






第二部分 :高级学习算法
第一章
1.1 简介
本部分将学习神经网络和决策树,当你在搭建一个实用的机器学习系统时,需要收集很多数据,选择一个更大的gpu来建立更大的神经网络。
将讨论神经网络以及如何进行推断或预测,如何训练自己的神经网络,还有建造机器学习系统的实用建议,最后将学习决策树(也是一个非常强大的算法)。
1.2 神经元和大脑
现代神经网络产生巨大影响的第一个领域是语音识别,得到了更好的语音识别系统,接着进入计算机视觉领域,在接下来的几年进入文本或自然语言处理等领域,现在被用于各行各业,机器学习在许多领域都使用神经网络。
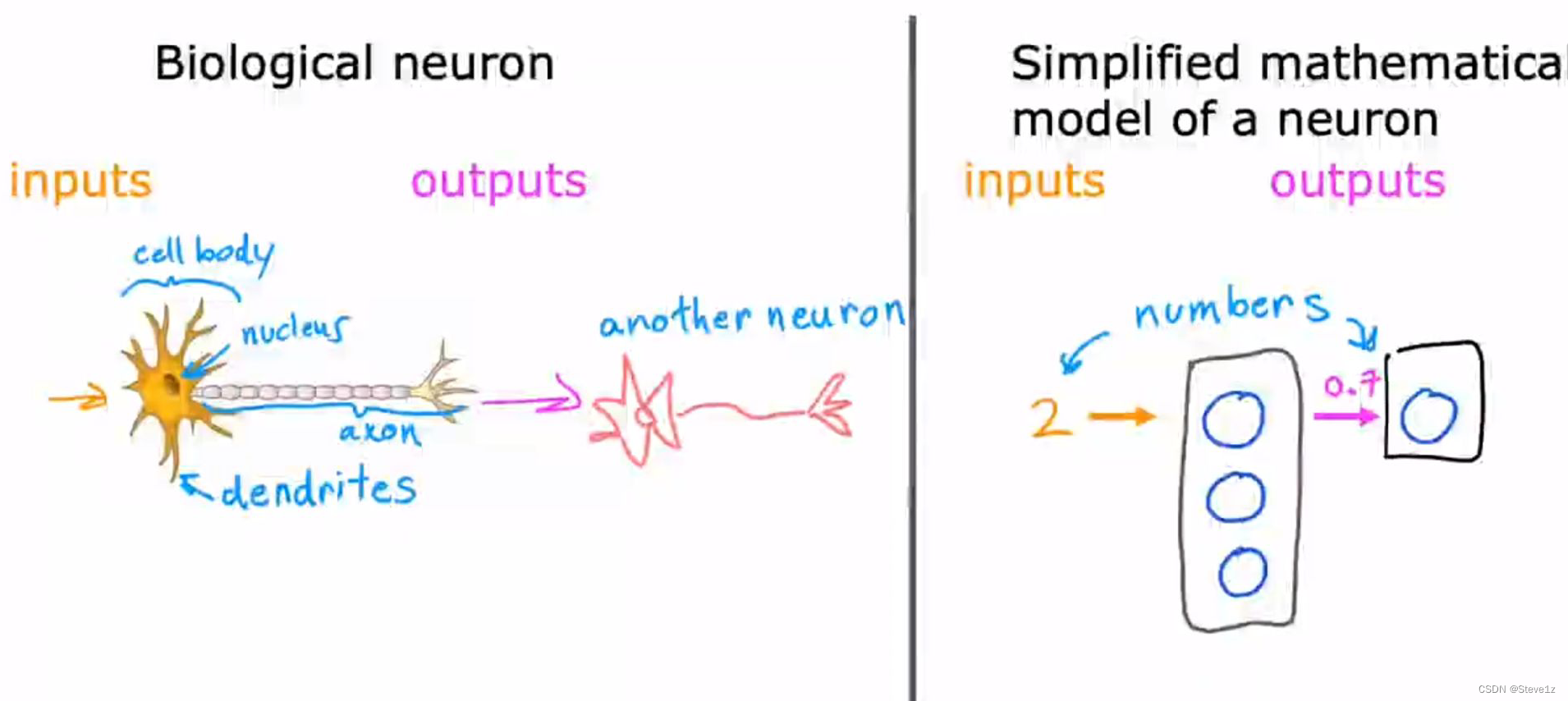
根据人类神经元的工作情况,人工神经网络使用了一个比较简单的模型来表示,即输入一个数字进入神经元,再通过一些计算输出一个数字给下一个神经元。
1.3 需求预测
将演示神经网络如何工作,首先举一个简单的例子,预测衬衫的售价与能否畅销的关系,这是一个逻辑回归,如下图。
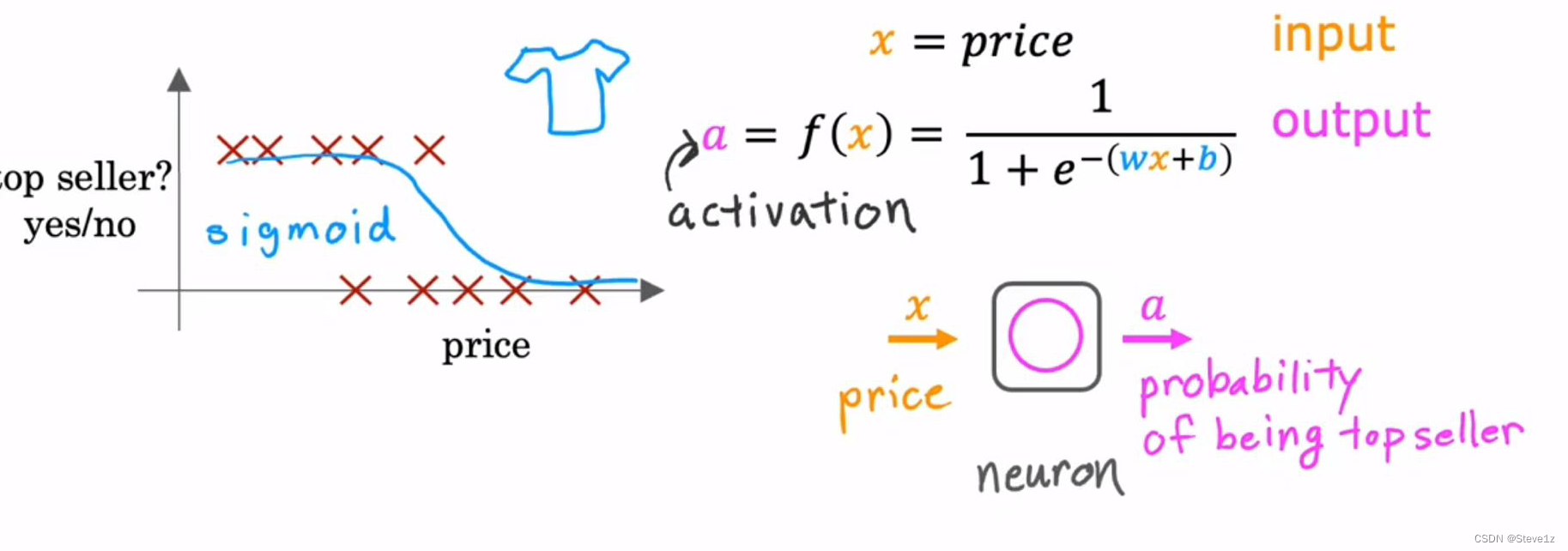
输入x为售价,输出f(x)为能否热销,在深度学习中f(x)也被称为a,即激活的意思。将这个过程模拟为神经元工作,即给神经元输入一个x,得到一个输出a。
当有多个特征时,它的神经网络更加复杂,分为多层,其中各种特征值为输入层,第一层神经元(隐藏层)对相似的特征进行处理并输出数值,这些数值再输入到第二层神经元(输出层),输出得到结果,具体流程如下图。
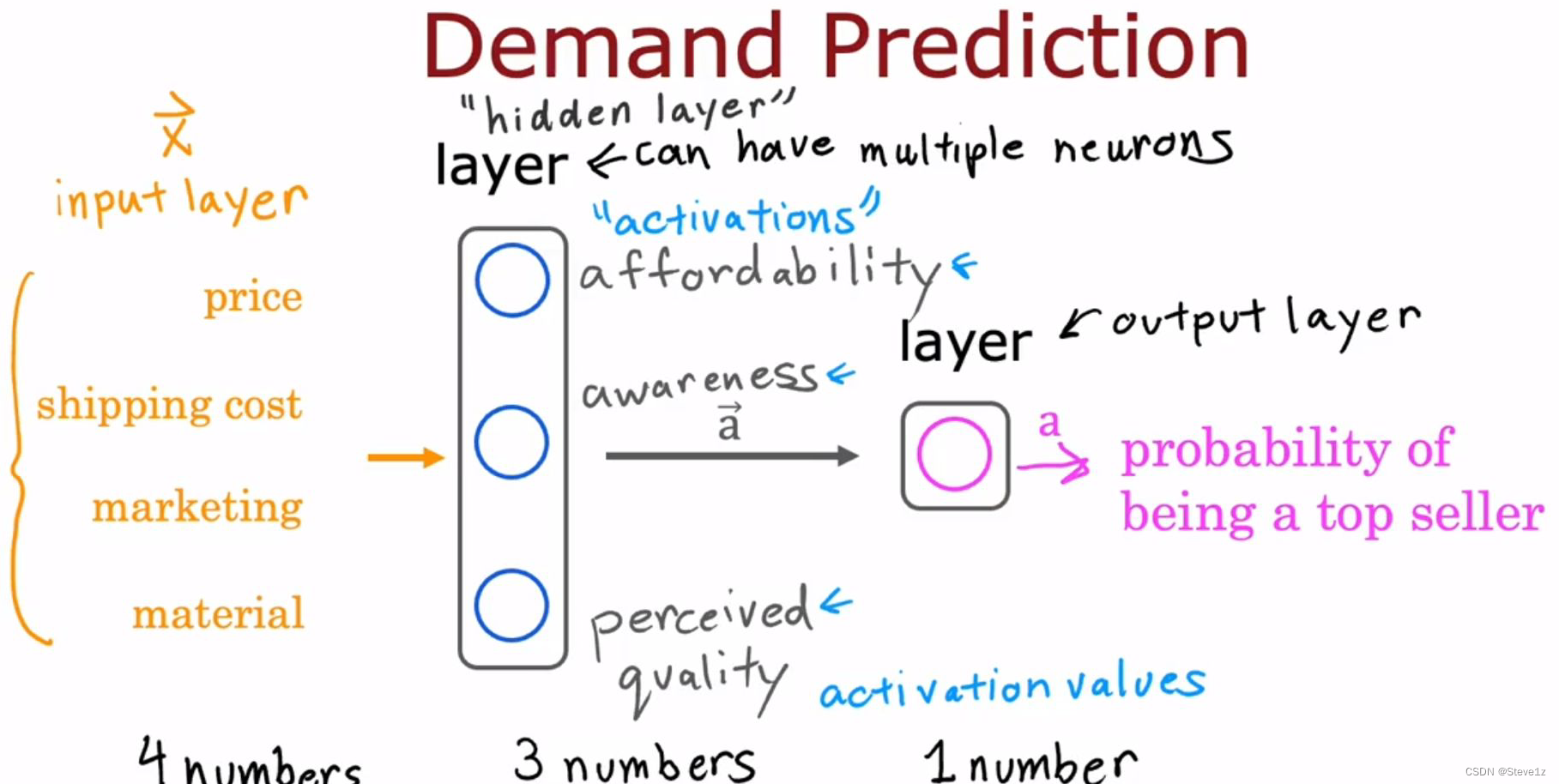
