







###1、官网地址
hadoop.apache.org
###2、三大组件
HDFS:分布式文件系统,存储
MapReduce:分布式计算
Yarn:资源和JOB调度监控
###3、部署方式
单机模式standalone: 1个java进程
伪分布式模式Pseudo-Distributed: 多个java进程
集群模式Cluster: 多台机器多个java进程
###4、部署
参考官方文档官方文档连接
####4.1、创建hadoop用户
# useradd hadoop
# id hadoop
uid=515(hadoop) gid=515(hadoop) groups=515(hadoop)
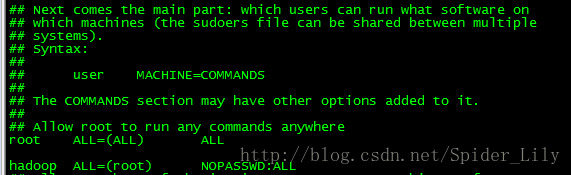
添加sudo权限
#vi /etc/sudoers
####4.2、部署java
Oracle jdk1.8(Open JDK尽量不要使用)
参考Linux安装JDK
####4.3、部署ssh服务是运行状态
后面配置相互信任关系会用到ssh
####4.4、解压
将编译好的hadoop拷贝到/opt/software/目录下
解压
# tar -xzvf hadoop-2.8.1.tar.gz
####4.5、创建hadoop软连接
#ln -s /opt/software/hadoop-2.8.1 hadoop

