







目录
灾难推文的自然语言处理——预测哪些推文是关于真实灾难的,哪些不是。
灾难推文的自然语言处理——预测哪些推文是关于真实灾难的,哪些不是。
一、比赛概述
Twitter已成为紧急情况下的重要沟通渠道。智能手机的普及使人们能够实时宣布他们正在观察到的紧急情况。正因为如此,更多机构对以编程方式监控 Twitter 感兴趣(即救灾组织和新闻机构)。但是,人们并不总是清楚一个人的话是否真的预示着一场灾难。举个例子:

作者明确使用了“ABLAZE”这个词,但它是隐喻的。这对于人类来说是显而易见的,尤其是在视觉辅助下。但对于机器来说就不太清楚了。
在本次比赛中,你面临的挑战是构建一个机器学习模型,该模型可以预测哪些推文是关于真实灾难的,哪些不是。你将可以访问包含 10,000 条手动分类的推文的数据集。
二、数据集
数据:train.csv、test.csv
格式:训练和测试集中的每个样本都具有以下信息:
- 一条
text推文的 - 来自该推文的A
keyword(尽管这可能是空白的!) - 推文的发送者
location(也可能为空)
结果:预测给定的推文是否与真正的灾难有关。如果是这样,则预测1。如果不是,则预测0。
列:
id- 每条推文的唯一标识符text- 推文的文本location- 推文发送的位置(可能为空)keyword- 推文中的特定关键字(可能为空)target- 仅在train.csv中,这表示推文是否与真正的灾难有关 (1) 或不是 (0)
三、代码
0.导入库与数据
!wget --quiet https://raw.githubusercontent.com/tensorflow/models/master/official/nlp/bert/tokenization.py
#下载库 此模型使用 GitHub 上 TensorFlow Models 存储库中的 BERT 实现import gc
#垃圾回收模块 garbage collector
import re
#正则表达式模块 Regular Expression
import string
import operator
from collections import defaultdict
#集合模块
import numpy as np
import pandas as pd
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
#显示最大行数、列数、设置列宽
import matplotlib.pyplot as plt
import seaborn as sns
#导入画图相关模块
import tokenization
from wordcloud import STOPWORDS
#词云-停用词
from sklearn.model_selection import StratifiedKFold, StratifiedShuffleSplit
from sklearn.metrics import precision_score, recall_score, f1_score
#导入机器学习工具包
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow import keras
from tensorflow.keras.optimizers import SGD, Adam
from tensorflow.keras.layers import Dense, Input, Dropout, GlobalAveragePooling1D
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, Callback
#导入TF相关模块
SEED = 1337
#设置随机种子方便复现df_train = pd.read_csv('../input/nlp-getting-started/train.csv', dtype={'id': np.int16, 'target': np.int8})
df_test = pd.read_csv('../input/nlp-getting-started/test.csv', dtype={'id': np.int16})
#导入Kaggle数据集
print('Training Set Shape = {}'.format(df_train.shape))
print('Training Set Memory Usage = {:.2f} MB'.format(df_train.memory_usage().sum() / 1024**2))
print('Test Set Shape = {}'.format(df_test.shape))
print('Test Set Memory Usage = {:.2f} MB'.format(df_test.memory_usage().sum() / 1024**2))
#输出数据集相关信息Training Set Shape = (7613, 5) Training Set Memory Usage = 0.20 MB Test Set Shape = (3263, 4) Test Set Memory Usage = 0.08 MB
1. 关键字和位置
1.1 缺失值
训练集和测试集的 keyword和 location 具有相同的缺失值比率。
- 训练集和测试集中均缺少0.8%的
keyword - 33% 的
location在训练集和测试集中均缺失
由于训练集和测试集之间的缺失值比率太接近,因此它们很可能取自同一样本。这些要素中的缺失值分别用 no_keyword和 no_location填充。
missing_cols = ['keyword', 'location']
fig, axes = plt.subplots(ncols=2, figsize=(17, 4), dpi=100)
sns.barplot(x=df_train[missing_cols].isnull().sum().index, y=df_train[missing_cols].isnull().sum().values, ax=axes[0])
sns.barplot(x=df_test[missing_cols].isnull().sum().index, y=df_test[missing_cols].isnull().sum().values, ax=axes[1])
#设置图表信息
axes[0].set_ylabel('Missing Value Count', size=15, labelpad=20)
axes[0].tick_params(axis='x', labelsize=15)
axes[0].tick_params(axis='y', labelsize=15)
axes[1].tick_params(axis='x', labelsize=15)
axes[1].tick_params(axis='y', labelsize=15)
axes[0].set_title('Training Set', fontsize=13)
axes[1].set_title('Test Set', fontsize=13)
plt.show()
遍历将缺失信息用no_XXX代替
for df in [df_train, df_test]:
for col in ['keyword', 'location']:
df[col] = df[col].fillna(f'no_{col}')
1.2 元素和目标分布
位置不是自动生成的,它们是用户输入的。这就是 location为什么非常肮脏,因为有太多的独特值,这种情况不应该当做特征。
但是,很幸运,keyword中有信号,因为其中一些词只能在一个上下文中使用。关键字具有非常不同的推文计数和目标平均值。 keyword可以单独用作特征,也可以用作添加到文本中的单词。训练集中的每个关键字都存在于测试集中。如果训练集和测试集来自同一样本,则还可以对 keyword使用目标编码。
print(f'Number of unique values in keyword = {df_train["keyword"].nunique()} (Training) - {df_test["keyword"].nunique()} (Test)')
print(f'Number of unique values in location = {df_train["location"].nunique()} (Training) - {df_test["location"].nunique()} (Test)')Number of unique values in keyword = 222 (Training) - 222 (Test) Number of unique values in location = 3342 (Training) - 1603 (Test)
df_train['target_mean'] = df_train.groupby('keyword')['target'].transform('mean')
fig = plt.figure(figsize=(8, 72), dpi=100)
sns.countplot(y=df_train.sort_values(by='target_mean', ascending=False)['keyword'],
hue=df_train.sort_values(by='target_mean', ascending=False)['target'])
plt.tick_params(axis='x', labelsize=15)
plt.tick_params(axis='y', labelsize=12)
plt.legend(loc=1)
plt.title('Target Distribution in Keywords')
plt.show()
df_train.drop(columns=['target_mean'], inplace=True)展示目标在关键词中分布(也就是这个关键词对应是否发生灾难的情况)

2. 元特征
类和数据集中元特征的分布有助于识别灾难推文。与非灾难推文相比,灾难推文会用更正式的方式编写,文字更长,因为它们中的大多数来自新闻机构。非灾难推文比灾难推文有更多的拼写错误,因为它们来自个人用户。用于分析的元特征是;
word_count文本中的字数unique_word_count文本中唯一单词的数量stop_word_count文本中的停用词数url_count文本中的网址数mean_word_length平均字符数(字数)char_count文本中的字符数punctuation_count文本中的标点符号数hashtag_count文本中的主题标签 (#) 数mention_count文本中的提及次数 (@)
# word_count
df_train['word_count'] = df_train['text'].apply(lambda x: len(str(x).split()))
df_test['word_count'] = df_test['text'].apply(lambda x: len(str(x).split()))
# unique_word_count
df_train['unique_word_count'] = df_train['text'].apply(lambda x: len(set(str(x).split())))
df_test['unique_word_count'] = df_test['text'].apply(lambda x: len(set(str(x).split())))
# stop_word_count
df_train['stop_word_count'] = df_train['text'].apply(lambda x: len([w for w in str(x).lower().split() if w in STOPWORDS]))
df_test['stop_word_count'] = df_test['text'].apply(lambda x: len([w for w in str(x).lower().split() if w in STOPWORDS]))
# url_count
df_train['url_count'] = df_train['text'].apply(lambda x: len([w for w in str(x).lower().split() if 'http' in w or 'https' in w]))
df_test['url_count'] = df_test['text'].apply(lambda x: len([w for w in str(x).lower().split() if 'http' in w or 'https' in w]))
# mean_word_length
df_train['mean_word_length'] = df_train['text'].apply(lambda x: np.mean([len(w) for w in str(x).split()]))
df_test['mean_word_length'] = df_test['text'].apply(lambda x: np.mean([len(w) for w in str(x).split()]))
# char_count
df_train['char_count'] = df_train['text'].apply(lambda x: len(str(x)))
df_test['char_count'] = df_test['text'].apply(lambda x: len(str(x)))
# punctuation_count
df_train['punctuation_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c in string.punctuation]))
df_test['punctuation_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c in string.punctuation]))
# hashtag_count
df_train['hashtag_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c == '#']))
df_test['hashtag_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c == '#']))
# mention_count
df_train['mention_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c == '@']))
df_test['mention_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c == '@']))所有元特征在训练集和测试集中的分布都非常相似,这也证明了训练集和测试集取自同一样本。
所有元特征也有关于目标的信息,但其中一些还不够好,例如 url_count、hashtag_count和mention_count 。
另一方面,word_count、unique_word_count、stop_word_count、mean_word_length、char_count、 punctuation_count对灾难和非灾难推文的分布非常不同。这些功能在模型中可能很有用。
#分析展示各个元特征和灾难相关的分布
METAFEATURES = ['word_count', 'unique_word_count', 'stop_word_count', 'url_count', 'mean_word_length',
'char_count', 'punctuation_count', 'hashtag_count', 'mention_count']
DISASTER_TWEETS = df_train['target'] == 1
fig, axes = plt.subplots(ncols=2, nrows=len(METAFEATURES), figsize=(20, 50), dpi=100)
for i, feature in enumerate(METAFEATURES):
sns.distplot(df_train.loc[~DISASTER_TWEETS][feature], label='Not Disaster', ax=axes[i][0], color='green')
sns.distplot(df_train.loc[DISASTER_TWEETS][feature], label='Disaster', ax=axes[i][0], color='red')
sns.distplot(df_train[feature], label='Training', ax=axes[i][1])
sns.distplot(df_test[feature], label='Test', ax=axes[i][1])
for j in range(2):
axes[i][j].set_xlabel('')
axes[i][j].tick_params(axis='x', labelsize=12)
axes[i][j].tick_params(axis='y', labelsize=12)
axes[i][j].legend()
axes[i][0].set_title(f'{feature} Target Distribution in Training Set', fontsize=13)
axes[i][1].set_title(f'{feature} Training & Test Set Distribution', fontsize=13)
plt.show()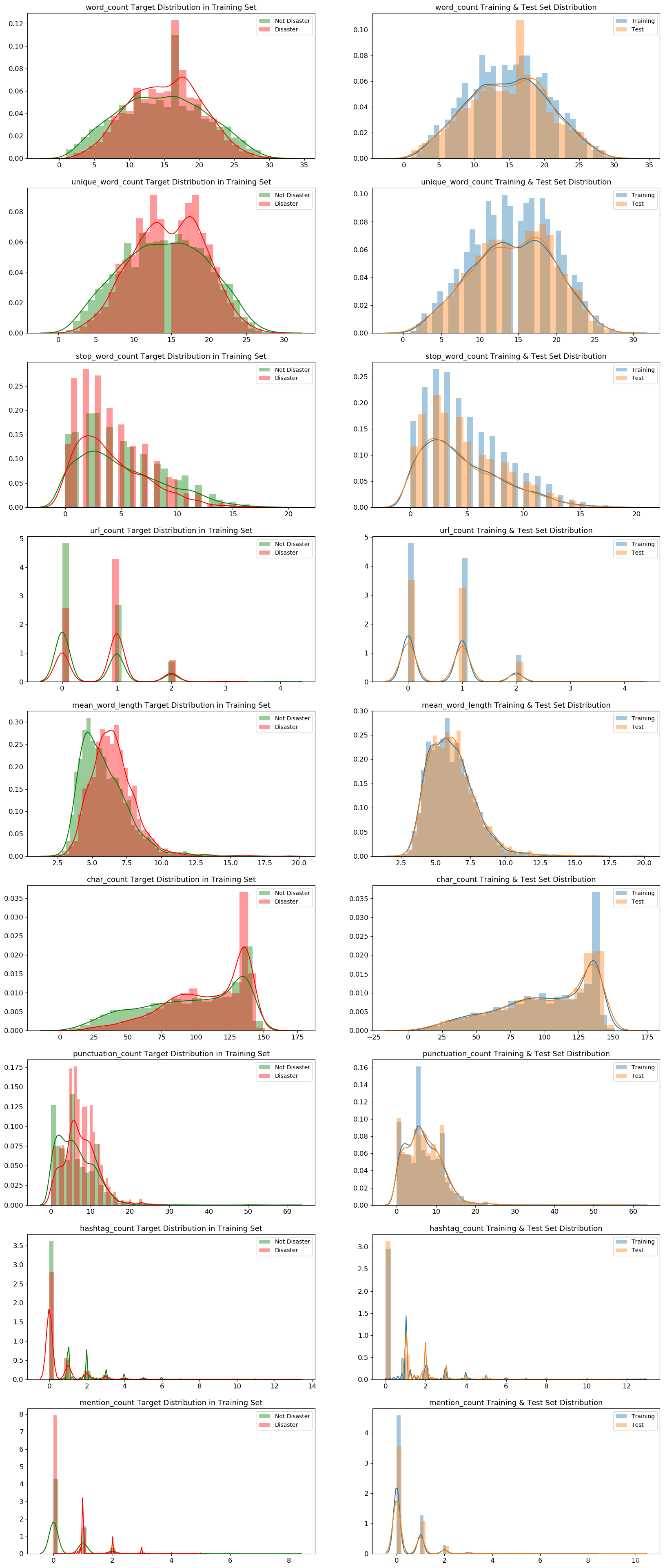
3. 目标和N-grams
3.1 目标
57%的分布为 0(非灾难),43%的分布为 1(灾难)。target每类几乎相等,因此它们不需要在交叉验证中进行任何分层。
#展示灾难和非在灾难的数量分布
fig, axes = plt.subplots(ncols=2, figsize=(17, 4), dpi=100)
plt.tight_layout()
df_train.groupby('target').count()['id'].plot(kind='pie', ax=axes[0], labels=['Not Disaster (57%)', 'Disaster (43%)'])
sns.countplot(x=df_train['target'], hue=df_train['target'], ax=axes[1])
axes[0].set_ylabel('')
axes[1].set_ylabel('')
axes[1].set_xticklabels(['Not Disaster (4342)', 'Disaster (3271)'])
axes[0].tick_params(axis='x', labelsize=15)
axes[0].tick_params(axis='y', labelsize=15)
axes[1].tick_params(axis='x', labelsize=15)
axes[1].tick_params(axis='y', labelsize=15)
axes[0].set_title('Target Distribution in Training Set', fontsize=13)
axes[1].set_title('Target Count in Training Set', fontsize=13)
plt.show()
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
n-gram模型用于评估语句是否合理
def generate_ngrams(text, n_gram=1):
token = [token for token in text.lower().split(' ') if token != '' if token not in STOPWORDS]
ngrams = zip(*[token[i:] for i in range(n_gram)])
return [' '.join(ngram) for ngram in ngrams]
N = 100
# Unigrams
#unigram 一元分词,把句子分成一个一个的字
disaster_unigrams = defaultdict(int)
nondisaster_unigrams = defaultdict(int)
for tweet in df_train[DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet):
disaster_unigrams[word] += 1
for tweet in df_train[~DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet):
nondisaster_unigrams[word] += 1
df_disaster_unigrams = pd.DataFrame(sorted(disaster_unigrams.items(), key=lambda x: x[1])[::-1])
df_nondisaster_unigrams = pd.DataFrame(sorted(nondisaster_unigrams.items(), key=lambda x: x[1])[::-1])
# Bigrams
#bigram 二元分词,把句子从头到尾每两个字组成一个词语
disaster_bigrams = defaultdict(int)
nondisaster_bigrams = defaultdict(int)
for tweet in df_train[DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet, n_gram=2):
disaster_bigrams[word] += 1
for tweet in df_train[~DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet, n_gram=2):
nondisaster_bigrams[word] += 1
df_disaster_bigrams = pd.DataFrame(sorted(disaster_bigrams.items(), key=lambda x: x[1])[::-1])
df_nondisaster_bigrams = pd.DataFrame(sorted(nondisaster_bigrams.items(), key=lambda x: x[1])[::-1])
