 上下文与词汇相似度
上下文与词汇相似度





 本文探讨了通过上下文理解词汇意义的Distributional Similarity概念,介绍了如何利用词频、点互信息(PMI)和余弦相似度衡量词汇相似度,以及在自然语言处理(NLP)任务中的应用。
本文探讨了通过上下文理解词汇意义的Distributional Similarity概念,介绍了如何利用词频、点互信息(PMI)和余弦相似度衡量词汇相似度,以及在自然语言处理(NLP)任务中的应用。
Distributional_Similarity解释:从上下文来考察词汇的含义。
本文图片参考自斯坦福NLP课程,作者斯坦福大学 Dan Jurafsky 教授,讲义写得非常好。
- 背景:
NLP任务中,建立同义词典非常困难且不必要,即使建立了,在召回率方面也有问题,比如丢失很多词汇和大部分的短语、丢失了句子之间的联系等等......
有人曾说过,可以通过上下文来确定一个单词的含义【(1957): “You shall know a word by the
company it keeps!” 】。
来看个例子:

我们可以猜测,tesgüino的含义类似于beer。这种思想就是:如果两个词有相似的上下文,那么他们有相似的含义。
- 再谈相似性

表中每个数字格代表词频tf(某个词在文中出现的次数)。
每个列向量代表一篇文章。如果两篇文章的向量相似,那么两篇文章相似(可以据此做文本分类)

每个行向量代表一个单词。如果两个单词的向量相似,那么两个单词相似。
- 现在把范围划定在段落,窗口大小设置为10,同时第一行替换为中心单词周围的单词,如下一段文字

数频数:
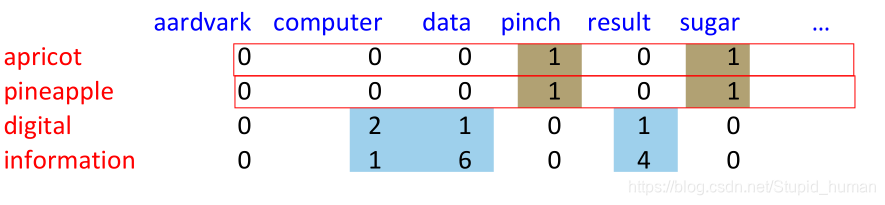
- 我们用一种 Pointwise Mutual Information (PMI) (点互信息)的指标来衡量两个事务的相关性。
PMI(x;y)=logp(x,y) / p(x)p(y)=logp(x|y) / p(x)=logp(y|x) / p(y)
联系概率论中,我们知道,如果x跟y不相关,则 p(x,y)=p(x)p(y) ;如果二者相关性越大,则 p(x,y) 就相比于 p(x)p(y) 越大,
在y出现的情况下x出现的条件概率 p(x|y) 除以x本身出现的概率 p(x) ,自然就表示x跟y的相关程度。 ——http://www.aiuxian.com/article/p-3009893.html
把所有小于0的值赋成0,就是Positive Pointwise Mutual Information (PPMI) 了。

