







目录
本文说明:2023的暑假中mysql的学习~ 学习的内容的侧重点不同于学校的理论,而是工作、面试中可能经常出现的内容~ 本文更针对小白和稍微有一些了解的同学所讲解~
一、数据库介绍
0x00 什么是数据库
数据库是一个广义的概念:
表示 “数据库” 这一门学科。研究如何设计实现一个数据库(造轮子)
表示一类软件,用来有效管理数据
......
我们这里介绍的是mysql数据库管理软件。学科啥的太抽象了~
0x01 数据库软件
数据库的软件大致可以分为下面几种:
Oracle : 数据库软件中的大哥。但是因为软件要收费,而且Oracle数据库在使用的时候,必须搭配IBM的小型机(不是一般我们用的电脑),才能发挥出十成功力, 但是小型机很贵,所以使用Oracle数据库的成本太高了,一般都是银行这种不差钱,且要保存非常重要的数据的公司才会使用。
MySQL:开源&免费的数据库(白嫖能不香嘛)!不过已经被Oracle公司收购了~ 钞能力的强大 ~
SQLSever:微软做的数据库,但是最初的时候,由于只支持Windows系统,而且还收费,而使用数据库的场景一般是服务器开发,用到的系统大多是Linux,所以到现在用的公司不是很多~
SQLite:主打一个轻便。运行速度快,占用内存小,经常在嵌入式设备(智能冰箱、洗衣机、空调......)中使用~
redis:与上面的数据库不同的是,redis是“非关系型数据库”。
补充:
关系型数据库(比较传统的数据库),是使用“表”这样的结构来组织数据的,对数据的格式要求较高,也就是说每一行的每一列都得与设置的含义匹配上。举个例子:我们创建一个int的二维数组, 里面就只能存放int型的数据,而非关系型,就类似创建一个object的二维数组,里面可以存放不止一种类型的数据。
非关系型数据库,更加灵活,通常使用“文档”、“键值对”这样的结构来组织数据,也就是说一行/条数据差异可以很大~
0x02 MySQL结构
MySQL使用的是cs的结构,就是“客户端-服务器”结构。
客户端:主动发起请求的一方
服务器:被动响应客户端请求的一方。由于服务器不知道客户端什么时候请求,因此服务器需要一直等待~
补充:
当客户端的数量越来越多的时候,那么他们对服务器的请求也越来越多,这就要求服务器要增加性能来应对这些请求,但是往后增加性能的成本会越来越高,因此,就出现了“分布式系统”,也就是说一台机器,既可以是服务器,也可以是客户端。当机器A想要请求资源的时候,可以对机器B发起,然后B可以看看自己有没有资源,没有的话就向其他机器请求,在这里面每一个就是一个对等体,所以也可以叫做peer to peer的模式。
虽然MySQL是客户端-服务器的结构,但是我们真实的数据是存储在硬盘上的,而服务器才是MySQL的本体,负责存储和管理数据~
二、数据库操作
0x00 创建数据库
create database [if not exists] 数据库名 charset 字符集名字;
#说明
#[]里面的内容是可加可不加的~
#if not exists 可以用来避免报错,使用场景是当我们要执行一系列的SQL语句时,如果存在了同名数据库,此时依旧会执行后面的SQL语句
#charset 也可以写成 character set 可以指定当前数据库使用什么编码方式
#在写完SQL语句后要加;号,表示此行语句写完了,因为mysql客户端允许你输入的时候换行补充:
不同的字符集,会产生不同的编码方式,也就是说在不同的字符集下,一个汉字占用几个字节是不同的。例如:gbk编码,一个汉字占用2个字节,utf8编码,一个汉字占3个字节。
0x01 查看所有数据库
show databases;
#列出当前mysql服务器上一共有哪些数据库0x02 选中数据库
use 数据库名;
#当我们想要对数据进行操作的时候,我们首先要选中数据库,可以理解为指向性技能~0x03 删除数据库
drop database 数据库名;
#删除一个数据库,会删除里面的所有内容,非常危险(从删库到跑路~)
#当年炉石服务器就发生了严重的数据问题,服务器选择了回档,但还好补偿够给力,玩家选择了集体失忆~三、表操作
0x 00 字段类型
一些常用的类型。一般够用了,如果有特殊场景可以去网上再查查~
| 数据类型 | 大小 | 说明 | 对应java类型 |
|---|---|---|---|
| int | 4字节 | Integer | |
| bigint | 8字节 | Long | |
| double | 8字节 | Double | |
| decimal(M,D) | M/D最大值+2 | M指定数的长度,D表示小数点显示到D位数 | BigDecimal |
| varchar(N) | 0-65535字节 | 可变长度字符串,N表示字符串长度 | String |
| datetime | 8字节 | 插入格式:“YY-MM-DD 00:00:00” | java.util.Date |
有了这些类型,那么就可以开始创建一张表,开始存储数据了~
0x 01 创建表
create table 表名(列名 类型, 列名 类型......);
#创建一张表,指定列的属性0x 02 查看所有表
show tables;
#查看当前数据库中所有的表0x 03 查看表结构
desc 表名;
#查看指定表的结构
#desc 的全称是 describe 描述0x 04 删除表
drop table 表名;
#删除指定表,比较危险需要慎重四、SQL的增删改查
增删改查也称crud,全称create、read、update、delete,是数据库非常基础的部分,也是后端开发工作中主要的一部分。
0x 00 插入数据
insert into 表名 values (值, 值......);
#此处的值需要和表的列进行一一对应, 也就是值的个数和类型要匹配
insert into 表名 (列名, 列名......) values (值, 值......);
#此处的值需要和前面的列名匹配,如果有的列没有赋值,会进行赋默认值
insert into 表名 values (值, 值......), (值, 值......);
#一次插入多个数据,相比于分多次插入会有性能的提升。因为每次一次操作客户端都要向服务器请求,服务器要响应,这一定会影响性能。0x 01 删除数据
delete from 表名 where 条件;
#删除表中某一行数据
#如果不加where的话,将会删除表中所有数据!0x 02 修改数据
update 表名 set 列名 = 值 where 条件;
#将表中某一列的值修改
#如果不加where的话,将会修改表中所有数据!0x 03 查询数据
3.1 全列查询
select * from 表名;
#把表中所有行所有列的数据查询出来
# * 表示通配符,代指所有列补充:
select * 是一个危险操作。如果当前这个表的数据特别多,可能会把硬盘的IO跑满, 此时其他程序想要访问硬盘,会非常慢。而且由于是客户端-服务器的结构,我们是通过客户端发起请求,然后服务器通过网络将查询的结构返回给客户端,此时数据太多的话, 可能会把网卡的带宽跑满,其他客户端通过网络访问服务器将非常慢~
