







本文是torch.compile()流程解析系列文章,因此很多代码和样例需要结合前面的文章才会更容易理解哦~
AOTAutograd(Ahead-Of-Time Autograd)介绍
在上一节TorchDynamo的介绍中,我们解析了torch.compile()是如何捕获计算图并保存为GraphModule的,但在这个过程中只是对整个Python字节码进行了模拟执行、解析并构建FX Graph,相当于只是初步构建了前向计算图,没有捕获训练场景下的反向计算图。在PyTorch中反向计算图的捕获是放在backend compiler里面实现了,以torch.compile的默认backend compiler——inductor为例,在其实现函数compile_fx中,涵盖了AOTAutograd(捕获fw-bw joint graph)、PrimTorch(lowering op)和TorchInductor(图优化、Triton)。下面开始解析backend compiler的默认函数——inductor的函数实现,并梳理出剩下三个组件的原理。
首先介绍AOTAutograd,AOTAutograd是 PyTorch 引入的一种自动求导机制,旨在在模型执行之前预先生成梯度计算的代码。这种方法通过静态分析模型的前向计算图,提前生成反向传播所需的梯度计算逻辑,从而减少运行时的开销,提升训练效率。有了 AOTAutograd,开发者可以做以下事情:
- 获取反向传播计算图、甚至是正向传播和反向传播联合的计算图;
- 用不同的后端编译器分别编译正向传播和反向传播计算图;
- 针对训练 (training) 做正向传播、反向传播联合优化,比如通过在反向传播中重算 (recompute) 来减少正向传播为反向传播保留的 tensor,从而削减内存需求;
总的来说,AOTAutograd的工作流程如下:
- 基于__torch_dispatch__机制trace正向反向传播,生成联合计算图(joint graph)。
- 通过decompositions进一步拆解,将FX Graph进一步转换为更低层次的中间表示,即PrimTorch。
- 通过partition_fn将joint-graph切分成正反向计算图。
- 调用fw_compiler和bw_compiler对正向、反向计算图分别进行编译,并整合成一个torch.autograd.Function。
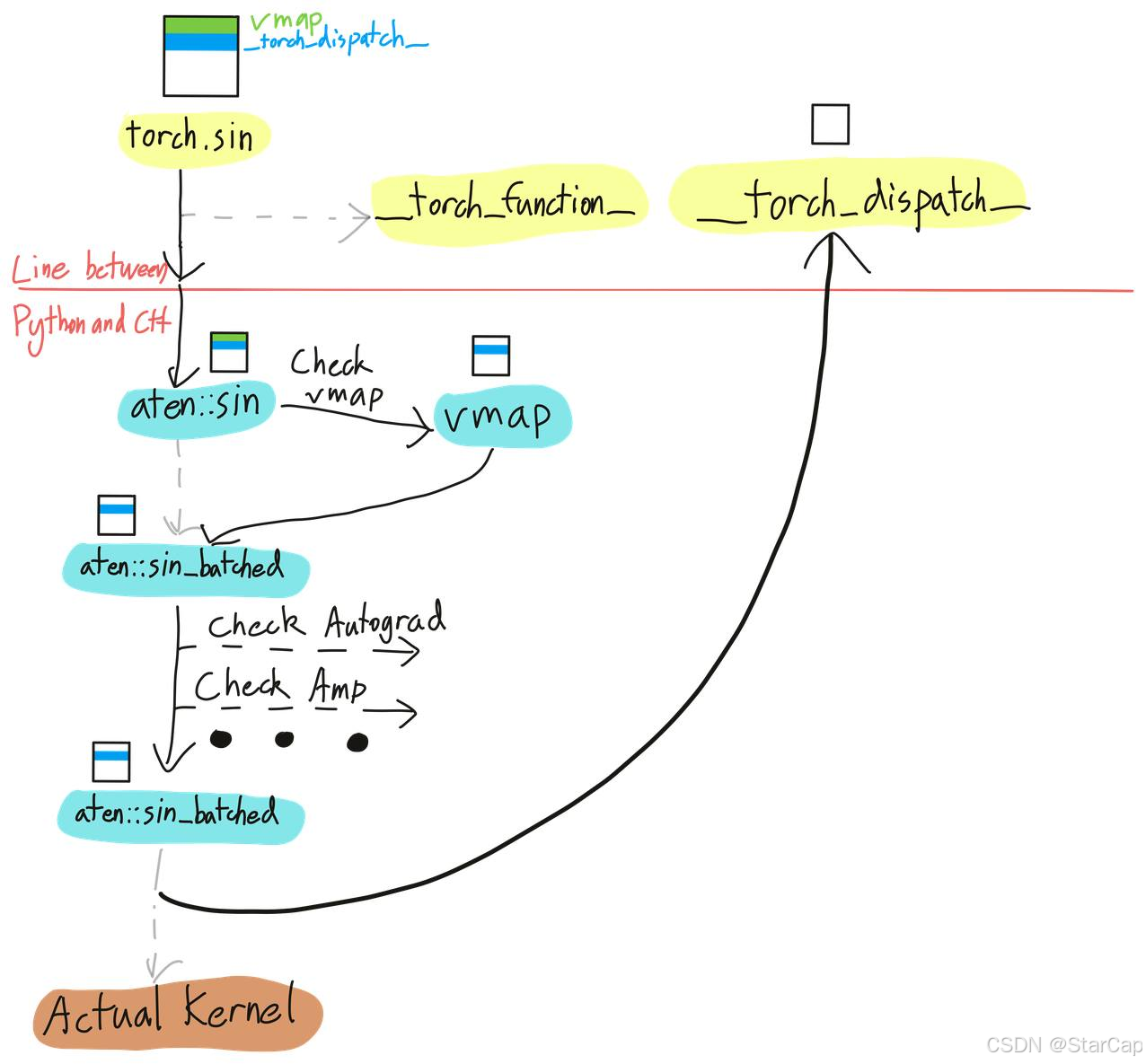
torch dispatch
AOTAutograd是基于__torch_dispatch__机制在算子下发执行前获得真正实际执行的op,并构建对应的Proxy,即PyTorch反向传播的计算图是在执行正向过程中动态创建的,这也意味着执行完整的前向过程才能构建出对应的FX Graph,从而在函数正式执行前拿到正反向计算图,实现AOTAutograd,而这一过程也是依赖于前面TorchDynamo捕获的FX Graph这一IR表示。
在正式解析AOTAutograd之前先了解一下__torch_dispatch__机制。PyTorch的核心是一个dispatcher,功能是根据输入tensor的属性把算子dispatch到具体的kernel上,如根据tensor的device属性决定是调用CUDA kernel还是CPU实现,从而综合各项属性算出一个dispatch key决定调用哪个kernel。一个算子在PyTorch中往往要经过多次dispatch,而**__torch_patch__给开发者提供了在算子最终dispatch前获取对应的算子和输入的接口。
