







Kalman filter
前言
最近学习了卡尔曼滤波器,所以整理在上面,之后如果有用到的话再看,这里就不再做前沿的介绍或者别的说明了,如果之后有空的话再做补充吧。最后附上一个扩展卡尔曼滤波器的例子,并附上 Matlab 代码。
公式推导
状态方程
状态方程的例子可以套在绝大多数情况(话不能说满),所以这里也就没有举具体的例子,如果大家想参考相关的例子,可以看最下面的参考连接,推荐哔哩哔哩 Up主 Dr_Can 的视频。
在自动控制原理中,连续系统状态方程表示如下:
X
˙
=
A
X
+
B
u
Y
=
C
X
+
D
u
\begin{aligned} \dot{X} &= AX+Bu\\ Y&=CX+Du \end{aligned}
X˙Y=AX+Bu=CX+Du
其中
X
X
X 为状态变量,
Y
Y
Y 为输出值或是待观测的变量,
u
u
u 为输入,
D
D
D 为输入对输出的直接影响,可以为 0 矩阵,所以上式也通常写为:
X ˙ = A X + B u Y = C X \begin{aligned} \dot{X} &= AX+Bu\\ Y&=CX \end{aligned} X˙Y=AX+Bu=CX
为了实际处理,我们需要将状态方程离散化,离散化后为:
X k = A k X k − 1 + B k u k − 1 Z k = H k X k \begin{aligned} X_k &= A_{k}X_{k-1}+B_ku_{k-1}\\ Z_k &= H_{k}X_{k} \end{aligned} XkZk=AkXk−1+Bkuk−1=HkXk
注意:这里的 A k , B k {A_k},{B_k} Ak,Bk 与离散化之前的值并不相同,要根据实际情况进行离散化。
实际情况中,无论是系统本身,还是观测器都伴随有噪声的影响,这也是要进行卡尔曼滤波的原因,加入噪声后得到如下公式:
真实值:
X k = A k X k − 1 + B k u k − 1 + w k − 1 (1) \tag{1} X_k = A_{k}X_{k-1}+B_ku_{k-1} +w_{k-1} Xk=AkXk−1+Bkuk−1+wk−1(1)
观测值:
Z k = H k X k + V k (2) \tag{2} Z_k = H_{k}X_{k}+V_k Zk=HkXk+Vk(2)
其中
w k − 1 w_{k-1} wk−1 为系统的噪声,符合高斯分布 w k ∼ N ( 0 , Q k ) w_k \sim N(0,Q_k) wk∼N(0,Qk)
v k v_k vk 为测量噪声,符合高斯分布 v k ∼ N ( 0 , R k ) v_k \sim N(0,R_k) vk∼N(0,Rk)
预测值:
X ^ k − = A k X ^ k − 1 + B k u k (3) \tag{3} {\mathbf{\hat{X}}_k^-} = {A_k}{\mathbf{\hat{X}}_{k-1}} + {B_k}{u_k} X^k−=AkX^k−1+Bkuk(3)
注: 因为无法知道 w k w_{k} wk 的值,所以我们无法知道真实值 X k X_k Xk 的具体位置,但忽略噪声影响的预测值(先验估计值) X ^ k − {\mathbf{\hat{X}}_k^-} X^k− ,可以通过带入上一次的计算值(后验估计值) X ^ k − 1 {\hat{X}}_{k-1} X^k−1得出。我们通过预测值,就得到了关于 真实值 X k X_k Xk 的高斯分布预测 真实值 X k ∼ N ( X ^ k − , P k − ) X_k\sim N({{\hat{X}}_k^-},P_k^-) Xk∼N(X^k−,Pk−)
其中
P
k
−
P_k^-
Pk− 为先验估计的协方差矩阵
P
k
−
=
E
(
e
k
−
,
e
k
−
T
)
e
k
−
=
(
X
k
−
X
^
k
−
)
\begin{aligned} {P_k^-} &= E(e_k^-,e_k^{-T})\\ e{_k^-} &= (X_{k}-{\hat{X}_k^-})\\ \end{aligned}
Pk−ek−=E(ek−,ek−T)=(Xk−X^k−)
先验估计误差
e
k
−
e{_k^-}
ek−
e
k
−
=
X
k
−
X
^
k
−
=
A
X
k
−
1
+
B
u
k
−
1
+
w
k
−
1
−
(
A
X
^
k
−
1
+
B
u
k
−
1
)
=
A
(
X
k
−
1
−
X
^
k
−
1
)
+
w
k
−
1
=
A
e
k
−
1
+
w
k
−
1
\begin{aligned} e{_k^-}&=X_{k}-{\hat{X}_k^-}\\ &= AX_{k-1}+Bu_{k-1}+w_{k-1}-(A\hat{X}_{k-1}+Bu_{k-1})\\ &= A(X_{k-1}-\hat{X}_{k-1})+w_{k-1}\\ &= Ae_{k-1}+w_{k-1} \end{aligned}