# Trigrams
#trigram 三元分词,把句子从头到尾每三个字组成一个词语
disaster_trigrams = defaultdict(int)
nondisaster_trigrams = defaultdict(int)
for tweet in df_train[DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet, n_gram=3):
disaster_trigrams[word] += 1
for tweet in df_train[~DISASTER_TWEETS]['text']:
for word in generate_ngrams(tweet, n_gram=3):
nondisaster_trigrams[word] += 1
df_disaster_trigrams = pd.DataFrame(sorted(disaster_trigrams.items(), key=lambda x: x[1])[::-1])
df_nondisaster_trigrams = pd.DataFrame(sorted(nondisaster_trigrams.items(), key=lambda x: x[1])[::-1])3.2 unigrams 一元语法
这两类中最常见的字母组合大多是标点符号、停用词或数字。最好在建模之前清理它们,因为它们没有提供太多关于target。
灾难推文中最常见的字母图已经提供了有关灾难的信息。在其他上下文中很难使用其中一些词。
非灾难推文中最常见的单词是动词。这是有道理的,因为这些句子中的大多数都有非正式的活动结构,因为它们来自个人用户。
fig, axes = plt.subplots(ncols=2, figsize=(18, 50), dpi=100)
plt.tight_layout()
sns.barplot(y=df_disaster_unigrams[0].values[:N], x=df_disaster_unigrams[1].values[:N], ax=axes[0], color='red')
sns.barplot(y=df_nondisaster_unigrams[0].values[:N], x=df_nondisaster_unigrams[1].values[:N], ax=axes[1], color='green')
for i in range(2):
axes[i].spines['right'].set_visible(False)
axes[i].set_xlabel('')
axes[i].set_ylabel('')
axes[i].tick_params(axis='x', labelsize=13)
axes[i].tick_params(axis='y', labelsize=13)
axes[0].set_title(f'Top {N} most common unigrams in Disaster Tweets', fontsize=15)
axes[1].set_title(f'Top {N} most common unigrams in Non-disaster Tweets', fontsize=15)
plt.show()
3.3 bigrams 二元语法
这两个类中不存在共同的双元词,因为上下文更清晰。
灾难推文中最常见的双字母比单字母提供了更多关于灾难的信息,但标点符号必须从单词中去除。
非灾难推文中最常见的双字母图大多是关于reddit或youtube的,它们包含很多标点符号。这些标点符号也必须从单词中清除。
fig, axes = plt.subplots(ncols=2, figsize=(18, 50), dpi=100)
plt.tight_layout()
sns.barplot(y=df_disaster_bigrams[0].values[:N], x=df_disaster_bigrams[1].values[:N], ax=axes[0], color='red')
sns.barplot(y=df_nondisaster_bigrams[0].values[:N], x=df_nondisaster_bigrams[1].values[:N], ax=axes[1], color='green')
for i in range(2):
axes[i].spines['right'].set_visible(False)
axes[i].set_xlabel('')
axes[i].set_ylabel('')
axes[i].tick_params(axis='x', labelsize=13)
axes[i].tick_params(axis='y', labelsize=13)
axes[0].set_title(f'Top {N} most common bigrams in Disaster Tweets', fontsize=15)
axes[1].set_title(f'Top {N} most common bigrams in Non-disaster Tweets', fontsize=15)
plt.show()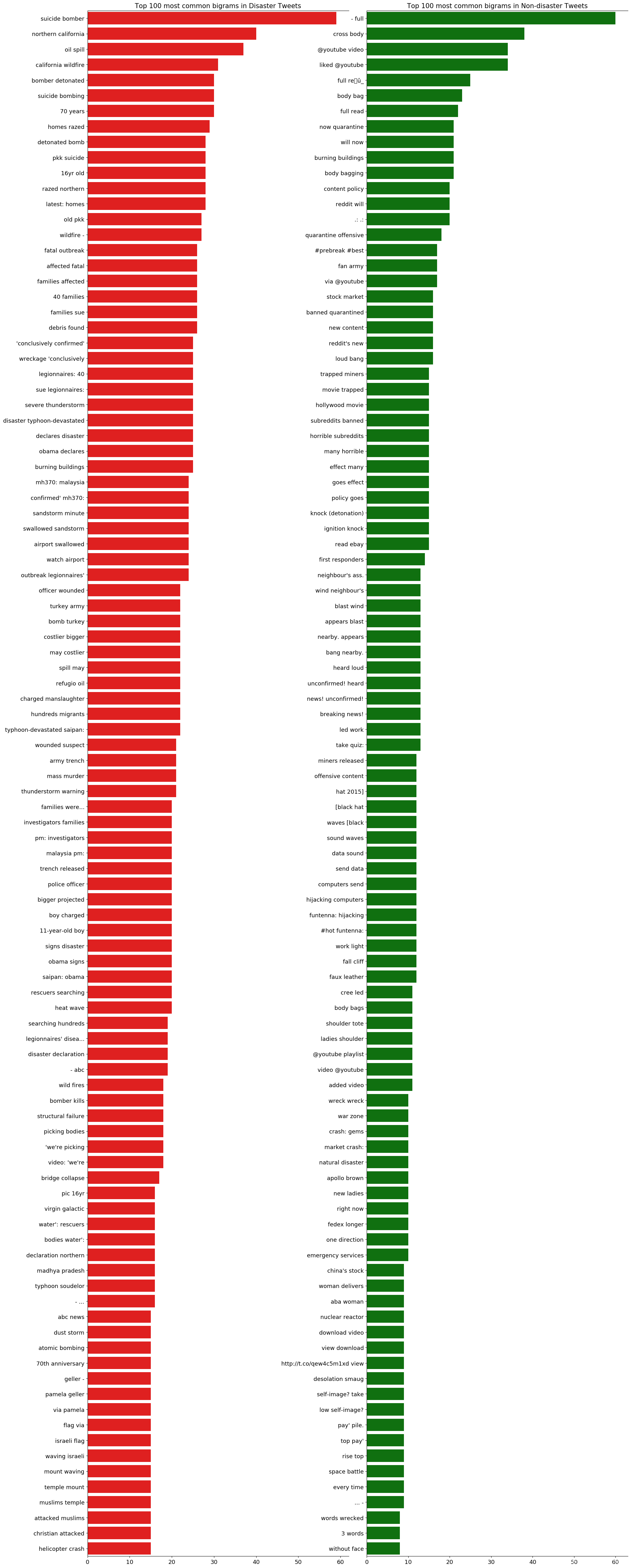
3.4 trigrams 三元语法
这两个类中不存在共同的三元组,因为上下文更清晰。
灾难推文中最常见的三元组与双字母非常相似。它们提供了大量有关灾难的信息,但它们可能不会提供任何其他信息以及双字母。
非灾难推文中最常见的三元组也与双字母非常相似,并且包含更多的标点符号。
fig, axes = plt.subplots(ncols=2, figsize=(20, 50), dpi=100)
sns.barplot(y=df_disaster_trigrams[0].values[:N], x=df_disaster_trigrams[1].values[:N], ax=axes[0], color='red')
sns.barplot(y=df_nondisaster_trigrams[0].values[:N], x=df_nondisaster_trigrams[1].values[:N], ax=axes[1], color='green')
for i in range(2):
axes[i].spines['right'].set_visible(False)
axes[i].set_xlabel('')
axes[i].set_ylabel('')
axes[i].tick_params(axis='x', labelsize=13)
axes[i].tick_params(axis='y', labelsize=11)
axes[0].set_title(f'Top {N} most common trigrams in Disaster Tweets', fontsize=15)
axes[1].set_title(f'Top {N} most common trigrams in Non-disaster Tweets', fontsize=15)
plt.show()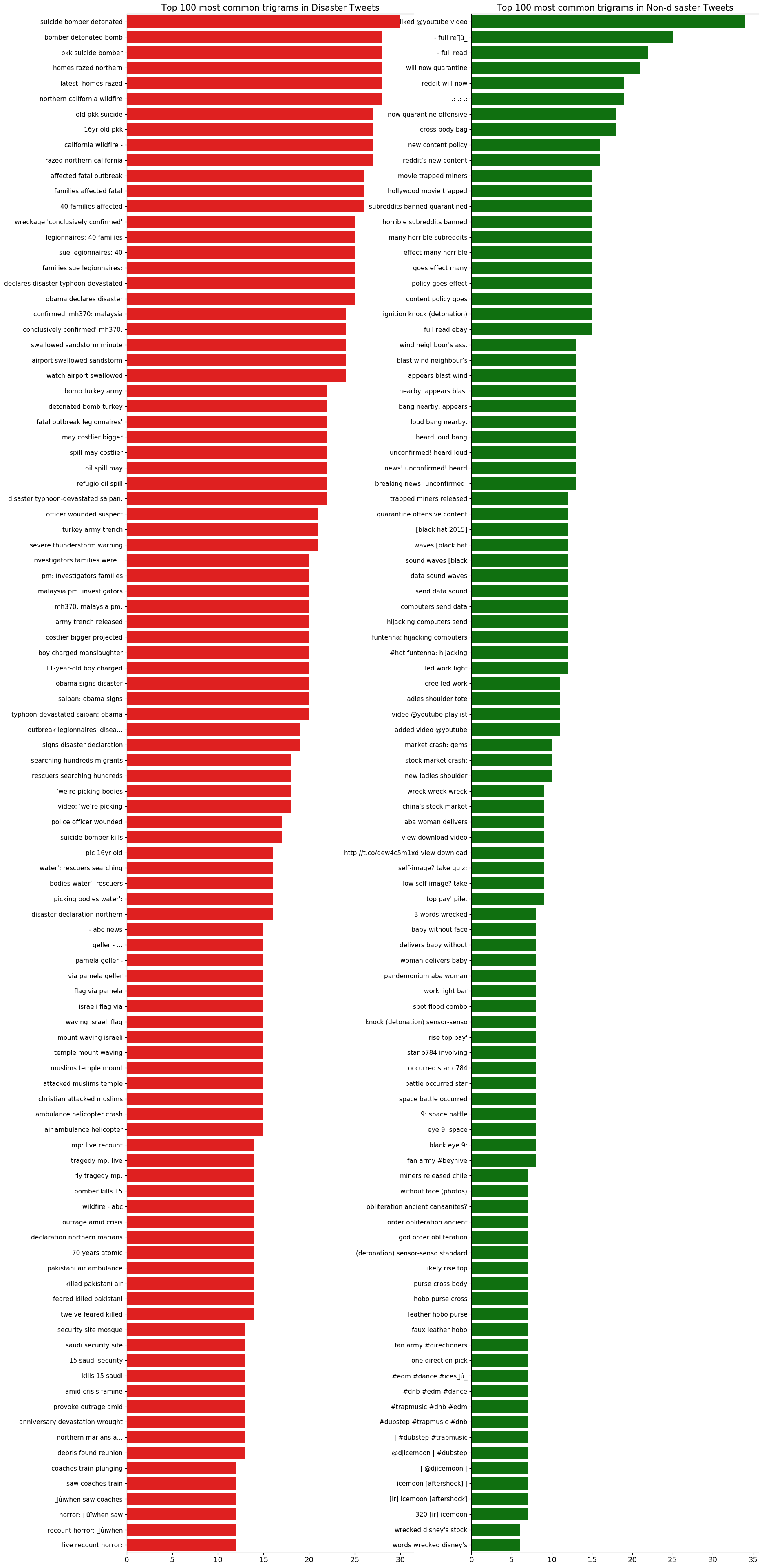
4. 嵌入和文本清理
4.1 嵌入覆盖率
当你有预先训练的嵌入时,执行标准的预处理步骤可能不是一个好主意,因为一些有价值的信息可能会丢失。最好使词汇尽可能接近嵌入。为了做到这一点,训练词汇和测试词汇是通过计算推文中的单词来创建的。
文本清理基于以下嵌入:
- GloVe-300d-840B
- FastText-Crawl-300d-2M
%%time
glove_embeddings = np.load('../input/pickled-glove840b300d-for-10sec-loading/glove.840B.300d.pkl', allow_pickle=True)
fasttext_embeddings = np.load('../input/pickled-crawl300d2m-for-kernel-competitions/crawl-300d-2M.pkl', allow_pickle=True)CPU times: user 14.2 s, sys: 5.2 s, total: 19.4 s Wall time: 19.8 s
词汇和嵌入交集中的单词与其计数一起存储在 covered。词汇表中不存在嵌入的单词与其计数一起存储在 oov。 n_covered和 n_oov是计数总数,它们用于计算覆盖率百分比。
GloVe 和 FastText 嵌入都具有超过 50% 的词汇量和 80% 的文本覆盖率,无需清理。GloVe和FastText的覆盖范围非常接近,但GloVe的覆盖范围略高。
def build_vocab(X):
tweets = X.apply(lambda s: s.split()).values
vocab = {}
for tweet in tweets:
for word in tweet:
try:
vocab[word] += 1
except KeyError:
vocab[word] = 1
return vocab
def check_embeddings_coverage(X, embeddings):
vocab = build_vocab(X)
covered = {}
oov = {}
n_covered = 0
n_oov = 0
for word in vocab:
try:
covered[word] = embeddings[word]
n_covered += vocab[word]
except:
oov[word] = vocab[word]
n_oov += vocab[word]
vocab_coverage = len(covered) / len(vocab)
text_coverage = (n_covered / (n_covered + n_oov))
sorted_oov = sorted(oov.items(), key=operator.itemgetter(1))[::-1]
return sorted_oov, vocab_coverage, text_coverage
train_glove_oov, train_glove_vocab_coverage, train_glove_text_coverage = check_embeddings_coverage(df_train['text'], glove_embeddings)
test_glove_oov, test_glove_vocab_coverage, test_glove_text_coverage = check_embeddings_coverage(df_test['text'], glove_embeddings)
print('GloVe Embeddings cover {:.2%} of vocabulary and {:.2%} of text in Training Set'.format(train_glove_vocab_coverage, train_glove_text_coverage))
print('GloVe Embeddings cover {:.2%} of vocabulary and {:.2%} of text in Test Set'.format(test_glove_vocab_coverage, test_glove_text_coverage))
train_fasttext_oov, train_fasttext_vocab_coverage, train_fasttext_text_coverage = check_embeddings_coverage(df_train['text'], fasttext_embeddings)
test_fasttext_oov, test_fasttext_vocab_coverage, test_fasttext_text_coverage = check_embeddings_coverage(df_test['text'], fasttext_embeddings)
print('FastText Embeddings cover {:.2%} of vocabulary and {:.2%} of text in Training Set'.format(train_fasttext_vocab_coverage, train_fasttext_text_coverage))
print('FastText Embeddings cover {:.2%} of vocabulary and {:.2%} of text in Test Set'.format(test_fasttext_vocab_coverage, test_fasttext_text_coverage))GloVe Embeddings cover 52.06% of vocabulary and 82.68% of text in Training Set GloVe Embeddings cover 57.21% of vocabulary and 81.85% of text in Test Set FastText Embeddings cover 51.52% of vocabulary and 81.84% of text in Training Set FastText Embeddings cover 56.55% of vocabu lary and 81.12% of text in Test Set
4.2 文本清理
推文需要大量清理,但清理每条推文效率低下,因为这会消耗太多时间。必须实施一般清洁方法。
- 需要清理的最常见单词类型
oov在开头或结尾都有标点符号。由于尾随标点符号,这些单词没有嵌入。标点符号#,@,!,?,+,&,-,$,=,<>,|,{},^,',(),[],*,%,...,',.,:,;。 - 附加到单词的特殊字符被完全删除
- 收缩扩大
- 网址被删除
- 字符实体参照将替换为其实际符号
- 更正错别字和俚语,并以长形式编写非正式缩写
- 有些单词被替换为其首字母缩略词,有些单词被分组为一个
- 最后,主题标签和用户名包含许多有关上下文的信息,但它们在单词之间没有空格,因此它们没有嵌入。信息用户名和主题标签应该扩展,但它们太多了。我尽可能多地扩展,但是在添加这些替换调用后运行
clean函数需要太多时间。
%%time
def clean(tweet):
# Special characters
tweet = re.sub(r"\x89Û_", "", tweet)
tweet = re.sub(r"\x89ÛÒ", "", tweet)
tweet = re.sub(r"\x89ÛÓ", "", tweet)
tweet = re.sub(r"\x89ÛÏWhen", "When", tweet)
tweet = re.sub(r"\x89ÛÏ", "", tweet)
tweet = re.sub(r"China\x89Ûªs", "China's", tweet)
tweet = re.sub(r"let\x89Ûªs", "let's", tweet)
tweet = re.sub(r"\x89Û÷", "", tweet)
tweet = re.sub(r"\x89Ûª", "", tweet)
tweet = re.sub(r"\x89Û\x9d", "", tweet)
tweet = re.sub(r"å_", "", tweet)
tweet = re.sub(r"\x89Û¢", "", tweet)
tweet = re.sub(r"\x89Û¢åÊ", "", tweet)
tweet = re.sub(r"fromåÊwounds", "from wounds", tweet)
tweet = re.sub(r"åÊ", "", tweet)
tweet = re.sub(r"åÈ", "", tweet)
tweet = re.sub(r"JapÌ_n", "Japan", tweet)
tweet = re.sub(r"Ì©", "e", tweet)
tweet = re.sub(r"å¨", "", tweet)
tweet = re.sub(r"Surṳ", "Suruc", tweet)
tweet = re.sub(r"åÇ", "", tweet)
tweet = re.sub(r"å£3million", "3 million", tweet)
tweet = re.sub(r"åÀ", "", tweet)
# Contractions
tweet = re.sub(r"he's", "he is", tweet)
tweet = re.sub(r"there's", "there is", tweet)
tweet = re.sub(r"We're", "We are", tweet)
tweet = re.sub(r"That's", "That is", tweet)
tweet = re.sub(r"won't", "will not", tweet)
tweet = re.sub(r"they're", "they are", tweet)
tweet = re.sub(r"Can't", "Cannot", tweet)
tweet = re.sub(r"wasn't", "was not", tweet)
tweet = re.sub(r"don\x89Ûªt", "do not", tweet)
tweet = re.sub(r"aren't", "are not", tweet)
tweet = re.sub(r"isn't", "is not", tweet)
tweet = re.sub(r"What's", "What is", tweet)
tweet = re.sub(r"haven't", "have not", tweet)
tweet = re.sub(r"hasn't", "has not", tweet)
tweet = re.sub(r"There's", "There is", tweet)
tweet = re.sub(r"He's", "He is", tweet)
tweet = re.sub(r"It's", "It is", tweet)
tweet = re.sub(r"You're", "You are", tweet)
tweet = re.sub(r"I'M", "I am", tweet)
tweet = re.sub(r"shouldn't", "should not", tweet)
tweet = re.sub(r"wouldn't", "would not", tweet)
tweet = re.sub(r"i'm", "I am", tweet)
tweet = re.sub(r"I\x89Ûªm", "I am", tweet)
tweet = re.sub(r"I'm", "I am", tweet)
tweet = re.sub(r"Isn't", "is not", tweet)
tweet = re.sub(r"Here's", "Here is", tweet)
tweet = re.sub(r"you've", "you have", tweet)
tweet = re.sub(r"you\x89Ûªve", "you have", tweet)
tweet = re.sub(r"we're", "we are", tweet)
tweet = re.sub(r"what's", "what is", tweet)
tweet = re.sub(r"couldn't", "could not", tweet)
tweet = re.sub(r"we've", "we have", tweet)
tweet = re.sub(r"it\x89Ûªs", "it is", tweet)
tweet = re.sub(r"doesn\x89Ûªt", "does not", tweet)
tweet = re.sub(r"It\x89Ûªs", "It is", tweet)
tweet = re.sub(r"Here\x89Ûªs", "Here is", tweet)
tweet = re.sub(r"who's", "who is", tweet)
tweet = re.sub(r"I\x89Ûªve", "I have", tweet)
tweet = re.sub(r"y'all", "you all", tweet)
tweet = re.sub(r"can\x89Ûªt", "cannot", tweet)
tweet = re.sub(r"would've", "would have", tweet)
tweet = re.sub(r"it'll", "it will", tweet)
tweet = re.sub(r"we'll", "we will", tweet)
tweet = re.sub(r"wouldn\x89Ûªt", "would not", tweet)
tweet = re.sub(r"We've", "We have", tweet)
tweet = re.sub(r"he'll", "he will", tweet)
tweet = re.sub(r"Y'all", "You all", tweet)
tweet = re.sub(r"Weren't", "Were not", tweet)
tweet = re.sub(r"Didn't", "Did not", tweet)
tweet = re.sub(r"they'll", "they will", tweet)
tweet = re.sub(r"they'd", "they would", tweet)
tweet = re.sub(r"DON'T", "DO NOT", tweet)
tweet = re.sub(r"That\x89Ûªs", "That is", tweet)
tweet = re.sub(r"they've", "they have", tweet)
tweet = re.sub(r"i'd", "I would", tweet)
tweet = re.sub(r"should've", "should have", tweet)
tweet = re.sub(r"You\x89Ûªre", "You are", tweet)
tweet = re.sub(r"where's", "where is", tweet)
tweet = re.sub(r"Don\x89Ûªt", "Do not", tweet)
tweet = re.sub(r"we'd", "we would", tweet)
tweet = re.sub(r"i'll", "I will", tweet)
tweet = re.sub(r"weren't", "were not", tweet)
