






之前我们讲到了顺序表,但是顺序表也有一些不可忽略的问题,以下是三点主要的问题

为了克服单链表的一些问题,我们今天来学习一种新的数据结构叫做链表。
这是链表的定义,链表就相当于一个一个的存储单元,将数据存储在一个单元中,同时有通向下一个单元的指针,就这样一个一个单元就被指针串联了起来,也就实现了链表,对于链表,有以下几点好处:
1、我们可以即开即用不需要浪费太多内存,因为它的空间都是分别malloc出来的,所以我们可以在不使用时将它的空间free
2、链表的插入不需要将数据覆盖,我们只需要将前后链表的指针分别连接起来,比较方便。

创建好链表的结构体后,我们在外面同时创建一个指针plist,来作为头结点,刚开始它指向空。

我们先来看一种头部插入数据函数的写法 :
这个函数的写法是有问题的因为在这里phead只是plist的拷贝,它和plist是没有关系的可以说phead和plist就是两个不同的链表,但是不同的是phead出了这个函数就会被销毁,结果就会导致开辟的空间就会找不到,就会造成内存的泄漏。所以为了改变本身为一级指针的plist我们要传入它的地址,通过它的地址来修改它。

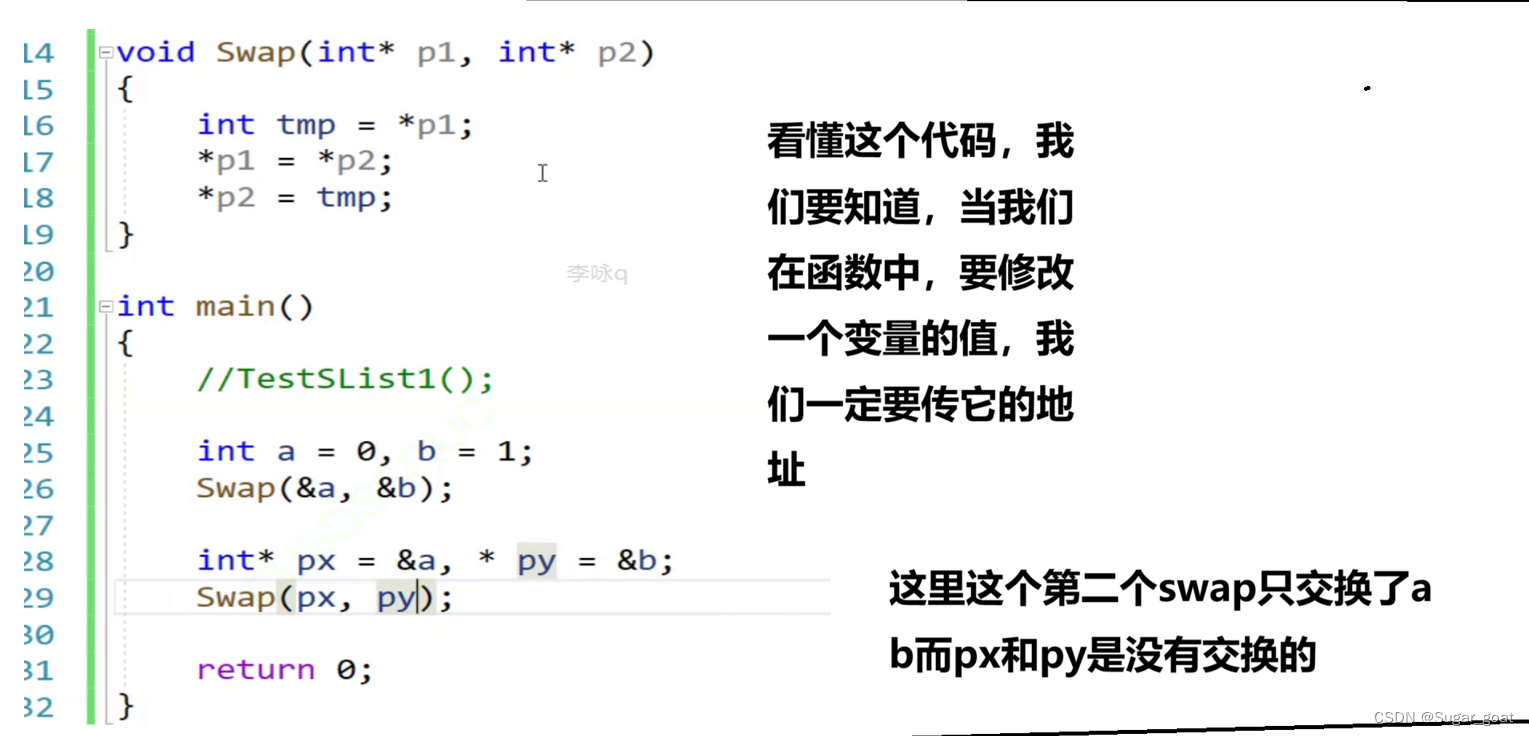
为了大家更方便理解,我们来看这个交换函数,我们知道当我们要修改函数外参数的值的话,我们就要传入它的地址,同理第一个交换中a和b的值是可以被交换的,但是第二个交换中就简单将px和py的值传入而且使用一级指针来接收,所以是不能将p1和p2的值交换的,交换的还是a和b的值