ek−=Xk−X^k−=AXk−1+Buk−1+wk−1−(AX^k−1+Buk−1)=A(Xk−1−X^k−1)+wk−1=Aek−1+wk−1
其中
e
k
−
1
−
e^-_{k-1}
ek−1− 为后验误差
先验估计误差的协方差矩阵
P
k
−
{P_k^-}
Pk−:
P
k
−
=
E
(
e
k
−
,
e
k
−
T
)
=
E
[
(
A
e
k
−
1
+
w
k
−
1
)
(
A
e
k
−
1
+
w
k
−
1
)
T
]
=
E
[
(
A
e
k
−
1
+
w
k
−
1
)
(
e
k
−
1
T
A
T
+
w
k
−
1
T
)
]
=
E
[
A
e
k
−
1
e
k
−
1
T
A
T
+
A
e
k
−
1
w
k
−
1
T
+
w
k
−
1
e
k
−
1
T
A
T
+
w
k
−
1
w
k
−
1
T
]
=
A
E
(
e
k
−
1
e
k
−
1
T
)
A
T
+
A
E
(
e
k
−
1
w
k
−
1
T
)
+
E
(
w
k
−
1
e
k
−
1
T
)
A
T
+
E
(
w
k
−
1
w
k
−
1
T
)
\begin{aligned} {P_k^-}&= E(e_k^-,e_k^{-T})\\ &= E[(Ae_{k-1}+w_{k-1})(Ae_{k-1}+w_{k-1})^T]\\ &= E[(Ae_{k-1}+w_{k-1})({e^T_{k-1}}A^T+w^T_{k-1})]\\ &= E[Ae_{k-1}{e^T_{k-1}}A^T+Ae_{k-1}w^T_{k-1}+w_{k-1}{e^T_{k-1}}A^T+w_{k-1}w^T_{k-1}]\\ &= AE(e_{k-1}{e^T_{k-1}})A^T+AE(e_{k-1}w^T_{k-1})+E(w_{k-1}{e^T_{k-1}})A^T+E(w_{k-1}w^T_{k-1})\\ \end{aligned}
Pk−=E(ek−,ek−T)=E[(Aek−1+wk−1)(Aek−1+wk−1)T]=E[(Aek−1+wk−1)(ek−1TAT+wk−1T)]=E[Aek−1ek−1TAT+Aek−1wk−1T+wk−1ek−1TAT+wk−1wk−1T]=AE(ek−1ek−1T)AT+AE(ek−1wk−1T)+E(wk−1ek−1T)AT+E(wk−1wk−1T)
其中 由于
e
k
−
1
e_{k-1}
ek−1 与
w
k
−
1
w_{k-1}
wk−1 相互独立,所以
A
E
(
e
k
−
1
w
k
−
1
T
)
AE(e_{k-1}w^T_{k-1})
AE(ek−1wk−1T)、
E
(
w
k
−
1
e
k
−
1
T
)
A
T
E(w_{k-1}{e^T_{k-1}})A^T
E(wk−1ek−1T)AT 两项为
0
0
0 。
E
(
w
k
−
1
w
k
−
1
T
)
=
Q
k
−
1
E(w_{k-1}w^T_{k-1}) = Q_{k-1}
E(wk−1wk−1T)=Qk−1
E
(
e
k
−
1
e
k
−
1
T
)
=
P
k
−
1
E(e_{k-1}{e^T_{k-1}}) = P_{k-1}
E(ek−1ek−1T)=Pk−1 ,所以上式可简化为:
P
k
−
=
A
P
k
−
1
A
T
+
Q
k
−
1
(4)
\tag{4} {P_k^-}= AP_{k-1}A^T+Q_{k-1}
Pk−=APk−1AT+Qk−1(4)
对于观测值
Z
k
=
H
k
X
k
+
V
k
Z_k = H_{k}X_{k}+V_k
Zk=HkXk+Vk
Z
k
=
H
k
X
k
+
V
k
H
k
X
k
=
Z
k
−
V
k
X
k
=
H
k
−
1
(
Z
k
−
V
k
)
\begin{aligned} Z_k &= H_{k}X_{k}+V_k\\ H_{k}X_{k} &= Z_k-V_k\\ X_{k} &= {H_{k}^{-1}}(Z_k-V_k)\\ \end{aligned}
ZkHkXkXk=HkXk+Vk=Zk−Vk=Hk−1(Zk−Vk)
由于无法建模观测噪声
V
k
V_k
Vk 的影响,所以
X
m
e
a
_
k
=
H
k
−
1
Z
k
X_{mea\_k} = {H_{k}^{-1}}Z_k
Xmea_k=Hk−1Zk
数据融合
至此,我们就知道了两个数据来源,一个是我们根据 公式 3 进行的预测值,一个是我们根据观测获得的测量值,这两个值都有误差,且误差都服从高斯分布,这就需要我们通过数据融合的思想,来获取更为精确的数据。
后验估计
采用数据融合的思想,新的预测数据
X
^
k
\hat{X}_{k}
X^k 由下式获得:
X
^
k
=
X
^
k
−
+
G
k
(
X
m
e
a
_
k
−
X
^
k
−
)
=
X
^
k
−
+
G
k
(
H
k
−
1
Z
k
−
X
^
k
−
)
令
G
k
=
K
k
H
k
=
X
^
k
−
+
