









渲染预览PDF文档,轻松搞定,这方案真香!
1.前言
在实际项目中,文档生成功能是较常用的需求.比如办单报告,缴费报告,合同文件之类等.生成相应office文档;可以在线预览文档,并支持打印下载.网上也有很多解决方案.今天我们就来聊一聊一种新的解决方案.在线动态PDF数据生成预览,一定让各位看客姥爷满意.
2.列举一些文档预览解决方案:
- 直接引用微软提供的方法,在 https://view.officeapps.live.com/op/view.aspx?src= 后边添加需要预览的文档地址,方便简单且免费
- pdf.js开源在线浏览工具,直接引入项目中,下载链接:http://mozilla.github.io/pdf.js/;下载下来的压缩包包含两个文件夹:build和web,打开web文件夹下的viewer.html,就能看到PDF的预览效果了。
- easypoi 开源工具里支持对excel 等文档的在线预览.
- https://file.keking.cn/index 开源文件预览 支持各类officce文档 图片 压缩包 等等.
- 使用pdfobject.js实现在线浏览PDF,官网:https://pdfobject.com/
- 付费产品预览方案有【永中office】【office365】【idocv】等.
3.列举一些文档解析生成解决方案:
- easypoi支持预览也支持根据模板动态生成文档.
- freemarker + word 实现动态文件生成; 受word版本影响,要office软件的word.
- jasperReports+ireport+java运用 还需下载工具,设计文档;较繁琐.
- wps开发者服务,支持在线编辑生成文档,很方便但是需要企业资质才能申请账号.
- java使用itext操作填充pdf模板 需要两个jar包 itext-asian-5.2.0.jar和 itextpdf-5.5.6.jar,编码复杂。
以上总结:
- 以上提到的关于预览文档和生成在线文档技术,我们不做过多研究,只是给大家例举一下.各类方案有各自的优势,之后有空再对各类实现方案进行单独讲解.
- 通过各类解决方案我们看到,动态生成文档的时候基本依赖于模板文档.只是通过动态数据替换值域.
- 今天我们要说的这种实现方案也是依赖于模板和freemarker技术实现.不同的就是这个模板的不同.
4.案列赏析
在讲解这个实现方案之前我们先来看一下小弟为各位看官提供的一些模板案列:
以上的模板都是都是依赖于一种XDOC标签,了解更多请看此文档:
Xdoc标签文档.
官网: http://www.xdocin.com/web.html.
官网中提供对office模板文档word,ppt,excel 设计指南,预览生成指南.但是需要付费购买服务才能分发秘钥.调用服务.今天我们讲解这种pdf 生成方案完全免费试用.
那么我们以个人资料在线模板为主进行展开讲解.
5.准备工作:
freemarker 中文官方参考手册 http://freemarker.foofun.cn/
- 项目中引入freemarker配置:
<!--freemarker-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
- freemarker 基本yml 配置:
freemarker:
template-loader-path: classpath:/templates/
suffix: .ftl
charset: utf-8
default-encoding: utf-8
content-type: text/html;charset=utf-8
#设定所有request的属性在merge到模板的时候,是否要都添加到model中
expose-request-attributes: true
#设定所有HttpSession的属性在merge到模板的时候,是否要都添加到model中.
expose-session-attributes: true
#设定是否以springMacroRequestContext的形式暴露RequestContext给Spring’s macro library使用
expose-spring-macro-helpers: true
#指定RequestContext属性的名.
request-context-attribute: request
#缓存
cache: false
settings:
#重新加载模版文件 间隔时间
template_update_delay: 10
#中文
locale: zh_CN
#日期-时间格式化
datetime_format: yyyy-MM-dd HH:mm:ss
#日期格式化
date_format: yyyy-MM-dd
#数字格式化
number_format: #.####
#兼容传统模式
classic_compatible: true
#忽略异常配置
template_exception_handler: ignore
3.xdoc pom配置引入:
<dependency>
<groupId>com.hg.xdoc</groupId>
<artifactId>xdoc</artifactId>
<version>X.1.0.0</version>
</dependency>
备注:此包已上传到gitee项目doc目录下.
6.模板讲解:
pdf预览模板实际就是一个freemarker 模板,以页面根标签xdoc为主的一系列标签元素组合.以个人资料模板作为解读.如下效果图所示:

我们看到此文档主要是表格table的组合.页面元素如下很多属性很HTML一样.
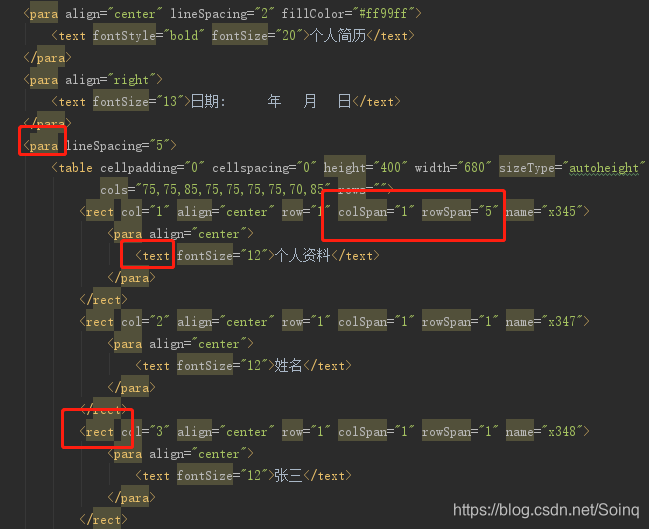
对应文档讲解如下 请认真阅读上面Xdoc文档:
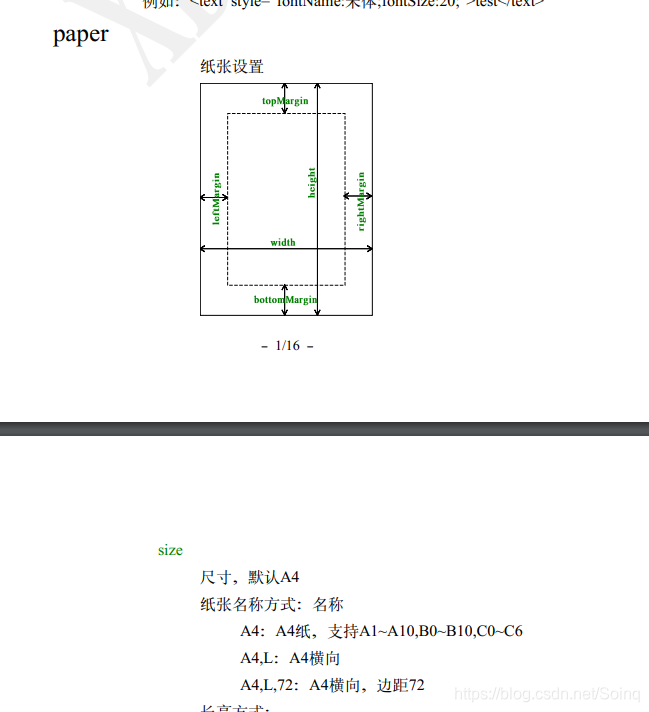
只要对前段页面标签html了解的小伙伴很快就能熟悉入手这些标签.因此对于模板设计这一块门槛还是很低的,易上手.
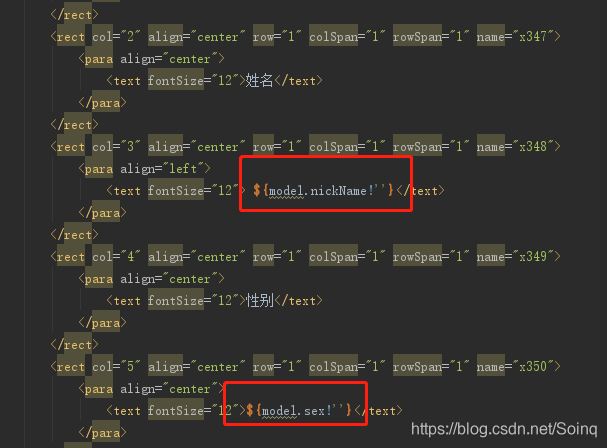
数据渲染完全遵循freemarker 解析语法.
7.代码实现:
文档生成的场景有很多,我们给一个简单的案例,用于个人资料展示.
这是前段文档预览入口.后端我们就需要考虑如何将个人用户数据封装到模板文件里,然后通过控制层展示出来.请看代码:
- 首先加载模板文件jianli.ftl:
InputStream inputStream = this.getClass().getResourceAsStream("/templates/jianli.ftl");
content = createTemplateView(user, inputStream);
- 封装数据调map 传递到freemarker 模板解析:
//设置模板变量
Map<String, Object> map = new HashMap<>(16);
map.put("model", user);
//获取年份
SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日");
Date date = new Date();
map.put("date", sdf.format(date));
String fileName = "jianli.ftl";
String content = FreeMarkerUtil.templateAnalysis(map, inputStream, fileName);
- freemarker 解析数据生成固定模板数据:
//创建配置实例 Configuration
Configuration cfg = new Configuration(Configuration.VERSION_2_3_25);
cfg.setDefaultEncoding("utf-8");
//读取到根目录
InputStreamReader isr = null;
BufferedReader br = null;
StringBuffer stringBuffer = new StringBuffer();
try {
isr = new InputStreamReader(inputStream,"utf-8");
br = new BufferedReader(isr);
String lineStr = "";
while ((lineStr = br.readLine()) != null) {
stringBuffer.append(lineStr);
}
} catch (Exception e) {
logger.error(e.toString());
} finally {
br.close();
isr.close();
}
StringTemplateLoader stl = new StringTemplateLoader();
String fileName = templateFile.replace("ftl", "");
stl.putTemplate(fileName, stringBuffer.toString());
cfg.setTemplateLoader(stl);
//工程目录下的目录
// cfg.setDirectoryForTemplateLoading(file);
//获取模板(template)
Template template = cfg.getTemplate(fileName);
//获取输出流(指定到控制台(标准输出))
StringWriter out = new StringWriter();
//数据与模板合并(数据+模板=输出)
template.process(root, out);
content = out.toString();
out.flush();
- 数据传输到view层:
ModelAndView modelAndView = new ModelAndView("/preview");
StringBuilder builder = new StringBuilder();
//动态封装数据