3.2 指定列查询
select 列名, 列名...... from 表名 ;
#指定查询表中指定列的数据3.3 查询字段为表达式
select 列名 + 10 from 表名;
#一边查询,一边进行计算
#这里的操作不会对真正的数据库中的数据进行修改,相当于临时的3.4 别名
select 列名 as 别名 from 表名;
#将某一列查询后面改个名字,一般配套表达式使用
#这里的as可以省略也可以不省略(通常建议不省略,防止看花眼)~3.5 去重
select distinct 列名, 列名...... from 表名;
# distinct 修饰某个列/多个列, 此时查询的结果中相同的数据只会保留一个3.6 排序
select 列名, 列名...... from 表名 order by 列名 desc/asc;
#以某一列的数值为准,进行排序操作
#如果写了desc 那就是降序,如果不写或者写了asc 那就是升序补充:
如果order by 列1, 列2, 列3 写了多个字段,那么会先按照字段的顺序进行排序,比如,现在回先按照列1进行排序,如果列1的值相同,那么再比较列2 ,以此往复~
3.7 条件查询
select 列名 from 表名 where 条件;条件中存在着一些运算符,我们来认识一下~
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于,推荐写成 != |
| between a0 and a1 | 范围匹配,[a0, a1] 都是闭区间,如果 a0 <= value <= a1,返回 TRUE(1) |
| in (n1, n2, .....) | 离散化,如果是 (n1, n2, ......) 中的任意一个,返回 TRUE(1) |
| is null | 是 null |
| is not null | 不是null |
| like | 模糊匹配。后面可以接通配符类似于癞子,或者%表示大于等于0个字符,_表示一个字符 |
还有一些逻辑运算符~
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE( |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
注意:
where 条件可以使用表达式,但不能使用别名。
因为select 条件查询的执行顺序:
遍历表中每个记录
根据记录的值带入条件,根据条件进行筛选
如果这个记录条件成立,则保留当前记录,然后进行列上的表达式计算(或者重命名啥的)
如果有order by, 再进行排序
所以,在条件筛选的优先级高于列上的表达式计算,因此使用别名的话,sql服务器就不认识了~
3.8 分页查询
select 列名 from 表名 limit n offset x;
#offset是偏移量的意思,也可以理解为下标
#从下标为x的记录(第一条记录的下标为0)开始, 查询出 n 条记录以上都是基础的SQL查询语句,不过很实用~
五、约束
有时候,数据库中数据是有约束的,比如 性别列,你不能填一些奇奇怪怪的数据~
如果靠人为的来对数据进行检索约束的话,肯定是不行的,人肯定会犯错~因此就需要让计算机对插入的数据进行约束要求!
约束的使用语法:
create 表名 (列名 类型 约束);
#在创建表的时候对某一列数据进行约束操作在mysql中提供了如下约束:
| 约束 | 说明 |
|---|---|
| not null | 某一列的数据不能为null值 |
| unique | 某一列中的值唯一 |
| default | 规定没有给某列赋值时为默认值 |
| primary key | not null 和 unique 的结合。记录身份的标识,一般配合自增主键使用 |
| foreign key | 保证一个表中的数据匹配另一个表中的值的参照完整性 |
| check | 保证列中的值符合指定条件 |
注意:
使用约束的话,一定会数据库的效率有影响!
由于not null、 unique、default、check比较容易,这里就对主键(primary key)和外键(foreign key) 进行解释。
主键primary key
主键可以理解为记录的身份标识,就像身份证一样是我们每个人的身份标识,既不能为空,又不能重复。
一张表里只能有一个主键,毕竟是身份标识嘛,存在多个了,以谁为准???
虽然主键只能有一个,但是主键不一定是一列,可以用多个列共同构成主键(联合主键)。
由于主键具有unique属性,因此我们一般配合mysql中 ”自增主键” 来使用,也就是会自动分配一个逐个增长的值~
语法:
create table 表名 (列名 类型 primary key auto_increment);如果手动插入一个数据,此时数据库会与主键最高的值进行比较,如果高了就更新,此后自动分配的值也会从这个最高值进行增长!
拓展:
如果是分布式系统,在同一时间插入了一个数据,此时自增主键就会出错,那么如何处理这种并发场景呢?
一般会使用一个公式来形成主键:
分布式主键值 = 时间戳 + 机房编号/主机号 + 随机因子 此处使用的是字符串拼接操作!!!
前面两个可以防止在同一时间不同机器的的主键冲突,后面的随机因子可以防止同一时间同一机器的主键冲突,但是理论上还是有可能存在冲突的~
外键foreign key
案例引入:
现在我们有两张表,一张是学生表,里面有学号、姓名、班级号字段,另一张表示班级表,里面有班级号、班级名字段。
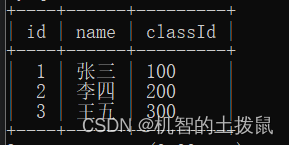
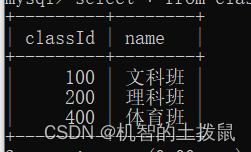
我们细细观察,可以发现,肯定是先有班级表,学生的班级号才能确定,但是现在突然冒出了一个classId 为 300的学生,但是在我们的班级表中不存在这个班级号,为了防止这种情况发生,我们可以使用外键约束~
语法:
create table 表名 (列名 类型, 列名 类型, ......, foreign key (列名) references 主表名(列名));
#我们创建学生表的时候可以这样写:
#create table student (id int, name varchar(20), classId int, foreign key (classId) references class(classId));
#student表的classId 的所有数据都要出自于class表的classId这一列,也就是说如果class表中没有这个班级号,那么我们插入的学生信息将会报错~使用外键之后,被约束的表就称为子表, 另一张表相对的就是父表,子表中的那一个字段的数据都要出自父表。当然,力的作用是相互的,约束也不例外,当我们想要删除/修改父表的约束子表的那个字段,如果子表已经引用过了,那么我们将会删除/修改失败
注意:
父表中约束子表的字段必须为主键或者unique!!!