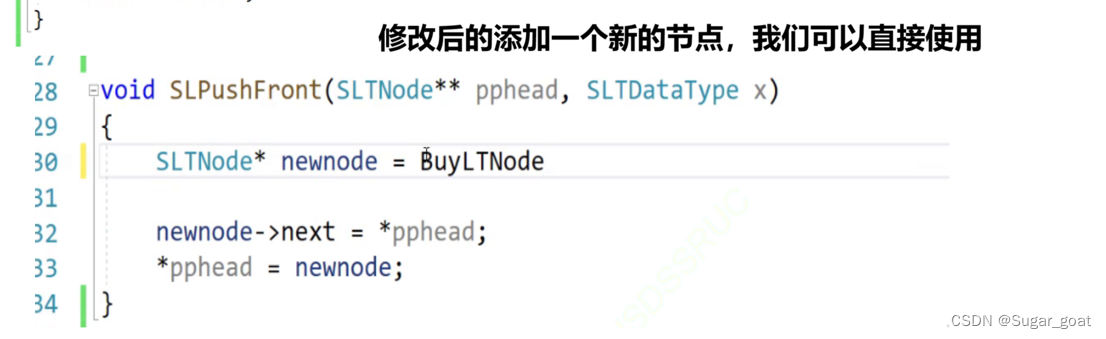
下面是修改后的头部插入的代码

主要的就是,在头部创建一个结点后,我们同时要将外部的plist结点赋值为newnode
因为后面我们要多次使用创建结点这个步骤我们就直接将它书写成为一个函数

注意创建一个结点后我们要将它的下个指针指向为NULL。
这时候我们又可以将头部插入的函数中的创建结点的步骤简化
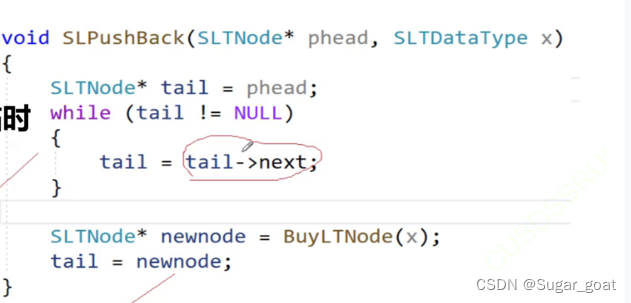
 对于尾部插入函数,我们首先定义一个结构体指针变量tail用来指向尾部,这里我们要使用tail来找到链表的尾部,判断的条件就是当tail的next为NULL就停止。
对于尾部插入函数,我们首先定义一个结构体指针变量tail用来指向尾部,这里我们要使用tail来找到链表的尾部,判断的条件就是当tail的next为NULL就停止。
我们先来看一种错误的写法
这样子写同我们先前讲到的头部插入的只传入一级指针的情况差不多,假如链表为空的情况下,如果这样插入,我们外部的plist指针还是指向NULL没有真实链接到newnode上,而且出了这个函数,tail还会被销毁,我们就再也找不到我们开辟的空间了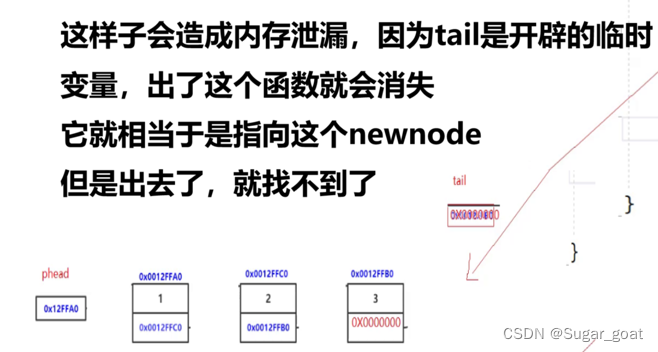
这时候有些人会说,出了函数为什么动态开辟的空间还会存在呢???