tweet = re.sub(r"They're", "They are", tweet)
tweet = re.sub(r"Can\x89Ûªt", "Cannot", tweet)
tweet = re.sub(r"you\x89Ûªll", "you will", tweet)
tweet = re.sub(r"I\x89Ûªd", "I would", tweet)
tweet = re.sub(r"let's", "let us", tweet)
tweet = re.sub(r"it's", "it is", tweet)
tweet = re.sub(r"can't", "cannot", tweet)
tweet = re.sub(r"don't", "do not", tweet)
tweet = re.sub(r"you're", "you are", tweet)
tweet = re.sub(r"i've", "I have", tweet)
tweet = re.sub(r"that's", "that is", tweet)
tweet = re.sub(r"i'll", "I will", tweet)
tweet = re.sub(r"doesn't", "does not", tweet)
tweet = re.sub(r"i'd", "I would", tweet)
tweet = re.sub(r"didn't", "did not", tweet)
tweet = re.sub(r"ain't", "am not", tweet)
tweet = re.sub(r"you'll", "you will", tweet)
tweet = re.sub(r"I've", "I have", tweet)
tweet = re.sub(r"Don't", "do not", tweet)
tweet = re.sub(r"I'll", "I will", tweet)
tweet = re.sub(r"I'd", "I would", tweet)
tweet = re.sub(r"Let's", "Let us", tweet)
tweet = re.sub(r"you'd", "You would", tweet)
tweet = re.sub(r"It's", "It is", tweet)
tweet = re.sub(r"Ain't", "am not", tweet)
tweet = re.sub(r"Haven't", "Have not", tweet)
tweet = re.sub(r"Could've", "Could have", tweet)
tweet = re.sub(r"youve", "you have", tweet)
tweet = re.sub(r"donå«t", "do not", tweet)
# Character entity references
tweet = re.sub(r">", ">", tweet)
tweet = re.sub(r"<", "<", tweet)
tweet = re.sub(r"&", "&", tweet)
# Typos, slang and informal abbreviations
tweet = re.sub(r"w/e", "whatever", tweet)
tweet = re.sub(r"w/", "with", tweet)
tweet = re.sub(r"USAgov", "USA government", tweet)
tweet = re.sub(r"recentlu", "recently", tweet)
tweet = re.sub(r"Ph0tos", "Photos", tweet)
tweet = re.sub(r"amirite", "am I right", tweet)
tweet = re.sub(r"exp0sed", "exposed", tweet)
tweet = re.sub(r"<3", "love", tweet)
tweet = re.sub(r"amageddon", "armageddon", tweet)
tweet = re.sub(r"Trfc", "Traffic", tweet)
tweet = re.sub(r"8/5/2015", "2015-08-05", tweet)
tweet = re.sub(r"WindStorm", "Wind Storm", tweet)
tweet = re.sub(r"8/6/2015", "2015-08-06", tweet)
tweet = re.sub(r"10:38PM", "10:38 PM", tweet)
tweet = re.sub(r"10:30pm", "10:30 PM", tweet)
tweet = re.sub(r"16yr", "16 year", tweet)
tweet = re.sub(r"lmao", "laughing my ass off", tweet)
tweet = re.sub(r"TRAUMATISED", "traumatized", tweet)
# Hashtags and usernames
tweet = re.sub(r"IranDeal", "Iran Deal", tweet)
tweet = re.sub(r"ArianaGrande", "Ariana Grande", tweet)
tweet = re.sub(r"camilacabello97", "camila cabello", tweet)
tweet = re.sub(r"RondaRousey", "Ronda Rousey", tweet)
tweet = re.sub(r"MTVHottest", "MTV Hottest", tweet)
tweet = re.sub(r"TrapMusic", "Trap Music", tweet)
tweet = re.sub(r"ProphetMuhammad", "Prophet Muhammad", tweet)
tweet = re.sub(r"PantherAttack", "Panther Attack", tweet)
tweet = re.sub(r"StrategicPatience", "Strategic Patience", tweet)
tweet = re.sub(r"socialnews", "social news", tweet)
tweet = re.sub(r"NASAHurricane", "NASA Hurricane", tweet)
tweet = re.sub(r"onlinecommunities", "online communities", tweet)
tweet = re.sub(r"humanconsumption", "human consumption", tweet)
tweet = re.sub(r"Typhoon-Devastated", "Typhoon Devastated", tweet)
tweet = re.sub(r"Meat-Loving", "Meat Loving", tweet)
tweet = re.sub(r"facialabuse", "facial abuse", tweet)
tweet = re.sub(r"LakeCounty", "Lake County", tweet)
tweet = re.sub(r"BeingAuthor", "Being Author", tweet)
tweet = re.sub(r"withheavenly", "with heavenly", tweet)
tweet = re.sub(r"thankU", "thank you", tweet)
tweet = re.sub(r"iTunesMusic", "iTunes Music", tweet)
tweet = re.sub(r"OffensiveContent", "Offensive Content", tweet)
tweet = re.sub(r"WorstSummerJob", "Worst Summer Job", tweet)
tweet = re.sub(r"HarryBeCareful", "Harry Be Careful", tweet)
tweet = re.sub(r"NASASolarSystem", "NASA Solar System", tweet)
tweet = re.sub(r"animalrescue", "animal rescue", tweet)
tweet = re.sub(r"KurtSchlichter", "Kurt Schlichter", tweet)
tweet = re.sub(r"aRmageddon", "armageddon", tweet)
tweet = re.sub(r"Throwingknifes", "Throwing knives", tweet)
tweet = re.sub(r"GodsLove", "God's Love", tweet)
tweet = re.sub(r"bookboost", "book boost", tweet)
tweet = re.sub(r"ibooklove", "I book love", tweet)
tweet = re.sub(r"NestleIndia", "Nestle India", tweet)
tweet = re.sub(r"realDonaldTrump", "Donald Trump", tweet)
tweet = re.sub(r"DavidVonderhaar", "David Vonderhaar", tweet)
tweet = re.sub(r"CecilTheLion", "Cecil The Lion", tweet)
tweet = re.sub(r"weathernetwork", "weather network", tweet)
tweet = re.sub(r"withBioterrorism&use", "with Bioterrorism & use", tweet)
tweet = re.sub(r"Hostage&2", "Hostage & 2", tweet)
tweet = re.sub(r"GOPDebate", "GOP Debate", tweet)
tweet = re.sub(r"RickPerry", "Rick Perry", tweet)
tweet = re.sub(r"frontpage", "front page", tweet)
tweet = re.sub(r"NewsInTweets", "News In Tweets", tweet)
tweet = re.sub(r"ViralSpell", "Viral Spell", tweet)
tweet = re.sub(r"til_now", "until now", tweet)
tweet = re.sub(r"volcanoinRussia", "volcano in Russia", tweet)
tweet = re.sub(r"ZippedNews", "Zipped News", tweet)
tweet = re.sub(r"MicheleBachman", "Michele Bachman", tweet)
tweet = re.sub(r"53inch", "53 inch", tweet)
tweet = re.sub(r"KerrickTrial", "Kerrick Trial", tweet)
tweet = re.sub(r"abstorm", "Alberta Storm", tweet)
tweet = re.sub(r"Beyhive", "Beyonce hive", tweet)
tweet = re.sub(r"IDFire", "Idaho Fire", tweet)
tweet = re.sub(r"DETECTADO", "Detected", tweet)
tweet = re.sub(r"RockyFire", "Rocky Fire", tweet)
tweet = re.sub(r"Listen/Buy", "Listen / Buy", tweet)
tweet = re.sub(r"NickCannon", "Nick Cannon", tweet)
tweet = re.sub(r"FaroeIslands", "Faroe Islands", tweet)
tweet = re.sub(r"yycstorm", "Calgary Storm", tweet)
tweet = re.sub(r"IDPs:", "Internally Displaced People :", tweet)
tweet = re.sub(r"ArtistsUnited", "Artists United", tweet)
tweet = re.sub(r"ClaytonBryant", "Clayton Bryant", tweet)
tweet = re.sub(r"jimmyfallon", "jimmy fallon", tweet)
tweet = re.sub(r"justinbieber", "justin bieber", tweet)
tweet = re.sub(r"UTC2015", "UTC 2015", tweet)
tweet = re.sub(r"Time2015", "Time 2015", tweet)
tweet = re.sub(r"djicemoon", "dj icemoon", tweet)
tweet = re.sub(r"LivingSafely", "Living Safely", tweet)
tweet = re.sub(r"FIFA16", "Fifa 2016", tweet)
tweet = re.sub(r"thisiswhywecanthavenicethings", "this is why we cannot have nice things", tweet)
tweet = re.sub(r"bbcnews", "bbc news", tweet)
tweet = re.sub(r"UndergroundRailraod", "Underground Railraod", tweet)
tweet = re.sub(r"c4news", "c4 news", tweet)
tweet = re.sub(r"OBLITERATION", "obliteration", tweet)
tweet = re.sub(r"MUDSLIDE", "mudslide", tweet)
tweet = re.sub(r"NoSurrender", "No Surrender", tweet)
tweet = re.sub(r"NotExplained", "Not Explained", tweet)
tweet = re.sub(r"greatbritishbakeoff", "great british bake off", tweet)
tweet = re.sub(r"LondonFire", "London Fire", tweet)
tweet = re.sub(r"KOTAWeather", "KOTA Weather", tweet)
tweet = re.sub(r"LuchaUnderground", "Lucha Underground", tweet)
tweet = re.sub(r"KOIN6News", "KOIN 6 News", tweet)
tweet = re.sub(r"LiveOnK2", "Live On K2", tweet)
tweet = re.sub(r"9NewsGoldCoast", "9 News Gold Coast", tweet)
tweet = re.sub(r"nikeplus", "nike plus", tweet)
tweet = re.sub(r"david_cameron", "David Cameron", tweet)
tweet = re.sub(r"peterjukes", "Peter Jukes", tweet)
tweet = re.sub(r"JamesMelville", "James Melville", tweet)
tweet = re.sub(r"megynkelly", "Megyn Kelly", tweet)
tweet = re.sub(r"cnewslive", "C News Live", tweet)
tweet = re.sub(r"JamaicaObserver", "Jamaica Observer", tweet)
tweet = re.sub(r"TweetLikeItsSeptember11th2001", "Tweet like it is september 11th 2001", tweet)
tweet = re.sub(r"cbplawyers", "cbp lawyers", tweet)
tweet = re.sub(r"fewmoretweets", "few more tweets", tweet)
tweet = re.sub(r"BlackLivesMatter", "Black Lives Matter", tweet)
tweet = re.sub(r"cjoyner", "Chris Joyner", tweet)
tweet = re.sub(r"ENGvAUS", "England vs Australia", tweet)
tweet = re.sub(r"ScottWalker", "Scott Walker", tweet)
tweet = re.sub(r"MikeParrActor", "Michael Parr", tweet)
tweet = re.sub(r"4PlayThursdays", "Foreplay Thursdays", tweet)
tweet = re.sub(r"TGF2015", "Tontitown Grape Festival", tweet)
tweet = re.sub(r"realmandyrain", "Mandy Rain", tweet)
tweet = re.sub(r"GraysonDolan", "Grayson Dolan", tweet)
tweet = re.sub(r"ApolloBrown", "Apollo Brown", tweet)
tweet = re.sub(r"saddlebrooke", "Saddlebrooke", tweet)
tweet = re.sub(r"TontitownGrape", "Tontitown Grape", tweet)
tweet = re.sub(r"AbbsWinston", "Abbs Winston", tweet)
tweet = re.sub(r"ShaunKing", "Shaun King", tweet)
tweet = re.sub(r"MeekMill", "Meek Mill", tweet)
tweet = re.sub(r"TornadoGiveaway", "Tornado Giveaway", tweet)
tweet = re.sub(r"GRupdates", "GR updates", tweet)
tweet = re.sub(r"SouthDowns", "South Downs", tweet)
tweet = re.sub(r"braininjury", "brain injury", tweet)
tweet = re.sub(r"auspol", "Australian politics", tweet)
tweet = re.sub(r"PlannedParenthood", "Planned Parenthood", tweet)
tweet = re.sub(r"calgaryweather", "Calgary Weather", tweet)
tweet = re.sub(r"weallheartonedirection", "we all heart one direction", tweet)
tweet = re.sub(r"edsheeran", "Ed Sheeran", tweet)
tweet = re.sub(r"TrueHeroes", "True Heroes", tweet)
tweet = re.sub(r"S3XLEAK", "sex leak", tweet)
tweet = re.sub(r"ComplexMag", "Complex Magazine", tweet)
tweet = re.sub(r"TheAdvocateMag", "The Advocate Magazine", tweet)
tweet = re.sub(r"CityofCalgary", "City of Calgary", tweet)
tweet = re.sub(r"EbolaOutbreak", "Ebola Outbreak", tweet)
tweet = re.sub(r"SummerFate", "Summer Fate", tweet)
tweet = re.sub(r"RAmag", "Royal Academy Magazine", tweet)
tweet = re.sub(r"offers2go", "offers to go", tweet)
tweet = re.sub(r"foodscare", "food scare", tweet)
tweet = re.sub(r"MNPDNashville", "Metropolitan Nashville Police Department", tweet)
tweet = re.sub(r"TfLBusAlerts", "TfL Bus Alerts", tweet)
tweet = re.sub(r"GamerGate", "Gamer Gate", tweet)
tweet = re.sub(r"IHHen", "Humanitarian Relief", tweet)
tweet = re.sub(r"spinningbot", "spinning bot", tweet)
tweet = re.sub(r"ModiMinistry", "Modi Ministry", tweet)
tweet = re.sub(r"TAXIWAYS", "taxi ways", tweet)
tweet = re.sub(r"Calum5SOS", "Calum Hood", tweet)
tweet = re.sub(r"po_st", "po.st", tweet)
tweet = re.sub(r"scoopit", "scoop.it", tweet)
tweet = re.sub(r"UltimaLucha", "Ultima Lucha", tweet)
