








本文乃Siliphen原创。转载请注明出处:http://blog.csdn.net/stevenkylelee
本文分为5部分。从我思考和认知的角度,由浅到深带你认识Trie数据结构。
1.桶状哈希表与直接定址表的概念。
2.为什么直接定址表会比桶状哈希表快
3.初识Trie数据结构
4.Trie为什么会比桶状哈希表快
5.实际做实验感受下Trie , std::map , std::unordered_map的差距
6.最后的补充
1.桶状哈希表与直接定址表的概念。
先考虑一下这个问题:如何统计5万个0-99范围的数字出现的次数?
可以用哈希表来进行统计。如下:
// 生成5万个0-99范围的随机数
int * pNumbers = new int[ 50000 ] ;
for ( int i = 0 ; i < 50000 ; ++i )
{
pNumbers[ i ] = rand( ) % 100 ;
}
// 统计每个数字出现个次数
unordered_map< int , int > Counter ;
for ( int i = 0 ; i < 50000 ; ++i )
{
++Counter[ pNumbers[ i ] ] ;
}
如果有冲突,那么就会退化成线性查找。
对于这个问题,有一种更好的做法,就是“直接定址表”
“直接定址表”的概念第一次我是在王爽著的《汇编语言》看到
使用“直接定址表”需要满足一些条件,比如:值刚好就是key
上面那题用直接定址表来统计的话,实现是这样:
// 统计每个数字出现个次数
int Counter[ 100 ] = { 0 } ;
for ( int i = 0 ; i < 50000 ; ++i )
{
++Counter[ pNumbers[ i ] ] ;
}以上代码只是把哈希表容器换成了一个数组。数组的0-99的下标范围就是表示0-99个数字,
下标对应的元素值就是该下标表示的数字的出现次数。
2.为什么直接定址表会比桶状哈希表快
直接定址表也是哈希的一种,只是比较特殊。
直接定址表不需要计算哈希散列值,既然没有哈希散列值自然就不存在哈希冲突处理了。
这就是直接定址表比桶状哈希表快的原因
3.初识Trie数据结构
再考虑这样一个问题:如何统计5万个单词出现的次数?
哈,这个有点难度了吧?只能用哈希表来做了吧?
实现是不是像这样:
vector< string > words ;
// 生成5万个随机单词,略。。。
// 统计每个数字出现个次数
unordered_map< string , int > Counter ;
for ( int i = 0 ; i < 50000 ; ++i )
{
++Counter[ words[ i ] ] ;
}还有没有更快的统计方法呢?
首先我们来看下桶状哈希表慢在哪里,有2点
1.对每个字符串key都要执行一次哈希散列函数
2.如果哈希散列有冲突的话,就要做冲突处理
要提速,就要把这2点给干掉,不计算哈希散列,不做冲突处理。
咦!这不就是之前说的“直接定址表”么?
那用“直接定址表”怎样做字符串的统计?
如果,你自认为自己是一个天才的话,看到这里,就先别往下看。
先自己想想:怎样用直接定址表的思想来做字符串的统计、查找。
答案那就是Trie数据结构。Trie是啥?
