







BeautifSoup4
初始化方法
resp = requests.get('https://www.baidu.com/',headers=header)
resp.encoding='utf-8'
soup = BeautifulSoup(resp.text,'lxml')
print(soup.prettify())解析器
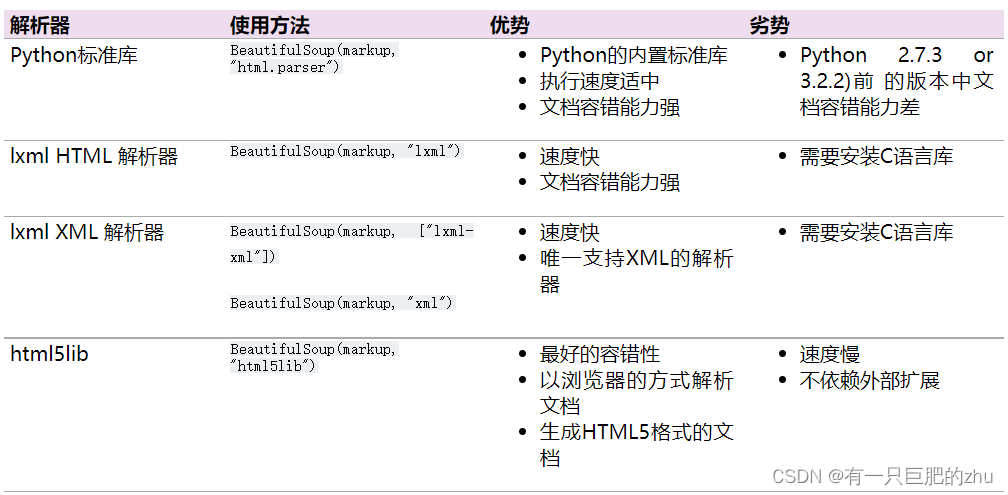
格式化html
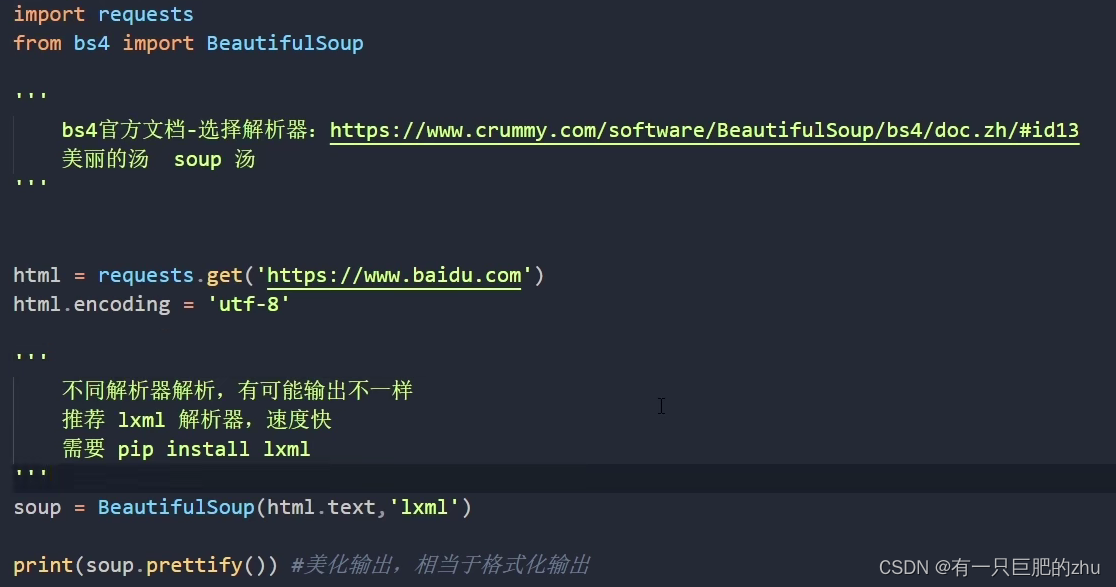
子节点
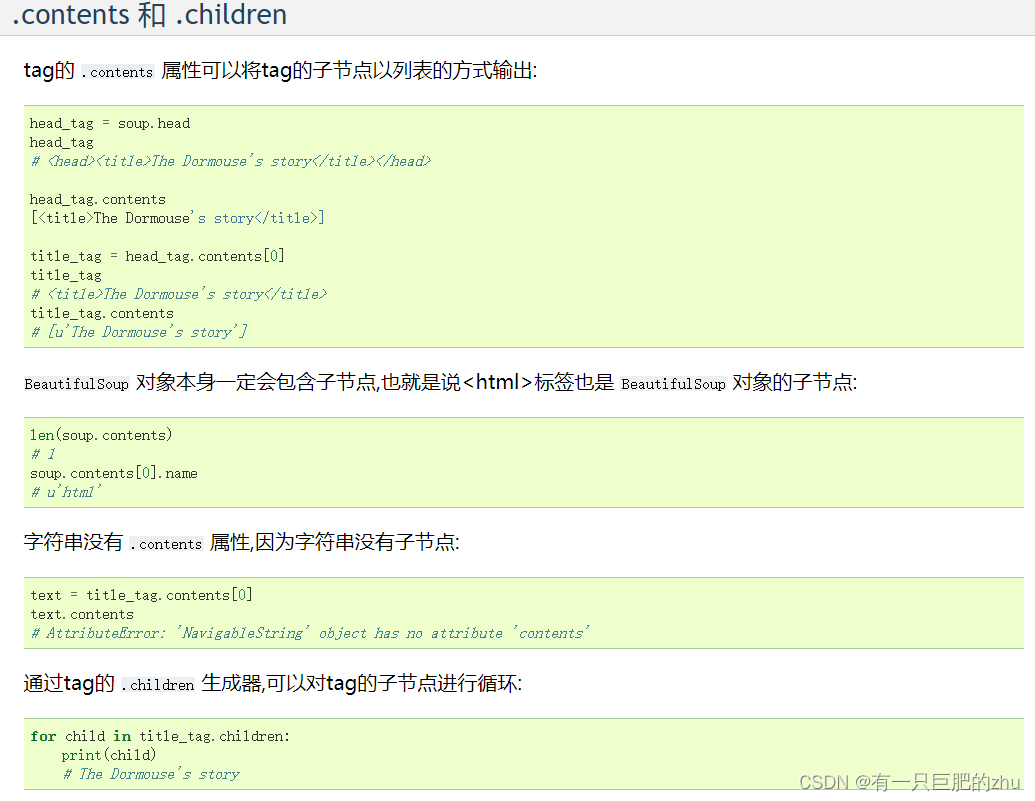
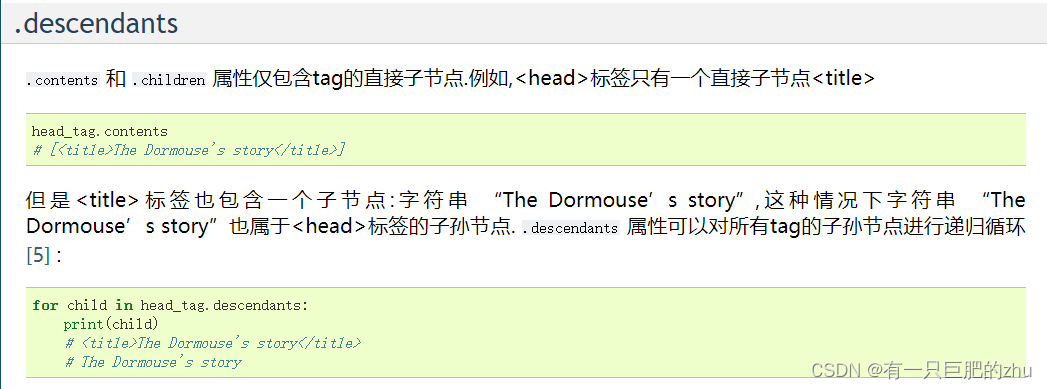
父节点
.parent 获取直接父节点
.parents 获取祖先结点
兄弟结点
.next_sibling获取下一个兄弟节点
.previous_sibling获取上一个兄弟节点
.previous_siblings获取上一个所有兄弟节点
以上方法获取多个结点时,换行会截断
定位
使用标签名定位标签
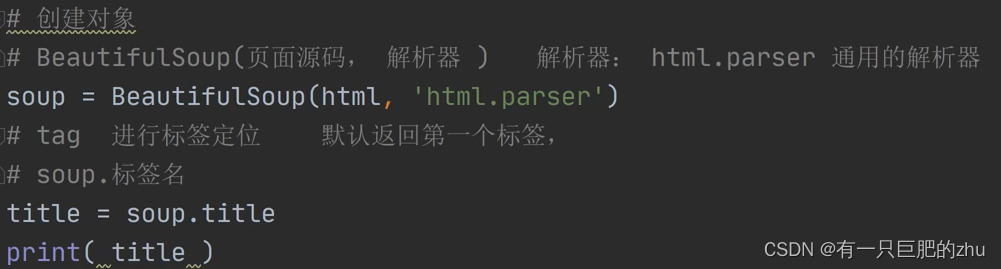
这种方法只能定位第一个该标签名对应的标签
PS:提取标签内的文本信息 使用标签对象.string或 标签对象.text
两者区别:如果string标签内还有其他的标签,使用string会提取出None,而使用text会将标签内中的全部标签的文本提取出来
获取标签内属性:全部属性 object.attrs 指定属性 object['属性名']或 object.get("属性名")
find方法
find( name , attrs , recursive , string , **kwargs )
find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个<body>标签,那么使用 find_all() 方法来查找<body>标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法.
findall方法
find_all( name , attrs , recursive , string , **kwargs )
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件.这里有几个例子:
soup.find_all("title")
# [<title>The Dormouse's story</title>]
soup.find_all("p", "title")
# [<p class="title"><b>The Dormouse's story</b></p>]
soup.find_all("a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find_all(id="link2")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
import re
soup.find(string=re.compile("sisters"))