K
k
H
k
(
H
k
−
1
Z
k
−
X
^
k
−
)
=
X
^
k
−
+
K
k
(
Z
k
−
H
k
X
^
k
−
)
\begin{aligned} {\hat{X}_{k}}&={\hat{X}_k^-}+{G_k}(X_{mea\_k}-{\hat{X}_k^-})\\ &={\hat{X}_k^-}+{G_k}({H_{k}^{-1}}Z_k-{\hat{X}_k^-})\\\\ &令 G_k = {K_k}{H_{k}}\\ &={\hat{X}_k^-}+{K_k}{H_{k}}({H_{k}^{-1}}Z_k-{\hat{X}_k^-})\\ &={\hat{X}_k^-}+{K_k}(Z_k-{H_{k}}{\hat{X}_k^-})\\ \end{aligned}
X^k=X^k−+Gk(Xmea_k−X^k−)=X^k−+Gk(Hk−1Zk−X^k−)令Gk=KkHk=X^k−+KkHk(Hk−1Zk−X^k−)=X^k−+Kk(Zk−HkX^k−)
X ^ k = X ^ k − + K k ( Z k − H k X ^ k − ) (5) \tag{5} {\hat{X}_{k}}={\hat{X}_k^-}+{K_k}(Z_k-{H_{k}}{\hat{X}_k^-})\\ X^k=X^k−+Kk(Zk−HkX^k−)(5)
则Kalman Gain
K
k
K_k
Kk 的取值范围为:
K
k
∈
[
0
,
H
k
−
1
]
w
h
e
n
:
K
k
=
0
,
X
^
k
=
X
^
k
−
w
h
e
n
:
K
k
=
H
k
−
1
,
X
^
k
=
X
m
e
a
_
k
\begin{aligned} &K_k\in[0,H{_k^{-1}}]\\ when:&K_k = 0,&\hat{X}_{k}&={\hat{X}_k^-}\\ when :&K_k = H{_k^{-1}},&\hat{X}_{k}&=X_{mea\_k} \end{aligned}
when:when:Kk∈[0,Hk−1]Kk=0,Kk=Hk−1,X^kX^k=X^k−=Xmea_k
这样就变成如下目标,寻找
K
k
K_k
Kk 值,使得后验误差
X
k
−
X
^
k
X_k-\hat{X}_k
Xk−X^k 误差最小。
e
k
=
X
k
−
X
^
k
e_k=X_k-\hat{X}_k
ek=Xk−X^k
后验误差的协方差矩阵
P k = E ( e , e T ) = [ σ e 1 2 σ e 1 e 2 σ e 2 e 1 σ e 2 2 ] P_k=E(e,e^T)= \begin{bmatrix} \sigma_{e_1}^2 & \sigma_{e_1e_2} \\ \sigma_{e_2e_1} & \sigma_{e_2}^2 \\ \end{bmatrix} Pk=E(e,eT)=[σe12σe2e1σe1e2σe22]
希望误差最小,既
X
^
k
\hat{X}_k
X^k 越接近
X
k
X_k
Xk ,既方差最小,既
P
k
P_k
Pk 的
t
r
(
P
k
)
tr(P_k)
tr(Pk) 最小。
X
k
−
X
^
k
=
X
k
−
X
^
k
−
−
K
k
(
Z
k
−
H
k
X
^
k
−
)
=
X
k
−
X
^
k
−
−
K
k
Z
k
+
K
k
H
k
X
^
k
−
=
X
k
−
X
^
k
−
−
K
k
(
H
k
X
k
+
V
k
)
+
K
k
H
k
X
^
k
−
=
X
k
−
X
^
k
−
−
K
k
H
k
X
k
−
K
k
V
k
+
K
k
H
k
X
^
k
−
=
(
X
k
−
X
^
k
−
)
−
K
k
H
k
(
X
k
−
X
^
k
−
)
−
K
k
V
k
=
(
I
−
K
k
H
k
)
(
X
k
−
X
^
k
−
)
−
K
k
V
k
=
(
I
−
K
k
H
k
)
e
k
−
−
K
k
V
k
\begin{aligned} X_k-\hat{X}_k&= X_k-{\hat{X}_k^-}-{K_k}({Z_k}-{H_k}{\hat{X}_k^-})\\ &= X_k-{\hat{X}_k^-}-{K_k}{Z_k}+{K_k}{H_k}{\hat{X}_k^-}\\ &= X_k-{\hat{X}_k^-}-{K_k}({H_k}{X_k}+{V_k})+{K_k}{H_k}{\hat{X}_k^-}\\ &= X_k-{\hat{X}_k^-}-{K_k}{H_k}{X_k}-{K_k}{V_k}+{K_k}{H_k}{\hat{X}_k^-}\\ &= (X_k-{\hat{X}_k^-})-{K_k}{H_k}({X_k}-{\hat{X}_k^-})-{K_k}{V_k}\\ &= (I-{K_k}{H_k})({X_k}-{\hat{X}_k^-})-{K_k}{V_k}\\ &= (I-{K_k}{H_k}){e_k^-}-{K_k}{V_k}\\ \end{aligned}