你不用动手设计神经网络可以学习的功能;它的特性是当你用数据进行训练时,不用明确地决定功能,它能自己找出在隐藏层中使用的功能。
当你自己建造神经网络时,需要决定设置多少个隐藏层,每个隐藏层有几个神经元,这便是学习神经网络的架构问题;不同的选择会对算法的性能产生影响。当设置多层隐藏层时,也可以称作多重层感知器。
1.4例子:图像识别
为了方便理解上一节的内容,下面通过图像识别的例子,更好地理解神经网络的结构。

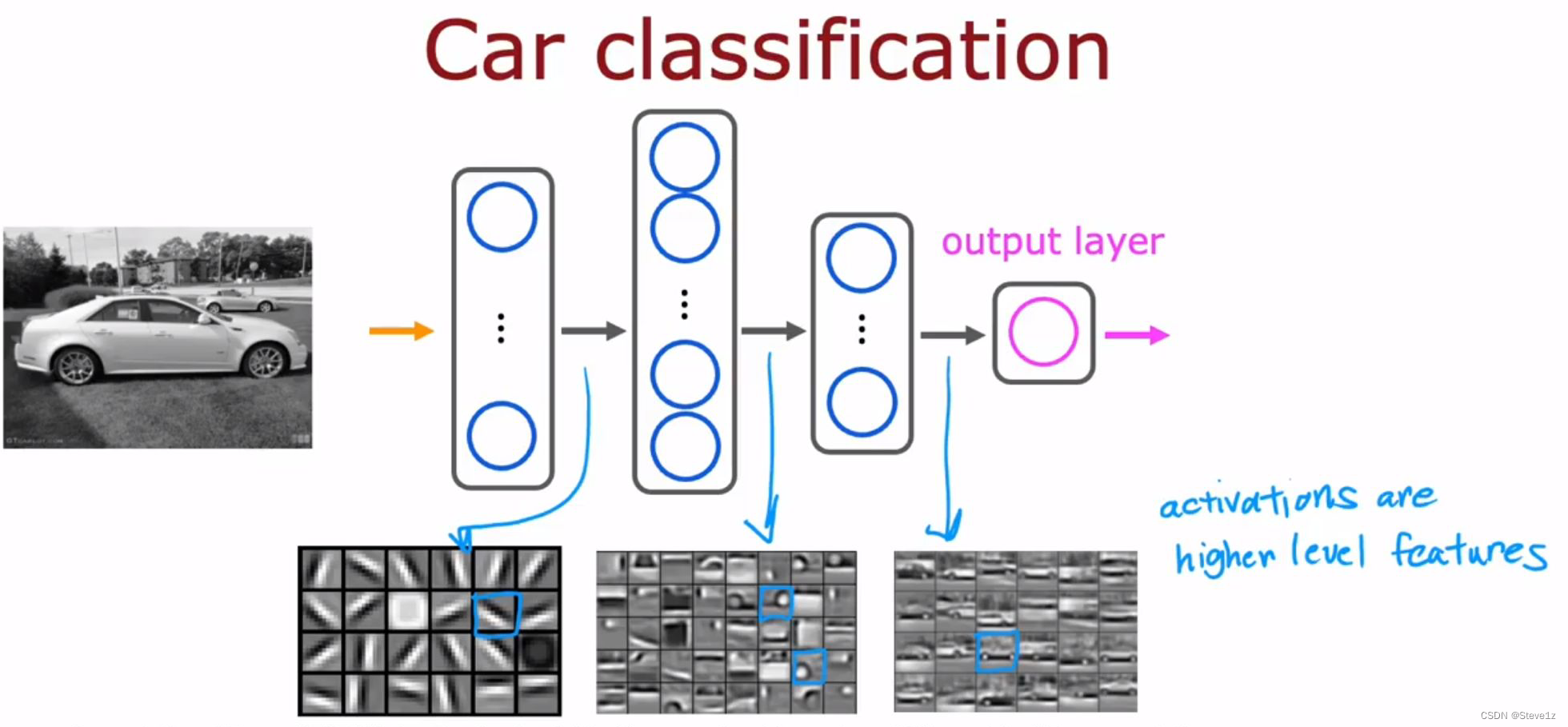
可以看到,在该系统中,输入为图片,输出为图片中人物的身份,图中有三层隐藏层,每一层的神经元工作内容都不相同,第一层隐藏层的神经元主要识别不同方向的线条,第二层的神经元则是识别脸部的某些部位,第三层则是在识别不同脸型的人脸,为最后的输出层提供判决的依据。可以发现每一层神经元识别图像的大小也不同,更有趣的是如果输入的图像不同,例如改成输入汽车的图案,则可以变成识别汽车的系统,如下图。
第二章 神经网络模型
2.1神经网络的层
如何构建神经网络的层,每个神经元都在执行一个小的逻辑回归单元或逻辑回归功能,因此每个神经元的输入都通过逻辑函数g(z)得到输出(激活值a),所有神经元的输出构成激活向量,
又作为第二层的输入,再通过第二层的逻辑函数g(z)得到输出,再对输出值进行比较,得到最后的结果y,具体过程如下图。
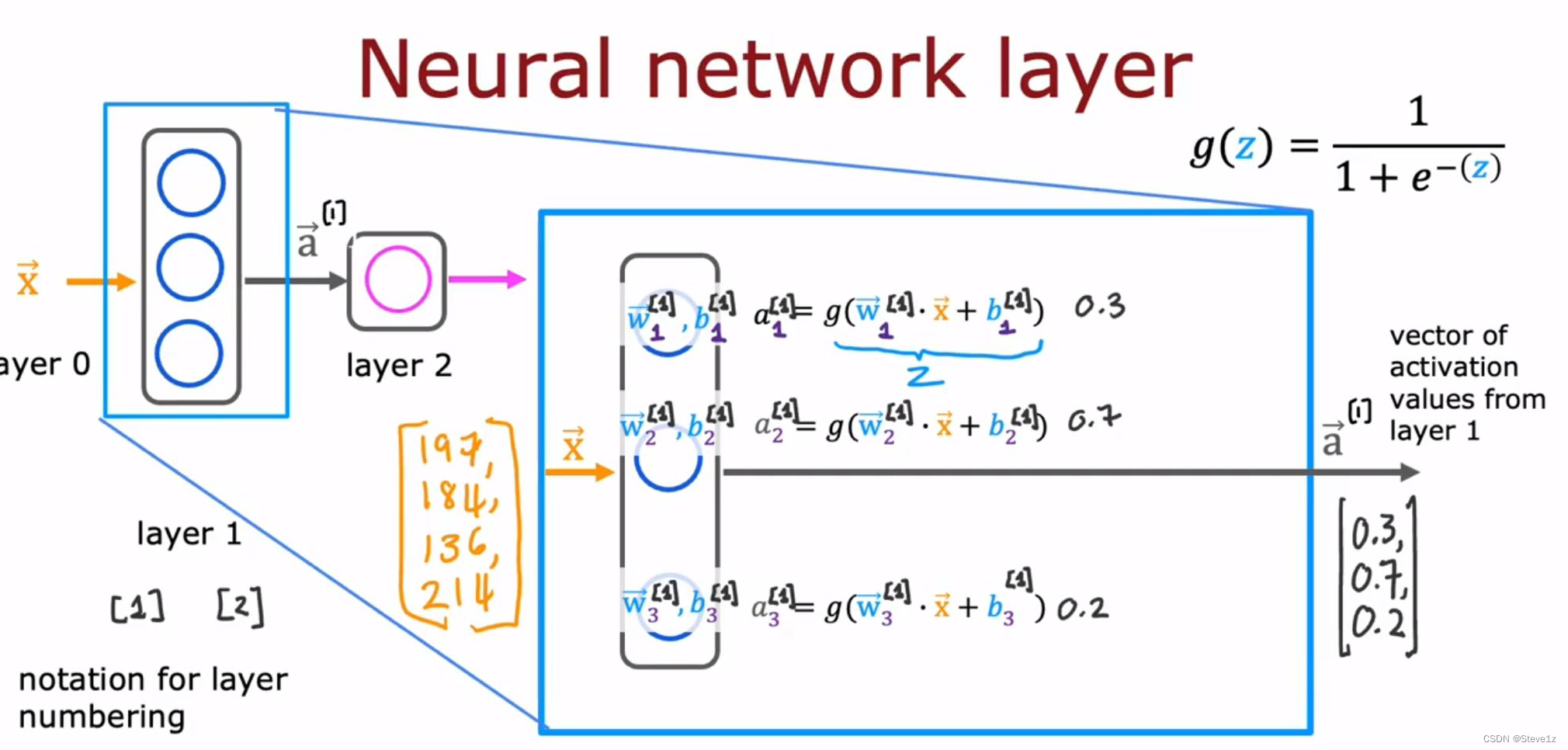
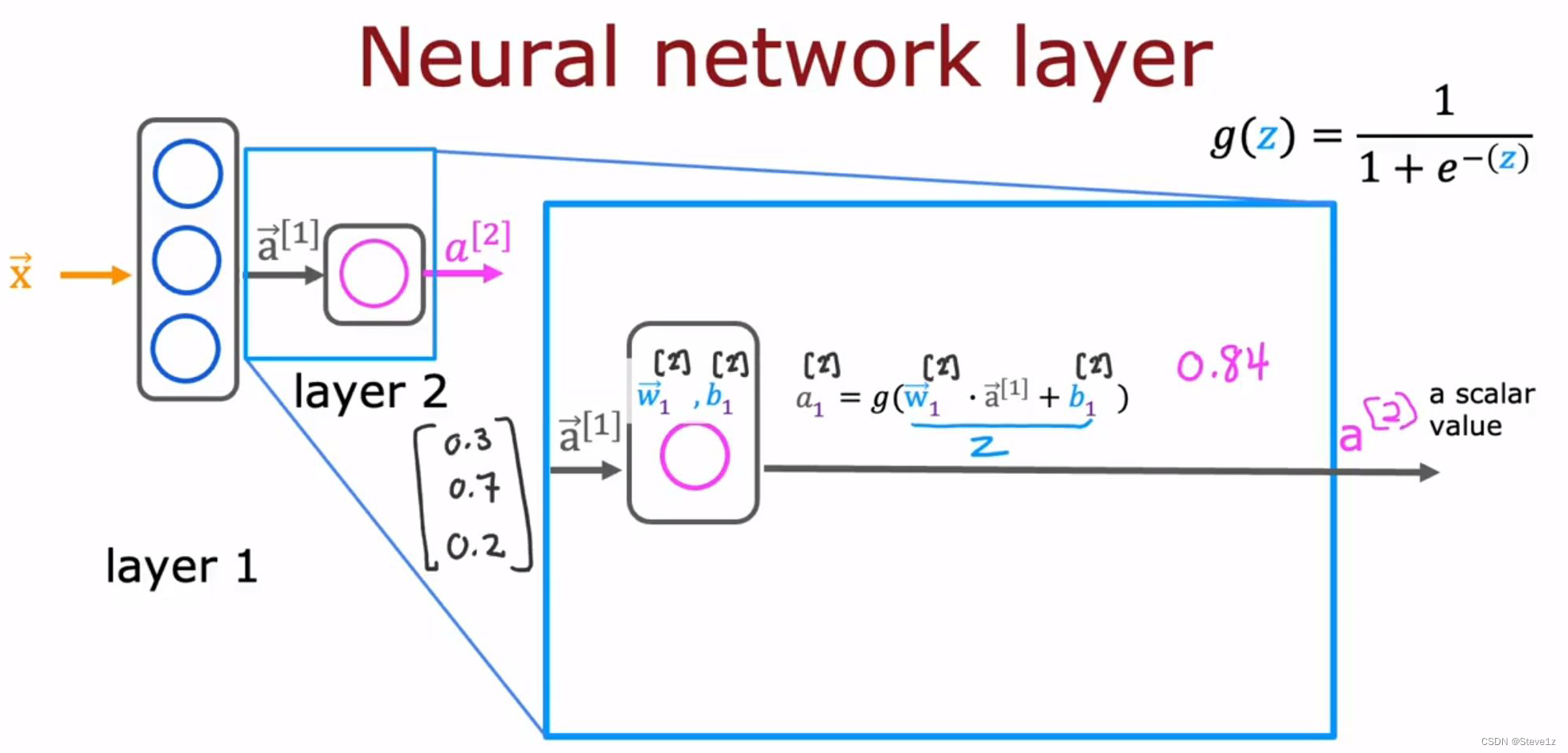
2.2 更复杂的神经网络
当有多层隐藏层时需要注意上标数字,具体见下图:

例如图中的第三层,是第二层的激发向量作为输入端,第三层的输出中所有参数的上标应该是3,它们都属于第三层。
