








YOLOv11v10v8使用教程: YOLOv11入门到入土使用教程
YOLOv11改进汇总贴:YOLOv11及自研模型更新汇总
《Rethinking Transformer-Based Blind-Spot Network for Self-Supervised Image Denoising》
一、 模块介绍
论文链接:https://arxiv.org/pdf/2404.07846
代码链接:https://github.com/nagejacob/TBSN/tree/main
论文速览:
盲点网络 (BSN) 是自监督图像降噪 (SSID) 中普遍存在的神经架构。但是,大多数现有的 BSN 都是使用卷积层进行的。尽管 transformer 在许多图像恢复任务中显示出克服卷积限制的潜力,但注意力机制可能会违反盲点要求,从而限制它们在 BSN 中的适用性。为此,我们建议分析和重新设计通道和空间注意力,以满足盲点需求。具体来说,通道自注意力可能会泄露多尺度架构中的盲点信息,因为下采样将空间特征洗牌到通道维度。为了缓解这个问题,我们将频道分成几组,分别进行频道关注。对于空间自我注意,我们对注意力矩阵应用了一个精心设计的掩码,以限制和模拟扩张卷积的感受野。基于重新设计的通道和窗口注意力,我们构建了一个基于 Transformer 的盲点网络 (TBSN),表现出很强的局部拟合和全局视角能力。此外,我们引入了一种知识蒸馏策略,将 TBSN 蒸馏成更小的降噪器,以提高计算效率,同时保持性能。对真实世界图像去噪数据集的广泛实验表明,TBSN 在很大程度上扩展了感受野,并且与最先进的 SSID 方法相比表现出良好的性能。
总结:本文介绍TBSN中DilatedMDTA模块的使用方式。
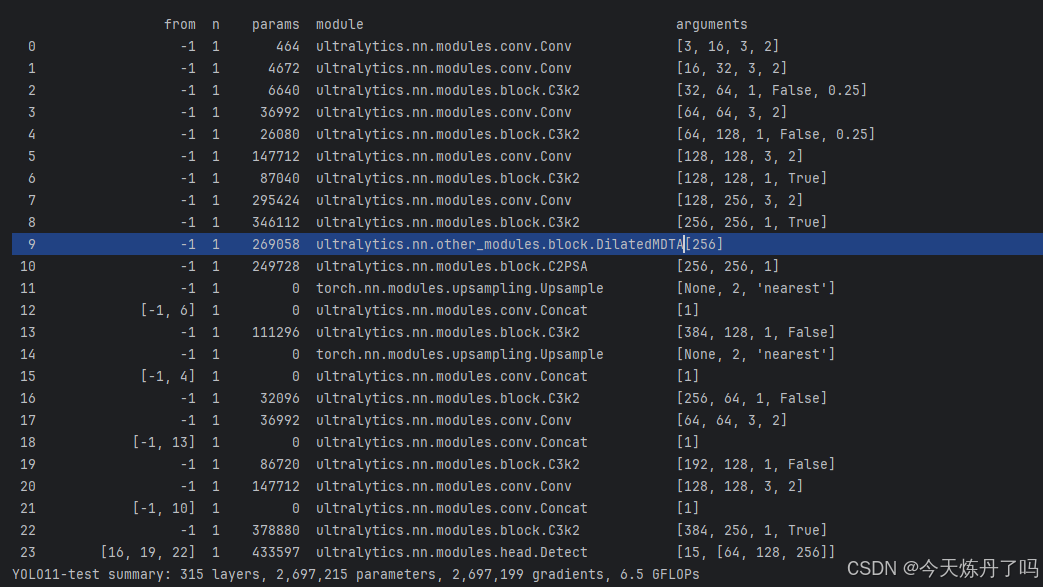
二、 加入到YOLO中
2.1 创建脚本文件
首先在ultralytics->nn路径下创建blocks.py脚本,用于存放模块代码。

2.2 复制代码
复制代码粘到刚刚创建的blocks.py脚本中,如下图所示:
class DilatedMDTA(nn.Module):
def __init__(self, dim, num_heads=2, bias=False):
super(DilatedMDTA, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, dilation=2, padding=2, groups=dim*3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x):
b,c,h,w = x.shape
qkv = self.qkv_dwconv(self.qkv(x))
q,k,v = qkv.chunk(3, dim=1)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
out = (attn @ v)
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out2.3 更改task.py文件
打开ultralytics->nn->modules->task.py,在脚本空白处导入函数。
from ultralytics.nn.blocks import *

之后找到模型解析函数parse_model(约在tasks.py脚本中940行左右位置,可能因代码版本不同变动),在该函数的最后一个else分支上面增加相关解析代码。
elif m in { DilatedMDTA}:
c2 = ch[f]
args = [ch[f], *args]2.4 更改yaml文件
打开更改ultralytics/cfg/models/11路径下的YOLOv11.yaml文件,替换原有模块。(放在该位置仅能插入该模块,具体效果未知。博主精力有限,仅完成本文的测试,结构图见文末,代码见群文件更新。)

# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, DilatedMDTA, []] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.5 修改train.py文件
创建Train脚本用于训练。
from ultralytics.models import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
if __name__ == '__main__':
model = YOLO(model='ultralytics/cfg/models/11/yolo11.yaml')
# model.load('yolov8n.pt')
model.train(data='./data.yaml', epochs=2, batch=1, device='0', imgsz=640, workers=2, cache=False,
amp=True, mosaic=False, project='runs/train', name='exp')

在train.py脚本中填入修改好的yaml路径,运行即可训练,数据集创建教程见下方链接。
三、相关改进思路(2025/2/15日群文件)
该模块可替换C2f、C3模块中的BottleNeck部分,代码见群文件,结构如图。自研模块与该模块融合代码及yaml文件见群文件。

⭐另外,融合上百种深度学习改进模块的YOLO项目仅119(含百种改进的v9),RTDETR119,含高性能自研模型,更易发论文,代码每周更新,欢迎点击下方小卡片加我了解。⭐
⭐⭐平均每个文章对应4-6个二创及自研融合模块⭐⭐



















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