简单地说,Trie就是直接定址表和树的结合的产物。
Trie其实是一种树结构,既然是树,那就会有树节点,
Trie树节点的特殊在于:一个节点的子节点就是一个直接定址表
Trie树节点的定义类似如下:
// Trie树节点
struct TrieNode
{
// 节点的值
int Val ;
// 子节点
Node* Children[ 256 ] ;
};要直观地用图形表示Trie树,大概是这样:
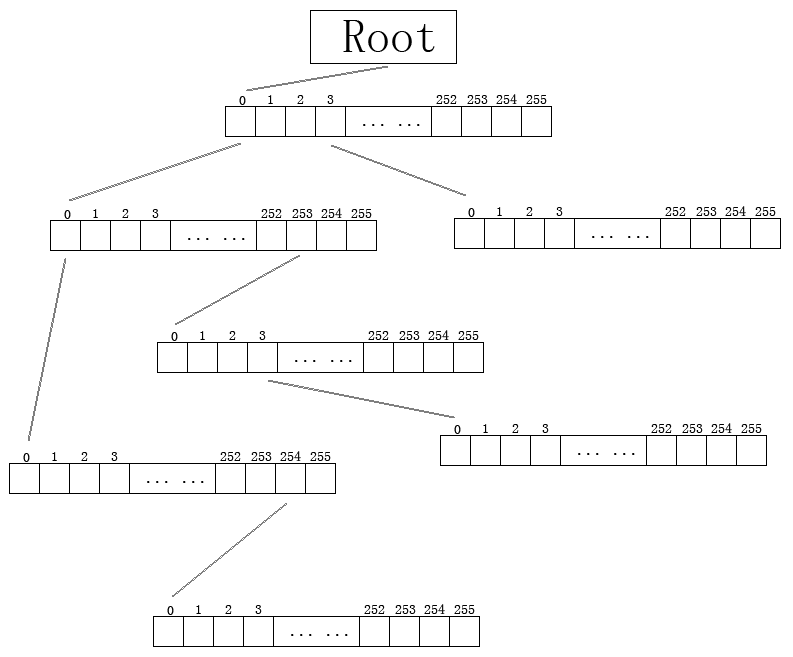
4.Trie为什么会比桶状哈希表快
从代码定义和图示可以看出,每个节点,对其子节点的定位,都是一个直接定址表。
要查找"Siliphen"这个字符串对应的值,过程是怎样的呢?
从根节点开始,用S的Ascii值直接定位找到S对应的子节点,
从S对应的节点,直接定位找到i对应的子节点
从i对应的节点,直接定位找到l对应的子节点
以此类推,直到最后的
从e对应的节点,直接定位找到n对应的子节点
n对应的子节点的数据字段就是"Siliphen"的字符串对应的值
从这个过程可以看到对于字符串的键值映射查找,Trie根本没有进行哈希散列和冲突处理。
This is the reason that Trie is faster than Hashtable!
这就是Trie比哈希表快的原因!
5.实际做实验感受下Trie , std::map , std::unordered_map的差距
理论上来说,Trie要比哈希表快。
到底快多少呢?咱们就做一个实验看看吧。有一个直观的感受。
首先,我们要写一个Trie。
我自己实现了一个TrieMap,
模仿C++的std标准库的map , unordered_map写的一个模板类
代码如下:
#pragma once
#include <string>
#include <queue>
#include <stack>
#include <list>
using namespace std ;
template< typename Value_t >
class TireMap
{
public:
TireMap( );
~TireMap( ) ;
private:
typedef pair< string , Value_t > Kv_t ;
struct Node
{
Kv_t * pKv ;
Node* Children[ 256 ] ;
Node( ) :
pKv( 0 )
{
memset( Children , 0 , sizeof( Children ) ) ;
}
~Node( )
{
if ( pKv != 0 )
{
//delete pKv ;
}
}
};
public :
/*
重载[ ] 运算符。和 map , unorder_map 容器接口一样。
*/
Value_t& operator[ ]( const string& strKey ) ;
// 清除保存的数据
void clear( ) ;
public :
const list< Kv_t >& GetKeyValueList( ) const { return m_Kvs ; }
protected:
// 删除一棵树
static void DeleteTree( Node *pNode ) ;
protected:
// 树根节点
Node * m_pRoot ;
// 映射的键值列表
list< Kv_t > m_Kvs ;
};
template< typename Value_t >
TireMap<Value_t>::TireMap( )
{
m_pRoot = new Node( ) ;
}
template< typename Value_t >
TireMap<Value_t>::~TireMap( )
{
clear( ) ;
delete m_pRoot ;
}
template< typename Value_t >
void TireMap<Value_t>::clear( )
{
for ( int i = 0 ; i < 256 ; ++i )
{
if ( m_pRoot->Children[ i ] != 0 )
{
DeleteTree( m_pRoot->Children[ i ] ) ;
m_pRoot->Children[ i ] = 0 ;
}
}
m_Kvs.clear( ) ;
}
template< typename Value_t >
void TireMap<Value_t>::DeleteTree( Node * pRoot )
{
// BFS 删除树
stack< Node* > stk ;
stk.push( pRoot ) ;
for ( ; stk.size( ) > 0 ; )
{
Node * p = stk.top( ) ; stk.pop( ) ;
// 扩展
for ( int i = 0 ; i < 256 ; ++i )
{
Node* p2 = p->Children[ i ] ;
if ( p2 == 0 )
{
continue;
}
stk.push( p2 ) ;
}
delete p ;
}
}
