






题目要求:
1. 使用的文法如下:
E ->TE '
E ' -> + TE ' | #
T -> FT '
T '-> * FT '| #
F ->(E) | id
2. 对于任意给定的输入串(词法记号流)进行语法分析,使用非递归预测分析方法
3. 要有一定的错误处理功能。即对错误能提示,并且能在一定程度上忽略尽量少的记号来进行接下来的分析。可以参考书上介绍的同步记号集合来处理。
可能的出错情况:idid*id, id**id, (id+id, +id*+id ……
网上的前辈们已有完整的思路以及代码,详情可参考:
大连理工大学编译原理第4次上机—语法分析2_偷熊的小糖的博客-CSDN博客_例如. 使用的文法如下: e te ¢ e ¢ + te ¢ | e t f
但是这个代码有个小的bug,他在实现分析后,错把“)”也当成终结符。这样,导致的问题就是你的语法分析,在移进右括号后,程序判断已分析结束,然后程序就会自己停止,剩下的部分程序就会自动将其忽略。
以下是修改前的运行结果:
可以发现此时,在分析到第一个括号后,程序停止。栈中并没有移进第一个右括号后的内容。
修改思路呢,就是在Ee()和Te()中判断终结符后,添加新的判断ahead==")",且此时input[0]后为运算符号"+"或"*",进行新的分析。
这是修改后的代码:
#include<iostream>
#include<cstring>
#include<vector>
using namespace std;
static string input;
static string ahead;
void E();
void Ee();
void T();
void Te();
void F();
bool whether_in(string target,vector<string> v){
for(int i=0;i<v.size();i++)
if(target==v[i])
return true;
return false;
}
void nextToken(){
ahead.clear();
if(input[0]=='*'||input[0]=='+'||input[0]=='('||input[0]==')'||input[0]=='$'){
ahead += input[0];
input = input.substr(1);
}
else if(input[0]=='i'){
ahead = "id";
input = input.substr(2);
}
else if(input[0]==' '){ //如果开头是空格的话就跳过
nextToken();
}
}
void E(){
vector<string> synch;
synch.push_back(")");
synch.push_back("$");
if(ahead == "id"||ahead == "("){
cout << "E->TE'" << endl;
T();
Ee();
}
else if(whether_in(ahead,synch)){
cout << "弹栈,弹出非终结符E,用户少输入了一个id"<<endl;
}
else{
cout << "输入串跳过记号" << ahead << ",用户多输入了一个" << ahead << endl;
nextToken();
E();
}
}
void Ee(){
if(ahead=="+"){
cout << "E'->+TE'" << endl;
nextToken();
T();
Ee();
}
else if(ahead=="$"||ahead==")"){
cout << "E'->#" << endl;
if(ahead==")"){
if(input[0]=='+')
{
nextToken();
Ee();
}
