







一、信息论基础
-
信息熵
信息熵常被用来作为一个系统的信息含量的量化指标,从而可以进一步用来作为系统方程优化的目标或者参数选择的判据。在决策树的生成过程中,就使用了熵来作为样本最优属性划分的判据。
公式:

https://www.zhihu.com/question/22178202
性质:
1、单调性,发生概率越高的事件,其携带的信息量越低;
2、非负性,信息熵可以看作为一种广度量,非负性是一种合理的必然;
3、累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和,
这也是广度 量的一种体现。
-
联合熵
联合熵就是度量一个联合分布的随机系统的不确定度。
公式:
设有随机变量(X,Y)(X,Y),其联合概率分布为:

其联合熵定义为:

-
条件熵
条件熵 表示在已知随机变量 X的条件下随机变量 Y 的不确定性。
表示在已知随机变量 X的条件下随机变量 Y 的不确定性。
条件熵 定义为 X给定条件下 Y 的条件概率分布的熵对 X 的数学期望:

条件熵 相当于联合熵 减去单独的熵
减去单独的熵  ,即
,即

证明如下:
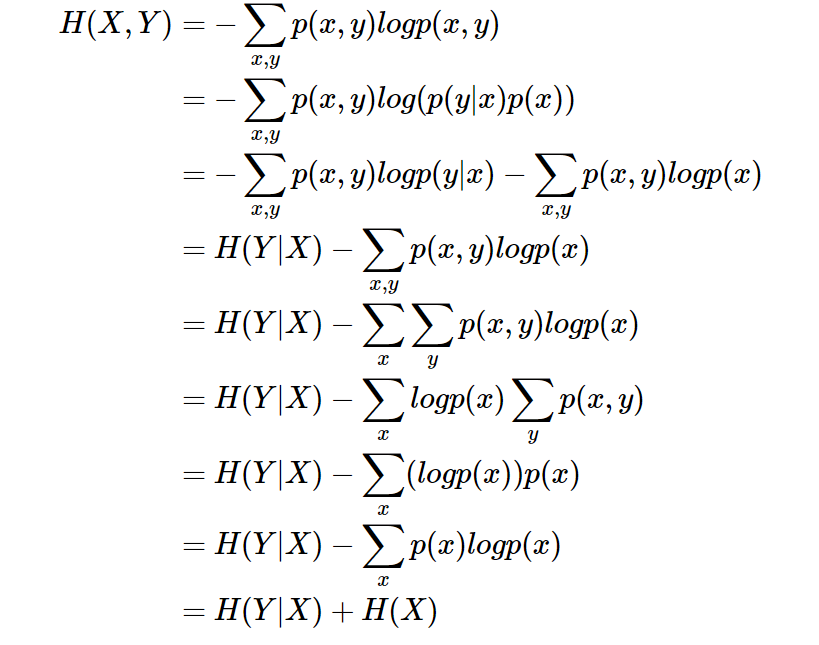
-
信息增益
信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好,
在概率中定义为:待分类的集合的熵和选定某个特征的条件熵之差,公式如下:
-
基尼不纯度
将来自集合中的某种结果随机应用于集合中某一数据项的预期误差率。大概意思是 一个随机事件变成它的对立事件的概率。
公式:

性质:
1、基尼不纯度越小,纯度越高,集合的有序程度越高,分类的效果越好;
2、基尼不纯度为 0 时,表示集合类别一致;
3、基尼不纯度最高(纯度最低)时,,
IG(f)=1−(1m)2×m=1−1m
二、分类算法
-
ID3
ID3算法是决策树的一种,它是基于奥卡姆剃刀原理的,即用尽量用较少的东西做更多的事。ID3算法,
即Iterative Dichotomiser 3,迭代二叉树3代,是Ross Quinlan发明的一种决策树算法,这个算法的基础就是
上面提到的奥卡姆剃刀原理,越是小型的决策树越优于大的决策树,尽管如此,也不总是生成最小的树型结
构,而是一个启发式算法。 在信息论中,期望信息越小,那么信息增益就越大,从而纯度就越高。ID3算法
的核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。该算法采用自顶
向下的贪婪搜索遍历可能的决策空间。
-
C4.5
C4.5是Ross Quinlan在1993年在ID3的基础上改进而提出的。ID3采用的信息增益度量存在一个缺点,它
一般会优先选择有较多属性值的Feature,因为属性值多的Feature会有相对较大的信息增益(信息增益反映的给
定一个条件以后不确定性减少的程度,必然是分得越细的数据集确定性更高,也就是条件熵越小,信息增益越大)。
为了避免这个不足C4.5中是用信息增益比率(gain ratio)来作为选择分支的准则。信息增益比率通过引入一个被
称作分裂信息(Split information)的项来惩罚取值较多的Feature。除此之外,C4.5还弥补了ID3中不能处理特征
属性值连续的问题。
-
CART
CART(Classification and Regression tree)分类回归树由L.Breiman,J.Friedman,R.Olshen和C.Stone于
1984年提出。ID3中根据属性值分割数据,之后该特征不会再起作用,这种快速切割的方式会影响算法的准确率。
CART是一棵二叉树,采用二元切分法,每次把数据切成两份,分别进入左子树、右子树。而且每个非叶子节点都
有两个孩子,所以CART的叶子节点比非叶子多1。相比ID3和C4.5,CART应用要多一些,既可以用于分类也可以
用于回归。CART分类时,使用基尼指数(Gini)来选择最好的数据分割的特征,gini描述的是纯度,与信息熵的含
义相似。
三、回归树原理
回归树
四、过拟合
五、模型评估
六、sklearn.tree.DecisionTreeRegressor
参考:https://scikit-learn.org/dev/modules/generated/sklearn.tree.DecisionTreeRegressor.html















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