六、表的设计
在实际的场景中,有大量的数据,我们需要明确当前要创建几个表,每个表有什么字段,这些表中是否存在一定的联系。
因此根据实际开发就整理出了三大范式~
一对一
例如:一个学生只有一个账号,一个账号只属于一个学生。
此时我们设计两张表,让其中的一张表存储另一张表的唯一属性,这样我们可以通过这个属性就能找到想要的值了。或者也可以将两张表整合,成为一张表。

一对多
例如:一个学生只能属于一个班级,一个班级可以拥有多个学生。
此时我们设计两张表,将那个“一”的表中添加上“多”的表中的唯一的字段。
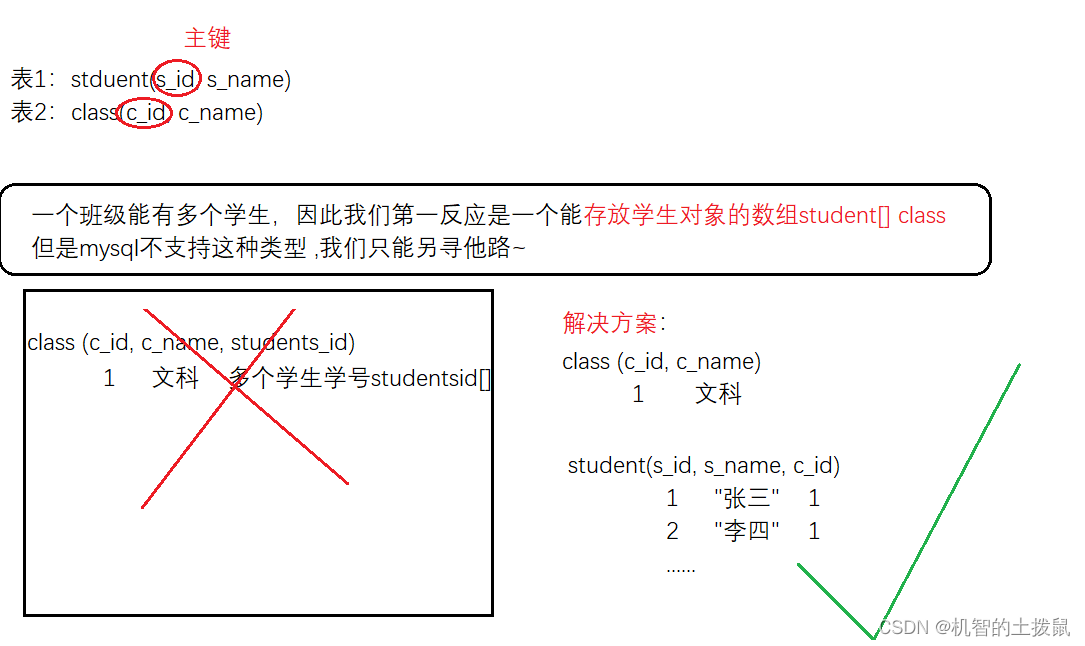
补充:
如果是redis这种能够支持数组类型的数据库,我们可以不这样设计,可以使用一个数组类型,用来存储多个学生。如下图:
多对多
例如:一个学生可以选多门课程,一个课程可以被多名学生选择。
此时我们需要再创建一张表来描述这两张表之间的关系。

七、查询增强(进阶)
查询操作有很多的花样,但一般实际开发中最最最常使用的还是前面基础的crud操作。
0x 00 聚合查询
之前的表达式查询是对于一条记录上的列与列之间进行运算的,如果要针对行与行之间进行运算呢?这时候就要用到聚合查询了~
首先来了解一些聚合函数:
| 函数 | 说明 |
|---|---|
| count() | 返回查询数据的个数 |
| sum() | 返回查询数据的总和,不是数字没意义 |
| avg() | 返回查询数据的平均值,不是数字没意义 |
| max() | 返回查询数据的最大值,不是数字没意义 |
| min() | 返回查询数据的最小值,不是数字没意义 |
语法:
select count([distinct]表达式) from 表名;
select sum([distinct]表达式) from 表名;
select avg([distinct]表达式) from 表名;
select max([distinct]表达式) from 表名;
select min([distinct]表达式) from 表名;
#注意:
#count(*) 和 count(列名)的区别,count(*)会把一条为null的数据也统计进去,而count(列名)则不会
#如果计算字符串的值,需要字符串合法,因为mysql会尝试转成double0x 01 分组查询
分组查询一般会配合聚合查询,因为分组查询会把几行数据看做是一行,如果不使用聚合查询,那么显示的结果为一组中某一个数据。
举例:
求各班的平均成绩:
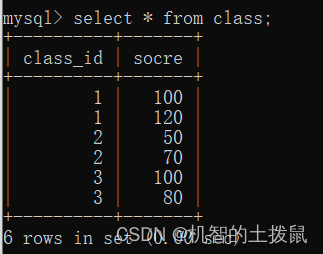
那么我们的代码得这样写:
select class_id, avg(socre) from class group by class_id;
使用group by的时候,还可以搭配条件。此时我们需要区分该条件是分组前的,还是分组之后的?