Xk−X^k=Xk−X^k−−Kk(Zk−HkX^k−)=Xk−X^k−−KkZk+KkHkX^k−=Xk−X^k−−Kk(HkXk+Vk)+KkHkX^k−=Xk−X^k−−KkHkXk−KkVk+KkHkX^k−=(Xk−X^k−)−KkHk(Xk−X^k−)−KkVk=(I−KkHk)(Xk−X^k−)−KkVk=(I−KkHk)ek−−KkVk
协方差矩阵:
P
k
=
E
(
e
,
e
T
)
=
E
(
(
X
k
−
X
^
k
)
(
X
k
−
X
^
k
)
T
)
=
E
(
(
I
−
K
k
H
k
)
e
k
−
−
K
k
V
k
)
(
(
I
−
K
k
H
k
)
e
k
−
−
K
k
V
k
)
T
)
=
E
(
(
I
−
K
k
H
k
)
e
k
−
−
K
k
V
k
)
(
e
k
−
T
(
I
−
K
k
H
k
)
T
−
V
k
T
K
k
T
)
T
)
=
E
(
(
I
−
K
k
H
k
)
e
k
−
e
k
−
T
(
I
−
K
k
H
k
)
T
−
(
I
−
K
k
H
k
)
e
k
−
V
k
T
K
k
T
−
K
k
V
k
e
k
−
T
(
I
−
K
k
H
k
)
T
+
K
k
V
k
V
k
T
K
k
T
)
=
E
(
(
I
−
K
k
H
k
)
e
k
−
e
k
−
T
(
I
−
K
k
H
k
)
T
)
−
E
(
(
I
−
K
k
H
k
)
e
k
−
V
k
T
K
k
T
)
−
E
(
K
k
V
k
e
k
−
T
(
I
−
K
k
H
k
)
T
)
+
E
(
K
k
V
k
V
k
T
K
k
T
)
\begin{aligned} P_k &= E(e,e^T)\\ &= E(({X_k}-{\hat{X}_k})({X_k}-{\hat{X}_k})^T)\\ &= E((I-{K_k}{H_k}){e_k^-}-{K_k}{V_k})((I-{K_k}{H_k}){e_k^-}-{K_k}{V_k})^T)\\ &= E((I-{K_k}{H_k}){e_k^-}-{K_k}{V_k})({{e_k^-}^T}(I-{K_k}{H_k})^T-{V_k^T}{K_k^T})^T)\\ &= E((I-{K_k}{H_k}){e_k^-}{{e_k^-}^T}(I-{K_k}{H_k})^T-(I-{K_k}{H_k}){e_k^-}{V_k^T}{K_k^T} -{K_k}{V_k}{{e_k^-}^T}(I-{K_k}{H_k})^T+{K_k}{V_k}{V_k^T}{K_k^T})\\ &= E((I-{K_k}{H_k}){e_k^-}{{e_k^-}^T}(I-{K_k}{H_k})^T) - E((I-{K_k}{H_k}){e_k^-}{V_k^T}{K_k^T}) - E({K_k}{V_k}{{e_k^-}^T}(I-{K_k}{H_k})^T) + E({K_k}{V_k}{V_k^T}{K_k^T})\\ \end{aligned}
Pk=E(e,eT)=E((Xk−X^k)(Xk−X^k)T)=E((I−KkHk)ek−−KkVk)((I−KkHk)ek−−KkVk)T)=E((I−KkHk)ek−−KkVk)(ek−T(I−KkHk)T−VkTKkT)T)=E((I−KkHk)ek−ek−T(I−KkHk)T−(I−KkHk)ek−VkTKkT−KkVkek−T(I−KkHk)T+KkVkVkTKkT)=E((I−KkHk)ek−ek−T(I−KkHk)T)−E((I−KkHk)ek−VkTKkT)−E(KkVkek−T(I−KkHk)T)+E(KkVkVkTKkT)
其中:
E
(
(
I
−
K
k
H
k
)
e
k
−
V
k
T
K
k
T
)
=
(
I
−
K
k
H
k
)
E
(
e
k
−
V
k
T
)
K
k
T
E
(
K
k
V
k
e
k
−
T
(
I
−
K
k
H
k
)
T
)
=
K
k
E
(
V
k
e
k
−
T
)
(
I
−
K
k
H
k
)
T
E((I-{K_k}{H_k}){e_k^-}{V_k^T}{K_k^T}) = (I-{K_k}{H_k})E({e_k^-}{V_k^T}){K_k^T}\\ E({K_k}{V_k}{{e_k^-}^T}(I-{K_k}{H_k})^T) ={K_k}E({V_k}{{e_k^-}^T})(I-{K_k}{H_k})^T
E((I−KkHk)ek−VkTKkT)=(I−KkHk)E(ek−VkT)KkTE(KkVkek−T(I−KkHk)T)=KkE(Vkek−T)(I−KkHk)T
在
E
(
V
k
e
k
−
T
)
E({V_k}{{e_k^-}^T})
E(Vkek−T) 中
V
k
与
e
k
−
T
{V_k}与{{e_k^-}^T}
Vk与ek−T 相互独立,故上面两个式子都为0.