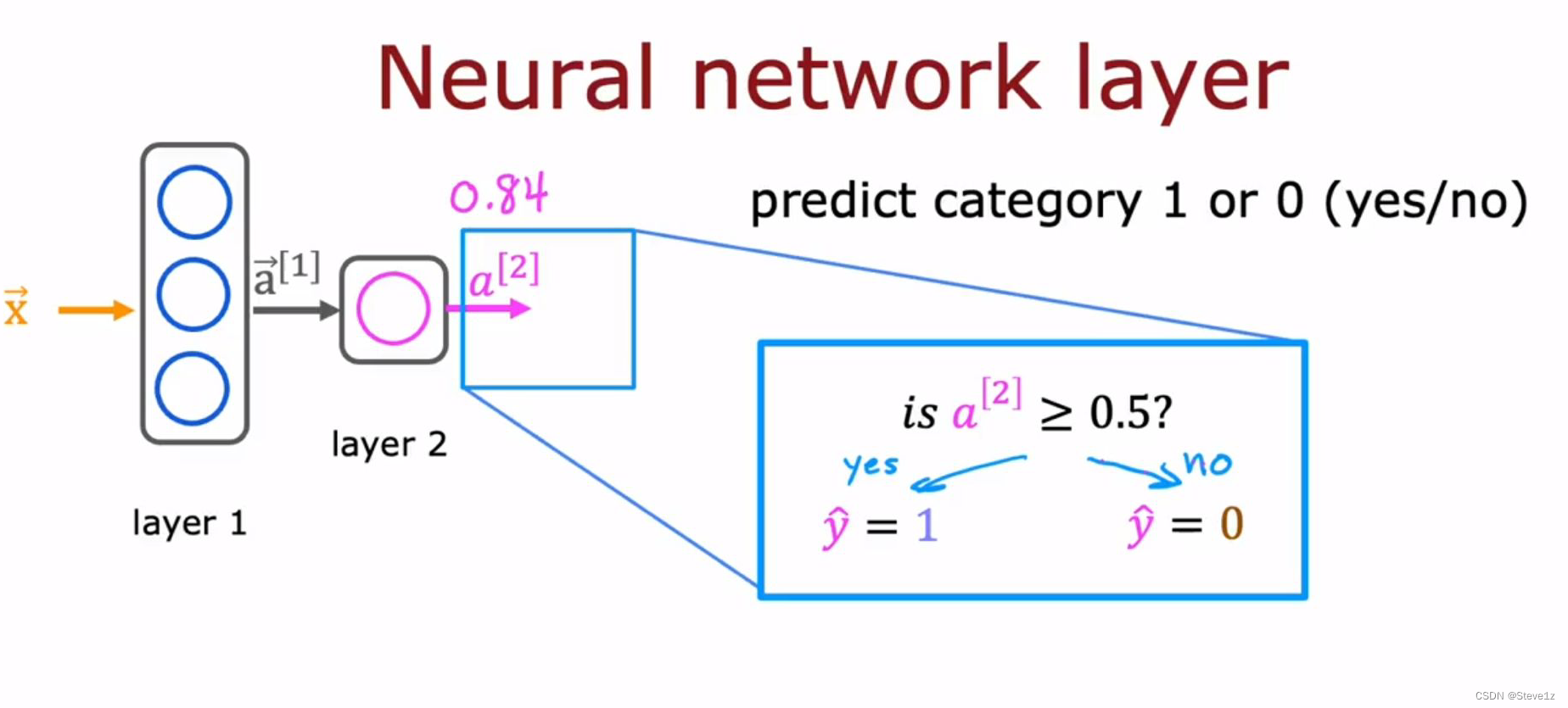
2.3 做出预测(前向传播 forward propagation)
这里主要举了识别手写数字1和0的例子,它的神经网络结构如下图:
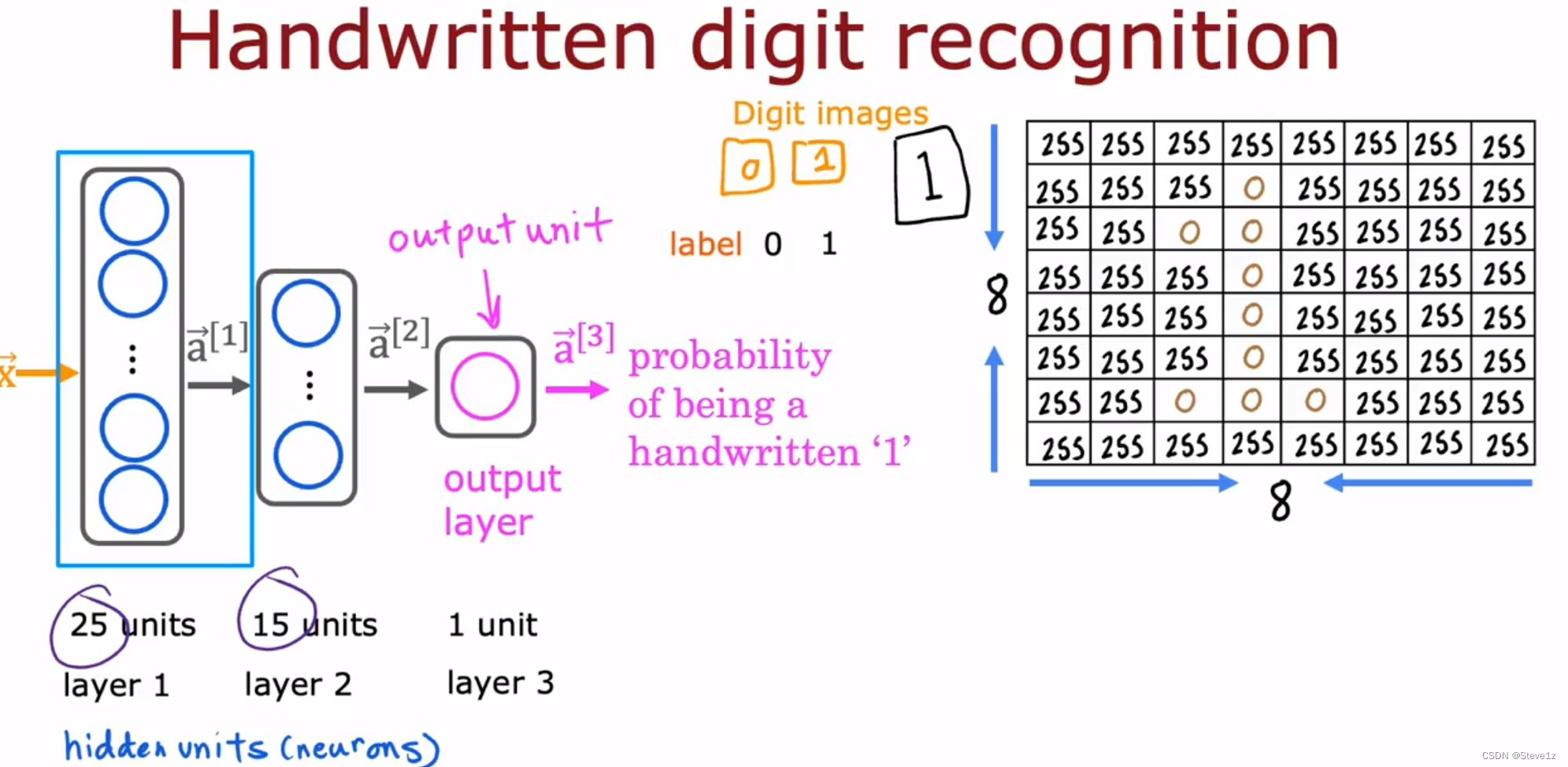
8*8的手写图像1作为输入,分别经过两层隐藏层得到再通过输出层得到
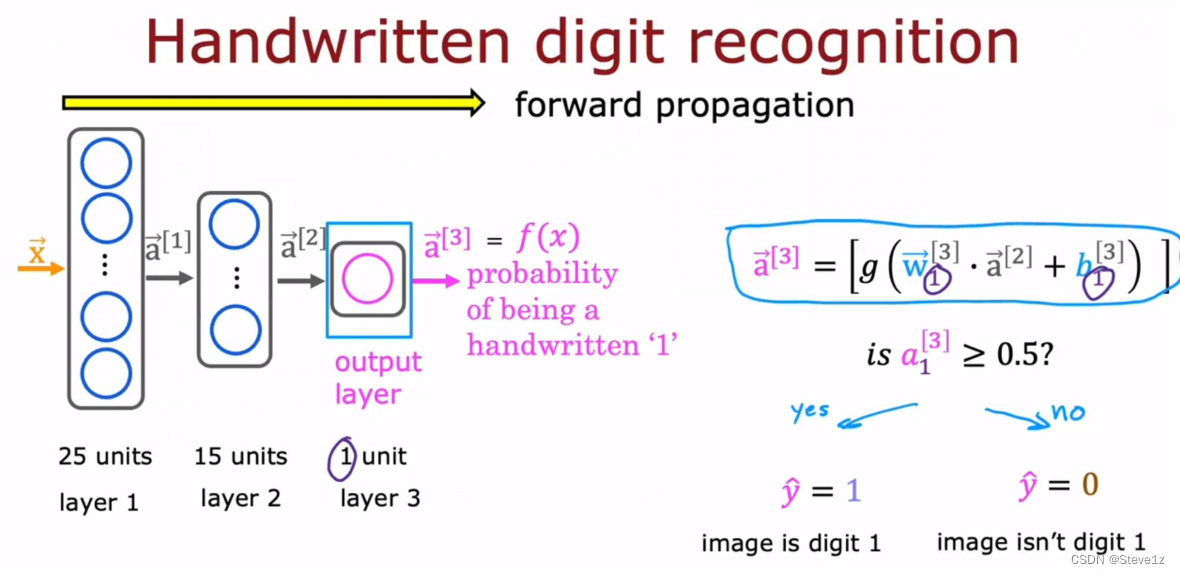
再通过判断的值,确定图像是否为1。
第三章 TensorFlow 实现
3.1 代码中的推理
TensorFlow是实现深度学习算法的领先框架之一,神经网络的非凡之处是同样的算法可以应用与多不同的应用。下面列举了烤咖啡的例子,有烘烤温度和烘烤时间两个变量,不难发现当时间较短或温度较低,都不能获得好的咖啡豆,同样的过度烘烤也不行。
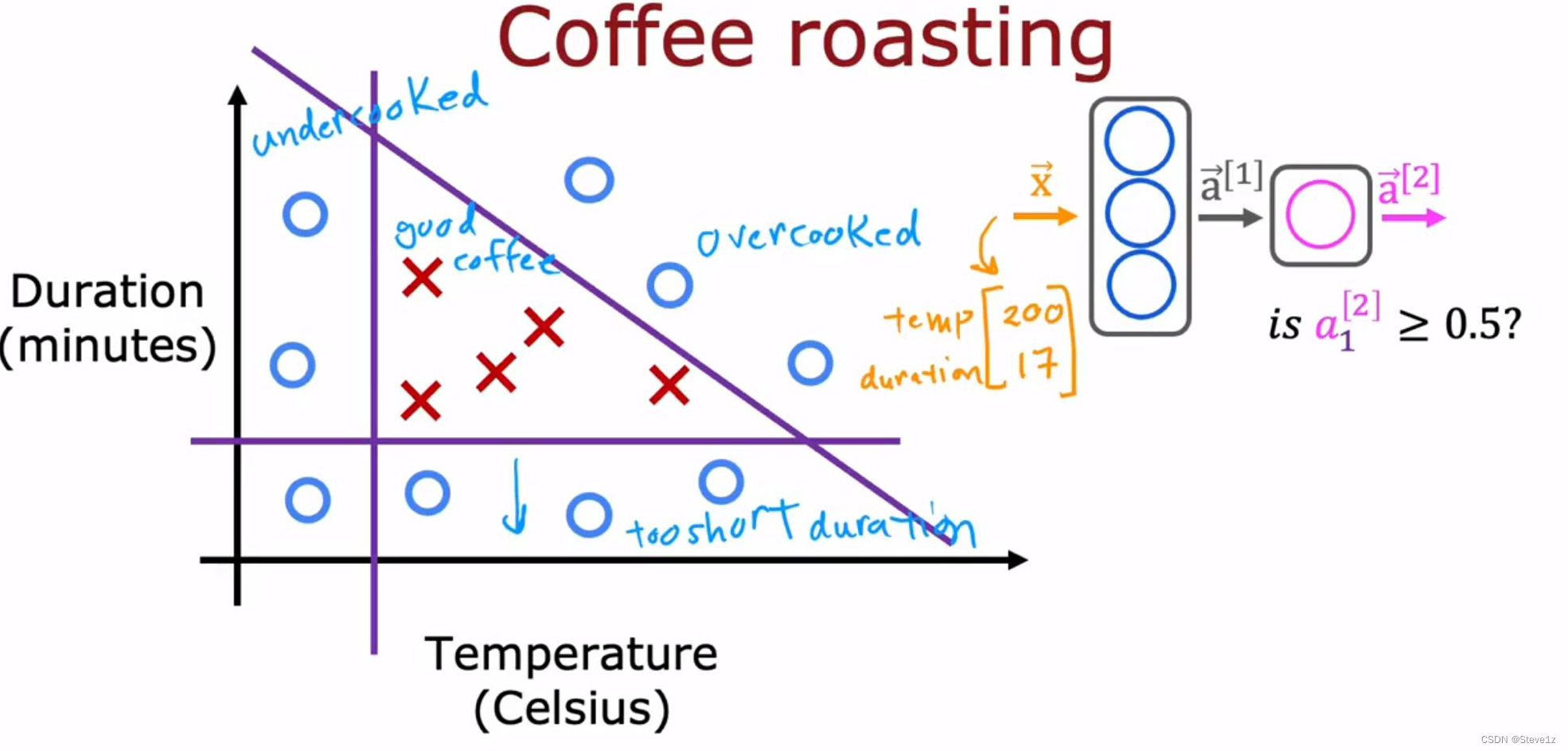
下面将针对这一问题通过神经网络进行解决,相关代码如下:
第一层
x =np.array([[200.0,17.0]]) #把x设置为温度和时间的数组
layer_1 = Dense(units=3,activation='sigmoid') #创造一个隐藏层,包含三个神经元,并采用sigmod函数
a1 = layer_1(x) #计算激活值
输出层
layer_2 = Dense(units=1,activation='sigmoid') #创造一个输出层,包含一个神经元,并采用sigmod函数
a2 = layer_2(a1) #计算激活值判断