如果是分组前,使用where条件查询
如果是分组后,使用having条件查询
举例:
查询各班平均分,但是学生成绩不能超过100
select class_id, avg(socre) from class where socre <= 100 group by class_id;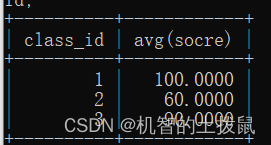
查询平均分大于100分的班级
select class_id, avg(score) from class group by class_id having avg(score) > 100;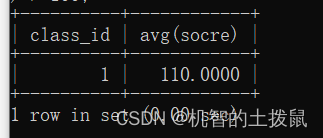
0x 02 联合查询
联合查询也就是多表查询,就是在多张表上进行查询。但是联合查询也会有一些问题......
联合查询会产生笛卡尔积,也就是说表A中的每一条数据都会与表B中每一条数据进行组合,如果A表中的数据个数为100,表B中的数据个数为100,那么最终会产生100*100条数据。但是仔细观察,会发现有一些数据是“非法”的。笛卡尔积是简单的排列组合,穷举所有情况,因此你我们需要筛选数据~
如果要联合n张表进行查询,那么我们需要使用n-1个连接条件,才不会出现笛卡尔积的现象~
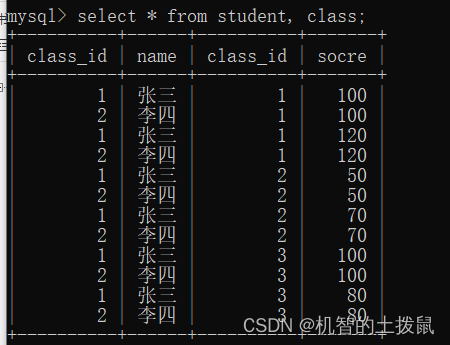
此时就出现了笛卡尔积,但是仔细观察,会发现class_id 不同的数据都组合到了一起,因此我们需要一个连接条件。
select student.class_id,
student.name,
class.socre from student,
class where student.class_id = class.class_id;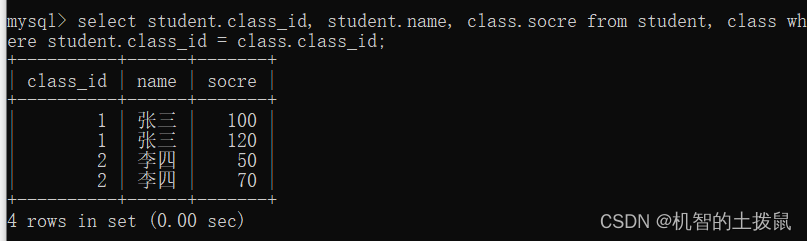
由于多表查询一般比较复杂,我们可以按照如下的步骤来写:
1、先进行指定哪个几个表,进行笛卡尔积
2、指定连接条件,去除笛卡尔积
3、精简列数据
以上查询都是基于“内连接“的操作,然而mysql还提供了”外连接“(左外连接,右外连接)
案例引入:
现有如下表

此时student的每一条记录都可以在score表中找到对应,每一个score中记录也可以在student表中找到对应。
此时我们使用外内接或者内连接查询的结果是一样。
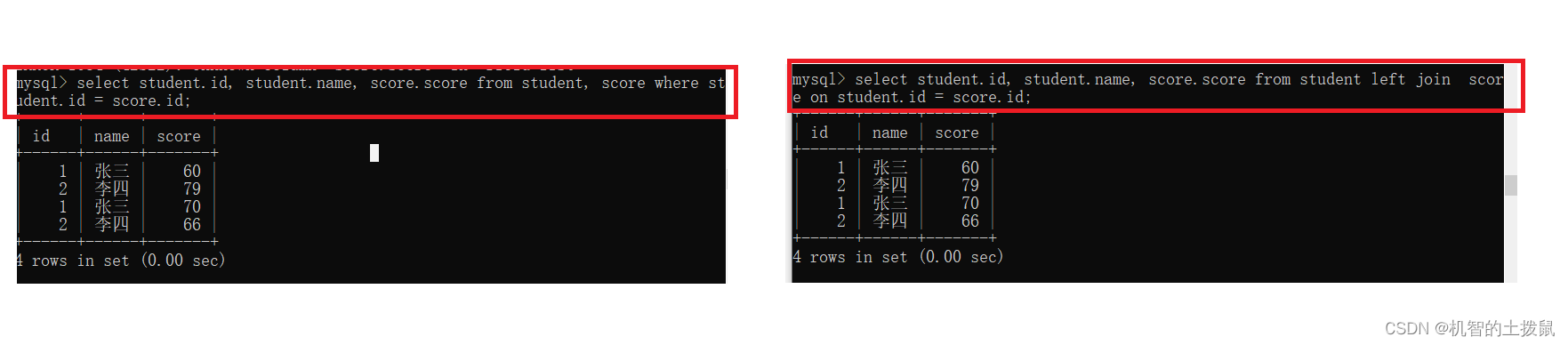
但是如果不存在记录,那么内连接与外连接就会天差地别~
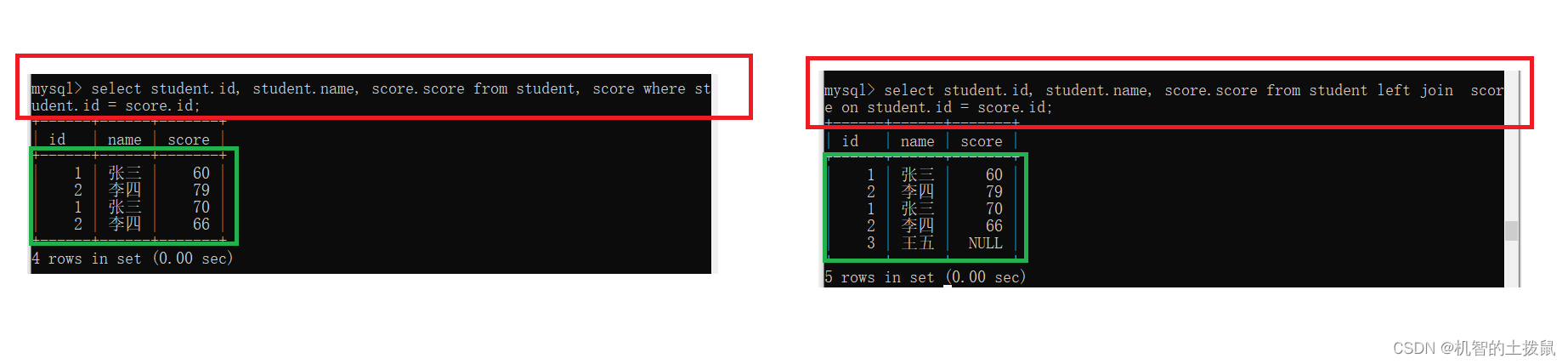
外连接分为左外连接和右外连接。
左外连接:以左表为基准,保证左侧表的每个数据都会出现在最终的结果集里,如果右表没有与之对应的记录则显示null。
select 列名 from 表名1 left join 表2 on 连接条件右外连接:以右表为基准,保证右侧表的每个数据都会出现在最终的结果集里,如果左表没有与之对应的记录则显示null。