这是因为我们动态开辟的空间是在堆上的,不是在栈帧上。
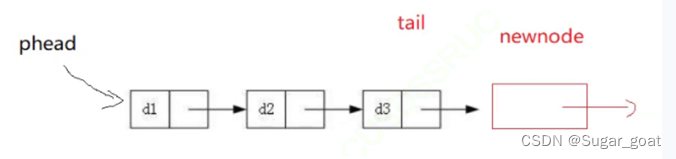
下面是修改后的尾部插入:我们要分类讨论,为空就将pphead的值直接赋值为newnode,反之就一直将tail向后走直到找到尾部,最后直接链接。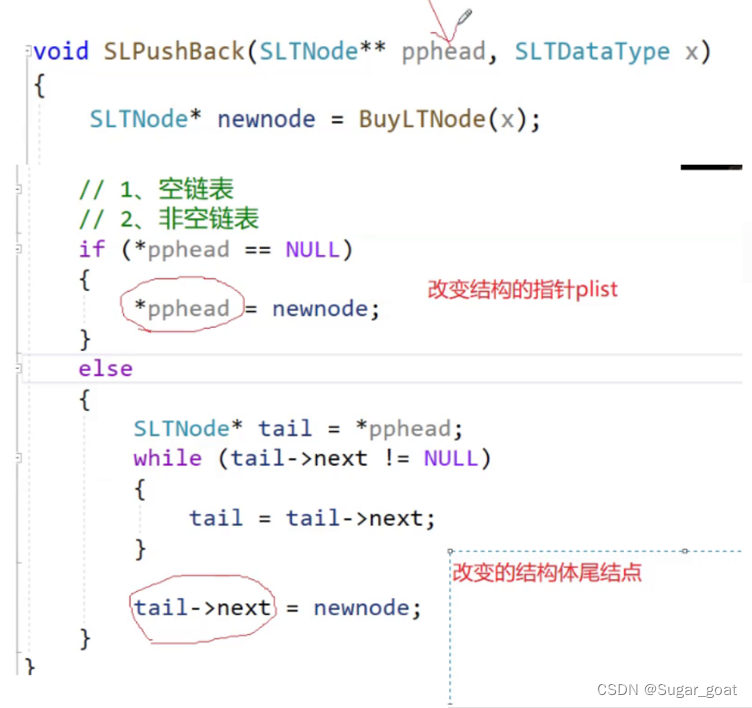
逻辑图如下
接下来到了删除环节:
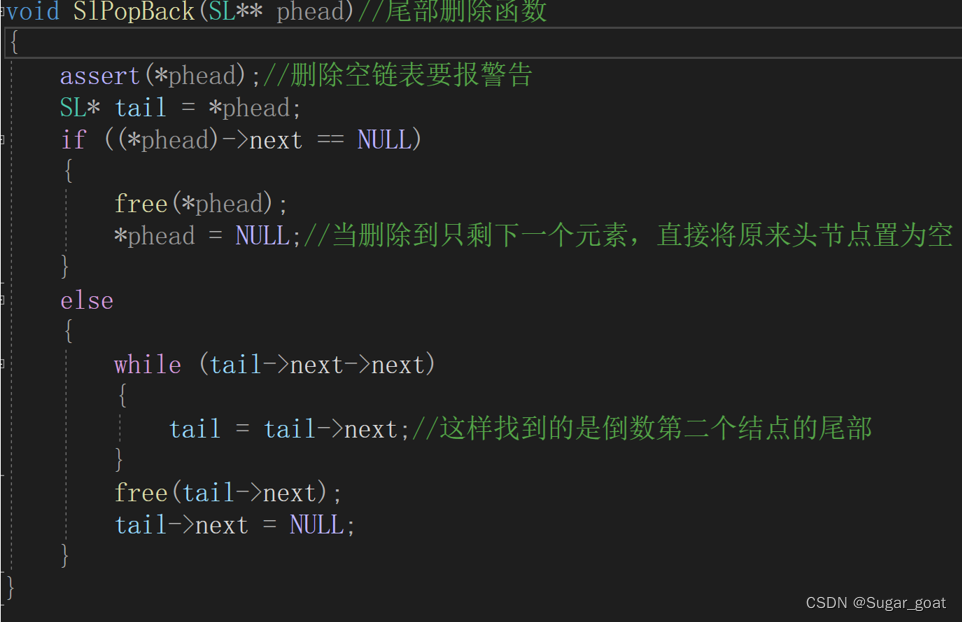
我们先来看尾部删除,尾部删除中我们要注意我们在找到尾部指针之后,我们不能仅仅将尾部指针free,因为这时候尾部指针的前一个结点的next还指向尾部指针,我们要将它的next置为NULL,不然的话就会造成野指针的问题
我们可以画图理解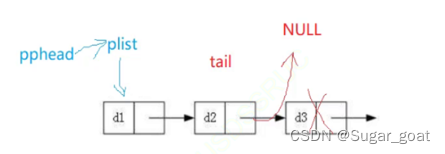
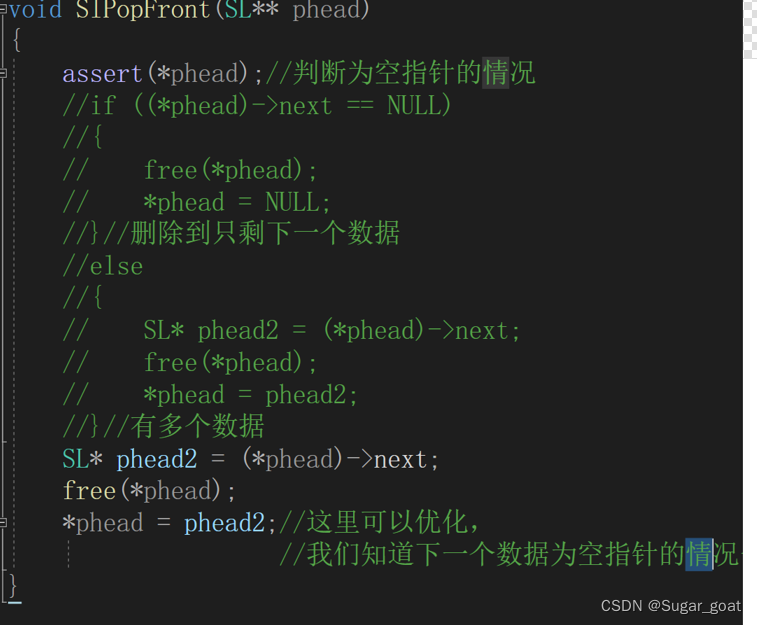
头部删除就比较简单:本来分类讨论发现都可以合并为同一种,注释部分是分情况的。
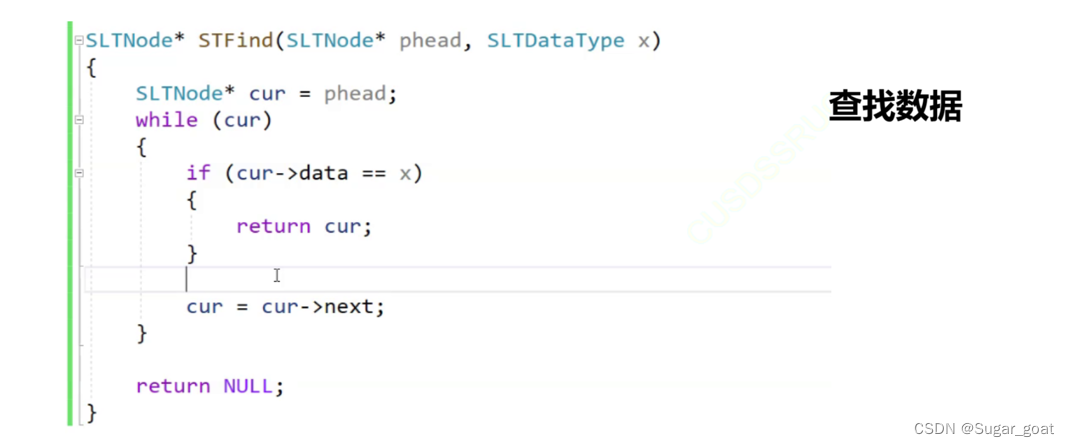
 下面是查找函数:对于查找函数我们只需要传递一级指针,因为我们不需要通过二级指针改变plist,这里同时也不需要断言,我们可以查找空链表。同理在插入中我们也不需要断言空链表,因为空链表也可以插入数据
下面是查找函数:对于查找函数我们只需要传递一级指针,因为我们不需要通过二级指针改变plist,这里同时也不需要断言,我们可以查找空链表。同理在插入中我们也不需要断言空链表,因为空链表也可以插入数据
在pos前插入数据:这里我们要找到本来pos处前面一个结点的指针还有pos处后一个结点的指针
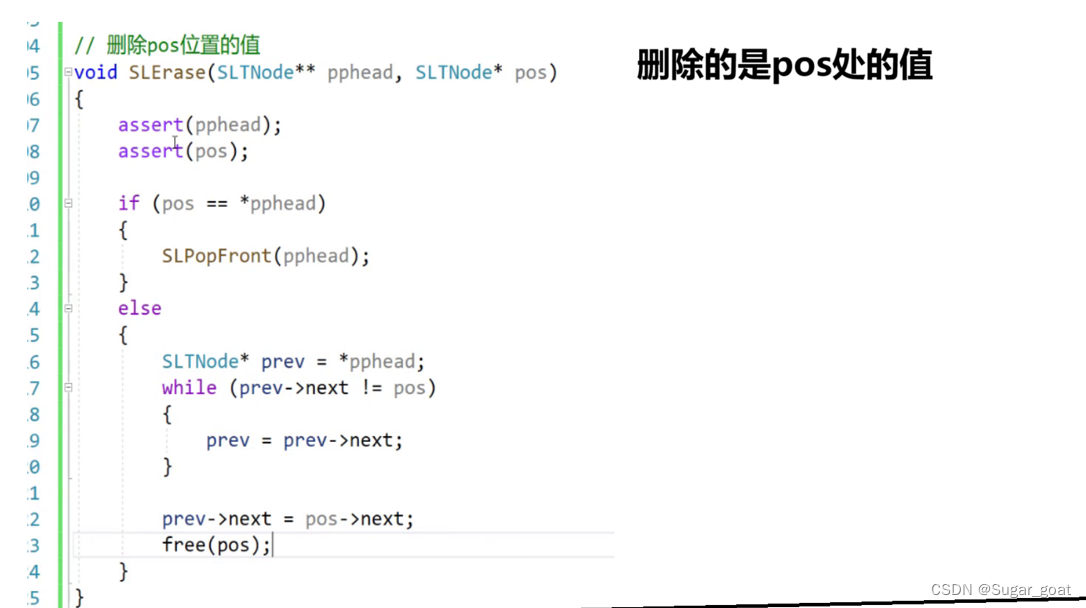