tweet = re.sub(r"JonathanFerrell", "Jonathan Ferrell", tweet)
tweet = re.sub(r"aria_ahrary", "Aria Ahrary", tweet)
tweet = re.sub(r"rapidcity", "Rapid City", tweet)
tweet = re.sub(r"OutBid", "outbid", tweet)
tweet = re.sub(r"lavenderpoetrycafe", "lavender poetry cafe", tweet)
tweet = re.sub(r"EudryLantiqua", "Eudry Lantiqua", tweet)
tweet = re.sub(r"15PM", "15 PM", tweet)
tweet = re.sub(r"OriginalFunko", "Funko", tweet)
tweet = re.sub(r"rightwaystan", "Richard Tan", tweet)
tweet = re.sub(r"CindyNoonan", "Cindy Noonan", tweet)
tweet = re.sub(r"RT_America", "RT America", tweet)
tweet = re.sub(r"narendramodi", "Narendra Modi", tweet)
tweet = re.sub(r"BakeOffFriends", "Bake Off Friends", tweet)
tweet = re.sub(r"TeamHendrick", "Hendrick Motorsports", tweet)
tweet = re.sub(r"alexbelloli", "Alex Belloli", tweet)
tweet = re.sub(r"itsjustinstuart", "Justin Stuart", tweet)
tweet = re.sub(r"gunsense", "gun sense", tweet)
tweet = re.sub(r"DebateQuestionsWeWantToHear", "debate questions we want to hear", tweet)
tweet = re.sub(r"RoyalCarribean", "Royal Carribean", tweet)
tweet = re.sub(r"samanthaturne19", "Samantha Turner", tweet)
tweet = re.sub(r"JonVoyage", "Jon Stewart", tweet)
tweet = re.sub(r"renew911health", "renew 911 health", tweet)
tweet = re.sub(r"SuryaRay", "Surya Ray", tweet)
tweet = re.sub(r"pattonoswalt", "Patton Oswalt", tweet)
tweet = re.sub(r"minhazmerchant", "Minhaz Merchant", tweet)
tweet = re.sub(r"TLVFaces", "Israel Diaspora Coalition", tweet)
tweet = re.sub(r"pmarca", "Marc Andreessen", tweet)
tweet = re.sub(r"pdx911", "Portland Police", tweet)
tweet = re.sub(r"jamaicaplain", "Jamaica Plain", tweet)
tweet = re.sub(r"Japton", "Arkansas", tweet)
tweet = re.sub(r"RouteComplex", "Route Complex", tweet)
tweet = re.sub(r"INSubcontinent", "Indian Subcontinent", tweet)
tweet = re.sub(r"NJTurnpike", "New Jersey Turnpike", tweet)
tweet = re.sub(r"Politifiact", "PolitiFact", tweet)
tweet = re.sub(r"Hiroshima70", "Hiroshima", tweet)
tweet = re.sub(r"GMMBC", "Greater Mt Moriah Baptist Church", tweet)
tweet = re.sub(r"versethe", "verse the", tweet)
tweet = re.sub(r"TubeStrike", "Tube Strike", tweet)
tweet = re.sub(r"MissionHills", "Mission Hills", tweet)
tweet = re.sub(r"ProtectDenaliWolves", "Protect Denali Wolves", tweet)
tweet = re.sub(r"NANKANA", "Nankana", tweet)
tweet = re.sub(r"SAHIB", "Sahib", tweet)
tweet = re.sub(r"PAKPATTAN", "Pakpattan", tweet)
tweet = re.sub(r"Newz_Sacramento", "News Sacramento", tweet)
tweet = re.sub(r"gofundme", "go fund me", tweet)
tweet = re.sub(r"pmharper", "Stephen Harper", tweet)
tweet = re.sub(r"IvanBerroa", "Ivan Berroa", tweet)
tweet = re.sub(r"LosDelSonido", "Los Del Sonido", tweet)
tweet = re.sub(r"bancodeseries", "banco de series", tweet)
tweet = re.sub(r"timkaine", "Tim Kaine", tweet)
tweet = re.sub(r"IdentityTheft", "Identity Theft", tweet)
tweet = re.sub(r"AllLivesMatter", "All Lives Matter", tweet)
tweet = re.sub(r"mishacollins", "Misha Collins", tweet)
tweet = re.sub(r"BillNeelyNBC", "Bill Neely", tweet)
tweet = re.sub(r"BeClearOnCancer", "be clear on cancer", tweet)
tweet = re.sub(r"Kowing", "Knowing", tweet)
tweet = re.sub(r"ScreamQueens", "Scream Queens", tweet)
tweet = re.sub(r"AskCharley", "Ask Charley", tweet)
tweet = re.sub(r"BlizzHeroes", "Heroes of the Storm", tweet)
tweet = re.sub(r"BradleyBrad47", "Bradley Brad", tweet)
tweet = re.sub(r"HannaPH", "Typhoon Hanna", tweet)
tweet = re.sub(r"meinlcymbals", "MEINL Cymbals", tweet)
tweet = re.sub(r"Ptbo", "Peterborough", tweet)
tweet = re.sub(r"cnnbrk", "CNN Breaking News", tweet)
tweet = re.sub(r"IndianNews", "Indian News", tweet)
tweet = re.sub(r"savebees", "save bees", tweet)
tweet = re.sub(r"GreenHarvard", "Green Harvard", tweet)
tweet = re.sub(r"StandwithPP", "Stand with planned parenthood", tweet)
tweet = re.sub(r"hermancranston", "Herman Cranston", tweet)
tweet = re.sub(r"WMUR9", "WMUR-TV", tweet)
tweet = re.sub(r"RockBottomRadFM", "Rock Bottom Radio", tweet)
tweet = re.sub(r"ameenshaikh3", "Ameen Shaikh", tweet)
tweet = re.sub(r"ProSyn", "Project Syndicate", tweet)
tweet = re.sub(r"Daesh", "ISIS", tweet)
tweet = re.sub(r"s2g", "swear to god", tweet)
tweet = re.sub(r"listenlive", "listen live", tweet)
tweet = re.sub(r"CDCgov", "Centers for Disease Control and Prevention", tweet)
tweet = re.sub(r"FoxNew", "Fox News", tweet)
tweet = re.sub(r"CBSBigBrother", "Big Brother", tweet)
tweet = re.sub(r"JulieDiCaro", "Julie DiCaro", tweet)
tweet = re.sub(r"theadvocatemag", "The Advocate Magazine", tweet)
tweet = re.sub(r"RohnertParkDPS", "Rohnert Park Police Department", tweet)
tweet = re.sub(r"THISIZBWRIGHT", "Bonnie Wright", tweet)
tweet = re.sub(r"Popularmmos", "Popular MMOs", tweet)
tweet = re.sub(r"WildHorses", "Wild Horses", tweet)
tweet = re.sub(r"FantasticFour", "Fantastic Four", tweet)
tweet = re.sub(r"HORNDALE", "Horndale", tweet)
tweet = re.sub(r"PINER", "Piner", tweet)
tweet = re.sub(r"BathAndNorthEastSomerset", "Bath and North East Somerset", tweet)
tweet = re.sub(r"thatswhatfriendsarefor", "that is what friends are for", tweet)
tweet = re.sub(r"residualincome", "residual income", tweet)
tweet = re.sub(r"YahooNewsDigest", "Yahoo News Digest", tweet)
tweet = re.sub(r"MalaysiaAirlines", "Malaysia Airlines", tweet)
tweet = re.sub(r"AmazonDeals", "Amazon Deals", tweet)
tweet = re.sub(r"MissCharleyWebb", "Charley Webb", tweet)
tweet = re.sub(r"shoalstraffic", "shoals traffic", tweet)
tweet = re.sub(r"GeorgeFoster72", "George Foster", tweet)
tweet = re.sub(r"pop2015", "pop 2015", tweet)
tweet = re.sub(r"_PokemonCards_", "Pokemon Cards", tweet)
tweet = re.sub(r"DianneG", "Dianne Gallagher", tweet)
tweet = re.sub(r"KashmirConflict", "Kashmir Conflict", tweet)
tweet = re.sub(r"BritishBakeOff", "British Bake Off", tweet)
tweet = re.sub(r"FreeKashmir", "Free Kashmir", tweet)
tweet = re.sub(r"mattmosley", "Matt Mosley", tweet)
tweet = re.sub(r"BishopFred", "Bishop Fred", tweet)
tweet = re.sub(r"EndConflict", "End Conflict", tweet)
tweet = re.sub(r"EndOccupation", "End Occupation", tweet)
tweet = re.sub(r"UNHEALED", "unhealed", tweet)
tweet = re.sub(r"CharlesDagnall", "Charles Dagnall", tweet)
tweet = re.sub(r"Latestnews", "Latest news", tweet)
tweet = re.sub(r"KindleCountdown", "Kindle Countdown", tweet)
tweet = re.sub(r"NoMoreHandouts", "No More Handouts", tweet)
tweet = re.sub(r"datingtips", "dating tips", tweet)
tweet = re.sub(r"charlesadler", "Charles Adler", tweet)
tweet = re.sub(r"twia", "Texas Windstorm Insurance Association", tweet)
tweet = re.sub(r"txlege", "Texas Legislature", tweet)
tweet = re.sub(r"WindstormInsurer", "Windstorm Insurer", tweet)
tweet = re.sub(r"Newss", "News", tweet)
tweet = re.sub(r"hempoil", "hemp oil", tweet)
tweet = re.sub(r"CommoditiesAre", "Commodities are", tweet)
tweet = re.sub(r"tubestrike", "tube strike", tweet)
tweet = re.sub(r"JoeNBC", "Joe Scarborough", tweet)
tweet = re.sub(r"LiteraryCakes", "Literary Cakes", tweet)
tweet = re.sub(r"TI5", "The International 5", tweet)
tweet = re.sub(r"thehill", "the hill", tweet)
tweet = re.sub(r"3others", "3 others", tweet)
tweet = re.sub(r"stighefootball", "Sam Tighe", tweet)
tweet = re.sub(r"whatstheimportantvideo", "what is the important video", tweet)
tweet = re.sub(r"ClaudioMeloni", "Claudio Meloni", tweet)
tweet = re.sub(r"DukeSkywalker", "Duke Skywalker", tweet)
tweet = re.sub(r"carsonmwr", "Fort Carson", tweet)
tweet = re.sub(r"offdishduty", "off dish duty", tweet)
tweet = re.sub(r"andword", "and word", tweet)
tweet = re.sub(r"rhodeisland", "Rhode Island", tweet)
tweet = re.sub(r"easternoregon", "Eastern Oregon", tweet)
tweet = re.sub(r"WAwildfire", "Washington Wildfire", tweet)
tweet = re.sub(r"fingerrockfire", "Finger Rock Fire", tweet)
tweet = re.sub(r"57am", "57 am", tweet)
tweet = re.sub(r"fingerrockfire", "Finger Rock Fire", tweet)
tweet = re.sub(r"JacobHoggard", "Jacob Hoggard", tweet)
tweet = re.sub(r"newnewnew", "new new new", tweet)
tweet = re.sub(r"under50", "under 50", tweet)
tweet = re.sub(r"getitbeforeitsgone", "get it before it is gone", tweet)
tweet = re.sub(r"freshoutofthebox", "fresh out of the box", tweet)
tweet = re.sub(r"amwriting", "am writing", tweet)
tweet = re.sub(r"Bokoharm", "Boko Haram", tweet)
tweet = re.sub(r"Nowlike", "Now like", tweet)
tweet = re.sub(r"seasonfrom", "season from", tweet)
tweet = re.sub(r"epicente", "epicenter", tweet)
tweet = re.sub(r"epicenterr", "epicenter", tweet)
tweet = re.sub(r"sicklife", "sick life", tweet)
tweet = re.sub(r"yycweather", "Calgary Weather", tweet)
tweet = re.sub(r"calgarysun", "Calgary Sun", tweet)
tweet = re.sub(r"approachng", "approaching", tweet)
tweet = re.sub(r"evng", "evening", tweet)
tweet = re.sub(r"Sumthng", "something", tweet)
tweet = re.sub(r"EllenPompeo", "Ellen Pompeo", tweet)
tweet = re.sub(r"shondarhimes", "Shonda Rhimes", tweet)
tweet = re.sub(r"ABCNetwork", "ABC Network", tweet)
tweet = re.sub(r"SushmaSwaraj", "Sushma Swaraj", tweet)
tweet = re.sub(r"pray4japan", "Pray for Japan", tweet)
tweet = re.sub(r"hope4japan", "Hope for Japan", tweet)
tweet = re.sub(r"Illusionimagess", "Illusion images", tweet)
tweet = re.sub(r"SummerUnderTheStars", "Summer Under The Stars", tweet)
tweet = re.sub(r"ShallWeDance", "Shall We Dance", tweet)
tweet = re.sub(r"TCMParty", "TCM Party", tweet)
tweet = re.sub(r"marijuananews", "marijuana news", tweet)
tweet = re.sub(r"onbeingwithKristaTippett", "on being with Krista Tippett", tweet)
tweet = re.sub(r"Beingtweets", "Being tweets", tweet)
tweet = re.sub(r"newauthors", "new authors", tweet)
tweet = re.sub(r"remedyyyy", "remedy", tweet)
tweet = re.sub(r"44PM", "44 PM", tweet)
tweet = re.sub(r"HeadlinesApp", "Headlines App", tweet)
tweet = re.sub(r"40PM", "40 PM", tweet)
tweet = re.sub(r"myswc", "Severe Weather Center", tweet)
tweet = re.sub(r"ithats", "that is", tweet)
tweet = re.sub(r"icouldsitinthismomentforever", "I could sit in this moment forever", tweet)
tweet = re.sub(r"FatLoss", "Fat Loss", tweet)
tweet = re.sub(r"02PM", "02 PM", tweet)
tweet = re.sub(r"MetroFmTalk", "Metro Fm Talk", tweet)
tweet = re.sub(r"Bstrd", "bastard", tweet)
tweet = re.sub(r"bldy", "bloody", tweet)
