







一、约束
有时候,数据库中数据是有约束的,比如 性别列,你不能填一些奇奇怪怪的数据~
如果靠人为的来对数据进行检索约束的话,肯定是不行的,人肯定会犯错~因此就需要让计算机对插入的数据进行约束要求!
约束的使用语法:
create 表名 (列名 类型 约束);
#在创建表的时候对某一列数据进行约束操作在mysql中提供了如下约束:
| 约束 | 说明 |
|---|---|
| not null | 某一列的数据不能为null值 |
| unique | 某一列中的值唯一 |
| default | 规定没有给某列赋值时为默认值 |
| primary key | not null 和 unique 的结合。记录身份的标识,一般配合自增主键使用 |
| foreign key | 保证一个表中的数据匹配另一个表中的值的参照完整性 |
| check | 保证列中的值符合指定条件 |
注意:
使用约束的话,一定会数据库的效率有影响!
由于not null、 unique、default、check比较容易,这里就对主键(primary key)和外键(foreign key) 进行解释。
主键primary key
主键可以理解为记录的身份标识,就像身份证一样是我们每个人的身份标识,既不能为空,又不能重复。
一张表里只能有一个主键,毕竟是身份标识嘛,存在多个了,以谁为准???
虽然主键只能有一个,但是主键不一定是一列,可以用多个列共同构成主键(联合主键)。
由于主键具有unique属性,因此我们一般配合mysql中 ”自增主键” 来使用,也就是会自动分配一个逐个增长的值~
语法:
create table 表名 (列名 类型 primary key auto_increment);如果手动插入一个数据,此时数据库会与主键最高的值进行比较,如果高了就更新,此后自动分配的值也会从这个最高值进行增长!
拓展:
如果是分布式系统,在同一时间插入了一个数据,此时自增主键就会出错,那么如何处理这种并发场景呢?
一般会使用一个公式来形成主键:
分布式主键值 = 时间戳 + 机房编号/主机号 + 随机因子 此处使用的是字符串拼接操作!!!
前面两个可以防止在同一时间不同机器的的主键冲突,后面的随机因子可以防止同一时间同一机器的主键冲突,但是理论上还是有可能存在冲突的~
外键foreign key
案例引入:
现在我们有两张表,一张是学生表,里面有学号、姓名、班级号字段,另一张表示班级表,里面有班级号、班级名字段。
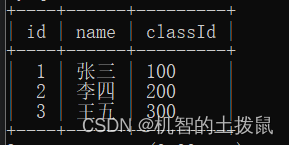
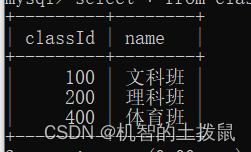
我们细细观察,可以发现,肯定是先有班级表,学生的班级号才能确定,但是现在突然冒出了一个classId 为 300的学生,但是在我们的班级表中不存在这个班级号,为了防止这种情况发生,我们可以使用外键约束~
语法:
create table 表名 (
列名 类型,
列名 类型,
......,
foreign key (列名)
references 主表名(列名));
#我们创建学生表的时候可以这样写:
#create table student (
id int,
name varchar(20),
classId int,
foreign key (classId) references class(classId));
#student表的classId 的所有数据都要出自于class表的classId这一列,
#也就是说如果class表中没有这个班级号,那么我们插入的学生信息将会报错~使用外键之后,被约束的表就称为子表, 另一张表相对的就是父表,子表中的那一个字段的数据都要出自父表。当然,力的作用是相互的,约束也不例外,当我们想要删除/修改父表的约束子表的那个字段,如果子表已经引用过了,那么我们将会删除/修改失败
注意:
父表中约束子表的字段必须为主键或者unique!!!