select 列名 from 表名1 right join 表2 on 连接条件我们还可以用集合图来表示这些连接的关系:
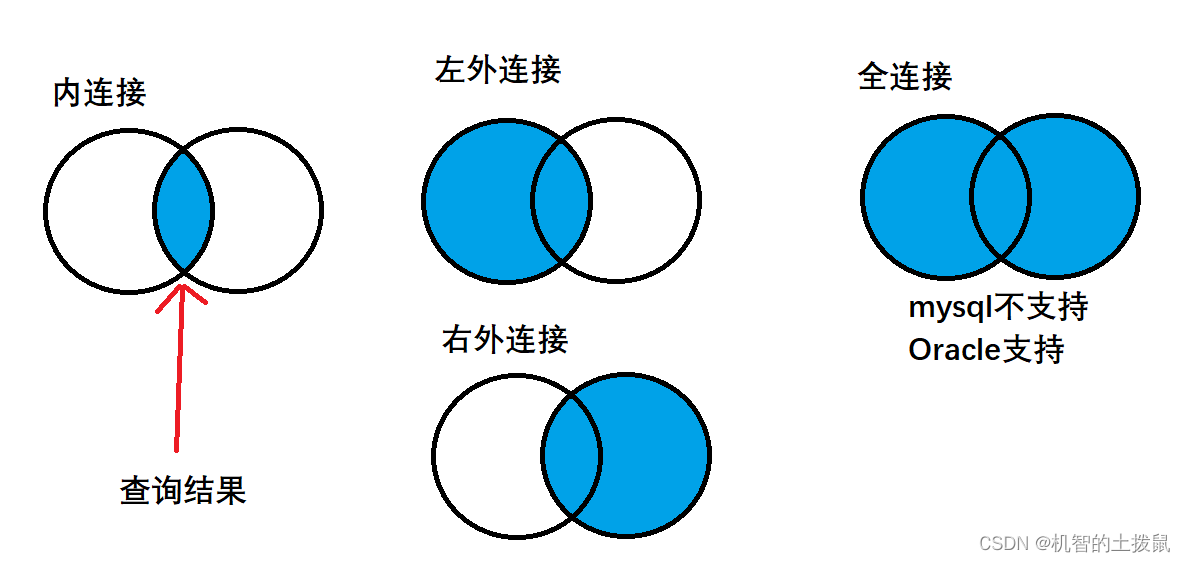
补充:
以上我们都是针对于两个表进行联合查询的,但我们甚至还可以将一个表当做两个表来进行联合查询,这样我们就能在一张表中进行 行与行的比较~这种连接方式一般被称为“内连接”。
自连接的查询跟上面的联合查询基本没什么区别,需要注意将两张表进行别名操作~
0x 03 子查询
子查询是将多个简单的SQL语句拼成一个复杂的SQL, 也就是说将某一个查询的结果看做是一张表,然后进行操作,但本质是在套娃。因此我们实际也是可以用简单的查询完成子查询的操作的~ (合成2048?合成复杂SQL!)
语法形式:
select 列名 from 表名 where 列名 = (select 列名 from 表名 where 列名 = (套娃下去....));0x 04 合并查询
合并查询就是将多个sql的查询结果集 合并在一起。合并的两个sql结果集的列,需要匹配,列的个数和类型得是一致的!合并的时候是会进行去重的,如果不想要去重,得使用 union all
select 列名1 列名2 from 表1 union [all] select 列名3 列名4 from 表2;最终结果:
八、索引
由于我们在使用数据库的时候,大部分操作的都是查询操作,但是我们每一次进行查询都需要遍历一遍表中所有数据,这会花费O(n)的时间,因此数据引入了“索引” 也就是在底层使用了数据结构来进行优化查询的操作,但是可能会造成插入/删除操作变慢和消耗空间。
语法:
show index from 表名;
#查看表中哪一列有索引
create index 索引名字 on 表名(列名);
#对某一列创建索引
drop index 索引名 on 表名;
#删除索引注意:
一个索引是针对列来指定的。只有针对这一列进行查询时,查询速度才能被索引优化~如果进行全列查询的话,那还是需要遍历表的。
如果某一列被primary key、foreign key、unique所约束的话,会自动创建索引。
创建索引也是一个相当危险的操作,因为创建索引是需要对现有的数据进行大规模的整理,如果数据非常多,很容易就把服务器卡住,一般来说创建索引的时候都是在创建完表后立马操作,一旦使用久了的话, 需要慎重操作。不过也可以采用分治的思想,一点一点将数据写入到创建好的表中~
以上内容都是基础的知识,但是面试常考查的是索引的底层~~
(由于本人水平有限,在此先简单介绍简单的内容知识~)
索引的底层使用的是一种类似二叉搜索树(在极端情况下,二叉搜索树的时间复杂度为O(n),AVL树,红黑树能达到O(logn))的树 ,也就是一棵改进的树形结构:B+树。可能会好奇,为啥不用哈希表呢?时间复杂度可以O(1),这是因为在查询的过程中我们往往会进行范围查询,而哈希表只能进行精确的查询,因此我们不使用哈希表。

B+树顾名思义是在B树的基础上改进的。那啥是B树呢?