# u'Once upon a time there were three little sisters; and their names were\n'有几个方法很相似,还有几个方法是新的,参数中的 string 和 id 是什么含义? 为什么 find_all("p", "title") 返回的是CSS Class为”title”的<p>标签? 我们来仔细看一下 find_all() 的参数
name 参数
name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉.
简单的用法如下:
soup.find_all("title")keyword 参数
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索,如果包含一个名字为 id 的参数,Beautiful Soup会搜索每个tag的”id”属性.
soup.find_all(id='link2')
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]如果传入 href 参数,Beautiful Soup会搜索每个tag的”href”属性:
soup.find_all(href=re.compile("elsie"))
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]搜索指定名字的属性时可以使用的参数值包括 字符串 , 正则表达式 , 列表, True .
下面的例子在文档树中查找所有包含 id 属性的tag,无论 id 的值是什么:
soup.find_all(id=True)
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]使用多个指定名字的参数可以同时过滤tag的多个属性:
soup.find_all(href=re.compile("elsie"), id='link1')
# [<a class="sister" href="http://example.com/elsie" id="link1">three</a>]
但是可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag:
data_soup.find_all(attrs={"data-foo": "value"})
# [<div data-foo="value">foo!</div>]PS:搜索class时要用class_
CSS选择器
选择所有出现的标签的列标
soup.select("title")
获取第一各结点:soup.select("title")[0]
选择第一个出现的指定标签
soup.select_one("title")
获取标签的属性,soup.select_one("title")['herf']
获取内容,soup.select_one("title").text,注意这样获取到的是子节点中全部的text,空格也算一个
通过CSS的类名查找:
soup.select(".sister")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select("[class~=sister]")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]PS:若类值中有空格则需要使用.来链式调用