后续AOTAutograd实现的代码逻辑如下,感兴趣的小伙伴也可以看看后面的代码解析部分
Joint Graph
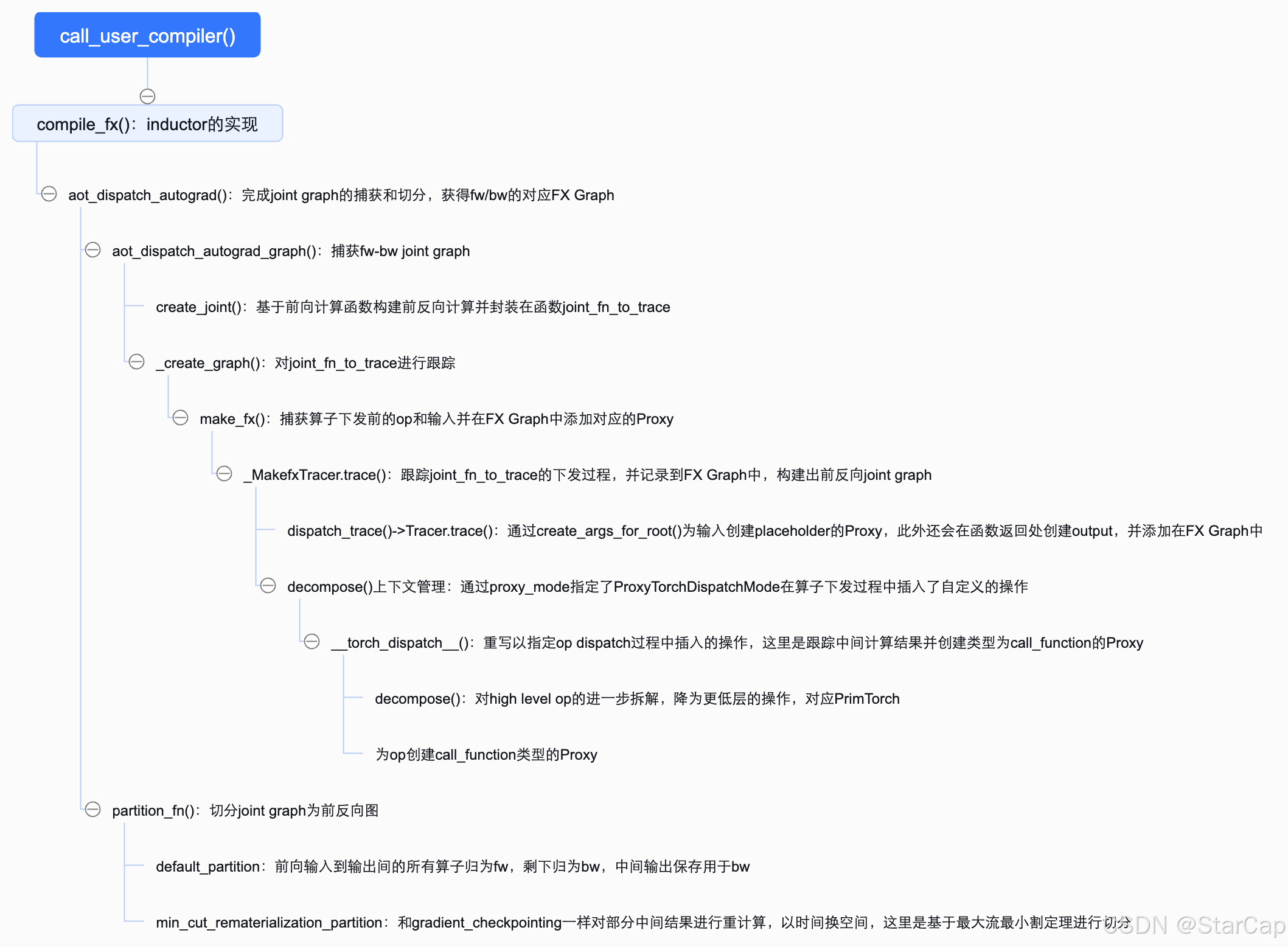
在TorchDynamo那一篇的第3节中提及通过在TorchDynamo构建FX Graph后会调用call_user_compiler()调用backend compiler对计算图进行编译,torch.compile()的默认编译函数实现inductor的入口函数是compile_fx()。
分析compile_fx()的函数调用栈,其核心实现是aot_dispatch_autograd()函数,其主要流程如下:
- 调用aot_dispatch_autograd_graph()生成前反向joint graph。
- 调用partition_fn进行切分,最后返回包含前、反向计算图的torch.autograd.Function。
首先介绍aot_dispatch_autograd_graph()函数生成joint graph的过程:
- 通过create_joint()函数将正反向计算封装成函数,create_joint()根据前向计算结果分析出需要计算梯度的参数以及对应的tangents(梯度权值),然后通过torch.autograd.grad进行反向求导,并将正反向过程封装在函数中返回,作为joint_fn_to_trace。
- 由_create_graph()对joint_fn_to_trace函数进行跟踪,核心是调用make_fx()函数在算子dispatch前拿到实际真正执行的op并创建Proxy添加到FX Graph中。
在make_fx()函数中是通过_MakefxTracer.trace()函数对整个函数计算过程进行跟踪并生成GraphModule,GraphModule中包含正反向计算对应的计算图。需要注意的是这里的正反向计算是TorchDynamo graph break对应的子图,即每个子图都会调用一次make_fx生成joint graph。捕获过程主要包括两个核心操作:
- 对输入输出的封装:在dispatch_trace()->Tracer.trace()中会为函数参数、局部变量以及输出生成对应的Proxy。其中通过create_args_for_root()->create_proxy()为所有变量(函数参数和局部变量)创建类型为placeholder的Proxy,在create_proxy()中会同步创建Node并将其加入到FX Graph中,并用Proxy封装一下Node。通过create_node()为输出创建类型为 output 的Node,并将其加入到FX Graph中)。
- op dispatch的捕获和封装: 在with decompose()上下文管理中通过self.proxy_mode指定了ProxyTorchDispatchMode(用于拦截和自定义张量操作的分发过程,Dispatch Mode 机制允许开发者在张量操作(如加法、矩阵乘法等)被执行时,插入自定义逻辑,以实现诸如调试、性能监控、自定义后端支持等功能,而不需要修改Python的核心代码)。通过重写__torch_dispatch__函数指定op dispatch过程中插入的操作,在ProxyTorchDispatchMode中是对op的decompose(拆解到PrimTorch规定的集合中),同时为op创建类型为call_function()的Proxy。