B树:是一棵N叉搜索树,每个节点的度不确定,一个节点上保存N个数据的值,划分出N + 1个区间,每个区间衍生出一棵子树。
逻辑上存储结果如下:
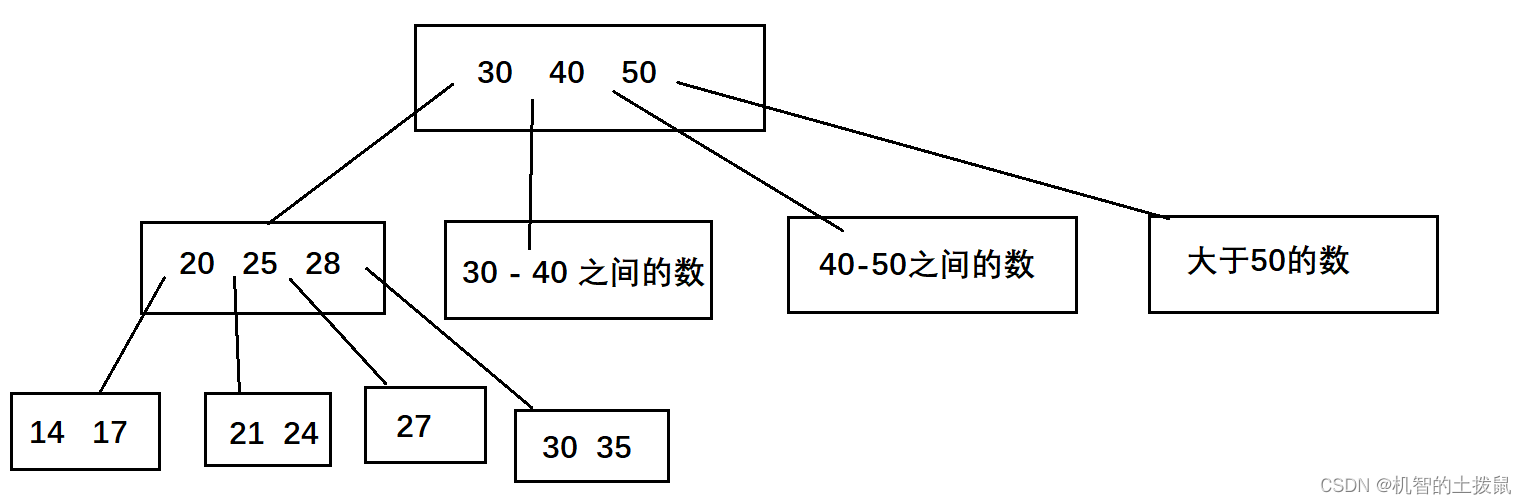
而B+树则是对B树的改进,感觉像是针对数据库进行量身定做。
如果使用B树会有遇到什么问题呢?假如我们现在要使用范围查询去查询10-40之间的数。我们在如下图中进行观察:
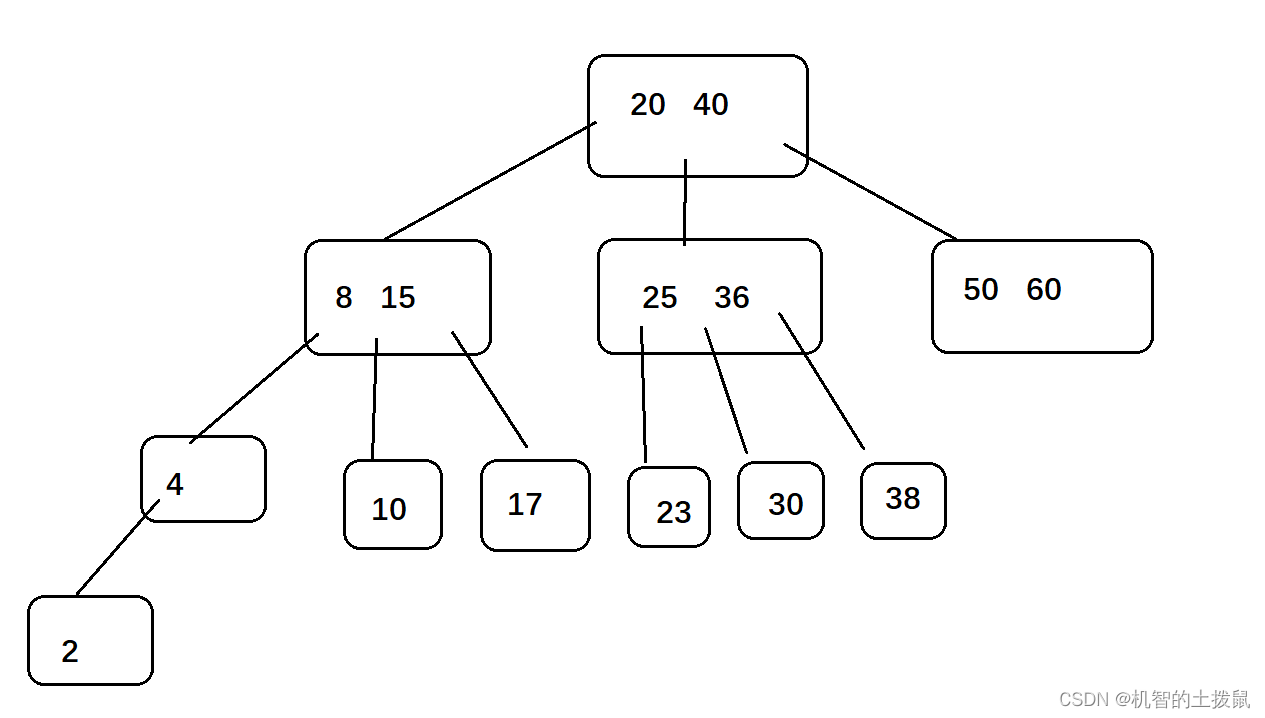
搜索过程大致如下:
我们先要进行小于20区间的搜索,然后再进行20-40区间的搜索,里面包含大量“向下递”(需要开辟内存空间),”回溯“的操作,如果一棵区间子树的高度较高,我们需要花费较多时间进行这个子树的搜索,恰巧另一些范围内的数据在另一棵子树上,那么我们又要花费较多时间进行搜索。总的来说,由于范围查询,我们有时要搜索多棵子树,这会导致效率的下降。
基于这些缺点,B+树进行了优化。首先,B+数在每个非叶子节点上存储的是索引(B树上就是实际的值),所有数据都是存储在叶子节点上,B+树再使用了一个链表,将所有叶子节点连了起来,这就导致了范围查询更加高效,因为只要找到了一个符合要求的叶子节点,我们就直接对链表进行遍历,省去了再搜索其他子树的操作。
B+树的优点(相比B树、哈希、红黑树):
1、是一棵N叉搜索树,因此树的高度比较小。
2、磁盘IO次数更少,效率更高。
红黑树是一棵平衡二叉搜索树,为了平衡需要进行旋转操作,而旋转操作时针对于整棵树的,但是因为数据库中可能存储着大量的数据,我们往往不能将所有的数据读取到内存中,因此需要部分多次读取,这就导致了旋转可能会有问题且效率不高,而且也无法利用磁盘预读(存储器某一个位置被访问了,那么其附近位置也会被访问)。
在B树中,每一个节点是在一个硬盘区域中,可以利用磁盘预读,一次读硬盘就能取出整个节点(多个键值对)。而读取硬盘的时间远大于内存比较的时间,近似于 读一次硬盘 = 内存1w次比较。
在B+树中,非叶子节点上是存的索引信息,而对应数据库中一行数据可能内容比较多,但是单单某一行的某一列(索引)所占空间往往只有几个字节,因此我们能够将所有的索引信息读取到内存中进行比较,然后找到叶子节点上的值,再通过链表遍历的方式进行搜索,从而大大减少了IO次数。
3、所有的查询最终要落实到叶子节点,因此整体的查询效率比较稳定,而B树中可能在前面的节点就能找到,复杂度为O(1), 不稳定。
4、非常擅长范围查询
九、事务
事务:一组数据库的操作语句,这些操作将会被视为一个整体,保证要么这些语句全部执行,要么“一个都不执行”。
0x 00 案例引入

现在,SQL语句执行完了第一条但是还没执行第二条的时候,突然电脑关机/程序崩溃了.......
