







一、问题发现
这两天全世界都在讨论deepseek,掀起热潮,而我需要做一个大模型方面的项目,于是选择了DeepSeek-R1-Distill-Llama-8B,一个蒸馏过的r1模型,参数量80亿,大约需要显存8G,我的笔记本正好带的动,然后就开始了本地部署。
主要的依赖选择的是unsloth,通过modelscope下载了DeepSeek-R1-Distill-Llama-8B
import torch
from unsloth import FastLanguageModel
#模型一些参数配置
max_seq_length = 2048 #序列最长限制
dtype = None
load_in_4bit = False
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "./DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
FastLanguageModel.for_inference(model)
#提问
question = "请问为什么先经过转置的再求逆的矩阵和先经过求逆再经过转置的矩阵相等?"
#借助分词器,将输入的问题转化为标记索引:
inputs = tokenizer([question], return_tensors="pt").to("cuda")
print(inputs)
#输入模型进行推理
outputs = model.generate(
input_ids=inputs.input_ids,
max_new_tokens=1200,
use_cache=True,
)
#得到回答也是token索引
print(outputs)在进行到模型推理model.generate时报错:unsupported autocast device_type 'meta'。
通过查询资料发现meta 设备用来模拟张量的形状和类型,但不分配实际的内存,实际原因是显存不足自动把部分模型参数的设备设为了meta
可以通过以下代码检查param.device
for name, param in model.named_parameters():
print(f"{name}: {param.device}")我的输出如下:
model.layers.0.self_attn.k_proj.weight: cpu
model.layers.0.self_attn.v_proj.weight: cpu
model.layers.0.self_attn.o_proj.weight: cpu
model.layers.0.mlp.gate_proj.weight: cpu
...
model.layers.31.input_layernorm.weight: meta
model.layers.31.post_attention_layernorm.weight: meta
model.norm.weight: meta
lm_head.weight: meta部分参数在cpu,部分在meta上。
二、问题解决
1. 先检查自己的torch版本和cuda是否可用
print(torch.__version__)
print(torch.cuda.is_available())torch.__version__应该输出 版本号X.X.X + cuXXX
torch.cuda.is_available() 应该是True
若不是则需要重新安装gpu版本的torch
2. 检查自己的显存是否够用
命令行cmd 输入nvidia-smi 输出自己显卡情况,查看 Memory-Usage
确保最大容量可以保证运行自己的模型。我的情况如下图:
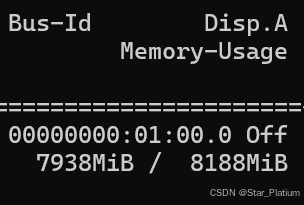
最大容量8G左右,但是几乎被占满。如果模型还没有加载,这时需要关掉一些占用显存的应用比如浏览器、大型游戏,或者重启电脑也可以清空占用。
3. 在加载模型前应该指定device类型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")然后在加载模型时设置device_map参数 = {"": device}
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "./DeepSeek-R1-Distill-Llama-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
#修改部分
device_map={"": device}, # 将所有参数加载到指定设备
)接着重新运行这一段代码,如果报错再检查之前的步骤。
模型运行成功之后再检查下各参数的device是否为cuda:0,如果是则成功将模型部署到gpu。
model.layers.2.self_attn.o_proj.weight: cuda:0
model.layers.2.mlp.gate_proj.weight: cuda:0
model.layers.2.mlp.up_proj.weight: cuda:0
...
model.layers.31.input_layernorm.weight: cuda:0
model.layers.31.post_attention_layernorm.weight: cuda:0
model.norm.weight: cuda:0
lm_head.weight: cuda:0
















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