builder.append(templateResume(user));
modelAndView.addObject("context", builder.toString());
return modelAndView;
- preview.ftl 展示出模板数据:
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8"/>
<script type="text/javascript" src="/api/js/xdoc.js"></script>
</head>
<body style="height:100%; margin:0; overflow:hidden;">
<script id="myxdoc" type="text/xdoc" _format="pdf" style="width:100%;height:100%;">
<xdoc version="11.1.5">
<meta modifyDate="2017-08-15 14:45:10" author="Administrator" id="3ulahulfbrdwnfujnnjulqjcpm" title="在线预览" createDate="2017-08-15 12:37:46"/>
<paper width="812" height="1124" topMargin="15" bottomMargin="15" leftMargin="61" rightMargin="71"/>
<body>
${context}
</body>
</xdoc>
</script>
</script>
</body>
</html>
- 在preview.ftl 引入xdoc.js 文件内容如下 :
var XDoc = {};
//版本
XDoc.version = "A.3.3";
//XDocServer地址
XDoc.server = "/api/freemarker";
/**
* 转换XDOC
* @param xdoc xdoc模板
* @param tarFormat 目标格式,可以是:pdf等
* @param param 其它参数,用对象方式传递多个参数
* @param target 目标类型,可以是:_blank、_self等
*/
XDoc.to = function(xdoc, tarFormat, param, target) {
param['type']='preview';
XDoc._invoke("to", xdoc, tarFormat, param, target);
};
- XDocServer地址 是需要我们设置的:
@PostMapping("/xdoc")
public void xdoc(HttpServletRequest request, HttpServletResponse response) throws IOException {
String format = request.getParameter("_format");
if (format == null) {
format = "pdf";
} else if (format.equals("jpg")) {
format = "jpeg";
}
if (format.equals("pdf")) {
response.setContentType("application/pdf");
} else if ((format.equals("png")) || (format.equals("jpeg"))) {
response.setContentType("image/" + format);
} else {
response.setContentType("text/xml;charset=utf-8");
}
XDoc.write(xdoc, out, format);
out.flush();
out.close();
}
总结: 动态模板生成数据完美实现.
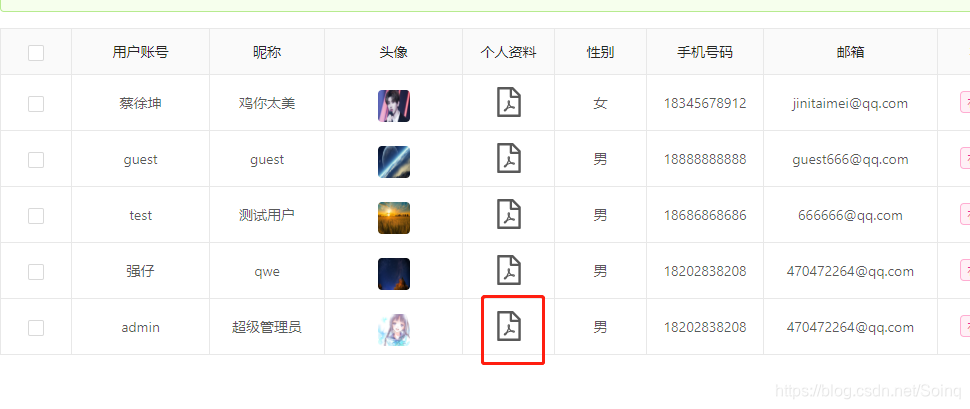
8.效果图:
我们看到数据已经动态渲染成功,在这里我们只渲染了个人资料,更多信息一样的渲染规则。

说明:这个pdf文档是在线预览的,可以选择性打印下载.不用生成文件后才能预览.
9.打印效果图:

10.体验:
以上项目案列体验地址如下:















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