template< typename Value_t >
Value_t& TireMap<Value_t>::operator[]( const string& strKey )
{
Node * pNode = m_pRoot ;
// 建立或者查找树路径
for ( size_t i = 0 , size = strKey.size( ) ; i < size ; ++i )
{
const char& ch = strKey[ i ] ;
Node*& Child = pNode->Children[ ch ] ;
if ( Child == 0 )
{
pNode = Child = new Node( ) ;
}
else
{
pNode = Child ;
}
}
// end for
// 如果没有数据字段的话,就生成一个。
if ( pNode->pKv == 0 )
{
m_Kvs.push_back( Kv_t( strKey , Value_t() ) ) ;
pNode->pKv = &*( --m_Kvs.end( ) ) ;
}
return pNode->pKv->second ;
}
有没有std的感觉?哈哈
核心代码就是[]运算符重载的实现。
为什么要我搞一个list< Kv_t > m_Kvs字段?
这个字段主要是用来方便查看结果。
OK。下面我们来写测试代码
看看 Trie , 与 std::map , std::unordered_map之间的差别
测试代码如下:
#include <string>
#include <vector>
#include <unordered_map>
#include <map>
#include <time.h>
#include "TireMap.h"
using namespace std ;
// 随机生成 Count 个随机字符组合的“单词”
template< typename StringList_t >
int CreateStirngs( StringList_t& strings , int Count )
{
int nTimeStart , nElapsed ;
nTimeStart = clock( ) ;
strings.clear( ) ;
for ( int i = 0 ; i < Count ; ++i )
{
int stringLen = 5 ;
string str ;
for ( int i = 0 ; i < stringLen ; ++i )
{
char ch = 'a' + rand( ) % ( 'z' - 'a' + 1 ) ;
str.push_back( ch ) ;
if ( ch == 'z' )
{
int a = 1 ;
}
}
strings.push_back( str ) ;
}
nElapsed = clock( ) - nTimeStart ;
return nElapsed ;
}
// 创建 Count 个整型数据。同样创建这些整型对应的字符串
template< typename StringList_t , typename IntList_t >
int CreateNumbers( StringList_t& strings , IntList_t& Ints , int Count )
{
strings.clear( ) ;
Ints.clear( ) ;
for ( int i = 0 ; i < Count ; ++i )
{
int n =rand( ) % 0x00FFFFFF ;
char sz[ 256 ] = { 0 } ;
_itoa_s( n , sz , 10 ) ;
strings.push_back( sz ) ;
Ints.push_back( n ) ;
}
return 0 ;
}
// Tire 正确性检查
string Check( const unordered_map< string , int >& Right , const TireMap< int >& Tire )
{
string strInfo = "Tire 统计正确" ;
const auto& TireRet = Tire.GetKeyValueList( ) ;
unordered_map< string , int > ttt ;
for ( auto& kv : TireRet )
{
ttt[ kv.first ] = kv.second ;
}
if ( ttt.size( ) != Right.size( ) )
{
strInfo = "Tire统计有错" ;
}
else
{
for ( auto& kv : ttt )
{
auto it = Right.find( kv.first ) ;
if ( it == Right.end( ) )
{
strInfo = "Tire统计有错" ;
break ;
}
else if ( kv.second != it->second )
{
strInfo = "Tire统计有错" ;
break ;
}
}
}
return strInfo ;
}
// 统计模板函数。可以用map , unordered_map , TrieMap 做统计