去掉aardvark这一列(全0),并且把频次转化为概率:
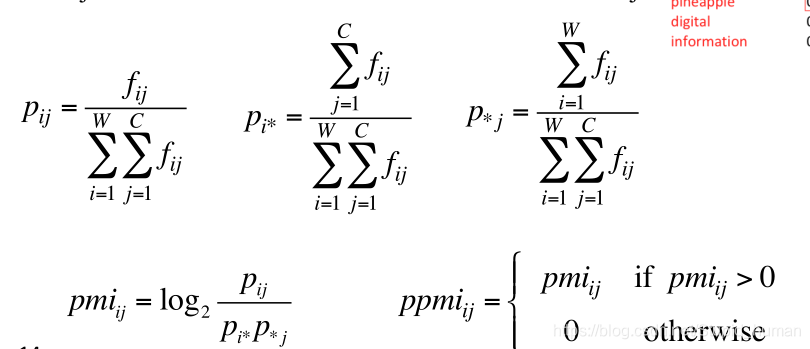
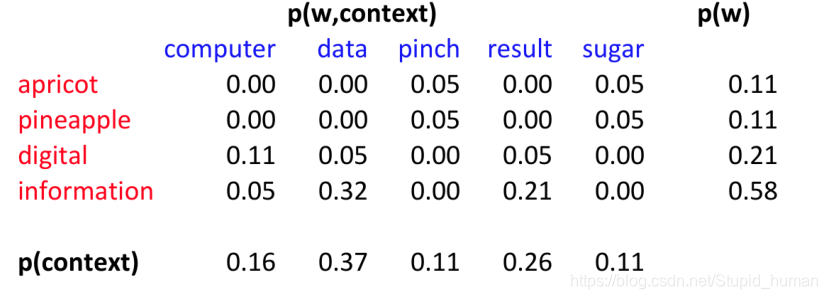
然后依照pmi的计算方法计算点互信息:
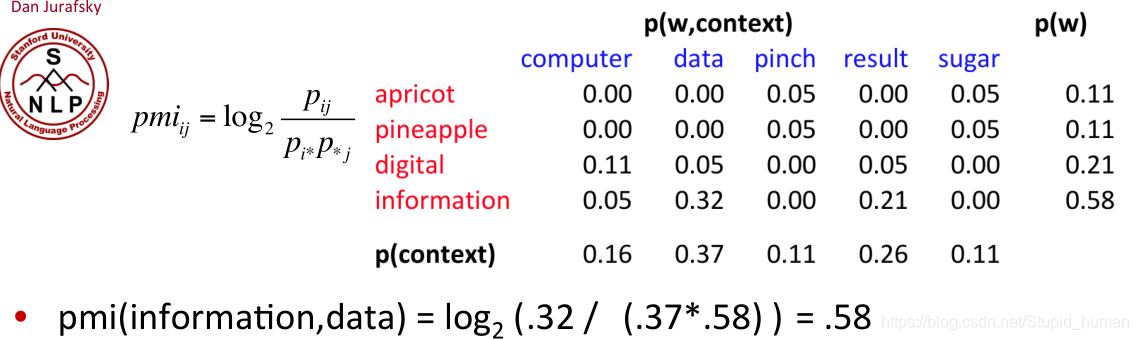
如此计算出每对单词的正点互信息(0.58->0.57是因为0.57用了full precision...)(表格中的“-”代表无穷大):
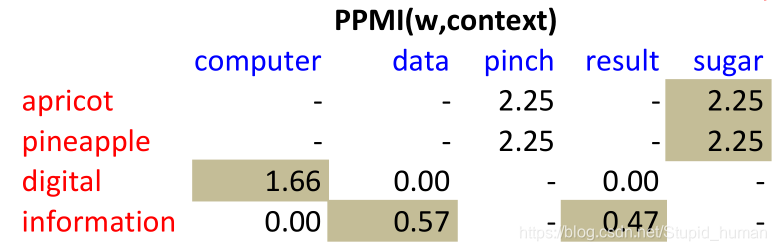
可以看出,digital和computer的相似度还是很高的。
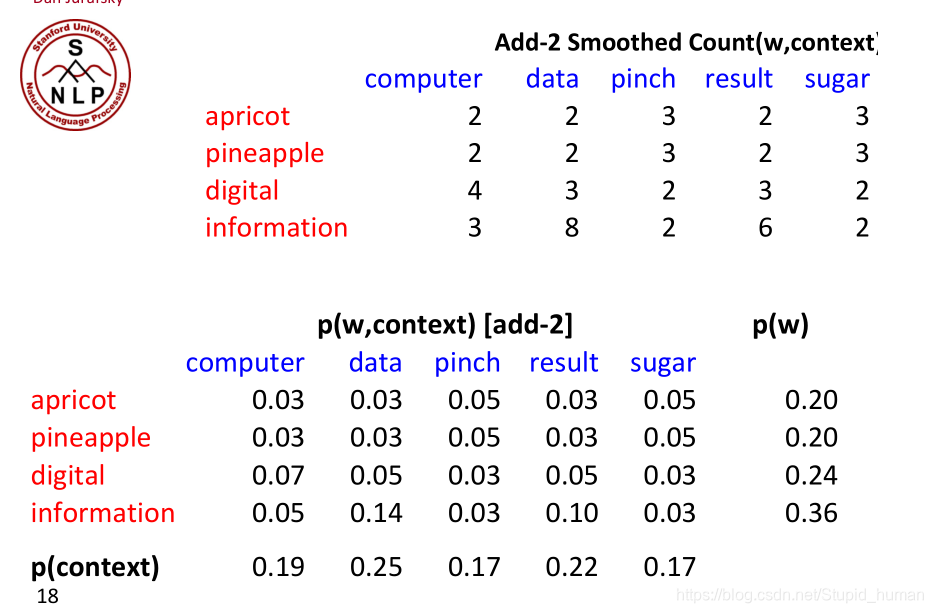
- 加1平滑或者加2平滑
- 此外,还有根据语法结构来定义单词的上下文的方法......
- 计算两个词的余弦来衡量两个单词的相似度。
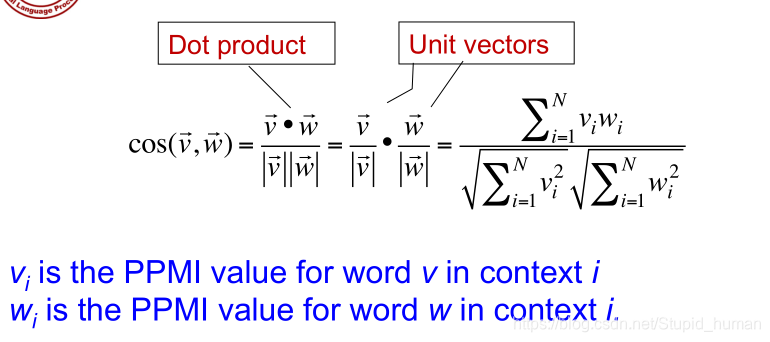
余弦值接近1,则相似;接近0,则不那么相似


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