张三一看已经扣了钱,但是李四却没有收到,这就很尴尬了。此时我们需要引入“事务”,来帮助我们解决这个问题,也就是要么张三扣了钱,李四收到了钱,要么就无事发生~ 我们将这种“要么全部执行,要么相当于没有执行”这个特殊的性质称为“原子性”
0x 01 事务的特性ACID
1、原子性(Atomicity) :事务出现的原因。将一系列sql语句看成一个整体,要么全部执行,要么通过回滚的方式,恢复如初。
2、 一致性(Consistency) :事务执行之前和之后,数据都不能出现非法的情况。
3、 持久性(Durability) :事务做出的修改,都是在硬盘上持久保存的,即使在系统故障或者崩溃的情况下,事务执行的修改都是有效的。
4、隔离性(Isolation) :由于mysql是客户端-服务器的模式,会存在并发的情况,即多个用户在同一时间请求服务器。事务的执行是相互隔离的,一个事务的操作不应该影响其他事务的操作。
补充:
并发操作往往能提高效率,但是会降低准确性。mysql数据库在并发执行的时候,会遇到如下问题:
1、脏读:
事务A在改变(修改,增加,删除) 数据
事务B在事务A未提交的时候就来读取数据
后来事物A可能在事物B读完了数据后又修改了或者回滚了,此时事务B读到数据就是“脏”的,即无效的。
脏读也就是在写的过程中进行读操作。 解决脏读问题,思路是对写操作进行加锁,告诉事务B在我写的时候,不要来读取数据。此时并发性降低了,隔离性提高了,效率降低了,准确性提高了~
2、不可重复读:
事务B在读取数据
事务A修改或删除了数据然后提交事务
事务B第二次读数据的时候,发现两次读到的数据不相同,也就是事务A在事物B两次读取的时候进行了修改。
不可重复读也就是在读的过程中进行了写操作。解决不可重复读问题,思路是对读操作进行加锁,告诉事务A在我读的时候,不要来修改数据。
3、幻读:
事务B在读数据
事务A此时插入了数据然后提交了事务
事务B第二次读数据,然后读到了与第一不一样的结果集。
幻读与不可重复读类似,区别在于幻读是强调插入操作,不可重读是修改操作。解决幻读的问题,思路是引入串行化的方式,保证绝对的串行执行事务,此时完全没有并发了。
针对以上的问题,mysql提供了4种隔离级别,可以在mysql配置文件中修改~
| 隔离级别 | 解决问题 |
|---|---|
| read uncommitted(读未提交) | 隔离性最低,但效率最高 |
| read committed(读已提交) | 给写加锁,解决脏读 |
| repeatable read(可重复读) | 给读、写加锁,解决脏读、不可重复读、幻读问题 |
| serializable(串行化) | 严格按照串行的方式,一个一个执行事务,解决脏读、不可重复读、幻读 |
0x 02 操作语句
start transaction; #开启事务
进行一些列sql语句......