二、表的设计
在实际的场景中,有大量的数据,我们需要明确当前要创建几个表,每个表有什么字段,这些表中是否存在一定的联系。
因此根据实际开发就整理出了三大范式~
一对一
例如:一个学生只有一个账号,一个账号只属于一个学生。
此时我们设计两张表,让其中的一张表存储另一张表的唯一属性,这样我们可以通过这个属性就能找到想要的值了。或者也可以将两张表整合,成为一张表。

一对多
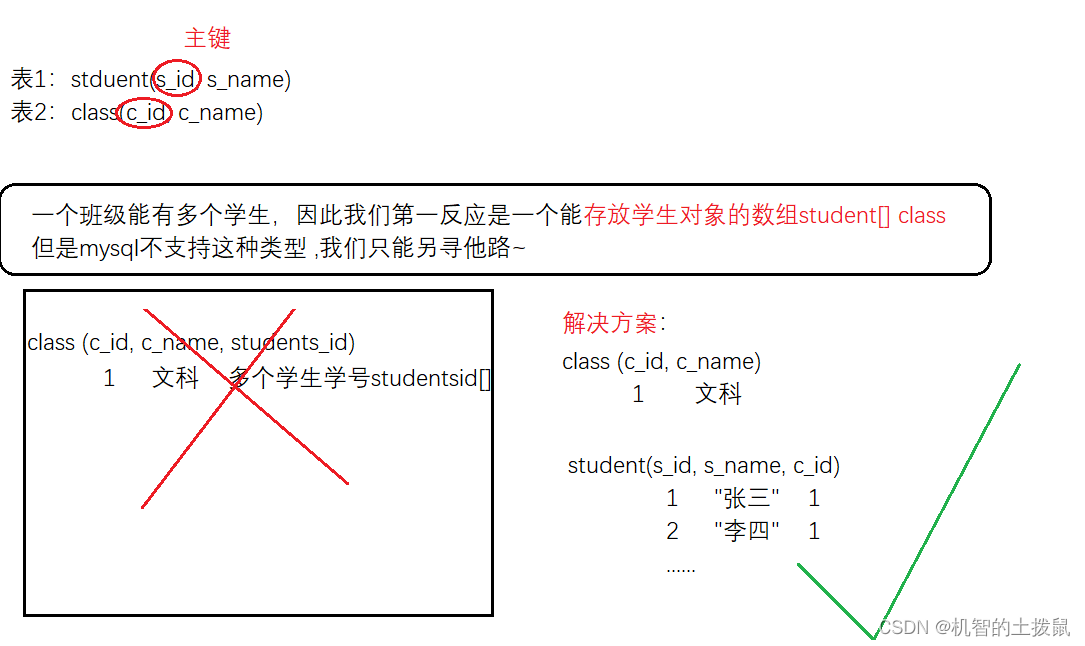
例如:一个学生只能属于一个班级,一个班级可以拥有多个学生。
此时我们设计两张表,将那个“一”的表中添加上“多”的表中的唯一的字段。
补充:
如果是redis这种能够支持数组类型的数据库,我们可以不这样设计,可以使用一个数组类型,用来存储多个学生。如下图:
多对多
例如:一个学生可以选多门课程,一个课程可以被多名学生选择。
此时我们需要再创建一张表来描述这两张表之间的关系。

三、查询增强(进阶)
查询操作有很多的花样,但一般实际开发中最最最常使用的还是前面基础的crud操作。
0x 00 聚合查询
之前的表达式查询是对于一条记录上的列与列之间进行运算的,如果要针对行与行之间进行运算呢?这时候就要用到聚合查询了~
首先来了解一些聚合函数:
| 函数 | 说明 |
|---|---|
| count() | 返回查询数据的个数 |
| sum() | 返回查询数据的总和,不是数字没意义 |
| avg() | 返回查询数据的平均值,不是数字没意义 |
| max() | 返回查询数据的最大值,不是数字没意义 |
| min() | 返回查询数据的最小值,不是数字没意义 |
语法:
select count([distinct]表达式) from 表名;
select sum([distinct]表达式) from 表名;
select avg([distinct]表达式) from 表名;
select max([distinct]表达式) from 表名;
select min([distinct]表达式) from 表名;
#注意:
#count(*) 和 count(列名)的区别,count(*)会把一条为null的数据也统计进去,而count(列名)则不会
#如果计算字符串的值,需要字符串合法,因为mysql会尝试转成double0x 01 分组查询
分组查询一般会配合聚合查询,因为分组查询会把几行数据看做是一行,如果不使用聚合查询,那么显示的结果为一组中某一个数据。
举例:
求各班的平均成绩:
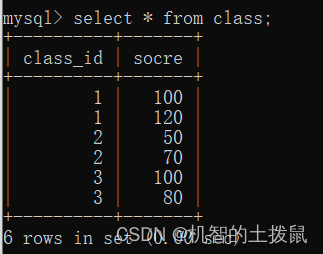
那么我们的代码得这样写:
select class_id, avg(socre) from class group by class_id;
使用group by的时候,还可以搭配条件。此时我们需要区分该条件是分组前的,还是分组之后的?