P
k
=
E
(
e
,
e
T
)
=
E
(
(
I
−
K
k
H
k
)
e
k
−
e
k
−
T
(
I
−
K
k
H
k
)
T
)
+
E
(
K
k
V
k
V
k
T
K
k
T
)
=
(
I
−
K
k
H
k
)
P
k
−
(
I
−
K
k
H
k
)
T
+
K
k
R
k
K
k
T
=
(
P
k
−
−
K
k
H
k
P
k
−
)
(
I
−
K
k
H
k
)
T
+
K
k
R
k
K
k
T
=
P
k
−
−
K
k
H
k
P
k
−
−
P
k
−
H
k
T
K
k
T
+
K
k
H
k
P
k
−
H
k
T
K
k
T
+
K
k
R
k
K
k
T
\begin{aligned} P_k &= E(e,e^T)\\ &= E((I-{K_k}{H_k}){e_k^-}{{e_k^-}^T}(I-{K_k}{H_k})^T) + E({K_k}{V_k}{V_k^T}{K_k^T})\\ &= (I-{K_k}{H_k}){P_k^-}(I-{K_k}{H_k})^T + {K_k}{R_k}{K_k^T}\\ &= ({P_k^-}-{K_k}{H_k}{P_k^-})(I-{K_k}{H_k})^T + {K_k}{R_k}{K_k^T}\\ &= {P_k^-} - {K_k}{H_k}{P_k^-} - {P_k^-}{H_k^T}{K_k^T} + {K_k}{H_k}{P_k^-}{H_k^T}{K_k^T} + {K_k}{R_k}{K_k^T} \end{aligned}
Pk=E(e,eT)=E((I−KkHk)ek−ek−T(I−KkHk)T)+E(KkVkVkTKkT)=(I−KkHk)Pk−(I−KkHk)T+KkRkKkT=(Pk−−KkHkPk−)(I−KkHk)T+KkRkKkT=Pk−−KkHkPk−−Pk−HkTKkT+KkHkPk−HkTKkT+KkRkKkT
协方差矩阵的迹
t r ( P k ) = t r ( P k − ) − t r ( K k H k P k − ) − t r ( P k − H k T K k T ) + t r ( K k H k P k − H k T K k T ) + t r ( K k R k K k T ) = t r ( P k − ) − 2 t r ( K k H k P k − ) + t r ( K k H k P k − H k T K k T ) + t r ( K k R k K k T ) 因为: t r ( A ) = t r ( A T ) ( ( P k − H k T ) K k T ) T = K k H k P k − T P k − 是对称矩阵 P k − = P k − T \begin{aligned} & tr(P_k) &&\\ =& tr({P_k^-}) - tr({K_k}{H_k}{P_k^-}) - tr({P_k^-}{H_k^T}{K_k^T})+ tr({K_k}{H_k}{P_k^-}{H_k^T}{K_k^T}) + tr({K_k}{R_k}{K_k^T})\\ =& tr({P_k^-}) - 2tr({K_k}{H_k}{P_k^-}) + tr({K_k}{H_k}{P_k^-}{H_k^T}{K_k^T}) + tr({K_k}{R_k}{K_k^T})\\ \end{aligned} \begin{aligned} &因为:\\ &tr(A) = tr(A^T)\\ &{(({P_k^-}{H_k^T}){K_k^T})^T}={K_k}{H_k}{{P_k^-}^T}\\ &{P_k^-}是对称矩阵{P_k^-}={{P_k^-}^T} \end{aligned} ==tr(Pk)tr(Pk−)−tr(KkHkPk−)−tr(Pk−HkTKkT)+tr(KkHkPk−HkTKkT)+tr(KkRkKkT)tr(Pk−)−2tr(KkHkPk−)+tr(KkHkPk−HkTKkT)+tr(KkRkKkT)因为:tr(A)=tr(AT)((Pk−HkT)KkT)T=KkHkPk−TPk−是对称矩阵Pk−=Pk−T
求
K
k
K_k
Kk 的最小值,即
t
r
(
P
k
)
tr(P_k)
tr(Pk) 对
K
k
K_k
Kk 求导:
d
(
t
r
(
P
k
)
)
d
(
K
k
)
=
0
−
2
(
H
k
P
k
−
)
T
+
2
K
k
H
k
P
k
−
H
k
T
+
2
K
k
R
k
因为:
d
(
t
r
(
A
B
)
)
d
(
A
)
=
B
T
d
(
t
r
(
A
B
A
T
)
)
d
(