修改hadoop的权限
#chown -R hadoop:hadoop hadoop
#chown -R hadoop:hadoop hadoop/*
#chown -R hadoop:hadoop hadoop-2.8.1
注意:
chown -R hadoop:hadoop 文件夹 文件夹和文件夹里面的都会修改
chown -R hadoop:hadoop 软连接文件夹 只修改软连接文件夹,不会修改文件夹里面的
chown -R hadoop:hadoop 软连接文件夹/* 软连接文件夹不修改,只会修改文件夹里面的
chown -R hadoop:hadoop
####4.6、切换hadoop用户
#su - hadoop
$cd /opt/software/hadoop
$ll
total 32
drwxr-xr-x. 2 hadoop hadoop 4096 Dec 17 13:26 bin
drwxr-xr-x. 3 hadoop hadoop 4096 Dec 17 13:26 etc
drwxr-xr-x. 2 hadoop hadoop 4096 Dec 17 13:26 include
drwxr-xr-x. 3 hadoop hadoop 4096 Dec 17 13:26 lib
drwxr-xr-x. 2 hadoop hadoop 4096 Dec 17 13:26 libexec
drwxrwxr-x. 3 hadoop hadoop 4096 Dec 30 10:49 logs
drwxr-xr-x. 2 hadoop hadoop 4096 Dec 17 13:26 sbin
drwxr-xr-x. 3 hadoop hadoop 4096 Dec 17 13:26 share
bin:命令
etc:配置文件
sbin:启动关闭hadoop进程命令
####4.7、修改配置
$cd /etc/hadoop
这里有几个比较重要的配置文件:
core-site.xml:hadoop核心配置文件
hadoop-env.sh:hadoop配置环境
hdfs-site.xml:hdfs服务的配置
mapred-site.xml:mapred计算所需要的配置文件,只有在jar计算时才有
yarn-site.xml:yarn服务的配置
slaves:集群的机器名称
#####4.7.1、配置hdfs默认的命名空间,是通过该配置访问hdfs
$vi core-site.xml
fs.defaultFS
hdfs://localhost:9000
生产使用的时候localhost修改为机器IP
#####4.7.2、hdfs服务配置
$vi hdfs-site.xml
dfs.replication
1
####4.8、配置用户ssh信任关系
//ssh-keygen
$ssh-keygen -t rsa -P ‘’ -f ~/.ssh/id_rsa
//生成公钥文件到authorized_keys文件
$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
//修改权限
$chmod 0600 ~/.ssh/authorized_keys
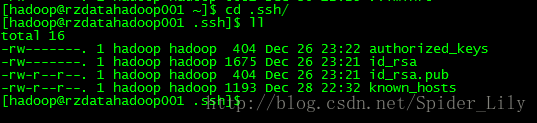
在当前hadoop用户目录下可以看到多了个.ssh目录,结构如下:
#####测试一下
$ssh hostname date
第一次执行要输入yes
然后再次执行
$ssh hostname date
第二次不再需要
####4.9、启动之前格式化文件系统
切换到/opt/software/hadoop目录
b
i
n
/
h
d
f
s
n
a
m
e
n
o
d
e
−
f
o
r
m
a
t
格
式
化
成
功
后
,
如
下
图
会
看
到
默
认
的
存
储
路
径
为
/
t
m
p
/
h
a
d
o
o
p
−
h
a
d
o
o
p
/
d
f
s
/
n
a
m
e
!
[
f
o
r
m
a
t
]
(
h
t
t
p
:
/
/
i
m
g
.
b
l
o
g
.
c
s
d
n
.
n
e
t
/
20180105001025969
?
w
a
t
e
r
m
a
r
k
/
2
/
t
e
x
t
/
a
H
R
0
c
D
o
v
L
2
J
s
b
2
c
u
Y
3
N
k
b
i
5
u
Z
X
Q
v
U
3
B
p
Z
G
V
y
X
0
x
p
b
H
k
=
/
f
o
n
t
/
5
a
6
L
5
L
2
T
/
f
o
n
t
s
i
z
e
/
400
/
f
i
l
l
/
I
0
J
B
Q
k
F
C
M
A
=
=
/
d
i
s
s
o
l
v
e
/
70
/
g
r
a
v
i
t
y
/
S
o
u
t
h
E
a
s
t
)
默
认
的
路
径
在
哪
里
配
置
?
1
)
、
官
网
找
到
c
o
r
e
−
d
e
f
a
u
l
t
.
x
m
l
配
置
文
件
h
a
d
o
o
p
.
t
m
p
.
d
i
r
/
t
m
p
/
h
a
d
o
o
p
−
bin/hdfs namenode -format 格式化成功后,如下图会看到默认的存储路径为/tmp/hadoop-hadoop/dfs/name  默认的路径在哪里配置? 1)、官网找到core-default.xml配置文件 hadoop.tmp.dir /tmp/hadoop-
bin/hdfsnamenode−format格式化成功后,如下图会看到默认的存储路径为/tmp/hadoop−hadoop/dfs/name默认的路径在哪里配置?1)、官网找到core−default.xml配置文件hadoop.tmp.dir/tmp/hadoop−{user.name}
hdfs-site.xml配置文件
dfs.namenode.name.dir file://KaTeX parse error: Expected 'EOF', got '#' at position 27: ….dir}/dfs/name #̲#####可以看到dfs的na…{hadoop.tmp.dir}环境变量,
因此默认的存储目录是/tmp/hadoop-hadoop/dfs/name

2)、路径/tmp/hadoop-hadoop/dfs/name中的hadoop-hadoop代表什么?
-前面的hadoop是默认的
-后面的hadoop是指当前hadoop用户
3)、修改hadoop的临时目录
vi core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop_temp</value>
</property>
####4.10、启动hdfs
$sbin/start-dfs.sh
启动成功后可以使用http://ip:50070访问

可能会出现的问题:
1)、JAVA_HOME存在,无法启动HDFS服务
修改/etc/hadoop/hadoop-env.sh中的JAVA_HOME路径为当前机器的正确路径
####4.11、修改HDFS的服务以机器名启动
默认的可能如下:
namenode: 机器名(hostname)
datanode: localhost
secondarynamenode: 0.0.0.0
#####datanode修改:
$vi slaves
hostname
#####secondarynamenode修改:
$vi hdfs-site.xml
dfs.replication
1
dfs.namenode.secondary.http-address
hostname:50090
dfs.namenode.secondary.https-address
hostname:50091
然后重启hdfs服务就可以了
####4.12、Yarn部署
etc/hadoop/mapred-site.xml:
mapreduce.framework.name
yarn
etc/hadoop/yarn-site.xml:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
启动Yarn
$sbin/start-yarn.sh
启动成功后可以通过web界面查看MapReduce job
http://ip:8088/
停止Yarn
$ sbin/stop-yarn.sh















 6201
6201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