else if(input[0]=='*'){
nextToken();
Te();
}
}
//return ;
}
else{
cout << "输入串跳过记号" << ahead << ",用户多输入了一个" << ahead << endl;
nextToken();
Ee();
}
}
void T(){
vector<string> synch;
synch.push_back("+");
synch.push_back(")");
synch.push_back("$");
if(ahead == "("||ahead=="id"){
cout << "T->FT'" << endl;
F();
Te();
}
else if(whether_in(ahead,synch)){
cout << "弹栈,弹出非终结符T,用户少输入了一个id"<<endl;
}
else{
cout << "输入串跳过记号" << ahead << ",用户多输入了一个" << ahead << endl;
nextToken();
T();
}
}
void Te(){
if(ahead == "*"){
cout << "T'->*FT'" << endl;
nextToken();
F();
Te();
}
else if(ahead=="$"||ahead=="+"||ahead==")"){
cout << "T'->#" << endl;
if(ahead==")"){
if(input[0]=='+')
{
nextToken();
Ee();
}
else if(input[0]=='*'){
nextToken();
Te();
}
}
//return ;
}
else{
cout << "输入串跳过记号" << ahead << ",用户多输入了一个" << ahead << endl;
nextToken();
Te();
}
}
void F(){
vector<string> synch;
synch.push_back("+");
synch.push_back("*");
synch.push_back(")");
synch.push_back("$");
if(ahead=="id"){
cout << "F->id" << endl;
nextToken();
}
else if(ahead=="("){
cout << "F->(E)" << endl;
nextToken();
E();
if(ahead!=")"&&ahead!="$")
cout << "弹栈,弹出终结符),用户少输入了一个)" << endl;
}
else if(whether_in(ahead,synch)){
cout << "弹栈,弹出非终结符F,用户少输入了一个id"<< endl;
}
else{
cout << "输入串跳过记号" << ahead << ",用户多输入了一个" << ahead << endl;
nextToken();
F();
}
}
int main(){
char in[100];
cin.getline(in,100);
input = in;
input+="$";
cout<<"输出:"<<endl;
nextToken();
E();
return 0;
}
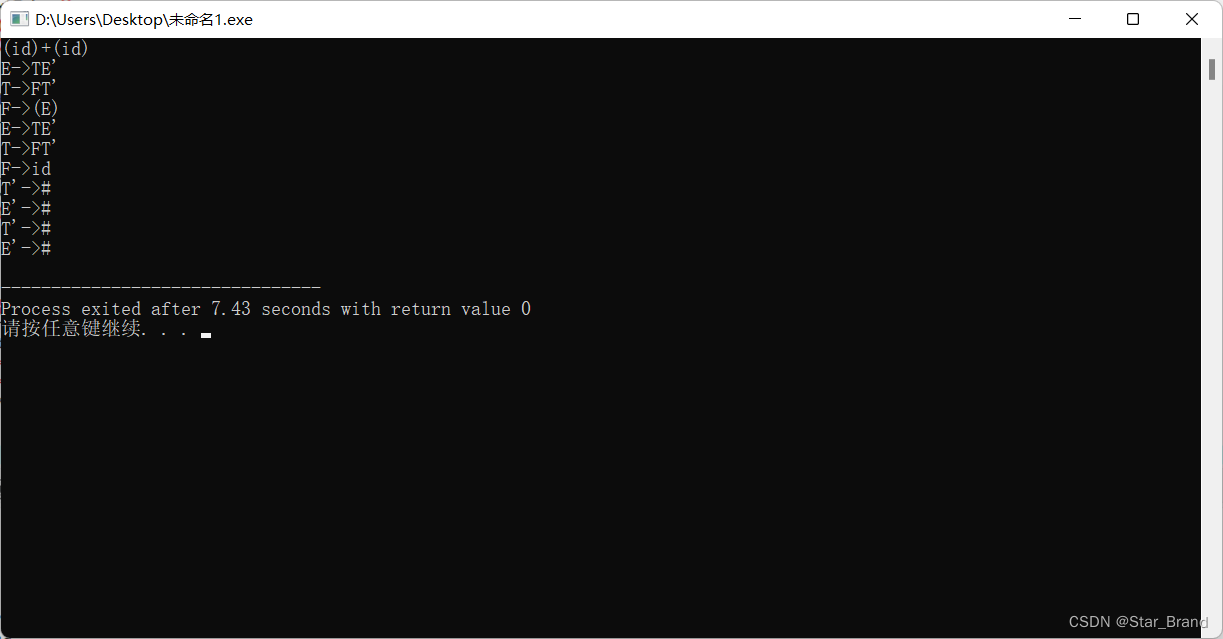
以下是运行截图:
 这是就出现了两个F->(E)的分析过程,结果正确。 经过测试,应该运行上没有bug了,可以放心使用。
这是就出现了两个F->(E)的分析过程,结果正确。 经过测试,应该运行上没有bug了,可以放心使用。














 2789
2789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









