






 文章探讨了Llama2,一个拥有700亿参数的模型,通过改进Llama2-Chat并强调其在实用性和安全性上的优势。文中介绍了模型的训练方法,如微调、强化学习和安全措施,并与竞品进行比较。
文章探讨了Llama2,一个拥有700亿参数的模型,通过改进Llama2-Chat并强调其在实用性和安全性上的优势。文中介绍了模型的训练方法,如微调、强化学习和安全措施,并与竞品进行比较。
Abstract 摘要
本文探讨了 Llama 2 的创建,这是一个拥有 70 亿至 700 亿个参数的大规模语言模型。它专注于改进 Llama 2-Chat 以供实际使用,声称优于开源聊天模型。该论文详细介绍了微调和安全性增强,并鼓励社区贡献。它解决了人类评估偏差,并深入研究了 Llama 2 的功能、训练和计算挑战。与 BLOOM、Llama 1、Falcon、GPT-3 和 Chinchilla 等模型进行了比较。概述了即将发布的用于研究和商业用途的 Llama 2 和 Llama 2-Chat (多达 700 亿个参数),以及数据注释、红队测试和迭代评估等安全措施。
Introduction 介绍
作者深入研究了大语言模型 (LLM) 的功能和训练方法。他们强调了大语言模型 (LLM) 作为熟练的人工智能助手的潜力,可以完成需要专业知识的复杂任务,例如编程和创意写作。这些模型凭借直观的聊天界面,迅速受到公众的欢迎。
LLM 的过程简单但是非常符合人类学习逻辑。自回归 transformers 最初根据大量自监督数据进行预训练,然后使用人类反馈强化学习 (RLHF) 等技术进行微调,以符合人类偏好。然而,大量的计算要求阻碍了 LLM 的发展。
Llama 2 论文将 BLOOM、Llama 1 和 Falcon 等公开发布的 LLM 与 GPT-3 和 Chinchilla 等非开源大模型对应版本进行了比较。虽然非开源模型因微调而表现出色,但其成本和缺乏透明度阻碍了人工智能对齐研究。
本文的贡献包括 Llama 2 和 Llama 2-Chat,LLM 拥有多达 700 亿个参数。Llama 2-Chat 在实用性和安全性基准方面超越了非开源模型。它们通过数据注释、红队测试和迭代评估来增强安全性。
-
Llama 2 是 Llama 1 的更新版本,使用新数据、更大的预训练语料库和分组查询注意力。将发布具有 7B、13B 和 70B 参数的变体。
-
Llama 2-Chat 针对对话进行了优化,也有这些更新。虽然这些模型有助于研究和商业用途,但它们需要安全验证并适应特定场景。
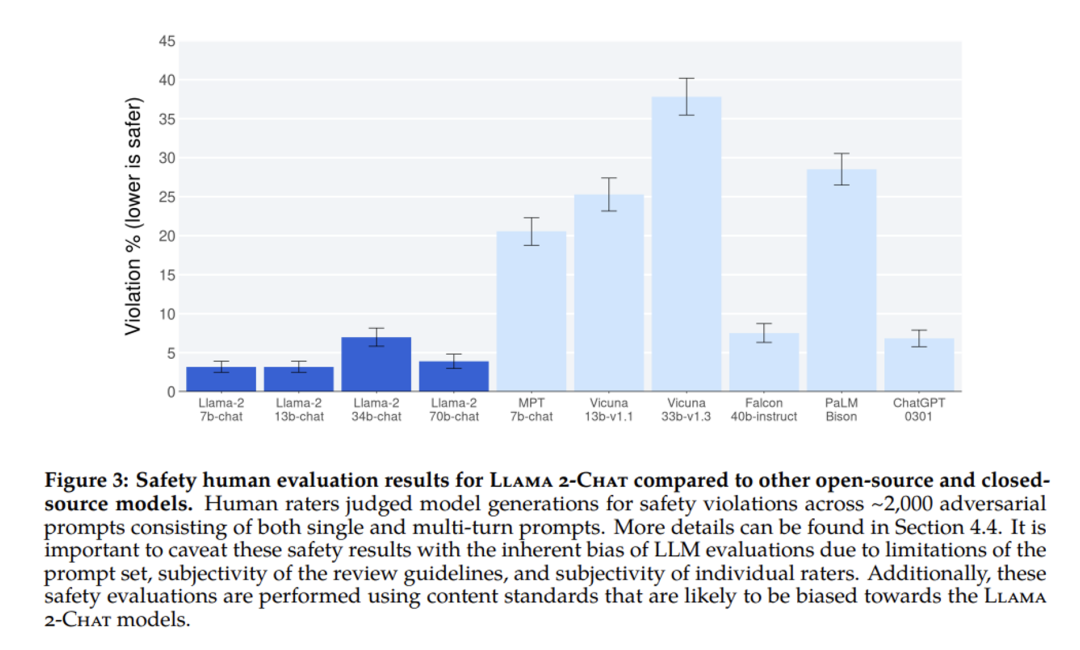
上图展示了 Llama 2-Chat 与其他开源和非开源模型之间的安全人工评估结果的比较。人类评估人员根据大约 2000 个对抗性提示 (包括单轮提示和多轮提示) 评估了模型生成内容的安全违规情况。然而,这些安全性评估结果可能会受到提示集、评估指南的主观性和个人评估者偏差等因素的影响,可能有利于 Llama 2-Chat 模型的开发。