通过tag的id查找:
符合标签a然后又有属性link2 =》 a#link2
符合标签a又有属性link2 =》a.link2
soup.select("#link1")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
soup.select("a#link2")
# [<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]同时用多种CSS选择器查询元素:
soup.select("#link1,#link2")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]通过是否存在某个属性来查找:
soup.select('a[href]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]通过属性的值来查找:
^匹配开始位置
$匹配结束位置
*匹配任意字符
soup.select('a[href="http://example.com/elsie"]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
soup.select('a[href^="http://example.com/"]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select('a[href$="tillie"]')
# [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select('a[href*=".com/el"]')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]逐层搜索用>声明,找前后结点(考虑结点关系)

逐层搜索用空格声明,找前后结点(不考虑结点关系)
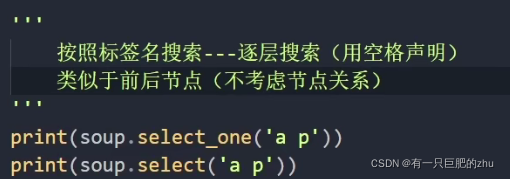
搜索兄弟结点用~声明,找前后结点(不考虑结点关系)

xpath
初始化
from lxml import etree
import requests
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
}
resp = requests.get('https://www.baidu.com/',headers=header)
resp.encoding='utf-8'
res_xpath = etree.HTML(resp.text)
知识点