rollback; #回滚事务,恢复到未执行事务前
commit; #提交事务
#事务的使用很简单,但需要关注事务背后的一些原理性质的内容十、JDBC
0x 00 什么是JDBC
JDBC代表Java连接数据库,也就是通过Java代码操作数据库。
在初期,市面上有着许多的数据库,如:MySQL, Oracle, SQL Sever.......但是不同的数据库大概率是由不同的程序员所开发出来的,因此在使用方面存在差异(如:方法名,类名,功能不同),这就大大的增加了程序员的难度,苦不堪言~这时候就需要一个真正有分量的大佬来一统江湖!!!于是Java就自己设计出一套API的规范,让各种各样的数据库都要遵守,因此java程序员只需要会一套自己的API就好了,大大减少了学习成本~

各厂商实现了接口后将其打包好并发布,如果Java程序员想要操作MySQL的话,只需要导入MySQL实现的jar包,然后在程序中调佣Java自己制定的API即可。其他如果数据库也同理,不过需要导入不同厂家的jar包。
0x 01导入jar包
在使用Java操作数据库前需要先将下载好的jar包(可以去中央仓库下载)导入程序。
Maven Repository: mysql » mysql-connector-java (mvnrepository.com)
然后就可以在程序中使用了。
0x 02 使用JDBC
1、创建DataSource
public class Main {
public static void main(String[] args) {
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource).setUser("root");
((MysqlDataSource) dataSource).setPassword("root");
}
}在这里我们可以看到,我们创建了一个dataSource,但是使用的时候却进行了向下转型,那为什么不直接创建一个MysqlDataSource的呢?这是因为要降低代码的耦合度,让MysqlDataSource这个类名不要扩散到代码的其他地方,如果后续要操作别的数据库了,代码的改动比较小。
那Url是什么呢?url表示网络上的资源位置通俗讲就是网址,因为服务器是cs模式,需要通过网络交互。
127.0.0.1 表示IP地址,描述网络上一个主机所在的位置,不过这个IP地址是一个“环回IP”,即自己把数据发给自己。这是因为jdbc程序和mysql服务器都在我们自己的电脑上~
3306 表示端口号,用来区分不同进程的。
test 表示数据库名称。
?& /...... 这些符号是一些特殊符号。这里从?后面,表示访问资源的时候,需要哪些参数
useSSL=false 表示是否要加密
这里dataSource光写url的话 只能找到mysql服务器,但还得登录认证,因此还需要设置账号,密码。
2、和数据库服务器建立连接
public class Main {
public static void main(String[] args) throws Exception{
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource).setUser("root");
((MysqlDataSource) dataSource).setPassword("root");
Connection connection = dataSource.getConnection();
}
}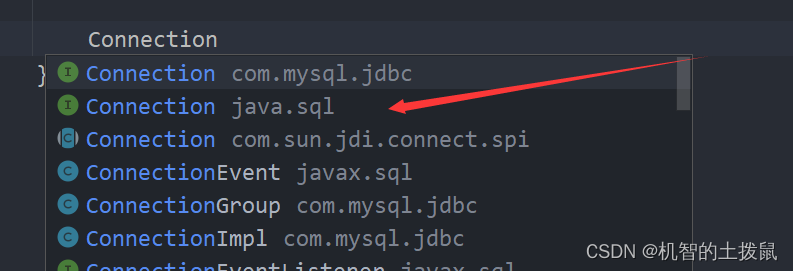
在创建的时候千万不要选错!!!
3、构造sql语句并执行
public class Main {
public static void main(String[] args) throws Exception{
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource).setUser("root");
((MysqlDataSource) dataSource).setPassword("root");
Connection connection = dataSource.getConnection();
String sql = "insert into student values(1, '张三')";
PreparedStatement statement = connection.prepareStatement(sql);
int n = statement.executeUpdate(); //看看修改了几条
}
}这里通过使用preparedStatement进行对sql语句的检查,在将sql发给服务器之前先看看有没有语法错误啥的,这样就能减小mysql服务器的开销。
如果要执查询操作的话,要使用executeQuery()方法,如果是改操作的话,使用executeUpdate()方法。
4、执行完后关闭连接,释放资源
程序通过代码和服务器进行通信,是需要消耗一定的资源的。因此在程序结束后需要告知服务器,释放这些资源。
public class Main {
public static void main(String[] args) throws Exception{
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource).setUser("root");
((MysqlDataSource) dataSource).setPassword("root");
Connection connection = dataSource.getConnection();
String sql = "insert into student values(1, '张三')";
PreparedStatement statement = connection.prepareStatement(sql);
int n = statement.executeUpdate();
statement.close();
connection.close();
}
}后申请的先释放!!!
0x 03自定义sql语句
刚刚我们是为了演示总得流程,所以sql语句就在程序中写死了,如果我们要插入我们想要的数据该怎么办呢?
方案一:
创建变量让用户输入赋值修改就行。
String sql = "insert into sutdent values (" + id + ", '" + name + "')";这样写,既不优雅,也不安全。这么多符号很容易出错,然后如果用户是高手,懂sql注入的话,那就危险了。name一栏不好好写,写成 删库 那就惨了。
方案二:
创建变量并使用占位符。
String sql = "insert into student values(?, ?)";
statement.setInt(1, id); //当心第一个是从1位置开始计算的,而不是0
statement.setString(2, name);这样就好多了~
0x 04 输出查询结果
查询在数据库操作中是大头,怎么将查询结果输出呢?
public class Main {
public static void main(String[] args) throws Exception{
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource) dataSource).setUser("root");
((MysqlDataSource) dataSource).setPassword("root");
Connection connection = dataSource.getConnection();
String sql = "select * from student";
PreparedStatement statement = connection.prepareStatement(sql);
ResultSet resultSet = statement.executeQuery();
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.println(id + "," + name);
}
resultSet.close();
statement.close();
connection.close();
}我们的查询结果返回的是一张临时表,此时需要使用ResultSet类来接收结果集。然后要进行遍历ResultSet才能取出全部数据。
遍历ResultSet是通过调用next方法获取临时表中的每一行数据。这个next方法相当于在临时表中有一个“光标”,一开始的时候指向的是第一行的前一个位置,而每一次执行,就相当于将光标移到下一行。如果走到最后一行,将会放回false。
resultSet中提供了getXXX方法,里面的参数是列名,这样就可以拿到一行中的某一列数据了。
最后记得要释放result资源~
以上就是一些mysql中高频常用的知识了~
完结,撒花~~














 235
235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