tweet = re.sub(r"MetrofmTalk", "Metro Fm Talk", tweet)
tweet = re.sub(r"terrorismturn", "terrorism turn", tweet)
tweet = re.sub(r"BBCNewsAsia", "BBC News Asia", tweet)
tweet = re.sub(r"BehindTheScenes", "Behind The Scenes", tweet)
tweet = re.sub(r"GeorgeTakei", "George Takei", tweet)
tweet = re.sub(r"WomensWeeklyMag", "Womens Weekly Magazine", tweet)
tweet = re.sub(r"SurvivorsGuidetoEarth", "Survivors Guide to Earth", tweet)
tweet = re.sub(r"incubusband", "incubus band", tweet)
tweet = re.sub(r"Babypicturethis", "Baby picture this", tweet)
tweet = re.sub(r"BombEffects", "Bomb Effects", tweet)
tweet = re.sub(r"win10", "Windows 10", tweet)
tweet = re.sub(r"idkidk", "I do not know I do not know", tweet)
tweet = re.sub(r"TheWalkingDead", "The Walking Dead", tweet)
tweet = re.sub(r"amyschumer", "Amy Schumer", tweet)
tweet = re.sub(r"crewlist", "crew list", tweet)
tweet = re.sub(r"Erdogans", "Erdogan", tweet)
tweet = re.sub(r"BBCLive", "BBC Live", tweet)
tweet = re.sub(r"TonyAbbottMHR", "Tony Abbott", tweet)
tweet = re.sub(r"paulmyerscough", "Paul Myerscough", tweet)
tweet = re.sub(r"georgegallagher", "George Gallagher", tweet)
tweet = re.sub(r"JimmieJohnson", "Jimmie Johnson", tweet)
tweet = re.sub(r"pctool", "pc tool", tweet)
tweet = re.sub(r"DoingHashtagsRight", "Doing Hashtags Right", tweet)
tweet = re.sub(r"ThrowbackThursday", "Throwback Thursday", tweet)
tweet = re.sub(r"SnowBackSunday", "Snowback Sunday", tweet)
tweet = re.sub(r"LakeEffect", "Lake Effect", tweet)
tweet = re.sub(r"RTphotographyUK", "Richard Thomas Photography UK", tweet)
tweet = re.sub(r"BigBang_CBS", "Big Bang CBS", tweet)
tweet = re.sub(r"writerslife", "writers life", tweet)
tweet = re.sub(r"NaturalBirth", "Natural Birth", tweet)
tweet = re.sub(r"UnusualWords", "Unusual Words", tweet)
tweet = re.sub(r"wizkhalifa", "Wiz Khalifa", tweet)
tweet = re.sub(r"acreativedc", "a creative DC", tweet)
tweet = re.sub(r"vscodc", "vsco DC", tweet)
tweet = re.sub(r"VSCOcam", "vsco camera", tweet)
tweet = re.sub(r"TheBEACHDC", "The beach DC", tweet)
tweet = re.sub(r"buildingmuseum", "building museum", tweet)
tweet = re.sub(r"WorldOil", "World Oil", tweet)
tweet = re.sub(r"redwedding", "red wedding", tweet)
tweet = re.sub(r"AmazingRaceCanada", "Amazing Race Canada", tweet)
tweet = re.sub(r"WakeUpAmerica", "Wake Up America", tweet)
tweet = re.sub(r"\\Allahuakbar\\", "Allahu Akbar", tweet)
tweet = re.sub(r"bleased", "blessed", tweet)
tweet = re.sub(r"nigeriantribune", "Nigerian Tribune", tweet)
tweet = re.sub(r"HIDEO_KOJIMA_EN", "Hideo Kojima", tweet)
tweet = re.sub(r"FusionFestival", "Fusion Festival", tweet)
tweet = re.sub(r"50Mixed", "50 Mixed", tweet)
tweet = re.sub(r"NoAgenda", "No Agenda", tweet)
tweet = re.sub(r"WhiteGenocide", "White Genocide", tweet)
tweet = re.sub(r"dirtylying", "dirty lying", tweet)
tweet = re.sub(r"SyrianRefugees", "Syrian Refugees", tweet)
tweet = re.sub(r"changetheworld", "change the world", tweet)
tweet = re.sub(r"Ebolacase", "Ebola case", tweet)
tweet = re.sub(r"mcgtech", "mcg technologies", tweet)
tweet = re.sub(r"withweapons", "with weapons", tweet)
tweet = re.sub(r"advancedwarfare", "advanced warfare", tweet)
tweet = re.sub(r"letsFootball", "let us Football", tweet)
tweet = re.sub(r"LateNiteMix", "late night mix", tweet)
tweet = re.sub(r"PhilCollinsFeed", "Phil Collins", tweet)
tweet = re.sub(r"RudyHavenstein", "Rudy Havenstein", tweet)
tweet = re.sub(r"22PM", "22 PM", tweet)
tweet = re.sub(r"54am", "54 AM", tweet)
tweet = re.sub(r"38am", "38 AM", tweet)
tweet = re.sub(r"OldFolkExplainStuff", "Old Folk Explain Stuff", tweet)
tweet = re.sub(r"BlacklivesMatter", "Black Lives Matter", tweet)
tweet = re.sub(r"InsaneLimits", "Insane Limits", tweet)
tweet = re.sub(r"youcantsitwithus", "you cannot sit with us", tweet)
tweet = re.sub(r"2k15", "2015", tweet)
tweet = re.sub(r"TheIran", "Iran", tweet)
tweet = re.sub(r"JimmyFallon", "Jimmy Fallon", tweet)
tweet = re.sub(r"AlbertBrooks", "Albert Brooks", tweet)
tweet = re.sub(r"defense_news", "defense news", tweet)
tweet = re.sub(r"nuclearrcSA", "Nuclear Risk Control Self Assessment", tweet)
tweet = re.sub(r"Auspol", "Australia Politics", tweet)
tweet = re.sub(r"NuclearPower", "Nuclear Power", tweet)
tweet = re.sub(r"WhiteTerrorism", "White Terrorism", tweet)
tweet = re.sub(r"truthfrequencyradio", "Truth Frequency Radio", tweet)
tweet = re.sub(r"ErasureIsNotEquality", "Erasure is not equality", tweet)
tweet = re.sub(r"ProBonoNews", "Pro Bono News", tweet)
tweet = re.sub(r"JakartaPost", "Jakarta Post", tweet)
tweet = re.sub(r"toopainful", "too painful", tweet)
tweet = re.sub(r"melindahaunton", "Melinda Haunton", tweet)
tweet = re.sub(r"NoNukes", "No Nukes", tweet)
tweet = re.sub(r"curryspcworld", "Currys PC World", tweet)
tweet = re.sub(r"ineedcake", "I need cake", tweet)
tweet = re.sub(r"blackforestgateau", "black forest gateau", tweet)
tweet = re.sub(r"BBCOne", "BBC One", tweet)
tweet = re.sub(r"AlexxPage", "Alex Page", tweet)
tweet = re.sub(r"jonathanserrie", "Jonathan Serrie", tweet)
tweet = re.sub(r"SocialJerkBlog", "Social Jerk Blog", tweet)
tweet = re.sub(r"ChelseaVPeretti", "Chelsea Peretti", tweet)
tweet = re.sub(r"irongiant", "iron giant", tweet)
tweet = re.sub(r"RonFunches", "Ron Funches", tweet)
tweet = re.sub(r"TimCook", "Tim Cook", tweet)
tweet = re.sub(r"sebastianstanisaliveandwell", "Sebastian Stan is alive and well", tweet)
tweet = re.sub(r"Madsummer", "Mad summer", tweet)
tweet = re.sub(r"NowYouKnow", "Now you know", tweet)
tweet = re.sub(r"concertphotography", "concert photography", tweet)
tweet = re.sub(r"TomLandry", "Tom Landry", tweet)
tweet = re.sub(r"showgirldayoff", "show girl day off", tweet)
tweet = re.sub(r"Yougslavia", "Yugoslavia", tweet)
tweet = re.sub(r"QuantumDataInformatics", "Quantum Data Informatics", tweet)
tweet = re.sub(r"FromTheDesk", "From The Desk", tweet)
tweet = re.sub(r"TheaterTrial", "Theater Trial", tweet)
tweet = re.sub(r"CatoInstitute", "Cato Institute", tweet)
tweet = re.sub(r"EmekaGift", "Emeka Gift", tweet)
tweet = re.sub(r"LetsBe_Rational", "Let us be rational", tweet)
tweet = re.sub(r"Cynicalreality", "Cynical reality", tweet)
tweet = re.sub(r"FredOlsenCruise", "Fred Olsen Cruise", tweet)
tweet = re.sub(r"NotSorry", "not sorry", tweet)
tweet = re.sub(r"UseYourWords", "use your words", tweet)
tweet = re.sub(r"WordoftheDay", "word of the day", tweet)
tweet = re.sub(r"Dictionarycom", "Dictionary.com", tweet)
tweet = re.sub(r"TheBrooklynLife", "The Brooklyn Life", tweet)
tweet = re.sub(r"jokethey", "joke they", tweet)
tweet = re.sub(r"nflweek1picks", "NFL week 1 picks", tweet)
tweet = re.sub(r"uiseful", "useful", tweet)
tweet = re.sub(r"JusticeDotOrg", "The American Association for Justice", tweet)
tweet = re.sub(r"autoaccidents", "auto accidents", tweet)
tweet = re.sub(r"SteveGursten", "Steve Gursten", tweet)
tweet = re.sub(r"MichiganAutoLaw", "Michigan Auto Law", tweet)
tweet = re.sub(r"birdgang", "bird gang", tweet)
tweet = re.sub(r"nflnetwork", "NFL Network", tweet)
tweet = re.sub(r"NYDNSports", "NY Daily News Sports", tweet)
tweet = re.sub(r"RVacchianoNYDN", "Ralph Vacchiano NY Daily News", tweet)
tweet = re.sub(r"EdmontonEsks", "Edmonton Eskimos", tweet)
tweet = re.sub(r"david_brelsford", "David Brelsford", tweet)
tweet = re.sub(r"TOI_India", "The Times of India", tweet)
tweet = re.sub(r"hegot", "he got", tweet)
tweet = re.sub(r"SkinsOn9", "Skins on 9", tweet)
tweet = re.sub(r"sothathappened", "so that happened", tweet)
tweet = re.sub(r"LCOutOfDoors", "LC Out Of Doors", tweet)
tweet = re.sub(r"NationFirst", "Nation First", tweet)
tweet = re.sub(r"IndiaToday", "India Today", tweet)
tweet = re.sub(r"HLPS", "helps", tweet)
tweet = re.sub(r"HOSTAGESTHROSW", "hostages throw", tweet)
tweet = re.sub(r"SNCTIONS", "sanctions", tweet)
tweet = re.sub(r"BidTime", "Bid Time", tweet)
tweet = re.sub(r"crunchysensible", "crunchy sensible", tweet)
tweet = re.sub(r"RandomActsOfRomance", "Random acts of romance", tweet)
tweet = re.sub(r"MomentsAtHill", "Moments at hill", tweet)
tweet = re.sub(r"eatshit", "eat shit", tweet)
tweet = re.sub(r"liveleakfun", "live leak fun", tweet)
tweet = re.sub(r"SahelNews", "Sahel News", tweet)
tweet = re.sub(r"abc7newsbayarea", "ABC 7 News Bay Area", tweet)
tweet = re.sub(r"facilitiesmanagement", "facilities management", tweet)
tweet = re.sub(r"facilitydude", "facility dude", tweet)
tweet = re.sub(r"CampLogistics", "Camp logistics", tweet)
tweet = re.sub(r"alaskapublic", "Alaska public", tweet)
tweet = re.sub(r"MarketResearch", "Market Research", tweet)
tweet = re.sub(r"AccuracyEsports", "Accuracy Esports", tweet)
tweet = re.sub(r"TheBodyShopAust", "The Body Shop Australia", tweet)
tweet = re.sub(r"yychail", "Calgary hail", tweet)
tweet = re.sub(r"yyctraffic", "Calgary traffic", tweet)
tweet = re.sub(r"eliotschool", "eliot school", tweet)
tweet = re.sub(r"TheBrokenCity", "The Broken City", tweet)
tweet = re.sub(r"OldsFireDept", "Olds Fire Department", tweet)
tweet = re.sub(r"RiverComplex", "River Complex", tweet)
tweet = re.sub(r"fieldworksmells", "field work smells", tweet)
tweet = re.sub(r"IranElection", "Iran Election", tweet)
tweet = re.sub(r"glowng", "glowing", tweet)
tweet = re.sub(r"kindlng", "kindling", tweet)
tweet = re.sub(r"riggd", "rigged", tweet)
tweet = re.sub(r"slownewsday", "slow news day", tweet)
tweet = re.sub(r"MyanmarFlood", "Myanmar Flood", tweet)
tweet = re.sub(r"abc7chicago", "ABC 7 Chicago", tweet)
tweet = re.sub(r"copolitics", "Colorado Politics", tweet)
tweet = re.sub(r"AdilGhumro", "Adil Ghumro", tweet)
tweet = re.sub(r"netbots", "net bots", tweet)
tweet = re.sub(r"byebyeroad", "bye bye road", tweet)
tweet = re.sub(r"massiveflooding", "massive flooding", tweet)
tweet = re.sub(r"EndofUS", "End of United States", tweet)
tweet = re.sub(r"35PM", "35 PM", tweet)
tweet = re.sub(r"greektheatrela", "Greek Theatre Los Angeles", tweet)
tweet = re.sub(r"76mins", "76 minutes", tweet)
tweet = re.sub(r"publicsafetyfirst", "public safety first", tweet)
tweet = re.sub(r"livesmatter", "lives matter", tweet)
tweet = re.sub(r"myhometown", "my hometown", tweet)
tweet = re.sub(r"tankerfire", "tanker fire", tweet)