上图说明了 Llama 2-Chat 的训练过程。该过程首先使用公开的在线资源对 Llama 2 进行预训练。随后,通过监督微调创建了 Llama 2-Chat 的初始版本。然后,采用人类反馈强化学习 (RLHF),包括拒绝采样和近端策略优化 (PPO),对模型进行迭代细化。在 RLHF 阶段,迭代奖励建模数据的积累与模型增强密切相关,确保奖励模型保持在分布范围内。
Pretraining 预训练
在开发新的 Llama 2 模型系列时,作者采用了 Touvron 等人概述的预训练方法,利用经过进一步改进的优化自回归变压器来提高性能。值得注意的是,这些改进包括更强大的数据清理、更新的数据混合、通过增加总标签来扩展训练、上下文长度加倍以及利用分组查询注意力 (GQA) 来增强大型模型的推理可靠性和可扩展性。
关于训练数据,Llama 2 模型的训练语料库包含来自可公开访问来源的新鲜数据的混合,不包括与 Meta 产品或服务相关的数据。作者采取措施排除来自已知包含私人个人信息的网站的数据。训练过程包含 2 万亿个令牌,战略性地对现实来源进行过采样,以增强知识,同时最大限度地减少失真。作者进行了各种预训练数据评估,以增强用户对模型潜力和局限性的理解。
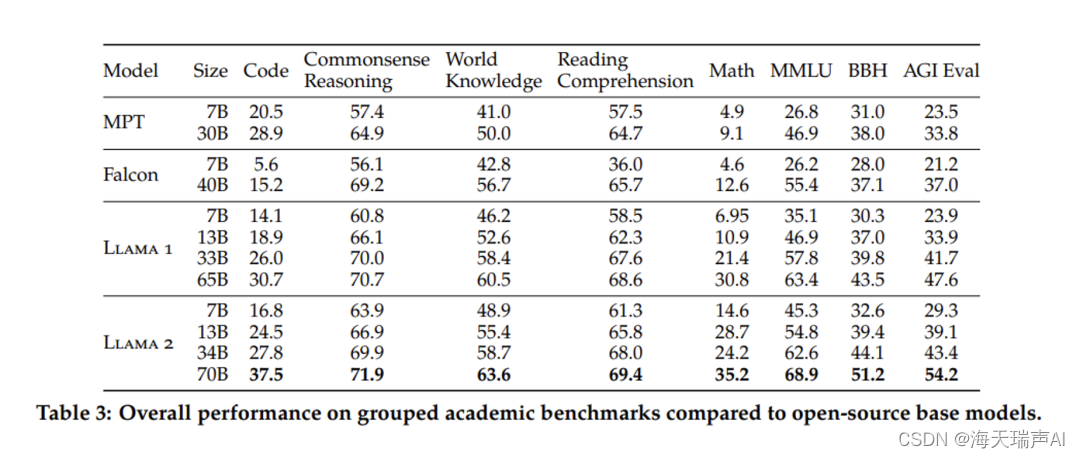
本节还报告了 Llama 2 预训练模型的评估。作者使用标准学术基准对 Llama 1、MosaicML Pretrained Transformer (MPT) 和 Falcon 模型进行了基准测试。这些基准涵盖各个领域,包括常识推理、世界知识、阅读理解、数学和流行的聚合基准。
表 3 概述了模型在这些基准测试中的性能。值得注意的是,安全基准在第 4.1 节中讨论,而各个基准的综合结果可在第 A.2.2 节中找到。这项综合评估证明了 Llama 2 模型在不同任务和领域的有效性。
Fine-tuning 微调
Llama 2-Chat 是涉及对准技术、引导微调和 RLHF 的广泛研究的结果。
引入幽灵注意力 (GAtt) 技术来控制多轮对话流。
-
监督微调 (SFT)
- 注重质量:强调高质量和多样化的SFT数据。
- 过滤了数百万个第三方示例,并纳入了更少的内部注释。
- 有限的数据集 (27,540 个注释) 足以获得高质量的结果。
- 数据质量验证至关重要;SFT 模型的输出与人类注释具有竞争力。
-
人类反馈强化学习 (RLHF)
- 通过二元比较收集人类偏好数据用于奖励建模。
- 注释者撰写提示,在模型响应之间进行选择。
- 注重标注的实用性和安全性;编译的大型数据集 (元奖励建模数据)。
-
奖励建模
- 实用性和安全性的奖励模型;从预先训练的检查点初始化。
- 二元排名标签是从人类偏好数据转换而来的。
- 数据组合:将新的和现有的数据集组合起来进行训练。
- 奖励模型优于包括 GPT-4 在内的基线。
-
迭代微调 (RLHF)
- 探索了 RLHF-V1 到 RLHF-V5 迭代。
- 使用了近端策略优化 (PPO) 和拒绝采样微调算法。
- 增强模型性能的组合方法。
- 训练细节:优化器、学习率、迭代、FSDP 使用。
-
多轮一致性的系统消息
- 根据安全性和帮助性划分的奖励模型。