if a2 >= 0.5:
yhat = 1
else:
yhat = 0对于上一节中的判断手写数字的例子,有以下代码:
第一层隐藏层:
x = np.array([[0.0,...245,...240...0]])
layer_1 = Dense(units=25,activation='sigmoid') #创造一个隐藏层,包含25个神经元,并采用sigmod函数
a1 = layer_1(x) #计算激活值
第二层隐藏层:
layer_2 = Dense(units=15,activation='sigmoid') #创造一个隐藏层,包含15个神经元,并采用sigmod函数
a2 = layer_2(a1) #计算激活值第三层输出层:
layer_3 = Dense(units=1,activation='sigmoid') #创造一个输出层,包含一个神经元,并采用sigmod函数
a3 = layer_3(a2) #计算激活值判断
if a3 >= 0.5:
yhat = 1
else:
yhat = 03.2 TensorFlow中的数据
在构建神经网络时,可以有一个一致的框架来考虑如何表示数据,在用Numpy和张量流表示数据时存在一些不一致的地方。
矩阵的表示方法:

当只有列向量或行向量时:
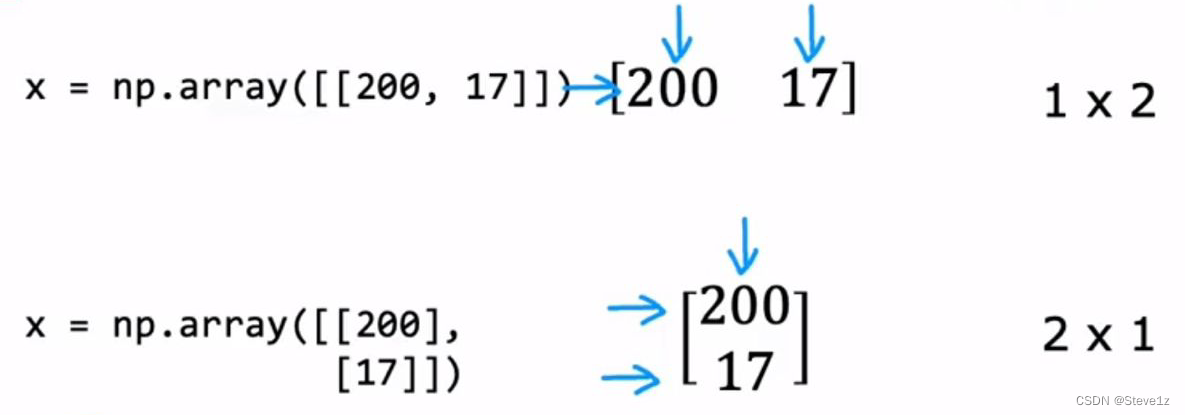
上图是矩阵的表示方法,表示为矩阵是为了方便处理大量数据,使其更加高效。
在线性回归和逻辑回归中会采用向量表示,如下图:
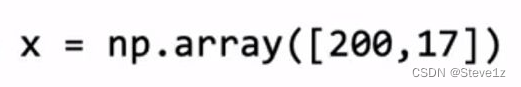
张量是张量流创作的数据类型,用于矩阵上充分存储和执行计算,其表示方法如下:
tf.Tensor([[0.2,0.7,0.3]],shape=(1,3),dtype=float32) #表示张量,shape表示矩阵形状1*3,设置数字类型为浮点型,例子如下图

可以使用numpy将张量流转化为numpy矩阵。
3.3 构建神经网络
本节讲述构建神经网络的方法,包括一种与之前不同更简便的方法。
新方法代码如下:
layer_1 = Dense(units=3,activation='sigmoid')
layer_2 = Dense(units=1,activation='sigmoid')
model = Sequential([layer_1,layer_2]) #将第一层与第二层串在一起,顺序函数
x = np.array([[200.0,17.0],
[120.0,5.0],
[425.0,20.0],
[212.0,18.0])
y = np.array([1,0,0,1])
model.fit(x,y) #训练数据
model.predict(x_new) #通过新的x预测y具体表示如下图:
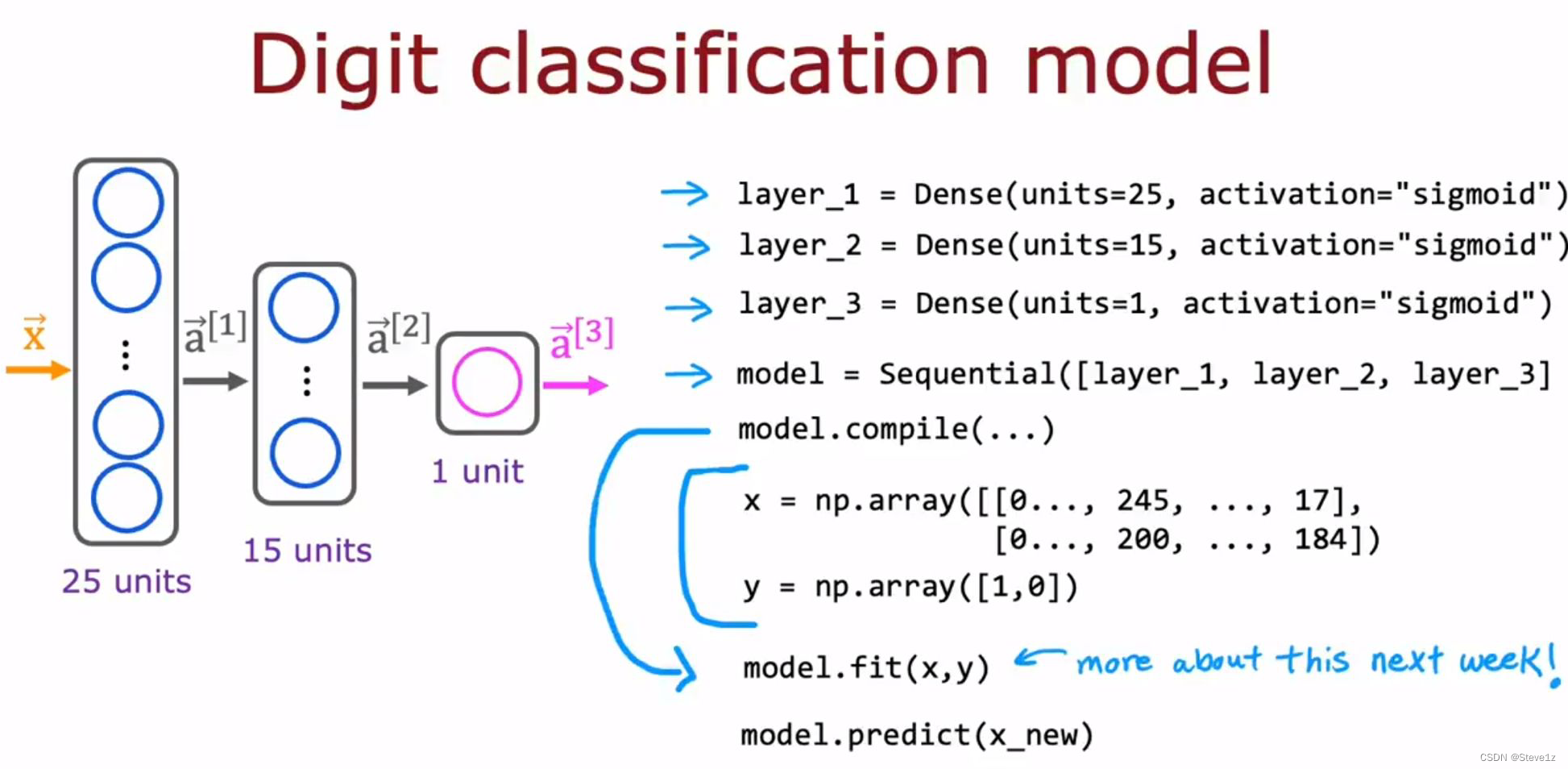
第四章 在python中实现神经网络
4.1 在单层中的前项传播
一个神经元中的代码:
w1_1 = np.array([1,2])
b1_1 = np.array([-1])
z1_1 = np.dot(w1_1,x)+b #np.dot(a,b)是指两个向量相乘
a1_1 = sigmoid(z1_1) #采用sigmoid函数计算整个层的输出:
a1 = np.array([a1_1,a1_2,a1_3])整个神经网络代码如下图:

4.2 前项传播的一般实现
python中更常用的forward prop实现,
定义函数来实现一个隐藏层:
def dense(a_in,W,b,g): #定义函数,将前一层的激活作为输入,给定参数w和b
units = w.shape[1] #设置神经元数量,即w的列数
a_out = np.zeros(units) #将a_out设置为元素与神经元数量相同的0向量
for j in range(units): #j取值为0,1,2
w = W[:,j] #将矩阵W的第j列赋值给w
z = np.dot(w,a_in)+b[j] #计算出z
a_out[j] = g(z) #赋值给 a_out
return a_out定义函数将多层按顺序连接在一起,构成神经网络:
def sequential(x):
a1 = dense(x,W1,b1)
a2 = dense(a1,W2,b2)
a3 = dense(a2,W3,b3)
a4 = dense(a3,W4,b4)
f_x = a4
return f_x需要注意的是,大写字母代表矩阵,小写代表向量

第五章 关于通用人工智能的假设
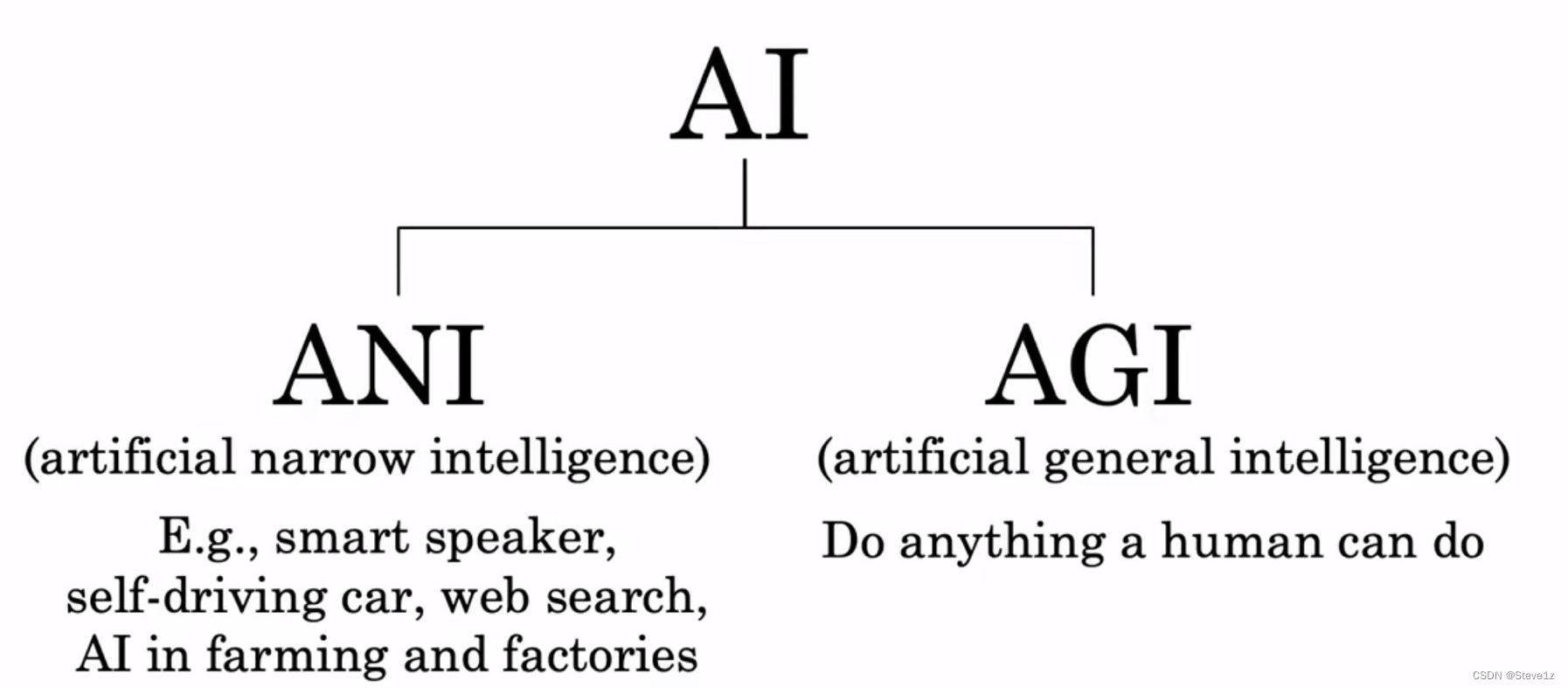
5.1 是否有路通向AGI
首先阐述了两种不同的关于AI的认知,如下图:
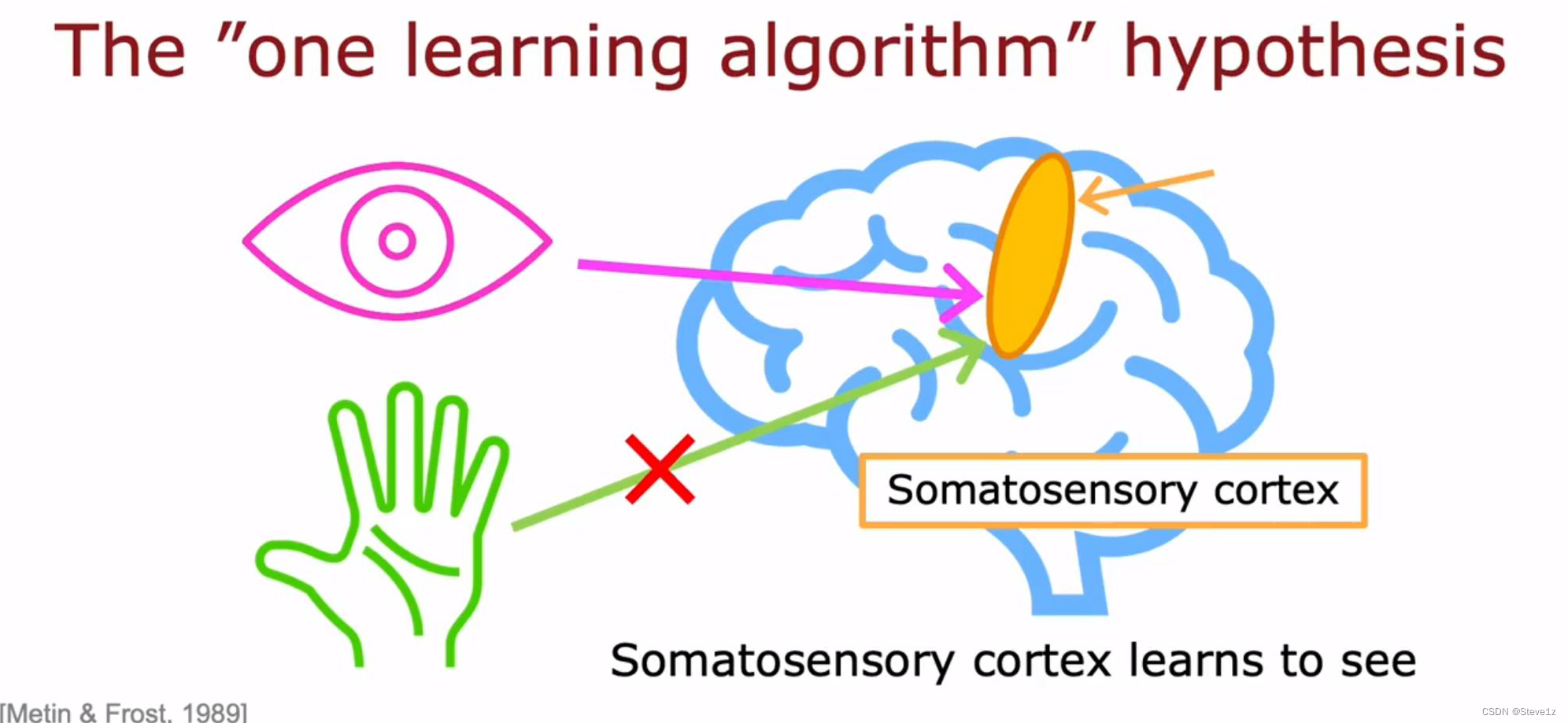
接着指出了人的大脑每一部分只能实现一部分功能,是因为其只接受了那部分的数据,并通过实验证明如果给头脑其他部分的信息也可以执行其他功能,就和神经网络相似。
第六章 矢量化
6.1 神经网络如何高效实现