如果是分组前,使用where条件查询
如果是分组后,使用having条件查询
举例:
查询各班平均分,但是学生成绩不能超过100
select class_id, avg(socre) from class where socre <= 100 group by class_id;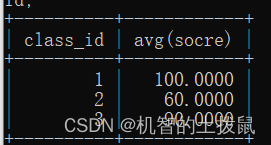
查询平均分大于100分的班级
select class_id, avg(score) from class group by class_id having avg(score) > 100;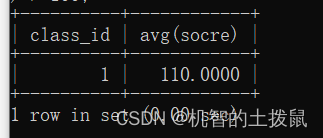
0x 02 联合查询
联合查询也就是多表查询,就是在多张表上进行查询。但是联合查询也会有一些问题......
联合查询会产生笛卡尔积,也就是说表A中的每一条数据都会与表B中每一条数据进行组合,如果A表中的数据个数为100,表B中的数据个数为100,那么最终会产生100*100条数据。但是仔细观察,会发现有一些数据是“非法”的。笛卡尔积是简单的排列组合,穷举所有情况,因此你我们需要筛选数据~
如果要联合n张表进行查询,那么我们需要使用n-1个连接条件,才不会出现笛卡尔积的现象~
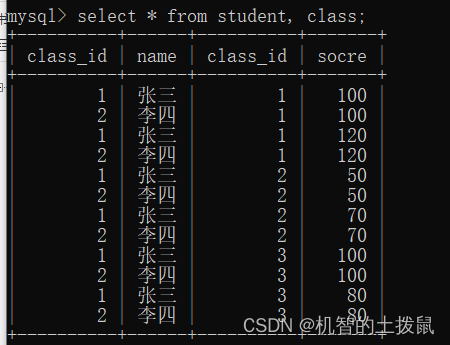
此时就出现了笛卡尔积,但是仔细观察,会发现class_id 不同的数据都组合到了一起,因此我们需要一个连接条件。