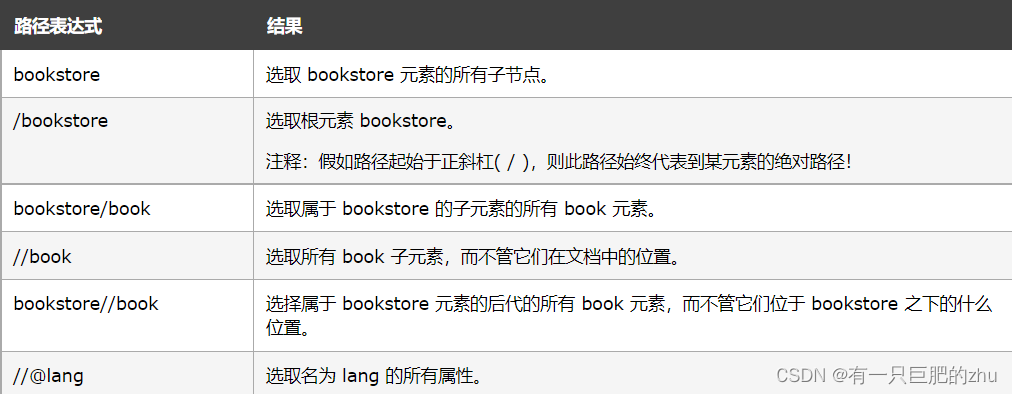
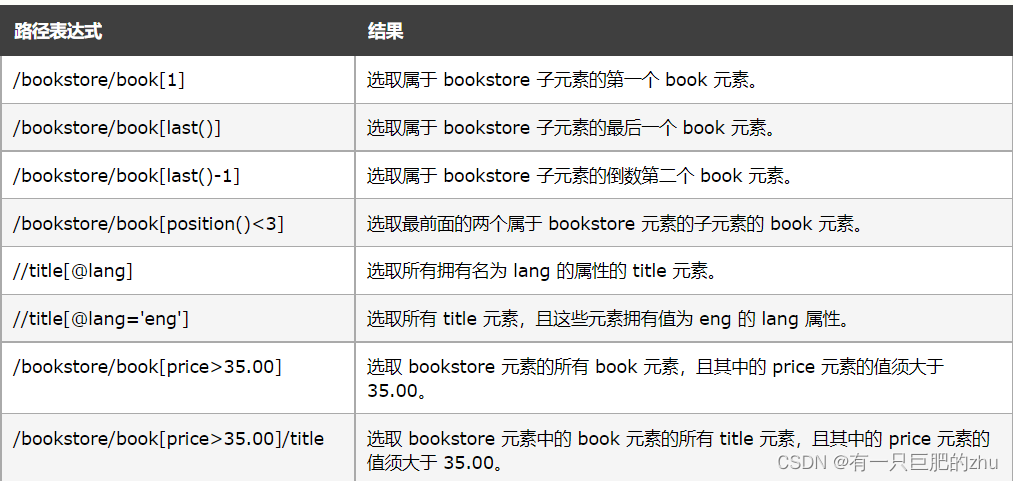

查找
res_xpath = etree.HTML(resp.text)
//绝对路径
title_object = res_xpath.xpath('/html/head/title')//获取全部title标签对象,类型为list
//任意路径
title_object = res_xpath.xpath('//title')//获取全部title标签对象,类型为list
print(title_object.xpath('text()'))//获取标签内文本信息按照属性
提取有herf属性的a标签
a[@herf]
提取class属性值为123的a标签
a[@class="123"]
可以加多个属性
a[@class="123" and @herf="hhhh"]
提取
提取文本 text()
title_object = res_xpath.xpath('//title')//获取全部title标签对象,类型为list
print(title_object.xpath('text()'))//获取标签内文本信息提取属性
title_object = res_xpath.xpath('//title')//获取全部title标签对象,类型为list
print(title_object.xpath('@href'))//获取标签内href属性从当前结点下查找
title_object = res_xpath.xpath('//title')//获取全部title标签对象,类型为list
hhh = title_object('//hhh/text()')获取兄弟结点
./following-sibling::兄弟标签名[1] 下面一个兄弟节点
./following-sibling::*[N] 下面N个性的节点
./preceding-sibling::兄弟标签名[1] 上面一个兄弟节点
./following-sibling::*[N] 上面N个性的节点

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