神经网络矢量化,使用矩阵乘法可以有效提高它的效率,并且计算机中的GPU和CPU的一些功能非常擅长做非常大量的矩阵乘法。

上图分别列举了采用向量和矩阵的方法的代码,可以看出当用矩阵表示参数时,代码更加简洁,且运算效率更高。
6.2 6.3 矩阵的知识
已经在之前的笔记中记录,这里不再叙述。
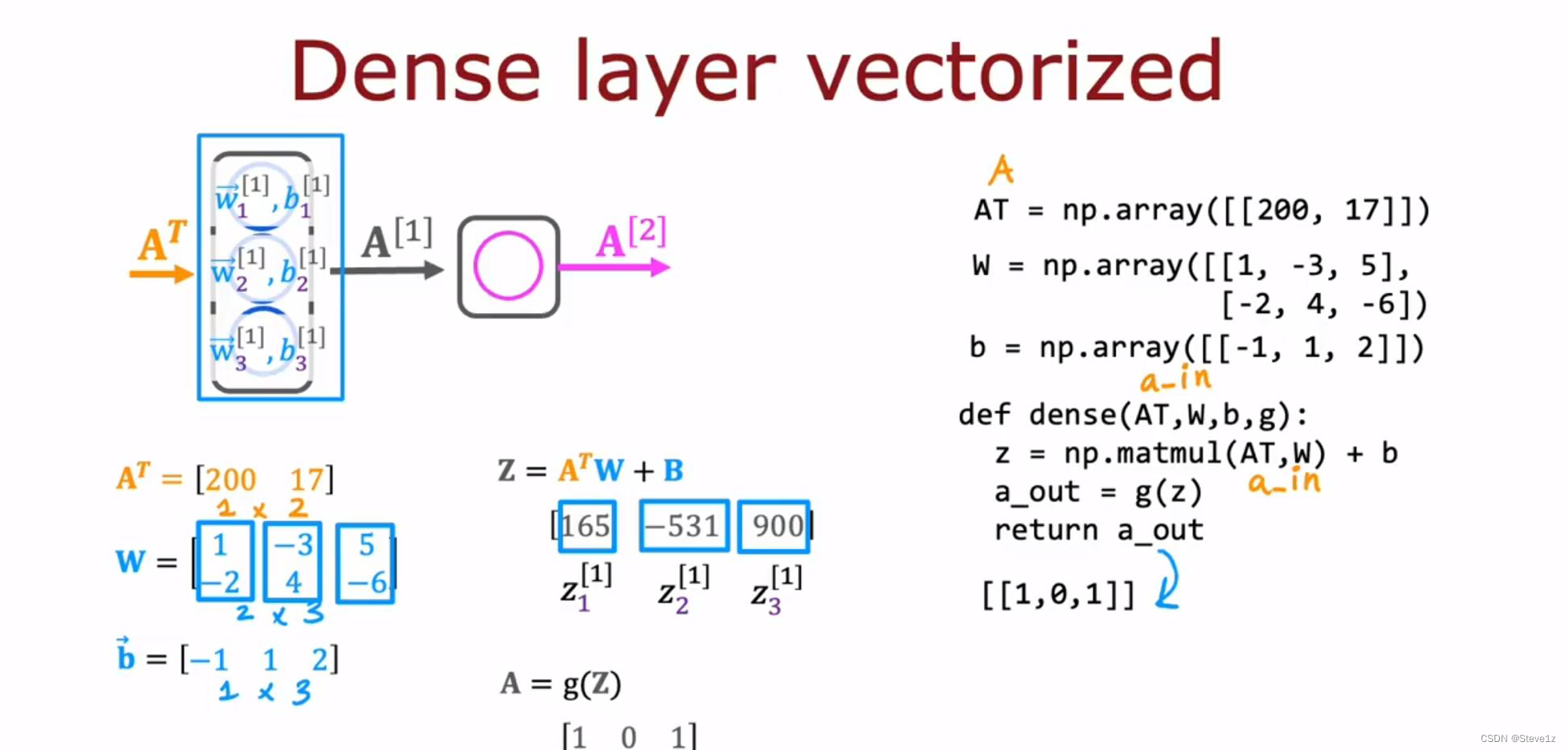
6.4 矩阵乘法代码

需要记忆的几个代码:
AT = A.T #将矩阵A的转置赋值给AT
C = np.matmul(A,AT) #矩阵乘法
C = A @ AT #矩阵乘法一个单层神经网络的矩阵计算过程
第七章 神经网络训练
7.1 TensorFlow实现
主要包括三步,首先指定一个模型,并告诉张流量如何进行计算,接着使用特定的损失函数对模型进行复合,最后是进行模型训练,具体如下图。
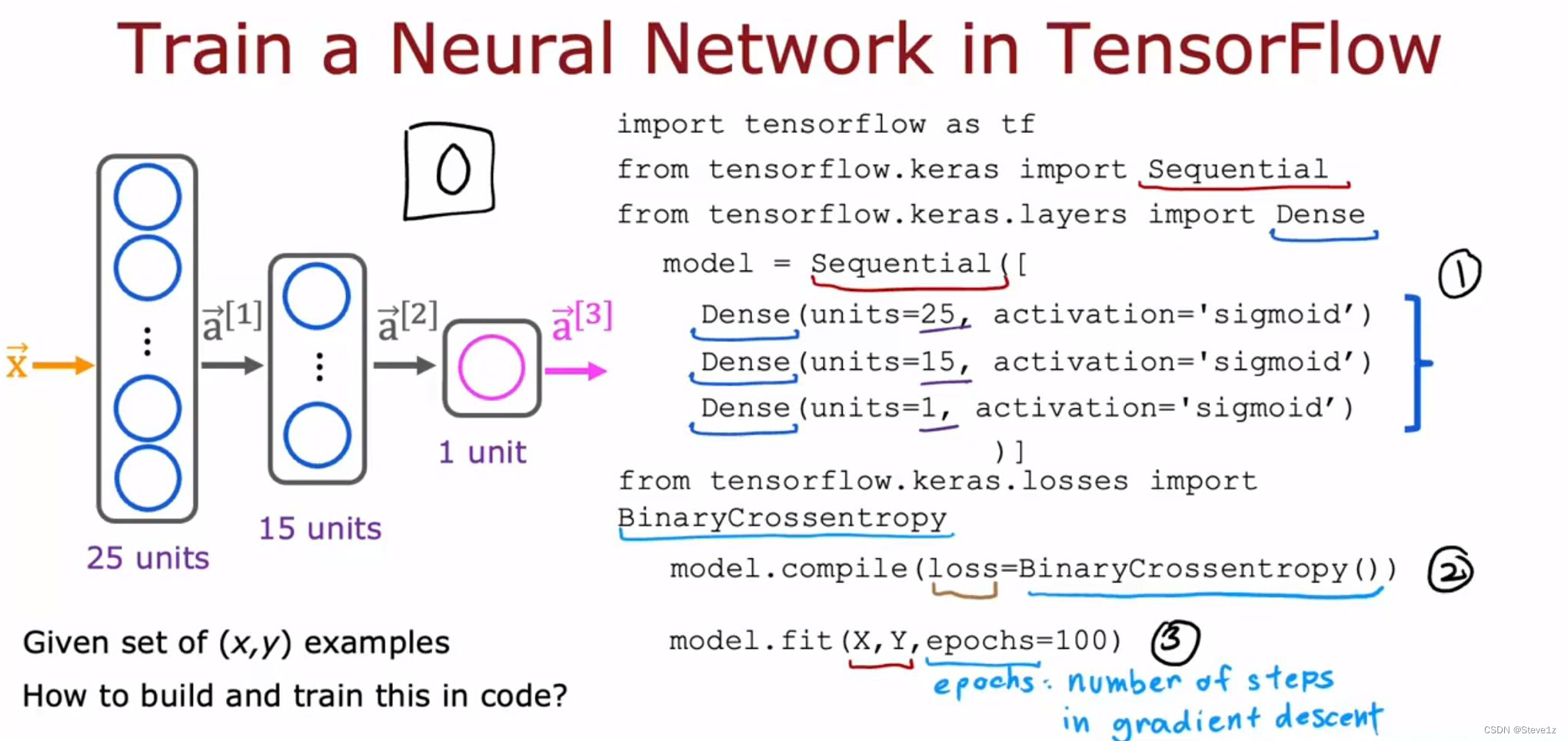
前面的代码和上一章的内容相似,接着便是使用TensorFlow编译模型,并使用BinaryCrossentropy损失函数(稀疏绝对交叉熵)。最后的epochs是指学习算法的步数。
7.2 训练细节
首先对比了逻辑回归和神经网络的训练模型的步骤和代码,具体如下:

主要分为三步:1、通过输入和参数求得输出,2、定义损失函数和代价函数,3、训练数据获得最小代价函数值(即不断更新参数)
具体如下图


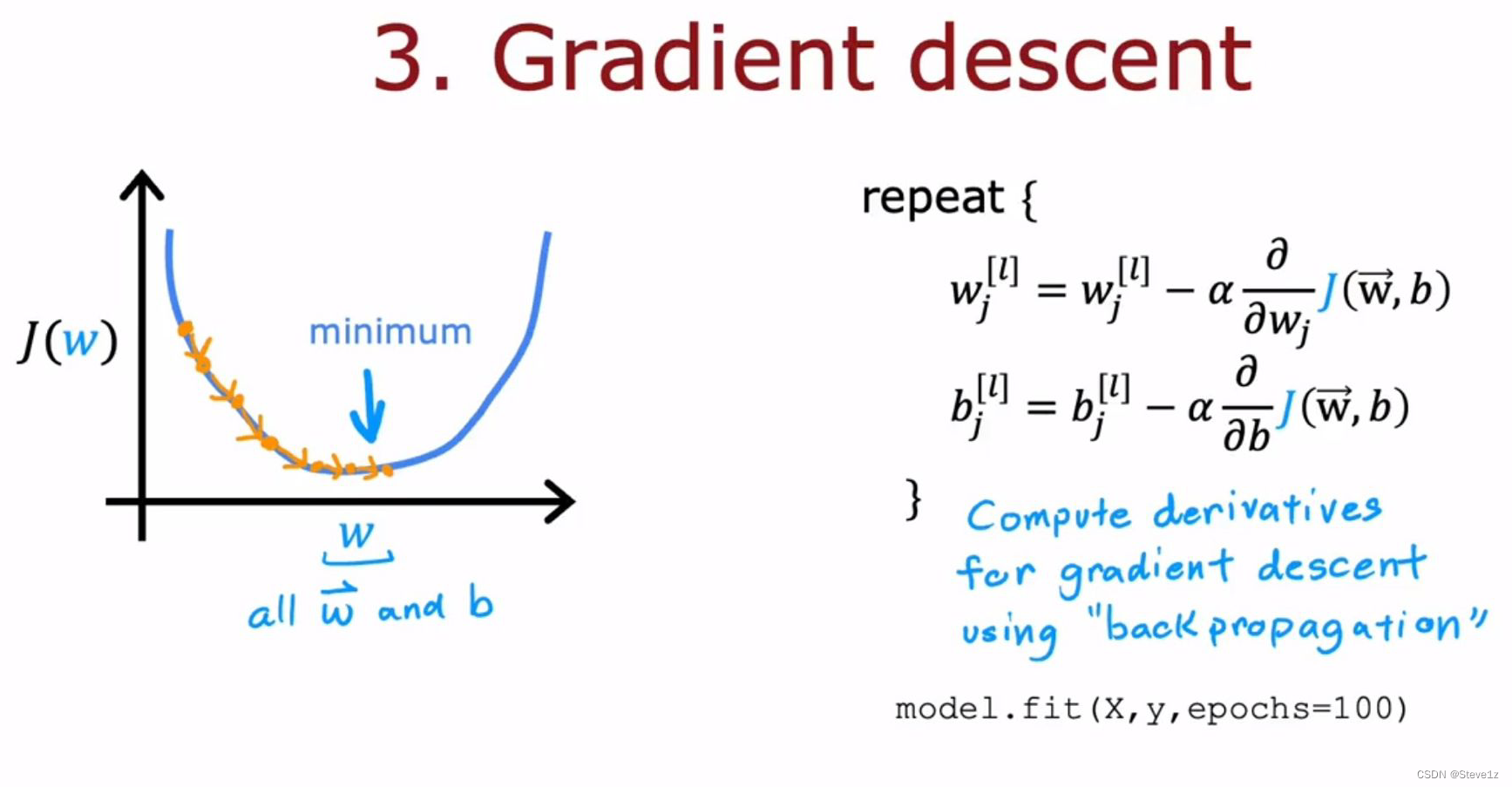
如今的深度学习库已经成熟,可以直接采用这些。
第八章 激活函数
8.1 sigmoid的替代品
