







本文是torch.compile()流程解析系列文章,因此很多代码和样例需要结合前面的文章才会更容易理解哦~
PrimTorch
在上一节AOTAutograd构建joint graph的时候提及过op执行的时候,通过ProxyTorchDispatchMode的__torch_dispatch__对op进行decompose,具体流程是:
- 调用maybe_handle_decomp()函数在CURRENT_DECOMPOSITION_TABLE(一个Aten op映射表)中查找op对应的函数实现并返回,若未实现则进入b;
- 若不是则调用decompose()函数继续进行拆解,decompose()实现逻辑如下:
# decompose()函数实现
# path:/torch/_ops.py
def decompose(self, *args, **kwargs):
dk = torch._C.DispatchKey.CompositeImplicitAutograd
if dk in self.py_kernels:
# NB: This branch is not too necessary anymore, because we can
# apply Python CompositeImplicitAutograd *before* tracing
# using Python dispatcher (also taking advantage of the autograd
# formula). But it's included for completeness
return self.py_kernels[dk](*args, **kwargs)
elif torch._C._dispatch_has_kernel_for_dispatch_key(self.name(), dk):
return self._op_dk(dk, *args, **kwargs)
else:
return NotImplemented
从而实现high level op一步步拆解到Aten op的过程。总的来说,PrimTorch是一种规定,将所有的op拆解为一个约定的op规范集合,并作为开发者和硬件厂商之间的一种中间桥梁,Pytorch前端将op拆解映射到PrimTorch,而硬件厂商针对这些特定的op进行优化即可。但目前看到基本都是拆解到ATen op上,还没看到PrimTorch相关的op。
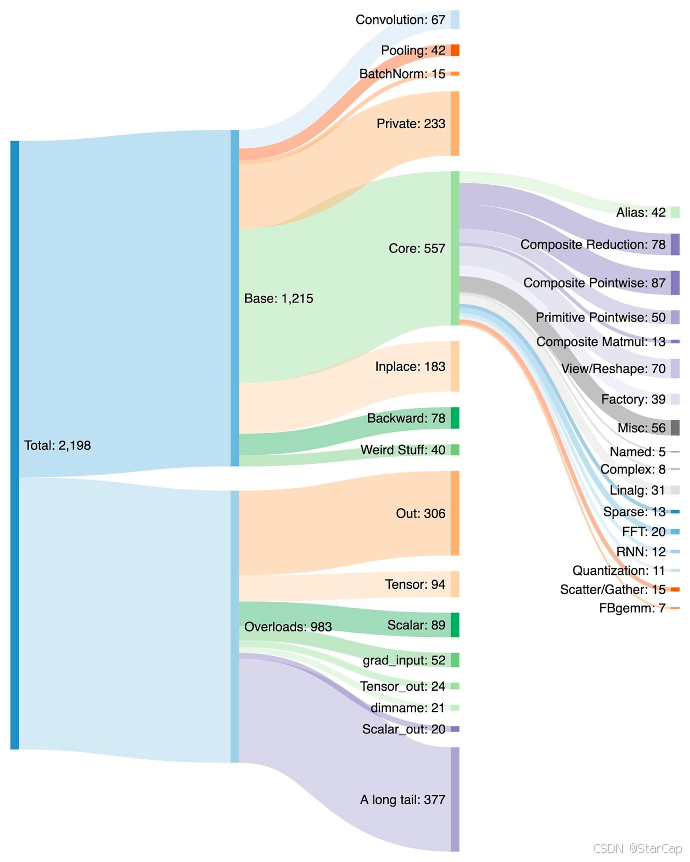
TorchInductor