A
)
=
2
A
B
\begin{aligned} &\frac{d(tr(P_k))}{d(K_k)}=0 - 2({H_k}{{P_k^-}})^T+2{K_k}{H_k}{P_k^-}{H_k^T}+2{K_k}{R_k}&&&\\ \end{aligned} \begin{aligned} 因为:&\\ &\frac{d(tr(AB))}{d(A)}=B^T\\ &\frac{d(tr(AB{A^T}))}{d(A)}=2AB\\ \end{aligned}\\
d(Kk)d(tr(Pk))=0−2(HkPk−)T+2KkHkPk−HkT+2KkRk因为:d(A)d(tr(AB))=BTd(A)d(tr(ABAT))=2AB
令
d
(
t
r
(
P
k
)
)
d
(
K
k
)
=
0
\frac{d(tr(P_k))}{d(K_k)}=0
d(Kk)d(tr(Pk))=0
−
2
(
H
k
P
k
−
)
T
+
2
K
k
H
k
P
k
−
H
k
T
+
2
K
k
R
k
=
0
K
k
H
k
P
k
−
H
k
T
+
K
k
R
k
=
(
H
k
P
k
−
)
T
K
k
(
H
k
P
k
−
H
k
T
+
R
k
)
=
P
k
−
T
H
k
T
\begin{aligned} -2({H_k}{{P_k^-}})^T+2{K_k}{H_k}{P_k^-}{H_k^T}+2{K_k}{R_k}&=0&&&&&&&&&&\\ {K_k}{H_k}{P_k^-}{H_k^T}+{K_k}{R_k}&=({H_k}{{P_k^-}})^T\\ {K_k}({H_k}{P_k^-}{H_k^T}+{R_k})&={{P_k^-}^T}{H_k^T}\\ \end{aligned}
−2(HkPk−)T+2KkHkPk−HkT+2KkRkKkHkPk−HkT+KkRkKk(HkPk−HkT+Rk)=0=(HkPk−)T=Pk−THkT
卡尔曼增益
K k = P k − T H k T H k P k − H k T + R k (6) \tag{6} {K_k}=\frac{{{P_k^-}^T}{H_k^T}}{{H_k}{P_k^-}{H_k^T}+{R_k}}\\ Kk=HkPk−HkT+RkPk−THkT(6)
同时:
P
k
=
P
k
−
−
K
k
H
k
P
k
−
−
P
k
−
H
k
T
K
k
T
+
K
k
H
k
P
k
−
H
k
T
K
k
T
+
K
k
R
k
K
k
T
=
P
k
−
−
K
k
H
k
P
k
−
−
P
k
−
H
k
T
K
k
T
+
K
k
(
H
k
P
k
−
H
k
T
+
K
k
R
k
)
K
k
T
=
P
k
−
−
K
k
H
k
P
k
−
−
P
k
−
H
k
T
K
k
T
+
P
k
−
H
k
T
K
k
T
=
P
k
−
−
K
k
H
k
P
k
−
=
(
I
−
K
k
H
k
)
P
k
−
\begin{aligned} P_k &= {P_k^-} - {K_k}{H_k}{P_k^-} - {P_k^-}{H_k^T}{K_k^T} + {K_k}{H_k}{P_k^-}{H_k^T}{K_k^T} + {K_k}{R_k}{K_k^T}\\ &= {P_k^-} - {K_k}{H_k}{P_k^-} - {P_k^-}{H_k^T}{K_k^T} + {K_k}({H_k}{P_k^-}{H_k^T} + {K_k}{R_k}){K_k^T}\\ &= {P_k^-} - {K_k}{H_k}{P_k^-} - {P_k^-}{H_k^T}{K_k^T} + {P_k^-}{H_k^T}{K_k^T}\\ &= {P_k^-} - {K_k}{H_k}{P_k^-}\\ &= (I - {K_k}{H_k}){P_k^-}\\ \end{aligned}
Pk=Pk−−KkHkPk−−Pk−HkTKkT+KkHkPk−HkTKkT+KkRkKkT=Pk−−KkHkPk−−Pk−HkTKkT+Kk(HkPk−HkT+KkRk)KkT=Pk−−KkHkPk−−Pk−HkTKkT+Pk−HkTKkT=Pk−−KkHkPk−=(I−KkHk)Pk−
P k = ( I − K k H k ) P k − (7) \tag{7} P_k = (I - {K_k}{H_k}){P_k^-}\\ Pk=(I−KkHk)Pk−(7)
至此,公式推导结束。
卡尔曼滤波器的使用
-
计算先验估计值