select student.class_id,
student.name,
class.socre from student,
class where student.class_id = class.class_id;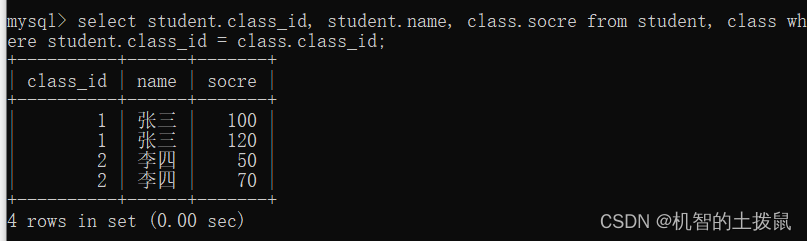
由于多表查询一般比较复杂,我们可以按照如下的步骤来写:
1、先进行指定哪个几个表,进行笛卡尔积
2、指定连接条件,去除笛卡尔积
3、精简列数据
以上查询都是基于“内连接“的操作,然而mysql还提供了”外连接“(左外连接,右外连接)
案例引入:
现有如下表

此时student的每一条记录都可以在score表中找到对应,每一个score中记录也可以在student表中找到对应。
此时我们使用外内接或者内连接查询的结果是一样。
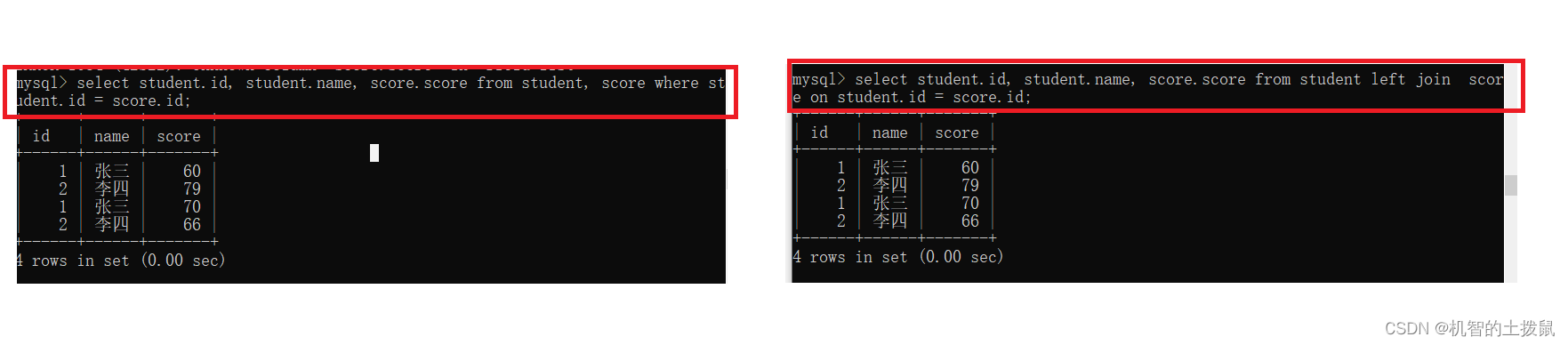
但是如果不存在记录,那么内连接与外连接就会天差地别~
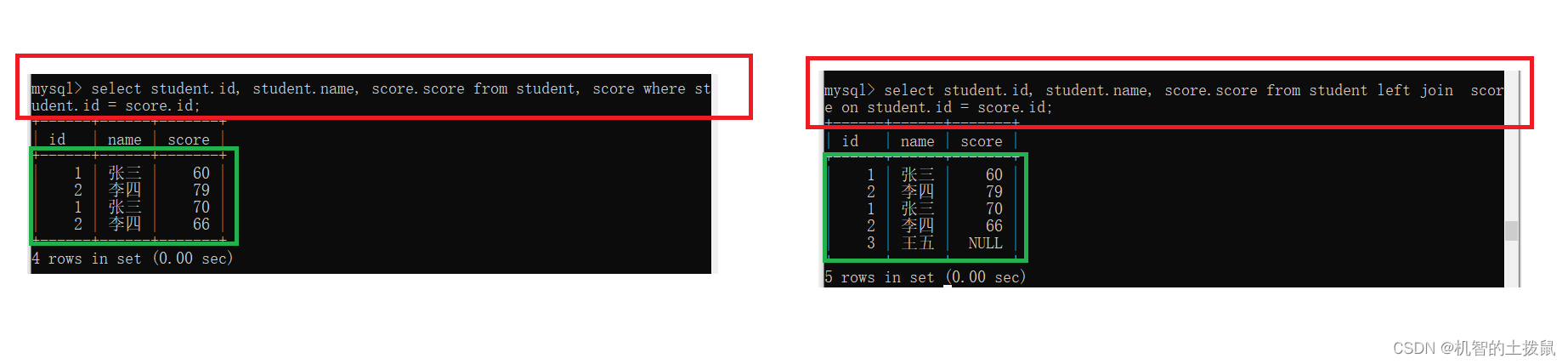
外连接分为左外连接和右外连接。
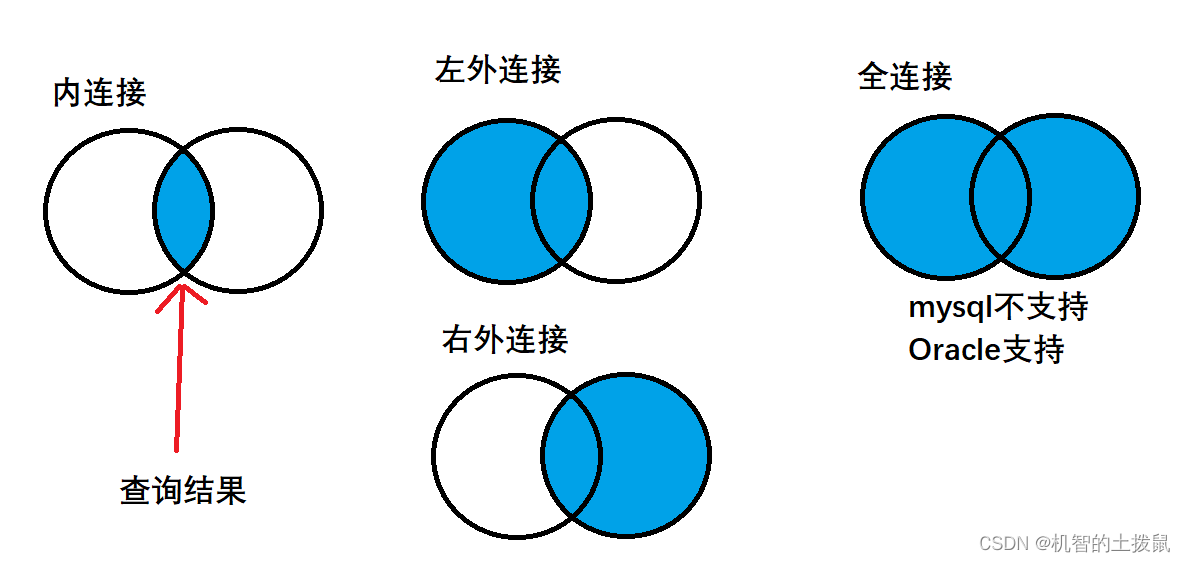
左外连接:以左表为基准,保证左侧表的每个数据都会出现在最终的结果集里,如果右表没有与之对应的记录则显示null。
select 列名 from 表名1 left join 表2 on 连接条件右外连接:以右表为基准,保证右侧表的每个数据都会出现在最终的结果集里,如果左表没有与之对应的记录则显示null。
select 列名 from 表名1 right join 表2 on 连接条件我们还可以用集合图来表示这些连接的关系:
补充:
以上我们都是针对于两个表进行联合查询的,但我们甚至还可以将一个表当做两个表来进行联合查询,这样我们就能在一张表中进行 行与行的比较~这种连接方式一般被称为“内连接”。
自连接的查询跟上面的联合查询基本没什么区别,需要注意将两张表进行别名操作~
0x 03 子查询
子查询是将多个简单的SQL语句拼成一个复杂的SQL, 也就是说将某一个查询的结果看做是一张表,然后进行操作,但本质是在套娃。因此我们实际也是可以用简单的查询完成子查询的操作的~ (合成2048?合成复杂SQL!)
语法形式:
select 列名 from 表名 where 列名 = (select 列名 from 表名 where 列名 = (套娃下去....));0x 04 合并查询
合并查询就是将多个sql的查询结果集 合并在一起。合并的两个sql结果集的列,需要匹配,列的个数和类型得是一致的!合并的时候是会进行去重的,如果不想要去重,得使用 union all
select 列名1 列名2 from 表1 union [all] select 列名3 列名4 from 表2;最终结果:















 1813
1813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