tweet = re.sub(r"MEMORIALDAY", "memorial day", tweet)
tweet = re.sub(r"MEMORIAL_DAY", "memorial day", tweet)
tweet = re.sub(r"instaxbooty", "instagram booty", tweet)
tweet = re.sub(r"Jerusalem_Post", "Jerusalem Post", tweet)
tweet = re.sub(r"WayneRooney_INA", "Wayne Rooney", tweet)
tweet = re.sub(r"VirtualReality", "Virtual Reality", tweet)
tweet = re.sub(r"OculusRift", "Oculus Rift", tweet)
tweet = re.sub(r"OwenJones84", "Owen Jones", tweet)
tweet = re.sub(r"jeremycorbyn", "Jeremy Corbyn", tweet)
tweet = re.sub(r"paulrogers002", "Paul Rogers", tweet)
tweet = re.sub(r"mortalkombatx", "Mortal Kombat X", tweet)
tweet = re.sub(r"mortalkombat", "Mortal Kombat", tweet)
tweet = re.sub(r"FilipeCoelho92", "Filipe Coelho", tweet)
tweet = re.sub(r"OnlyQuakeNews", "Only Quake News", tweet)
tweet = re.sub(r"kostumes", "costumes", tweet)
tweet = re.sub(r"YEEESSSS", "yes", tweet)
tweet = re.sub(r"ToshikazuKatayama", "Toshikazu Katayama", tweet)
tweet = re.sub(r"IntlDevelopment", "Intl Development", tweet)
tweet = re.sub(r"ExtremeWeather", "Extreme Weather", tweet)
tweet = re.sub(r"WereNotGruberVoters", "We are not gruber voters", tweet)
tweet = re.sub(r"NewsThousands", "News Thousands", tweet)
tweet = re.sub(r"EdmundAdamus", "Edmund Adamus", tweet)
tweet = re.sub(r"EyewitnessWV", "Eye witness WV", tweet)
tweet = re.sub(r"PhiladelphiaMuseu", "Philadelphia Museum", tweet)
tweet = re.sub(r"DublinComicCon", "Dublin Comic Con", tweet)
tweet = re.sub(r"NicholasBrendon", "Nicholas Brendon", tweet)
tweet = re.sub(r"Alltheway80s", "All the way 80s", tweet)
tweet = re.sub(r"FromTheField", "From the field", tweet)
tweet = re.sub(r"NorthIowa", "North Iowa", tweet)
tweet = re.sub(r"WillowFire", "Willow Fire", tweet)
tweet = re.sub(r"MadRiverComplex", "Mad River Complex", tweet)
tweet = re.sub(r"feelingmanly", "feeling manly", tweet)
tweet = re.sub(r"stillnotoverit", "still not over it", tweet)
tweet = re.sub(r"FortitudeValley", "Fortitude Valley", tweet)
tweet = re.sub(r"CoastpowerlineTramTr", "Coast powerline", tweet)
tweet = re.sub(r"ServicesGold", "Services Gold", tweet)
tweet = re.sub(r"NewsbrokenEmergency", "News broken emergency", tweet)
tweet = re.sub(r"Evaucation", "evacuation", tweet)
tweet = re.sub(r"leaveevacuateexitbe", "leave evacuate exit be", tweet)
tweet = re.sub(r"P_EOPLE", "PEOPLE", tweet)
tweet = re.sub(r"Tubestrike", "tube strike", tweet)
tweet = re.sub(r"CLASS_SICK", "CLASS SICK", tweet)
tweet = re.sub(r"localplumber", "local plumber", tweet)
tweet = re.sub(r"awesomejobsiri", "awesome job siri", tweet)
tweet = re.sub(r"PayForItHow", "Pay for it how", tweet)
tweet = re.sub(r"ThisIsAfrica", "This is Africa", tweet)
tweet = re.sub(r"crimeairnetwork", "crime air network", tweet)
tweet = re.sub(r"KimAcheson", "Kim Acheson", tweet)
tweet = re.sub(r"cityofcalgary", "City of Calgary", tweet)
tweet = re.sub(r"prosyndicate", "pro syndicate", tweet)
tweet = re.sub(r"660NEWS", "660 NEWS", tweet)
tweet = re.sub(r"BusInsMagazine", "Business Insurance Magazine", tweet)
tweet = re.sub(r"wfocus", "focus", tweet)
tweet = re.sub(r"ShastaDam", "Shasta Dam", tweet)
tweet = re.sub(r"go2MarkFranco", "Mark Franco", tweet)
tweet = re.sub(r"StephGHinojosa", "Steph Hinojosa", tweet)
tweet = re.sub(r"Nashgrier", "Nash Grier", tweet)
tweet = re.sub(r"NashNewVideo", "Nash new video", tweet)
tweet = re.sub(r"IWouldntGetElectedBecause", "I would not get elected because", tweet)
tweet = re.sub(r"SHGames", "Sledgehammer Games", tweet)
tweet = re.sub(r"bedhair", "bed hair", tweet)
tweet = re.sub(r"JoelHeyman", "Joel Heyman", tweet)
tweet = re.sub(r"viaYouTube", "via YouTube", tweet)
# Urls
tweet = re.sub(r"https?:\/\/t.co\/[A-Za-z0-9]+", "", tweet)
# Words with punctuations and special characters
punctuations = '@#!?+&*[]-%.:/();$=><|{}^' + "'`"
for p in punctuations:
tweet = tweet.replace(p, f' {p} ')
# ... and ..
tweet = tweet.replace('...', ' ... ')
if '...' not in tweet:
tweet = tweet.replace('..', ' ... ')
# Acronyms
tweet = re.sub(r"MH370", "Malaysia Airlines Flight 370", tweet)
tweet = re.sub(r"m̼sica", "music", tweet)
tweet = re.sub(r"okwx", "Oklahoma City Weather", tweet)
tweet = re.sub(r"arwx", "Arkansas Weather", tweet)
tweet = re.sub(r"gawx", "Georgia Weather", tweet)
tweet = re.sub(r"scwx", "South Carolina Weather", tweet)
tweet = re.sub(r"cawx", "California Weather", tweet)
tweet = re.sub(r"tnwx", "Tennessee Weather", tweet)
tweet = re.sub(r"azwx", "Arizona Weather", tweet)
tweet = re.sub(r"alwx", "Alabama Weather", tweet)
tweet = re.sub(r"wordpressdotcom", "wordpress", tweet)
tweet = re.sub(r"usNWSgov", "United States National Weather Service", tweet)
tweet = re.sub(r"Suruc", "Sanliurfa", tweet)
# Grouping same words without embeddings
tweet = re.sub(r"Bestnaijamade", "bestnaijamade", tweet)
tweet = re.sub(r"SOUDELOR", "Soudelor", tweet)
return tweet
df_train['text_cleaned'] = df_train['text'].apply(lambda s : clean(s))
df_test['text_cleaned'] = df_test['text'].apply(lambda s : clean(s))
train_glove_oov, train_glove_vocab_coverage, train_glove_text_coverage = check_embeddings_coverage(df_train['text_cleaned'], glove_embeddings)
test_glove_oov, test_glove_vocab_coverage, test_glove_text_coverage = check_embeddings_coverage(df_test['text_cleaned'], glove_embeddings)
print('GloVe Embeddings cover {:.2%} of vocabulary and {:.2%} of text in Training Set'.format(train_glove_vocab_coverage, train_glove_text_coverage))
print('GloVe Embeddings cover {:.2%} of vocabulary and {:.2%} of text in Test Set'.format(test_glove_vocab_coverage, test_glove_text_coverage))
train_fasttext_oov, train_fasttext_vocab_coverage, train_fasttext_text_coverage = check_embeddings_coverage(df_train['text_cleaned'], fasttext_embeddings)
test_fasttext_oov, test_fasttext_vocab_coverage, test_fasttext_text_coverage = check_embeddings_coverage(df_test['text_cleaned'], fasttext_embeddings)
print('FastText Embeddings cover {:.2%} of vocabulary and {:.2%} of text in Training Set'.format(train_fasttext_vocab_coverage, train_fasttext_text_coverage))
print('FastText Embeddings cover {:.2%} of vocabulary and {:.2%} of text in Test Set'.format(test_fasttext_vocab_coverage, test_fasttext_text_coverage))GloVe Embeddings cover 82.89% of vocabulary and 97.14% of text in Training Set GloVe Embeddings cover 88.09% of vocabulary and 97.32% of text in Test Set FastText Embeddings cover 82.88% of vocabulary and 97.12% of text in Training Set FastText Embeddings cover 87.80% of vocabulary and 97.25% of text in Test Set CPU times: user 8min 27s, sys: 211 ms, total: 8min 28s Wall time: 8min 30s Parser : 156 ms
清理推文后,由于它们消耗太多内存(10+ GB),因此被删除并被垃圾回收。glove_embeddingsfasttext_embeddings
#垃圾回收
del glove_embeddings, fasttext_embeddings, train_glove_oov, test_glove_oov, train_fasttext_oov, test_fasttext_oov
gc.collect()0
5. 错误标记的例子
训练集中有 18 条独特的推文,它们的副本中标记不同。这些推文可能被不同的人标记,他们对含义的解释不同,因为其中一些不是很清楚。具有两个唯一 target值的推文将被重新标记,因为它们可能会影响训练分数。
df_mislabeled = df_train.groupby(['text']).nunique().sort_values(by='target', ascending=False)
df_mislabeled = df_mislabeled[df_mislabeled['target'] > 1]['target']
df_mislabeled.index.tolist()['like for the music video I want some real action shit like burning buildings and police chases not some weak ben winston shit', 'Hellfire! We don\x89Ûªt even want to think about it or mention it so let\x89Ûªs not do anything that leads to it #islam!', "The Prophet (peace be upon him) said 'Save yourself from Hellfire even if it is by giving half a date in charity.'", 'In #islam saving a person is equal in reward to saving all humans! Islam is the opposite of terrorism!', 'To fight bioterrorism sir.', 'Who is bringing the tornadoes and floods. Who is bringing the climate change. God is after America He is plaguing her\n \n#FARRAKHAN #QUOTE', '#foodscare #offers2go #NestleIndia slips into loss after #Magginoodle #ban unsafe and hazardous for #humanconsumption', '#Allah describes piling up #wealth thinking it would last #forever as the description of the people of #Hellfire in Surah Humaza. #Reflect', 'He came to a land which was engulfed in tribal war and turned it into a land of peace i.e. Madinah. #ProphetMuhammad #islam', 'RT NotExplained: The only known image of infamous hijacker D.B. Cooper. http://t.co/JlzK2HdeTG', 'Hellfire is surrounded by desires so be careful and don\x89Ûªt let your desires control you! #Afterlife', 'CLEARED:incident with injury:I-495 inner loop Exit 31 - MD 97/Georgia Ave Silver Spring', "Mmmmmm I'm burning.... I'm burning buildings I'm building.... Oooooohhhh oooh ooh...", 'wowo--=== 12000 Nigerian refugees repatriated from Cameroon', '.POTUS #StrategicPatience is a strategy for #Genocide; refugees; IDP Internally displaced people; horror; etc. https://t.co/rqWuoy1fm4', 'Caution: breathing may be hazardous to your health.', 'I Pledge Allegiance To The P.O.P.E. And The Burning Buildings of Epic City. ??????', 'that horrible sinking feeling when you\x89Ûªve been at home on your phone for a while and you realise its been on 3G this whole time']
df_train['target_relabeled'] = df_train['target'].copy()
df_train.loc[df_train['text'] == 'like for the music video I want some real action shit like burning buildings and police chases not some weak ben winston shit', 'target_relabeled'] = 0
df_train.loc[df_train['text'] == 'Hellfire is surrounded by desires so be careful and donÛªt let your desires control you! #Afterlife', 'target_relabeled'] = 0
df_train.loc[df_train['text'] == 'To fight bioterrorism sir.', 'target_relabeled'] = 0
df_train.loc[df_train['text'] == '.POTUS #StrategicPatience is a strategy for #Genocide; refugees; IDP Internally displaced people; horror; etc. https://t.co/rqWuoy1fm4', 'target_relabeled'] = 1
df_train.loc[df_train['text'] == 'CLEARED:incident with injury:I-495 inner loop Exit 31 - MD 97/Georgia Ave Silver Spring', 'target_relabeled'] = 1
df_train.loc[df_train['text'] == '#foodscare #offers2go #NestleIndia slips into loss after #Magginoodle #ban unsafe and hazardous for #humanconsumption', 'target_relabeled'] = 0