template< typename StringList_t , typename Counter_t >
int Count( const StringList_t& strings , Counter_t& Counter )
{
int nTimeStart , nElapsed ;
nTimeStart = clock( ) ;
map< string , int > Counter1 ;
for ( const auto& str : strings )
{
++Counter[ str ] ;
}
nElapsed = clock( ) - nTimeStart ;
return nElapsed ;
}
int _tmain( int argc , _TCHAR* argv[ ] )
{
map< string , int > ElapsedInfo ;
int nTimeStart , nElapsed ;
// 生成50000个随机单词
list< string > strings ;
nElapsed = CreateStirngs( strings , 50000 ) ;
//ElapsedInfo[ "生成单词 耗时" ] = nElapsed ;
// 用 map 做统计
map< string , int > Counter1 ;
nElapsed = Count( strings , Counter1 ) ;
ElapsedInfo[ "统计单词 用map 耗时" ] = nElapsed ;
// 用 unordered_map 做统计
unordered_map< string , int > Counter2 ;
nElapsed = Count( strings , Counter2 ) ;
ElapsedInfo[ "统计单词 用unordered_map 耗时" ] = nElapsed ;
// 用 Tire 做统计
TireMap< int > Counter3 ;
nElapsed = Count( strings , Counter3 ) ;
ElapsedInfo[ "统计单词 用Tire 耗时" ] = nElapsed ;
// Tire 统计的结果。正确性检查
string CheckRet = Check( Counter2 , Counter3 ) ;
// 用哈希表统计5万个整形数字出现的次数
// 与 用Tire统计同样的5万个整形数字出现的次数的 对比
// 当然,用Tire统计的话,先要把那5万个整形数据,转换成对应的字符串的表示。
list< int > Ints ;
CreateNumbers( strings , Ints , 50000 ) ;
unordered_map< int , int > kivi ;
nTimeStart = clock( ) ;
for ( const auto& num : Ints )
{
++kivi[ num ] ;
}
nElapsed = clock( ) - nTimeStart ;
ElapsedInfo[ "统计数字 unordered_map 耗时" ] = nElapsed ;
//Counter3.clear( ) ; 这句话非常耗时。因为要遍历树逐个delete树节点。树有可能会非常大。所以我注释掉
nElapsed = Count( strings , Counter3 ) ;
ElapsedInfo[ "统计数字 用Tire 耗时" ] = nElapsed ;
return 0;
}实际运行的结果是:

对于统计5万个单词出现的次数
std::map耗时:3122毫秒
std::unordered_map耗时:2421毫秒
而我们写的Trie耗时:1332毫秒
可以看到,红黑树实现的std::map比桶状哈希表实现的std::unordered_map慢了差不多一秒
std::unordered_map又比Trie慢了差不多一秒。
这里有一个有趣的实验。
哈希表的Key类型用int,会不会快?
最后,我生成了5万个随机int整型整数,同时也把这5万个int转换成对应的string。
用key为int的哈希表和key为string的Trie做测试,看哪个快。
答案是:用key为string的Trie超过了key为int的哈希表
unordered_map耗时:1269毫秒
Trie耗时:750毫秒
6.最后的补充
Trie又称为字典树,是哈希树的一个变种。
Trie有一个特点是:有字符串公共前缀的信息
比如字符串"Siliphen"和字符串"Siliphen Lee"的公共前缀是"Siliphen"
在匹配字符串"Siliphen Lee"时,一定会先发现是否存在"Siliphen",
因为走的前缀树路径都是一样的。
是否还记得KMP算法。一种带有回溯的字符串匹配算法。
如果Trie+KMP的话,就变成另一个玩意:AC自动机。
AC自动机用于编译原理。
也可以用来做格斗游戏的摇招判定。就像拳皇KOF的那种摇招系统。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









