






目录
3.浏览器相当于翻译器,检查是否为html文件,是的话就翻译,否则就报错。
四、HTML ( Hyper Text Markup Language )超文本标记语言
一、网页概念:
1.纯文本格式文件
2.编写语言-----html---超文本标记语言
3.浏览器相当于翻译器,检查是否为html文件,是的话就翻译,否则就报错。
二、域名
- 域名就是浏览网页时输入的网址,网络是基于 TCP/IP 协议进行通信和连接的,每一台主机都有一个唯一的标识(固定的 IP 地址),用以区别在网络上成千上万个用户和计算机。网络在区分所有与之相 连的网络和主机时,均采用一种唯一、通用的地址格式,即每一个与网络相连接的计算机和服务器都被指派一个独一无二的地址

- http:用来传输网页的通讯协议
- URL:万维网寻址系统(跟在路径后的字符)
域名申请流程:
1.输入域名(查询重名)
2.付款
3.备案(负责人拍照)
流程大约10~20天,审核通过后才可以使用
三、DNS解析
1.分布式域名解析-----层次性:迭代处理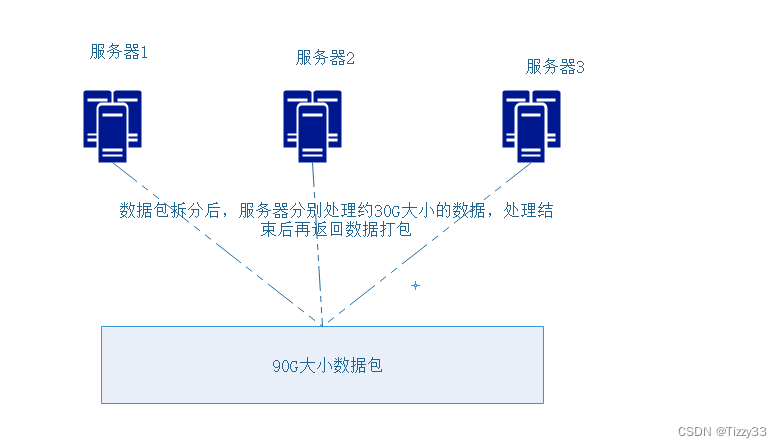
就是把整块的,大量的数据,分给不同的服务器处理,而这些服务器之间又统一映射着同一个域名。
2.DNS解析方式
- /etc/hosts linux系统中负责快速解析的文件,包含了ip与主机名的映射关系,在没有DNS服务器的情况下,使用本地/etc/hosts完成解析/映射,实现快速访问 PS: 主要用于主机之间(IP和主机名)的映射/解析关系,示例: 192.168.226.128 master 192.168.226.129 node1 192.168.226.130 node2
- /etc/resolv.conf DNS客户端配置文件,主要用于设置DNS服务器的IP和域名,还包含了主机域名的搜索顺序等等,这个文件是由域名解析器(resolver,一个根据主机名解析IP地址的库)使用的配置文件。 PS:主要用与匹配DNS服务器,示例: nameserver 114.114.114.114 nameserver 8.8.8.8 nameserver 218.2.135.1
- /etc/sysconfig/network-scripts/ifcfg-ens33 我们也可以在网卡配置文件中定义DNS1= DNS2=
- 生效顺序 1 hosts文件 2 网卡配置文件 3 /etc/resolv.conf
四、HTML ( Hyper Text Markup Language )超文本标记语言
网页的“源码” 浏览器:“解释和执行”HTML源码的工具
1.格式: 
2.标签头部

3.内容标签中常用标签
五、Web的迭代
1.web 1.0
最早的、静态的网页,指的是网站到用户的单向行为,以用户单向阅读网页为主
2.web 2.0
目前在大量使用的,主要特点是可以使服务端和客户端双向沟通为主(网页登录、商城购物选购商品等)
3.web 3.0
未来的趋势,以AI人工智能自动学习为主
六、网页状态的定义
1.静态页面
- 静态网页是标准的HTML文件
- 扩展名是.htm、.html 例如文本、图像、声音、Flash动画、客户端脚本和ActiveX控件及Java小程序等
- 是网站建设的基础,早期网站一般都由静态网页制作
- 没有后台数据库、不含程序和不可交互的网页
- 相对更新起来比较麻烦,适用于一般更新较少的展示型网站

2.动态页面
可以实现更多功能,如用户登录、注册、查询等,由PHP(python)、JSP(java)等语言编写
七、http协议
HTTP(超文本传输协议HyperText Transfer Protocol)协议是互联网上应用最为广泛的一种网络协议,它是基于TCP协议的应用层传输协议,简单来说就是客户端和服务端进行数据传输的一种规则建立在传输层TCP之上,客户端通过与服务端进行TCP连接(三次握手),之后发送HTTP请求与接收HTTP响应都是通过访问Socket接口来调用TCP协议实现。
HTTP 是一种无状态 (stateless) 协议, HTTP协议本身不会对发送过的请求和相应的通信状态进行持久化处理(存储,保存)。这样做的目的是为了保持HTTP协议的简单性,从而能够快速处理大量的事务, 提高效率。
- 无状态:重复、持久的处理
- 有状态:在无状态基础上,加入新任务进行处理
1.cookie和session
cookie(用户端缓存)和session(服务器缓存)主要为了防止sever和client资源被占用,客户首次登录时,会将记录在用户端的浏览器中(cookie),下次再次登录时,会直接读取cookie缓存,然后直接连接服务器。
两者对比: cookie 省服务器性能 session 更安全
2.http请求格式
- GET方式
- POST方式

- GET方法:
- 从指定的服务器上获得数据
- GET请求能被缓存
- GET请求会保存在浏览器的浏览纪录里(cookit)
- GET请求有长度的限制 主要用于获取数据 查询的字符串会显示在URL中,不安全
- POST方法:
- 提交数据给指定服务器处理
- POST请求不能被缓存
- POST请求不会保存在浏览器的浏览纪录里
- POST请求没有长度限制 查询的字符串不会显示在URL中,比较安全
3.HTTP状态码
状态码首位 已定义范围 分类
- 1xx 100-101 信息提示
- 2xx 200-206 成功
- 3xx 300-305 重定向
- 4xx 400-415 客户端错误
- 5xx 500-505 服务器错误

总结:
1.网络是基于TCP/IP协议建立连接并进行通讯的,每个主机都有独一无二的标识来区分(IP地址、mac地址),方便在交互时进行区分
2.访问网页时,是由dns域名解析后,映射的网址(由协议名、域名和URL组成),大量的访问数据由该域名映射的多个服务器共同迭代处理,并返回给用户不同的状态,在成功登陆之后,会通过缓存的方式记录用户的登录选项,在下一次登录时,读取缓存快速访问。
3.访问网页时返回的状态由于不同的状态码组成,分为客户端和服务端。















 5237
5237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