df_train.loc[df_train['text'] == 'In #islam saving a person is equal in reward to saving all humans! Islam is the opposite of terrorism!', 'target_relabeled'] = 0
df_train.loc[df_train['text'] == 'Who is bringing the tornadoes and floods. Who is bringing the climate change. God is after America He is plaguing her\n \n#FARRAKHAN #QUOTE', 'target_relabeled'] = 1
df_train.loc[df_train['text'] == 'RT NotExplained: The only known image of infamous hijacker D.B. Cooper. http://t.co/JlzK2HdeTG', 'target_relabeled'] = 1
df_train.loc[df_train['text'] == "Mmmmmm I'm burning.... I'm burning buildings I'm building.... Oooooohhhh oooh ooh...", 'target_relabeled'] = 0
df_train.loc[df_train['text'] == "wowo--=== 12000 Nigerian refugees repatriated from Cameroon", 'target_relabeled'] = 0
df_train.loc[df_train['text'] == "He came to a land which was engulfed in tribal war and turned it into a land of peace i.e. Madinah. #ProphetMuhammad #islam", 'target_relabeled'] = 0
df_train.loc[df_train['text'] == "Hellfire! We donÛªt even want to think about it or mention it so letÛªs not do anything that leads to it #islam!", 'target_relabeled'] = 0
df_train.loc[df_train['text'] == "The Prophet (peace be upon him) said 'Save yourself from Hellfire even if it is by giving half a date in charity.'", 'target_relabeled'] = 0
df_train.loc[df_train['text'] == "Caution: breathing may be hazardous to your health.", 'target_relabeled'] = 1
df_train.loc[df_train['text'] == "I Pledge Allegiance To The P.O.P.E. And The Burning Buildings of Epic City. ??????", 'target_relabeled'] = 0
df_train.loc[df_train['text'] == "#Allah describes piling up #wealth thinking it would last #forever as the description of the people of #Hellfire in Surah Humaza. #Reflect", 'target_relabeled'] = 0
df_train.loc[df_train['text'] == "that horrible sinking feeling when youÛªve been at home on your phone for a while and you realise its been on 3G this whole time", 'target_relabeled'] = 06. 交叉验证
首先,当训练集/测试集连接起来,并计算推文 keyword计数时,可以看到训练集和测试集被分成 keyword组。我们也可以通过查看 id功能来得出这个结论。这意味着 keyword在创建训练和测试集时,每个都是分层的。我们可以复制相同的拆分以进行交叉验证。
来自每个 keyword组的推文都存在于训练集和测试集中,并且它们来自同一样本。为了复制相同的拆分技术,使用StratifiedKFold,keyword作为y传递,因此根据 keyword特征进行分层。 shuffle设置为 True用于额外的训练多样性。两个折叠都有来自训练和验证集中每个 keyword组的推文,可以从下面看到。
K = 2
skf = StratifiedKFold(n_splits=K, random_state=SEED, shuffle=True)
DISASTER = df_train['target'] == 1
print('Whole Training Set Shape = {}'.format(df_train.shape))
print('Whole Training Set Unique keyword Count = {}'.format(df_train['keyword'].nunique()))
print('Whole Training Set Target Rate (Disaster) {}/{} (Not Disaster)'.format(df_train[DISASTER]['target_relabeled'].count(), df_train[~DISASTER]['target_relabeled'].count()))
for fold, (trn_idx, val_idx) in enumerate(skf.split(df_train['text_cleaned'], df_train['target']), 1):
print('\nFold {} Training Set Shape = {} - Validation Set Shape = {}'.format(fold, df_train.loc[trn_idx, 'text_cleaned'].shape, df_train.loc[val_idx, 'text_cleaned'].shape))
print('Fold {} Training Set Unique keyword Count = {} - Validation Set Unique keyword Count = {}'.format(fold, df_train.loc[trn_idx, 'keyword'].nunique(), df_train.loc[val_idx, 'keyword'].nunique())) Whole Training Set Shape = (7613, 16) Whole Training Set Unique keyword Count = 222 Whole Training Set Target Rate (Disaster) 3271/4342 (Not Disaster) Fold 1 Training Set Shape = (3806,) - Validation Set Shape = (3807,) Fold 1 Training Set Unique keyword Count = 222 - Validation Set Unique keyword Count = 222 Fold 2 Training Set Shape = (3807,) - Validation Set Shape = (3806,) Fold 2 Training Set Unique keyword Count = 222 - Validation Set Unique keyword Count = 222
7. 模型
7.1 评估指标
排行榜基于Mean F-Score,可以使用Macro Average F1 Score.来实现。但是,如果没有准确性,精度和召回率,它就不会提供很多信息,因为类几乎是平衡的,很难说哪个类更难预测。
- 准确度测量正确识别的总样品比例
- 精度衡量在所有预测为正数的示例中,有多少实际上是正数
- 召回率,在所有实际正值中,有多少示例被模型正确分类为正数
- F1 分数是精度和召回率的调和平均值
Keras 在 metrics模块中具有准确性,但没有上述其余指标。另一个关键点是精度、召回率和 F1-Score 是全局指标,因此它们应该在整个训练或验证集上计算。在每个批次上计算它们在执行时间方面既具有误导性又无效。 ClassificationReport这类似于sklearn.metrics.classification_report ,在给定训练和验证集的每个 epoch之后计算这些指标。
class ClassificationReport(Callback):
def __init__(self, train_data=(), validation_data=()):
super(Callback, self).__init__()
self.X_train, self.y_train = train_data
self.train_precision_scores = []
self.train_recall_scores = []
self.train_f1_scores = []
self.X_val, self.y_val = validation_data
self.val_precision_scores = []
self.val_recall_scores = []
self.val_f1_scores = []
def on_epoch_end(self, epoch, logs={}):
train_predictions = np.round(self.model.predict(self.X_train, verbose=0))
train_precision = precision_score(self.y_train, train_predictions, average='macro')
train_recall = recall_score(self.y_train, train_predictions, average='macro')
train_f1 = f1_score(self.y_train, train_predictions, average='macro')
self.train_precision_scores.append(train_precision)
self.train_recall_scores.append(train_recall)
self.train_f1_scores.append(train_f1)
val_predictions = np.round(self.model.predict(self.X_val, verbose=0))
val_precision = precision_score(self.y_val, val_predictions, average='macro')
val_recall = recall_score(self.y_val, val_predictions, average='macro')
val_f1 = f1_score(self.y_val, val_predictions, average='macro')
self.val_precision_scores.append(val_precision)
self.val_recall_scores.append(val_recall)
self.val_f1_scores.append(val_f1)
print('\nEpoch: {} - Training Precision: {:.6} - Training Recall: {:.6} - Training F1: {:.6}'.format(epoch + 1, train_precision, train_recall, train_f1))
print('Epoch: {} - Validation Precision: {:.6} - Validation Recall: {:.6} - Validation F1: {:.6}'.format(epoch + 1, val_precision, val_recall, val_f1)) 7.2 bert层
此模型使用 GitHub 上 TensorFlow Models 存储库中的 BERT 实现,网址为tensorflow/models/official/nlp/bert 。它使用 L=12 个隐藏层(变形金刚块),隐藏大小为 H=768,A=12 个注意头。
该模型已在维基百科和BooksCorpus上进行了英语预训练。输入已“不区分大小写”,这意味着文本在标记化为单词片段之前已小写,并且任何重音标记已被剥离。为了下载此模型,Internet必须在内核上激活。
%%time
bert_layer = hub.KerasLayer('https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/1', trainable=True)CPU times: user 30.6 s, sys: 1.69 s, total: 32.2 s Wall time: 35.1 s
7.3 结构
DisasterDetector是一个包含上述交叉验证和指标的包装器。
输入文本的标记化是使用 中的类执行的。 参数可用于调整文本的序列长度。FullTokenizertensorflow/models/official/nlp/bert/tokenization.pymax_seq_length
参数,如 lr和 epochs、batch_size可用于控制学习过程。在BERT的最后一层之后没有添加密集层或池化层。 SGD用作优化器,因为其他人在收敛时很难。
plot_learning_curve绘制每个时期后存储的准确性、精度、召回率和 F1 分数(用于验证集)以及训练/验证损失曲线。这有助于查看训练时哪个指标波动最大。
class DisasterDetector:
def __init__(self, bert_layer, max_seq_length=128, lr=0.0001, epochs=15, batch_size=32):
# BERT and Tokenization params
self.bert_layer = bert_layer
self.max_seq_length = max_seq_length
vocab_file = self.bert_layer.resolved_object.vocab_file.asset_path.numpy()
do_lower_case = self.bert_layer.resolved_object.do_lower_case.numpy()
self.tokenizer = tokenization.FullTokenizer(vocab_file, do_lower_case)
# Learning control params
self.lr = lr
self.epochs = epochs
self.batch_size = batch_size
self.models = []
self.scores = {}
def encode(self, texts):
all_tokens = []
all_masks = []
all_segments = []
for text in texts:
text = self.tokenizer.tokenize(text)
text = text[:self.max_seq_length - 2]
input_sequence = ['[CLS]'] + text + ['[SEP]']
pad_len = self.max_seq_length - len(input_sequence)
tokens = self.tokenizer.convert_tokens_to_ids(input_sequence)
tokens += [0] * pad_len
pad_masks = [1] * len(input_sequence) + [0] * pad_len
segment_ids = [0] * self.max_seq_length
all_tokens.append(tokens)
all_masks.append(pad_masks)
all_segments.append(segment_ids)
return np.array(all_tokens), np.array(all_masks), np.array(all_segments)
def build_model(self):
input_word_ids = Input(shape=(self.max_seq_length,), dtype=tf.int32, name='input_word_ids')
input_mask = Input(shape=(self.max_seq_length,), dtype=tf.int32, name='input_mask')
segment_ids = Input(shape=(self.max_seq_length,), dtype=tf.int32, name='segment_ids')
pooled_output, sequence_output = self.bert_layer([input_word_ids, input_mask, segment_ids])
clf_output = sequence_output[:, 0, :]
out = Dense(1, activation='sigmoid')(clf_output)
model = Model(inputs=[input_word_ids, input_mask, segment_ids], outputs=out)
optimizer = SGD(learning_rate=self.lr, momentum=0.8)
model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
def train(self, X):
for fold, (trn_idx, val_idx) in enumerate(skf.split(X['text_cleaned'], X['keyword'])):
print('\nFold {}\n'.format(fold))
X_trn_encoded = self.encode(X.loc[trn_idx, 'text_cleaned'].str.lower())
y_trn = X.loc[trn_idx, 'target_relabeled']
X_val_encoded = self.encode(X.loc[val_idx, 'text_cleaned'].str.lower())
y_val = X.loc[val_idx, 'target_relabeled']
# Callbacks
metrics = ClassificationReport(train_data=(X_trn_encoded, y_trn), validation_data=(X_val_encoded, y_val))
# Model
model = self.build_model()
model.fit(X_trn_encoded, y_trn, validation_data=(X_val_encoded, y_val), callbacks=[metrics], epochs=self.epochs, batch_size=self.batch_size)
self.models.append(model)
self.scores[fold] = {
'train': {
'precision': metrics.train_precision_scores,
'recall': metrics.train_recall_scores,
'f1': metrics.train_f1_scores
},
'validation': {
'precision': metrics.val_precision_scores,
'recall': metrics.val_recall_scores,
'f1': metrics.val_f1_scores
}
}
def plot_learning_curve(self):
fig, axes = plt.subplots(nrows=K, ncols=2, figsize=(20, K * 6), dpi=100)
for i in range(K):
# Classification Report curve
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.models[i].history.history['val_accuracy'], ax=axes[i][0], label='val_accuracy')
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.scores[i]['validation']['precision'], ax=axes[i][0], label='val_precision')
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.scores[i]['validation']['recall'], ax=axes[i][0], label='val_recall')
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.scores[i]['validation']['f1'], ax=axes[i][0], label='val_f1')
axes[i][0].legend()
axes[i][0].set_title('Fold {} Validation Classification Report'.format(i), fontsize=14)
# Loss curve
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.models[0].history.history['loss'], ax=axes[i][1], label='train_loss')
sns.lineplot(x=np.arange(1, self.epochs + 1), y=clf.models[0].history.history['val_loss'], ax=axes[i][1], label='val_loss')