TorchInductor 是 PyTorch 的一个高性能编译后端,专注于将优化后的计算图转换为高效的、针对特定硬件(如 CPU、GPU)的内核代码。它利用多种优化技术,包括内存优化、并行化和低层次的代码生成,以最大化计算性能。aot_dispatch_autograd()函数在拿到前反向的FX Graph后,分别调用fw_compiler、bw_compiler对前反向图进行编译,这里的fw_compiler和bw_compiler可以是不同的compiler,在inductor的默认实现中调用的是compile_fx_inner,而其中的核心函数是fx_codegen_and_compile(),负责对FX Graph进行图优化、Triton内核代码生成等。
TorchInductor的核心实现逻辑如下,感兴趣的小伙伴也可以看看后面的代码解析部分
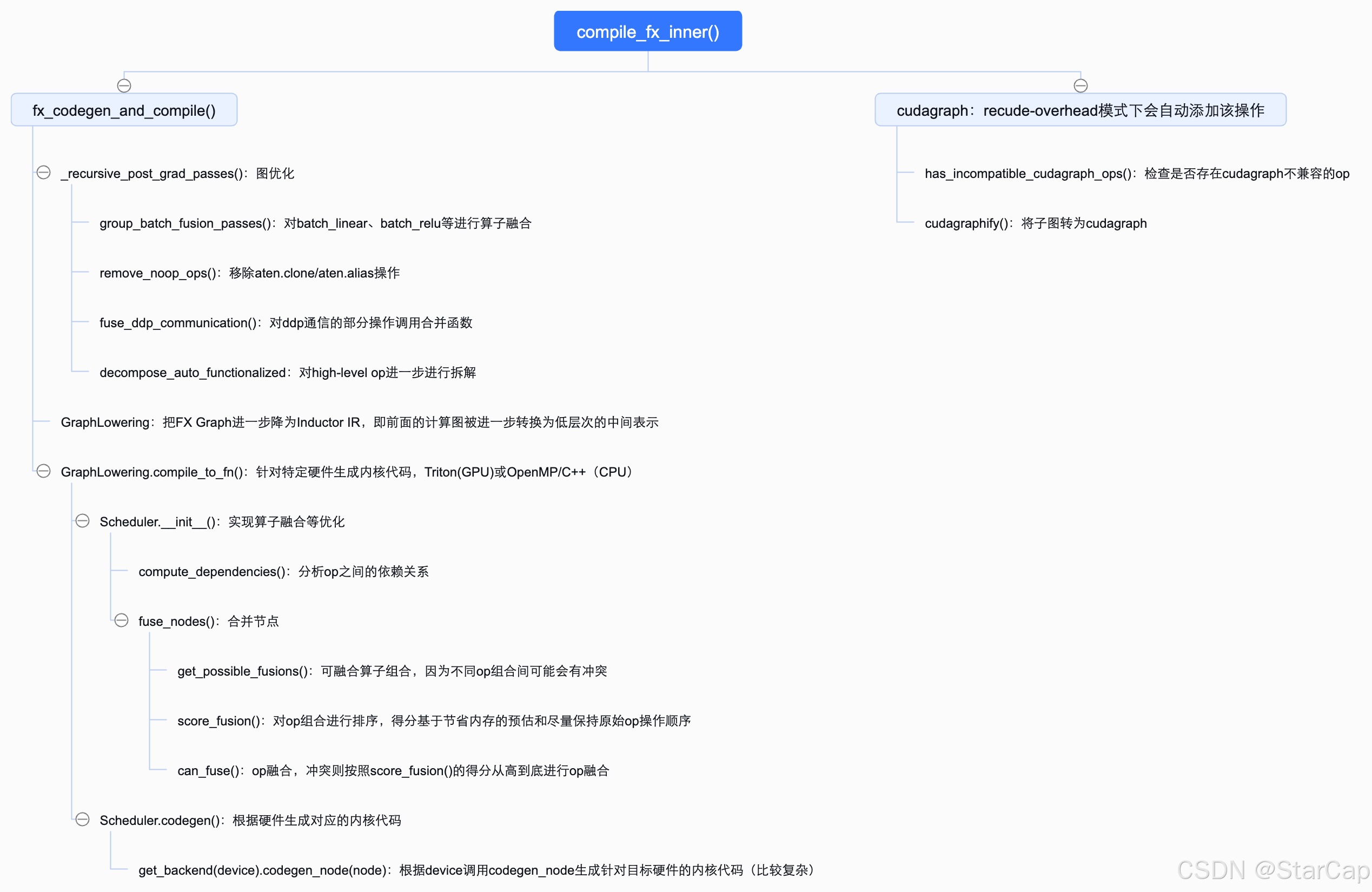
fx_codegen_and_compile()中比较重要的三个函数是:
- _recursive_post_grad_passes:负责对计算图进一步的优化,包括:
- group_batch_fusion_passes:对batch_linear、batch_relu、batch_sigmoid等归一化操作进行算子融合,先生成融合规则,然后以BFS的方式查找符合规则的op进行融合。
- remove_noop_ops:移除图形中本质上是 aten.clone 和aten.alias的操作。
- fuse_ddp_communication:对ddp通信的部分操作调用合并函数进行融合。
- decompose_auto_functionalized:对high-level op进一步进行拆解(因为前面进行算子融合那些操作可能会引入新的high level op所以这里再操作一遍),将高层次的操作逐步转换为更低层次的实现。
- GraphLowering:把FX Graph进一步降为Inductor IR,即前面的计算图被进一步转换为低层次的中间表示。这一表示更加接近最终的机器代码,并且适合进一步的代码生成和优化。
- GraphLowering.compile_to_fn():负责对前面生成的IR表示转换为针对目标硬件低层次代码,GPU上会生成Triton,CPU上会生成OpenMP/C++,同时可能会利用 SIMD 指令和多线程并行化来加速计算,是inductor中一个核心的实现。
compile_to_fn()——内核代码生成
compile_to_fn()在Scheduler类中实现内核代码编译的核心功能。而Scheduler的两个函数值得关注:
-
Scheduler.init():实现算子融合等优化,基本流程为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1419
1419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