X ^ k − = A k X ^ k − 1 + B k u k {\mathbf{\hat{X}}_k^-} = {A_k}{\mathbf{\hat{X}}_{k-1}} + {B_k}{u_k} X^k−=AkX^k−1+Bkuk -
更新先验误差的协方差矩阵
P k − = A P k − 1 A T + Q k − 1 {P_k^-}= AP_{k-1}A^T+Q_{k-1} Pk−=APk−1AT+Qk−1 -
计算Kalman Gain
K k = P k − T H k T H k P k − H k T + R k {K_k}=\frac{{{P_k^-}^T}{H_k^T}}{{H_k}{P_k^-}{H_k^T}+{R_k}}\\ Kk=HkPk−HkT+RkPk−THkT -
计算后验估计
X ^ k = X ^ k − + K k ( Z k − H k X ^ k − ) {\hat{X}_{k}}={\hat{X}_k^-}+{K_k}(Z_k-{H_{k}}{\hat{X}_k^-}) X^k=X^k−+Kk(Zk−HkX^k−) -
更新误差协方差矩阵
P k = ( I − K k H k ) P k − P_k = (I - {K_k}{H_k}){P_k^-} Pk=(I−KkHk)Pk−
参考
【1】【卡尔曼滤波器】3_卡尔曼增益超详细数学推导 ~全网最完整_哔哩哔哩_bilibili
【5】How a Kalman filter works, in pictures | Bzarg
【6】kalman滤波理解一:理论框架_还差得远呢的博客-CSDN博客
例子
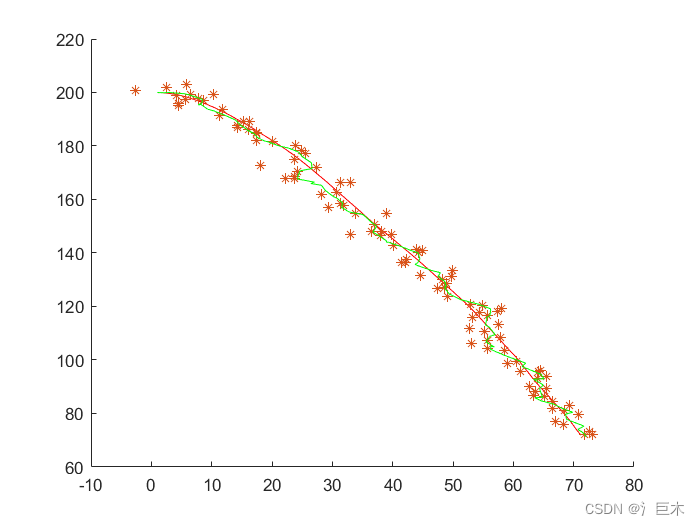
这是一个基于扩展卡尔曼滤波器的例子

clear
clc
%初始参数
%状态函数:
[ x_k v_xk y_k v_yk]'
X = [0 10 200 0]';
t = 10;
T = 0.1;
m = 1;
kx = 0.01;
ky = 0.05;
g = -9.8;
Status = [T,g,m,kx,ky];
I = eye(4);
H = zeros(2,4);
% 初始的误差协方差矩阵
P_k1 = zeros(4,4);
% 噪声
Q = zeros(4,4);
Q(2,2) = 5;
Q(4,4) = 5;
R = eye(2);
R(1,1) = 0.0004;
R(2,2) = 3;
P_k1,Q,R
X_real = X;
X_real1 = X;
X_head1 = X;
X_headp = zeros(4,1);
X_head = zeros(4,1);
XY = zeros(t/T,4);
ZZ = zeros(t/T,2);
%生成 A,H 矩阵
A = [1 T 0 0;
0 1-2*T/m*kx*X(2) 0 0;
0 0 1 T;
0 0 0 1+2*T/m*ky*X(4)];
H = zeros(2,4);
%迭代计算
rng(10);
for i = 1: t/T
% 构造真实值
X_real = CreatRealDatas(X_real1, Status, Q);
% 构造观测值
Zk = CreatObserveDatas(X_real, R);
% 计算先验值
X_headp = CalculatePriorValue(X_head1, Status);
% 更新 A H 矩阵
[A, H] = UpdateAHmatrix(X_head1, Status);
% 误差协方差矩阵 Pk 的先验值
Pkp = A*P_k1*A' + Q;
% 计算 Kalman Gain
Kk = Pkp*H'*(H*Pkp*H'+ R)^-1;
% 计算 后验估计
ZZ_a = atan(X_headp(1)/X_headp(3));
ZZ_r = sqrt(X_headp(1)^2 + X_headp(3)^2);
abc = [ZZ_a,ZZ_r]';
% X_head = X_headp + Kk*(Zk - H*X_headp);
X_head = X_headp + Kk*(Zk - abc);
% 更新误差的协方差矩阵
Pk = (I - Kk*H)*Pkp;
%数据更新
X_real1 = X_real;
X_head1 = X_head;
P_k1 = Pk;
XY(i,:) = X_real;
Xh(i,:) = X_head;
ZZ(i,:) = Zk;
end
%绘制图像
figure(1)
hold on
ZZ2 = [ZZ(:,2).*sin(ZZ(:,1)),ZZ(:,2).*cos(ZZ(:,1))];
plot(XY(:,1),XY(:,3),'r');
plot(ZZ2(:,1),ZZ2(:,2),'*');
