
~LogStrategy() = default;
virtual void SyncLog(const std::string &message) = 0;
};
// 显示器打印日志的策略 : 子类
class ConsoleLogStrategy : public LogStrategy
{
public:
ConsoleLogStrategy()
{
}
void SyncLog(const std::string &message) override
{
LockGuard lockguard(_mutex);
std::cout << message << gsep;
}
~ConsoleLogStrategy()
{
}
private:
Mutex _mutex;
};
// 文件打印日志的策略 : 子类
const std::string defaultpath = "/var/log/";
const std::string defaultfile = "my.log";
class FileLogStrategy : public LogStrategy
{
public:
FileLogStrategy(const std::string &path = defaultpath, const std::string &file = defaultfile)
: _path(path),
_file(file)
{
LockGuard lockguard(_mutex);
if (std::filesystem::exists(_path))
{
return;
}
try
{
std::filesystem::create_directories(_path);
}
catch (const std::filesystem::filesystem_error &e)
{
std::cerr << e.what() << '\n';
}
}
void SyncLog(const std::string &message) override
{
LockGuard lockguard(_mutex);
std::string filename = _path + (_path.back() == '/' ? "" : "/") + _file; // "./log/" + "my.log"
std::ofstream out(filename, std::ios::app); // 追加写入的 方式打开
if (!out.is_open())
{
return;
}
out << message << gsep;
out.close();
}
~FileLogStrategy()
{
}
private:
std::string _path; // 日志文件所在路径
std::string _file; // 日志文件本身
Mutex _mutex;
};
// 形成一条完整的日志&&根据上面的策略,选择不同的刷新方式
// 1. 形成日志等级
enum class LogLevel
{
DEBUG,
INFO,
WARNING,
ERROR,
FATAL
};
std::string Level2Str(LogLevel level)
{
switch (level)
{
case LogLevel::DEBUG:
return "DEBUG";
case LogLevel::INFO:
return "INFO";
case LogLevel::WARNING:
return "WARNING";
case LogLevel::ERROR:
return "ERROR";
case LogLevel::FATAL:
return "FATAL";
default:
return "UNKNOWN";
}
}
std::string GetTimeStamp()
{
time_t curr = time(nullptr);
struct tm curr_tm;
localtime_r(&curr, &curr_tm);
char timebuffer[128];
snprintf(timebuffer, sizeof(timebuffer),"%4d-%02d-%02d %02d:%02d:%02d",
curr_tm.tm_year+1900,
curr_tm.tm_mon+1,
curr_tm.tm_mday,
curr_tm.tm_hour,
curr_tm.tm_min,
curr_tm.tm_sec
);
return timebuffer;
}
// 1. 形成日志 && 2. 根据不同的策略,完成刷新
class Logger
{
public:
Logger()
{
EnableConsoleLogStrategy();
}
void EnableFileLogStrategy()
{
_fflush_strategy = std::make_unique<FileLogStrategy>();
}
void EnableConsoleLogStrategy()
{
_fflush_strategy = std::make_unique<ConsoleLogStrategy>();
}
// 表示的是未来的一条日志
class LogMessage
{
public:
LogMessage(LogLevel &level, std::string &src_name, int line_number, Logger &logger)
: _curr_time(GetTimeStamp()),
_level(level),
_pid(getpid()),
_src_name(src_name),
_line_number(line_number),
_logger(logger)
{
// 日志的左边部分,合并起来
std::stringstream ss;
ss << "[" << _curr_time << "] "
<< "[" << Level2Str(_level) << "] "
<< "[" << _pid << "] "
<< "[" << _src_name << "] "
<< "[" << _line_number << "] "
<< "- ";
_loginfo = ss.str();
}
// LogMessage() << "hell world" << "XXXX" << 3.14 << 1234
template <typename T>
LogMessage &operator<<(const T &info)
{
// a = b = c =d;
// 日志的右半部分,可变的
std::stringstream ss;
ss << info;
_loginfo += ss.str();
return *this;
}
~LogMessage()
{
if (_logger._fflush_strategy)
{
_logger._fflush_strategy->SyncLog(_loginfo);
}
}
private:
std::string _curr_time;
LogLevel _level;
pid_t _pid;
std::string _src_name;
int _line_number;
std::string _loginfo; // 合并之后,一条完整的信息
Logger &_logger;
};
// 这里故意写成返回临时对象
LogMessage operator()(LogLevel level, std::string name, int line)
{
return LogMessage(level, name, line, *this);
}
~Logger()
{
}
private:
std::unique_ptr<LogStrategy> _fflush_strategy;
};
// 全局日志对象
Logger logger;
// 使用宏,简化用户操作,获取文件名和行号
#define LOG(level) logger(level, __FILE__, __LINE__)
#define Enable_Console_Log_Strategy() logger.EnableConsoleLogStrategy()
#define Enable_File_Log_Strategy() logger.EnableFileLogStrategy()
}
#endif
Mutex.hpp
#pragma once
#include <iostream>
#include <pthread.h>
namespace MutexModule
{
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&_mutex, nullptr);
}
void Lock()
{
int n = pthread_mutex_lock(&_mutex);
(void)n;
}
void Unlock()
{
int n = pthread_mutex_unlock(&_mutex);
(void)n;
}
~Mutex()
{
pthread_mutex_destroy(&_mutex);
}
pthread_mutex_t *Get()
{
return &_mutex;
}
private:
pthread_mutex_t _mutex;
};
class LockGuard
{
public:
LockGuard(Mutex &mutex) : _mutex(mutex)
{
_mutex.Lock();
}
~LockGuard()
{
_mutex.Unlock();
}
private:
Mutex &_mutex;
};
}Socket.hpp
#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <cstdlib>
#include "Common.hpp"
#include "Log.hpp"
#include "InetAddr.hpp"
namespace SocketModule
{
using namespace LogModule;
const static int gbacklog = 16;
// 模版方法模式
// 基类socket, 大部分方法,都是纯虚方法
class Socket
{
public:
virtual ~Socket() {}
virtual void SocketOrDie() = 0;
virtual void BindOrDie(uint16_t port) = 0;
virtual void ListenOrDie(int backlog) = 0;
virtual std::shared_ptr<Socket> Accept(InetAddr *client) = 0;
virtual void Close() = 0;
virtual int Recv(std::string *out) = 0;
virtual int Send(const std::string &message) = 0;
virtual int Connect(const std::string &server_ip, uint16_t port) = 0;
public:
void BuildTcpSocketMethod(uint16_t port, int backlog = gbacklog)
{
SocketOrDie();
BindOrDie(port);
ListenOrDie(backlog);
}
void BuildTcpClientSocketMethod()
{
SocketOrDie();
}
// void BuildUdpSocketMethod()
// {
// SocketOrDie();
// BindOrDie();
// }
};
const static int defaultfd = -1;
class TcpSocket : public Socket
{
public:
TcpSocket() : _sockfd(defaultfd)
{
}
TcpSocket(int fd) : _sockfd(fd)
{
}
~TcpSocket() {}
void SocketOrDie() override
{
_sockfd = ::socket(AF_INET, SOCK_STREAM, 0);
if (_sockfd < 0)
{
LOG(LogLevel::FATAL) << "socket error";
exit(SOCKET_ERR);
}
LOG(LogLevel::INFO) << "socket success";
}
void BindOrDie(uint16_t port) override
{
InetAddr localaddr(port);
int n = ::bind(_sockfd, localaddr.NetAddrPtr(), localaddr.NetAddrLen());
if (n < 0)
{
LOG(LogLevel::FATAL) << "bind error";
exit(BIND_ERR);
}
LOG(LogLevel::INFO) << "bind success";
}
void ListenOrDie(int backlog) override
{
int n = ::listen(_sockfd, backlog);
if (n < 0)
{
LOG(LogLevel::FATAL) << "listen error";
exit(LISTEN_ERR);
}
LOG(LogLevel::INFO) << "listen success";
}
std::shared_ptr<Socket> Accept(InetAddr *client) override
{
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int fd = ::accept(_sockfd, CONV(peer), &len);
if (fd < 0)
{
LOG(LogLevel::WARNING) << "accept warning ...";
return nullptr; // TODO
}
client->SetAddr(peer);
return std::make_shared<TcpSocket>(fd);
}
// n == read的返回值
int Recv(std::string *out) override
{
// 流式读取,不关心读到的是什么
char buffer[4096];
ssize_t n = ::recv(_sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
*out += buffer; // 故意
}
return n;
}
int Send(const std::string &message) override
{
return send(_sockfd, message.c_str(), message.size(), 0);
}
void Close() override //??
{
if (_sockfd >= 0)
::close(_sockfd);
}
int Connect(const std::string &server_ip, uint16_t port) override
{
InetAddr server(server_ip, port);
return ::connect(_sockfd, server.NetAddrPtr(), server.NetAddrLen());
}
private:
int _sockfd; // _sockfd , listensockfd, sockfd;
};
// class UdpSocket : public Socket
// {
// };
}TcpServer.hpp
#include "Socket.hpp"
#include <iostream>
#include <memory>
#include <sys/wait.h>
#include <functional>
using namespace SocketModule;
using namespace LogModule;
using ioservice_t = std::function<void(std::shared_ptr<Socket> &sock, InetAddr &client)>;
class TcpServer
{
public:
TcpServer(uint16_t port) : _port(port),
_listensockptr(std::make_unique<TcpSocket>()),
_isrunning(false)
{
_listensockptr->BuildTcpSocketMethod(_port);
}
void Start(ioservice_t callback)
{
_isrunning = true;
while (_isrunning)
{
InetAddr client;
auto sock = _listensockptr->Accept(&client); // 1. 和client通信sockfd 2. client 网络地址
if (sock == nullptr)
{
continue;
}
LOG(LogLevel::DEBUG) << "accept success ..." << client.StringAddr();
// sock && client
pid_t id = fork();
if (id < 0)
{
LOG(LogLevel::FATAL) << "fork error ...";
exit(FORK_ERR);
}
else if (id == 0)
{
// 子进程 -> listensock
_listensockptr->Close();
if (fork() > 0)
exit(OK);
// 孙子进程在执行任务,已经是孤儿了
callback(sock, client);
sock->Close();
exit(OK);
}
else
{
// 父进程 -> sock
sock->Close();
pid_t rid = ::waitpid(id, nullptr, 0);
(void)rid;
}
}
_isrunning = false;
}
~TcpServer() {}
private:
uint16_t _port;
std::unique_ptr<Socket> _listensockptr;
bool _isrunning;
};
















 9220
9220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