- 引入幽灵注意力 (GAtt) 方法来引导注意力集中。
- GAtt 最多可保持 20 多个回合的对话一致性。
- RLHF 结果表明该模型在安全性和实用性方面优于 ChatGPT。
- 承认人类评估的局限性。
总体而言,Llama 2-Chat 的研究涉及微调、奖励建模和迭代 RLHF 过程,以及确保对多轮对话的控制的创新 GAtt 技术。该模型在符合人类偏好和安全方面显示出有希望的结果。
Comparison 比较
-
技术细节的差异
在 Llama 1 论文中,对训练数据方法的全面解释有助于该过程的复制。相反,Llama 2 论文更侧重于概述模型训练的方法,数据透明度较低。Llama 1 由 67% 公开获得的数据和 15% 精心挑选的数据组成。尽管 Llama 2 论文缺乏深入的数据细节,但元部分强调了与 Llama 1 相比大 40% 的预训练语料库。随着科技公司共享的培训细节越来越少,分布式培训变得越来越重要,因为内部培训可以降低安全风险和知识产权泄漏。
-
数据不透明背后的原因
由于数据安全和合规性方面的监管审查,Meta 的模型发布会遇到风险,特别是对于拥有大量用户群的公司而言。数据透明度受到限制以防止复制,因为 Llama 1 的数据暴露导致未经授权的复制。持续不断的诉讼,例如 Sarah Silverman 涉及 Llama 1 数据的版权案,加剧了数据不透明。由于版权或使用问题,许多网络爬取的数据并不是真正“公开可用”的,这凸显了公共数据感知与人工智能不断变化的需求之间不断变化的差距。数据标注公司的参与增加了数据的不透明性。Llama 2 使用精心策划的数据集,产生了大量费用。
-
数据质量的意义
Llama 2 通过更加重视高度可靠的数据来增强可信度,增强模型的置信度。彻底的数据清理对于精确的文本生成至关重要。关于训练数据量持续增加的讨论随着数据质量评估和重复数据删除技术的进步而出现。鉴于 Llama 2 的数据超出了 Chinchilla Optimal 的限制,预训练数据量和 Chinchilla Optimal 之间的关系引发了问题。随着质量评估和重复数据删除方法的进步,训练数据量增加的趋势可能会持续下去,从而可能改变过去的质量定义。
One More 值得一提
在全球范围内,大语言模型 (LLM) 在自然语言处理领域获得了巨大的成功。海天瑞声已经为加速构建大语言模型提前准备,推出「中文千万轮对话语料库 DOTS-NLP-216」。该数据集包含海量数据、质量卓越,非常适合微调和预训练目的。
这是一个符合中国人表达习惯的自然对话数据集,共计约 1,0000,000 轮,上亿级 token,包含正式&非正式风格对话,使用偏口语化自然表达。覆盖工作、生活、校园等场景,及金融、教育、娱乐、体育、汽车、科技等领域。
在数据集构成上,DOTS-NLP-216 包含了对真实场景的对话采集,和高度还原真实场景的模拟对话这两种方式,来兼顾了分布的代表性、多样性和样本规模。
欢迎前往海天瑞声官网,了解更多数据集详情。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