# aot_dispatch_autograd_graph()函数实现
# ps:这里只展示核心函数调用
def aot_dispatch_autograd_graph(
flat_fn,
flat_args: List[Any],
aot_config: AOTConfig,
*,
fw_metadata: ViewAndMutationMeta,
) -> Tuple[torch.fx.GraphModule, Tuple[List[Any], List[Any]], Optional[SubclassMeta]]:
# traced_tangents corresponds to the set of outputs in the traced forward that should get grad_outputs in the traced backward.
# It includes outputs of the original forward, *and* any updated inputs due to input mutations.
# However, it does *not* include any outputs that are aliases of inputs or intermediates, or any metadata-only input mutations.
joint_inputs = (flat_args, fw_metadata.traced_tangents)
joint_fn_to_trace = create_joint(fn_prepared_for_autograd, aot_config=aot_config) # 生成正反向计算,封装成函数
fx_g = _create_graph(joint_fn_to_trace, updated_joint_inputs, aot_config=aot_config) # 通过make_fx()函数跟踪joint_fn_to_trace的计算过程生成joint_graph,以torch.fx.GraphModule格式返回
# _create_graph()的核心实现实现
# path:torch/fx/experimental/proxy_tensor.py::class _MakefxTracer
# ps:只展示核心代码实现
def _trace_inner(self, f, *args):
phs = pytree.tree_map(lambda _: fx.PH, args) # type: ignore[attr-defined]
args = _wrap_fake(args)
func = _wrap_func(f, phs)
# We disable the autocast cache as the autocast cache causes type conversions on parameters to
# check a cache, which introduces untracked tensors into the graph
#
# We also disable tracing by any other tensor proxy-based tracers except the current. The
# purpose of `make_fx  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