axes[i][1].legend()
axes[i][1].set_title('Fold {} Train / Validation Loss'.format(i), fontsize=14)
for j in range(2):
axes[i][j].set_xlabel('Epoch', size=12)
axes[i][j].tick_params(axis='x', labelsize=12)
axes[i][j].tick_params(axis='y', labelsize=12)
plt.show()
def predict(self, X):
X_test_encoded = self.encode(X['text_cleaned'].str.lower())
y_pred = np.zeros((X_test_encoded[0].shape[0], 1))
for model in self.models:
y_pred += model.predict(X_test_encoded) / len(self.models)
return y_pred7.4 训练、评估和预测
clf = DisasterDetector(bert_layer, max_seq_length=128, lr=0.0001, epochs=10, batch_size=32)
clf.train(df_train)Fold 0
Train on 3747 samples, validate on 3866 samples
Epoch 1/10
3744/3747 [============================>.] - ETA: 0s - loss: 0.6147 - accuracy: 0.6755
Epoch: 1 - Training Precision: 0.735408 - Training Recall: 0.719853 - Training F1: 0.723161
Epoch: 1 - Validation Precision: 0.72065 - Validation Recall: 0.709626 - Validation F1: 0.71231
3747/3747 [==============================] - 124s 33ms/sample - loss: 0.6147 - accuracy: 0.6755 - val_loss: 0.5667 - val_accuracy: 0.7243
Epoch 2/10
3744/3747 [============================>.] - ETA: 0s - loss: 0.5228 - accuracy: 0.7487
Epoch: 2 - Training Precision: 0.780094 - Training Recall: 0.756824 - Training F1: 0.761698
Epoch: 2 - Validation Precision: 0.759078 - Validation Recall: 0.74282 - Validation F1: 0.746674
3747/3747 [==============================] - 104s 28ms/sample - loss: 0.5229 - accuracy: 0.7486 - val_loss: 0.5126 - val_accuracy: 0.7584
Epoch 3/10
3744/3747 [============================>.] - ETA: 0s - loss: 0.4697 - accuracy: 0.7842
Epoch: 3 - Training Precision: 0.802989 - Training Recall: 0.785967 - Training F1: 0.790651
Epoch: 3 - Validation Precision: 0.776012 - Validation Recall: 0.76321 - Validation F1: 0.766887
3747/3747 [==============================] - 104s 28ms/sample - loss: 0.4695 - accuracy: 0.7844 - val_loss: 0.4800 - val_accuracy: 0.7763
Epoch 4/10
3744/3747 [============================>.] - ETA: 0s - loss: 0.4334 - accuracy: 0.8098
Epoch: 4 - Training Precision: 0.824896 - Training Recall: 0.809021 - Training F1: 0.813797
Epoch: 4 - Validation Precision: 0.791327 - Validation Recall: 0.779743 - Validation F1: 0.783362
3747/3747 [==============================] - 104s 28ms/sample - loss: 0.4336 - accuracy: 0.8097 - val_loss: 0.4601 - val_accuracy: 0.7915
Epoch 5/10
3744/3747 [============================>.] - ETA: 0s - loss: 0.4089 - accuracy: 0.8224
Epoch: 5 - Training Precision: 0.829625 - Training Recall: 0.824943 - Training F1: 0.82689
Epoch: 5 - Validation Precision: 0.794302 - Validation Recall: 0.792688 - Validation F1: 0.79343
3747/3747 [==============================] - 104s 28ms/sample - loss: 0.4089 - accuracy: 0.8223 - val_loss: 0.4521 - val_accuracy: 0.7982
Epoch 6/10
3744/3747 [============================>.] - ETA: 0s - loss: 0.3908 - accuracy: 0.8339
Epoch: 6 - Training Precision: 0.842125 - Training Recall: 0.832088 - Training F1: 0.835699
Epoch: 6 - Validation Precision: 0.807396 - Validation Recall: 0.801045 - Validation F1: 0.803479
3747/3747 [==============================] - 104s 28ms/sample - loss: 0.3906 - accuracy: 0.8340 - val_loss: 0.4387 - val_accuracy: 0.8094
Epoch 7/10
3744/3747 [============================>.] - ETA: 0s - loss: 0.3759 - accuracy: 0.8446
Epoch: 7 - Training Precision: 0.847563 - Training Recall: 0.842696 - Training F1: 0.844736
Epoch: 7 - Validation Precision: 0.803542 - Validation Recall: 0.801137 - Validation F1: 0.802208
3747/3747 [==============================] - 104s 28ms/sample - loss: 0.3757 - accuracy: 0.8447 - val_loss: 0.4369 - val_accuracy: 0.8070
Epoch 8/10
3744/3747 [============================>.] - ETA: 0s - loss: 0.3630 - accuracy: 0.8486
Epoch: 8 - Training Precision: 0.861135 - Training Recall: 0.846872 - Training F1: 0.85165
Epoch: 8 - Validation Precision: 0.814815 - Validation Recall: 0.805184 - Validation F1: 0.808542
3747/3747 [==============================] - 104s 28ms/sample - loss: 0.3628 - accuracy: 0.8487 - val_loss: 0.4289 - val_accuracy: 0.8151
Epoch 9/10
3744/3747 [============================>.] - ETA: 0s - loss: 0.3511 - accuracy: 0.8560
Epoch: 9 - Training Precision: 0.86844 - Training Recall: 0.848727 - Training F1: 0.854725
Epoch: 9 - Validation Precision: 0.823877 - Validation Recall: 0.808942 - Validation F1: 0.813529
3747/3747 [==============================] - 104s 28ms/sample - loss: 0.3510 - accuracy: 0.8562 - val_loss: 0.4257 - val_accuracy: 0.8210
Epoch 10/10
3744/3747 [============================>.] - ETA: 0s - loss: 0.3410 - accuracy: 0.8600
Epoch: 10 - Training Precision: 0.869806 - Training Recall: 0.863247 - Training F1: 0.865911
Epoch: 10 - Validation Precision: 0.812164 - Validation Recall: 0.808603 - Validation F1: 0.810123
3747/3747 [==============================] - 104s 28ms/sample - loss: 0.3409 - accuracy: 0.8602 - val_loss: 0.4291 - val_accuracy: 0.8151
Fold 1
Train on 3866 samples, validate on 3747 samples
Epoch 1/10
3840/3866 [============================>.] - ETA: 0s - loss: 0.5054 - accuracy: 0.7729
Epoch: 1 - Training Precision: 0.815764 - Training Recall: 0.804803 - Training F1: 0.808484
Epoch: 1 - Validation Precision: 0.853746 - Validation Recall: 0.842676 - Validation F1: 0.84662
3866/3866 [==============================] - 117s 30ms/sample - loss: 0.5046 - accuracy: 0.7734 - val_loss: 0.3908 - val_accuracy: 0.8519
Epoch 2/10
3840/3866 [============================>.] - ETA: 0s - loss: 0.4239 - accuracy: 0.8203
Epoch: 2 - Training Precision: 0.822622 - Training Recall: 0.811898 - Training F1: 0.81557
Epoch: 2 - Validation Precision: 0.859211 - Validation Recall: 0.846799 - Validation F1: 0.851118
3866/3866 [==============================] - 105s 27ms/sample - loss: 0.4234 - accuracy: 0.8205 - val_loss: 0.3709 - val_accuracy: 0.8564
Epoch 3/10
3840/3866 [============================>.] - ETA: 0s - loss: 0.4051 - accuracy: 0.8273
Epoch: 3 - Training Precision: 0.841872 - Training Recall: 0.823046 - Training F1: 0.828554
Epoch: 3 - Validation Precision: 0.865489 - Validation Recall: 0.84647 - Validation F1: 0.8523
3866/3866 [==============================] - 105s 27ms/sample - loss: 0.4036 - accuracy: 0.8280 - val_loss: 0.3642 - val_accuracy: 0.8586
Epoch 4/10
3840/3866 [============================>.] - ETA: 0s - loss: 0.3901 - accuracy: 0.8352
Epoch: 4 - Training Precision: 0.851454 - Training Recall: 0.832404 - Training F1: 0.838074
Epoch: 4 - Validation Precision: 0.865231 - Validation Recall: 0.844051 - Validation F1: 0.85028
3866/3866 [==============================] - 105s 27ms/sample - loss: 0.3895 - accuracy: 0.8357 - val_loss: 0.3609 - val_accuracy: 0.8570
Epoch 5/10
3840/3866 [============================>.] - ETA: 0s - loss: 0.3780 - accuracy: 0.8448
Epoch: 5 - Training Precision: 0.849203 - Training Recall: 0.837934 - Training F1: 0.841904
Epoch: 5 - Validation Precision: 0.863501 - Validation Recall: 0.850847 - Validation F1: 0.855254
3866/3866 [==============================] - 105s 27ms/sample - loss: 0.3779 - accuracy: 0.8451 - val_loss: 0.3576 - val_accuracy: 0.8604
Epoch 6/10
3840/3866 [============================>.] - ETA: 0s - loss: 0.3699 - accuracy: 0.8456
Epoch: 6 - Training Precision: 0.849176 - Training Recall: 0.842553 - Training F1: 0.84519
Epoch: 6 - Validation Precision: 0.858479 - Validation Recall: 0.850394 - Validation F1: 0.853516
3866/3866 [==============================] - 105s 27ms/sample - loss: 0.3687 - accuracy: 0.8461 - val_loss: 0.3581 - val_accuracy: 0.8580
Epoch 7/10
3840/3866 [============================>.] - ETA: 0s - loss: 0.3592 - accuracy: 0.8544
Epoch: 7 - Training Precision: 0.85202 - Training Recall: 0.846708 - Training F1: 0.848912
Epoch: 7 - Validation Precision: 0.854678 - Validation Recall: 0.848688 - Validation F1: 0.851129
3866/3866 [==============================] - 105s 27ms/sample - loss: 0.3583 - accuracy: 0.8549 - val_loss: 0.3585 - val_accuracy: 0.8554
Epoch 8/10
3840/3866 [============================>.] - ETA: 0s - loss: 0.3484 - accuracy: 0.8620
Epoch: 8 - Training Precision: 0.853089 - Training Recall: 0.851629 - Training F1: 0.852318
Epoch: 8 - Validation Precision: 0.853223 - Validation Recall: 0.849866 - Validation F1: 0.851348
3866/3866 [==============================] - 105s 27ms/sample - loss: 0.3488 - accuracy: 0.8616 - val_loss: 0.3633 - val_accuracy: 0.8551
Epoch 9/10
3840/3866 [============================>.] - ETA: 0s - loss: 0.3417 - accuracy: 0.8602
Epoch: 9 - Training Precision: 0.875377 - Training Recall: 0.846498 - Training F1: 0.854106
Epoch: 9 - Validation Precision: 0.872443 - Validation Recall: 0.842787 - Validation F1: 0.850445
3866/3866 [==============================] - 105s 27ms/sample - loss: 0.3415 - accuracy: 0.8606 - val_loss: 0.3592 - val_accuracy: 0.8583
Epoch 10/10
3840/3866 [============================>.] - ETA: 0s - loss: 0.3341 - accuracy: 0.8635
Epoch: 10 - Training Precision: 0.879964 - Training Recall: 0.860556 - Training F1: 0.866622
Epoch: 10 - Validation Precision: 0.863049 - Validation Recall: 0.844368 - Validation F1: 0.850105
3866/3866 [==============================] - 105s 27ms/sample - loss: 0.3328 - accuracy: 0.8645 - val_loss: 0.3545 - val_accuracy: 0.8564clf.plot_learning_curve()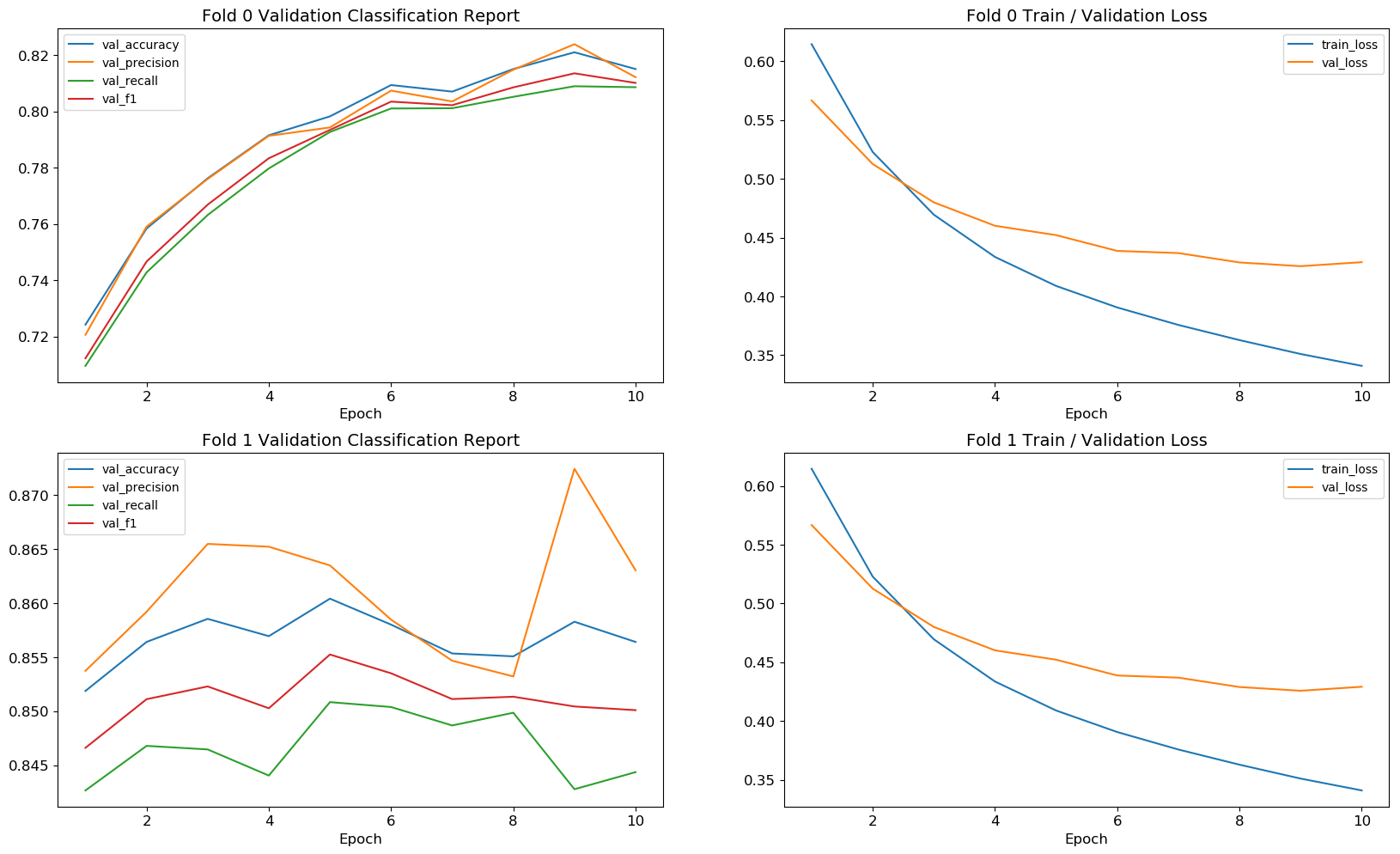
预测
y_pred = clf.predict(df_test)
model_submission = pd.read_csv("/kaggle/input/nlp-getting-started/sample_submission.csv")
model_submission['target'] = np.round(y_pred).astype('int')
model_submission.to_csv('model_submission.csv', index=False)
model_submission.describe()| id | target | |
|---|---|---|
| count | 3263.000000 | 3263.000000 |
| mean | 5427.152927 | 0.361324 |
| std | 3146.427221 | 0.480458 |
| min | 0.000000 | 0.000000 |
| 25% | 2683.000000 | 0.000000 |
| 50% | 5500.000000 | 0.000000 |
| 75% | 8176.000000 | 1.000000 |
| max | 10875.000000 | 1.000000 |
原文地址:NLP with Disaster Tweets - EDA, Cleaning and BERT | Kaggle

















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