目前在所有神经元中我们都采用了sigmoid函数,是因为都采用了逻辑回归模型,但是选择其他激活函数可以让神经网络变得更加强大。
事实证明,在神经网络中,有一个非常常见的激活函数ReLU:
常用的三种激活函数如下图:
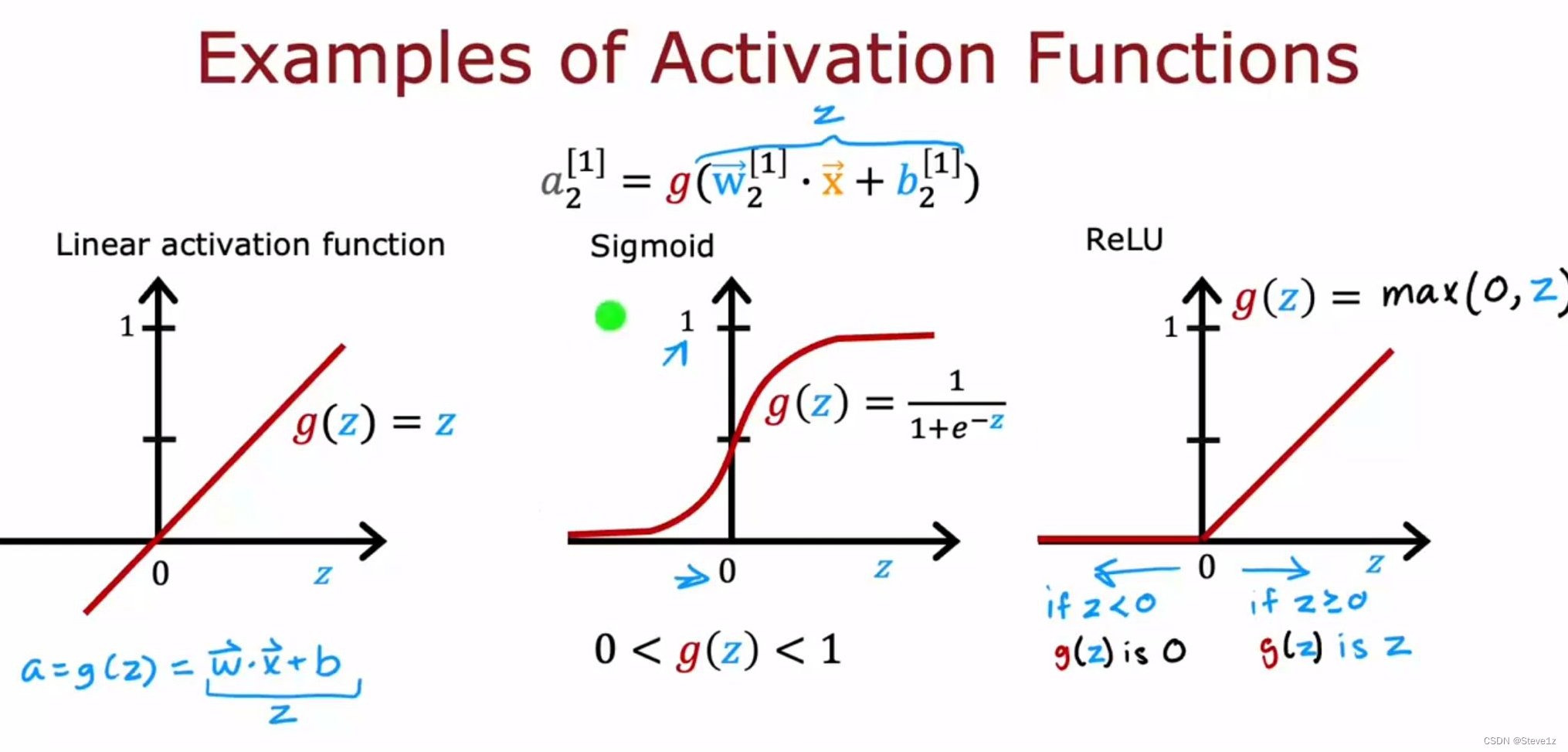
8.2 选择激活函数
可以对不同的神经元选择不同的激活功能,当考虑输出层的激活函数时,如何选择取决于目标,如果是分类问题,选择sigmoid函数较好;如果是回归问题且结果值有正有负,则选择线性激活函数较好;如果是回归问题且结果值全部大于0,则选择ReLU激活函数。
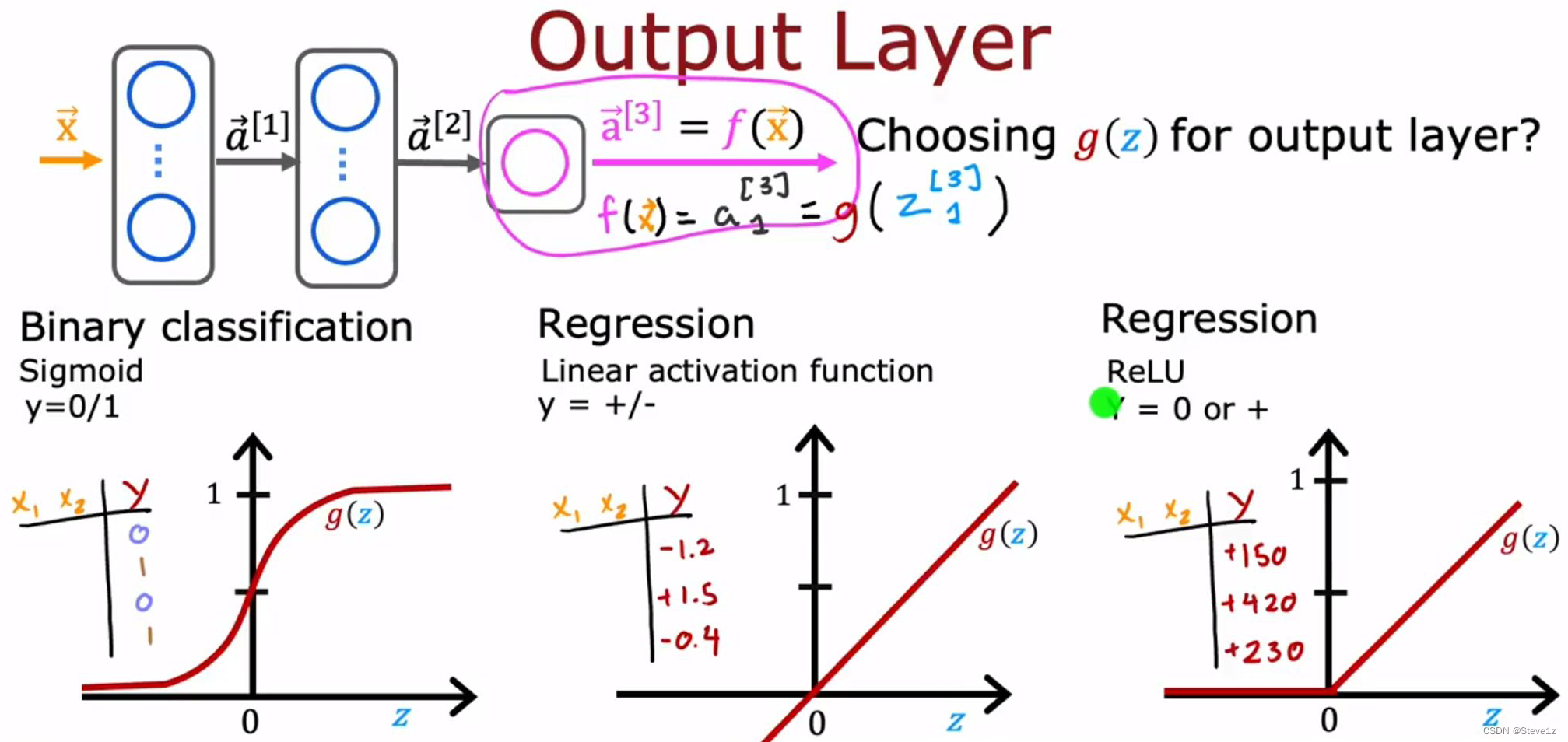
对于隐藏层,在sigmoid函数和ReLU函数二者中,现在更倾向于选择ReLU函数,因为其计算速度更快,且只有小于0的部分是平的。当你选择梯度下降算法时,在平整的部位下降会特别慢,

代码实现上述内容:
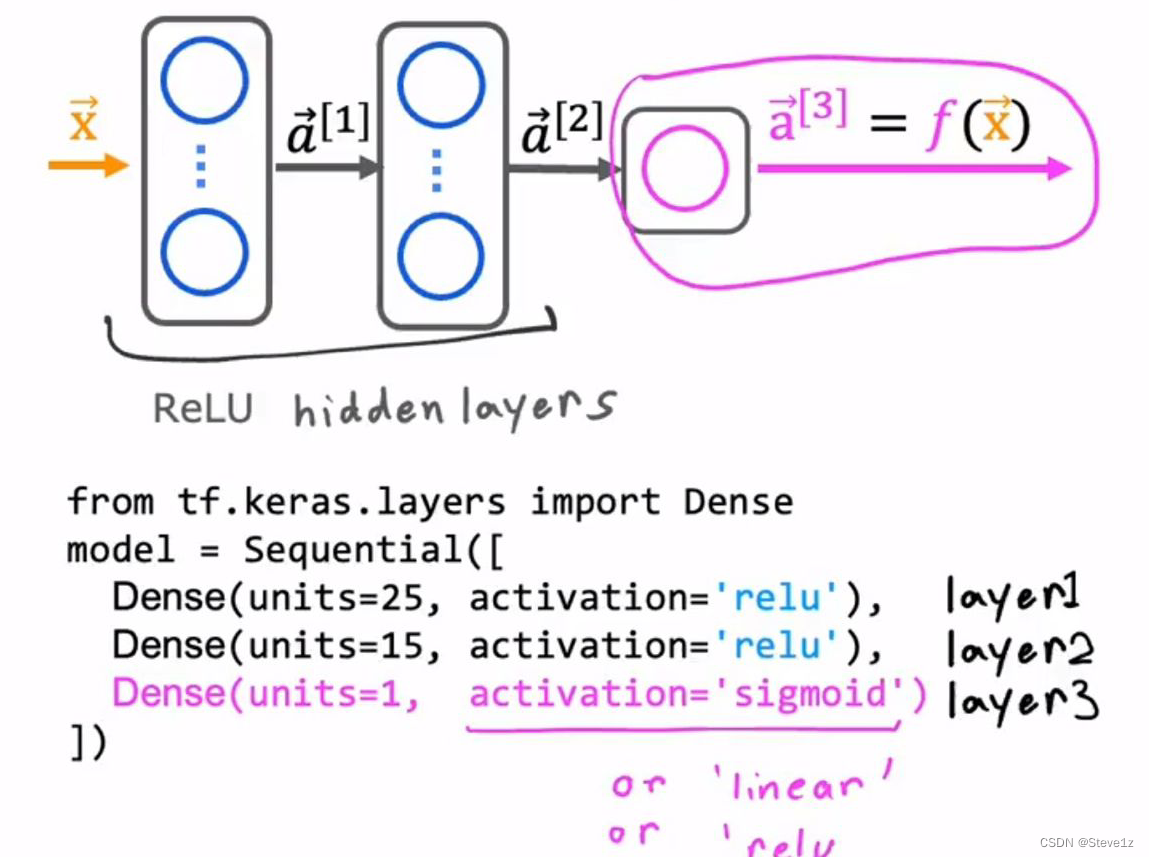
8.3 为什么需要激活函数
如果所有激活函数都是线性激活函数,则不能实现神经网络的功能,因为不论经过多少次线性函数最后的结果仍可以化为一个线性函数,因此不要在隐藏层中采用线性激活函数,采用ReLU函数可以获得较好的效果。
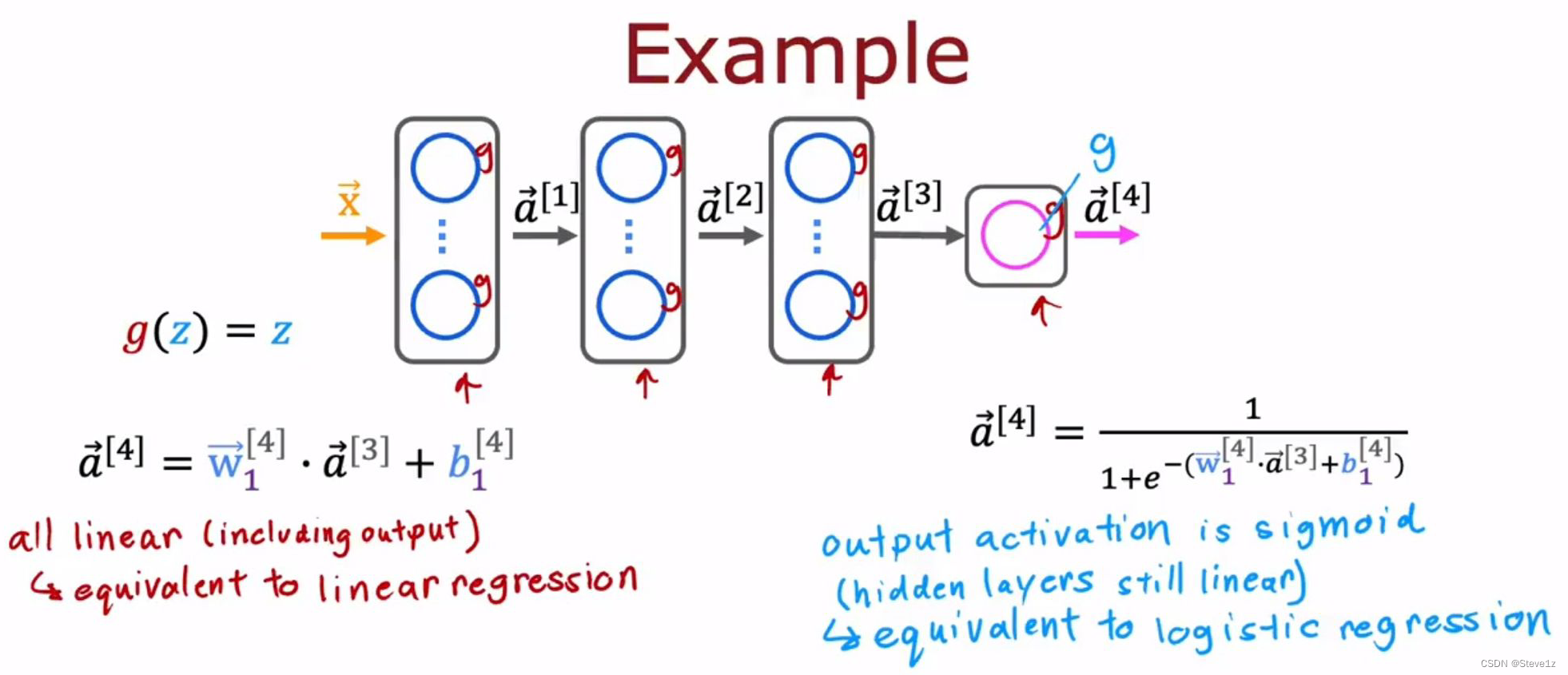
上图展示了隐藏层全部采用线性激活函数的情况,可以看出这个模型就等价于逻辑回归,没有实现神经网络的功能。















 785
785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