plot(Xh(:,1),Xh(:,3),'g');
figure(2)
hold on
plot(XY(:,2),'r')
plot(XY(:,4),'b')
函数创建
- 构造真实值
function X_real = CreatRealDatas(X_real1, Status, Q)
X_k1 = X_real1(1); V_xk1 = X_real1(2); Y_k1 = X_real1(3); V_yk1 = X_real1(4);
T = Status(1); g = Status(2); m = Status(3); kx =Status(4); ky = Status(5);
X_k = X_k1 + T*V_xk1;
if V_xk1 >= 0
V_xk = V_xk1 - T/m*kx * V_xk1*V_xk1 + Q(2,2)^0.5*randn(1)*T;
else
V_xk = V_xk1 + T/m*kx * V_xk1*V_xk1 + Q(2,2)^0.5*randn(1)*T;
end
Y_k = Y_k1 + T*V_yk1;
if V_yk1 >= 0
V_yk = V_yk1 + T*g - T/m*ky * V_yk1*V_yk1 + Q(4,4)^0.5*randn(1)*T;
else
V_yk = V_yk1 + T*g + T/m*ky * V_yk1*V_yk1 + Q(4,4)^0.5*randn(1)*T;
end
X_real = [X_k V_xk Y_k V_yk]';
end
- 构造观测值
function Zk = CreatObserveDatas(X_real, R)
X_k = X_real(1); Y_k = X_real(3);
Z_a = atan(X_k/Y_k) + R(1,1)^0.5*randn(1);
Z_r = sqrt(X_k^2 + Y_k^2) + R(2,2)^0.5*randn(1);
Zk = [Z_a;Z_r];
end
- 计算先验值
function X_headp = CalculatePriorValue(X_head1, Status)
T = Status(1); g = Status(2); m = Status(3); kx =Status(4); ky = Status(5);
X_k = X_head1(1) + T*X_head1(2);
if X_head1(2) >= 0
V_xk = X_head1(2) - T/m*kx * X_head1(2)*X_head1(2);
else
V_xk = X_head1(2) + T/m*kx * X_head1(2)*X_head1(2);
end
Y_k = X_head1(3) + T*X_head1(4);
if X_head1(4) >= 0
V_yk = X_head1(4) + T*g - T/m*ky * X_head1(4)*X_head1(4);
else
V_yk = X_head1(4) + T*g + T/m*ky * X_head1(4)*X_head1(4);
end
X_headp = [X_k V_xk Y_k V_yk]';
end
- 更新 A,H 矩阵
function [A, H] = UpdateAHmatrix(X_head1, Status)
T = Status(1); g = Status(2); m = Status(3); kx =Status(4); ky = Status(5);
A = zeros(4);
A(1,1) = 1;
A(1,2) = T;
A(2,2) = 1-2*T/m*kx*X_head1(2);
A(3,3) = 1;
A(3,4) = T;
A(4,4) = 1+2*T/m*ky*X_head1(4);
H = zeros(2,4);
H(1,1) = X_head1(3)/(X_head1(1)^2 + X_head1(3)^2);
H(1,3) = X_head1(1)/(X_head1(1)^2 + X_head1(3)^2);
H(2,1) = X_head1(1)/sqrt(X_head1(1)^2 + X_head1(3)^2);
H(2,3) = X_head1(3)/sqrt(X_head1(1)^2 + X_head1(3)^2);
end
结果
红色 为真实值
* 为观测值
绿色 为滤波后的输出值。















 982
982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