同理删除pos处的元素也是同样的道理,我们也要找到pos前一个结点的指针和后一个结点的指针,然后将他们连起来
今天我们分享的链表是链表中最基础的,但不是最简单的链表:单向不带头不循环链表。
希望对大家有所帮助!!!
代码附在下面
void Print_sl(SL* phead)
{
SL* cur = phead;
while (cur != NULL)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
SL* Buynewnode(SlDatatype x)
{
SL* newnode = (SL*)malloc(sizeof(SL));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
void SlPushFront(SL** phead, SlDatatype x)
{
assert(phead);//这里我们断言是为了防止传过来的是空指针
SL* newnode = Buynewnode(x);
newnode->next = *phead;
*phead = newnode;//将原来的 头节点赋值给新的节点的头部
}
void SlPushBack(SL** phead, SlDatatype x)
{
SL* newnode = Buynewnode(x);
if (*phead == NULL)
{
*phead = newnode;
}
else
{
SL* tail = *phead;
while (tail -> next != NULL)
{
tail = tail->next;
}
tail->next = newnode;//注意尾插的逻辑,可以画逻辑图,更方便理解
}
}
void SlPopBack(SL** phead)//尾部删除函数
{
assert(phead);
assert(*phead);//删除空链表要报警告
SL* tail = *phead;
if ((*phead)->next == NULL)
{
free(*phead);
*phead = NULL;//当删除到只剩下一个元素,直接将原来头节点置为空
}
else
{
while (tail->next->next)
{
tail = tail->next;//这样找到的是倒数第二个结点的尾部
}
free(tail->next);
tail->next = NULL;
}
}
void SlPopFront(SL** phead)
{
assert(phead);
assert(*phead);//判断为空指针的情况
//if ((*phead)->next == NULL)
//{
// free(*phead);
// *phead = NULL;
//}//删除到只剩下一个数据
//else
//{
// SL* phead2 = (*phead)->next;
// free(*phead);
// *phead = phead2;
//}//有多个数据
SL* phead2 = (*phead)->next;
free(*phead);
*phead = phead2;//这里可以优化,
//我们知道下一个数据为空指针的情况也可以包含进去
}
SL* Findnode(SL* phead, SlDatatype x)//查找元素
{
SL* cur = phead;
while(cur)
{
if (cur->data == x)
{
return cur;
}
else
{
cur = cur->next;
}
}
return NULL;//没有找到或为空链表就返回空指针
}
void SlInsert(SL** phead, SL* pos, SlDatatype x)//在pos前插入数据x
{
assert(phead);
SL* newnode = Buynewnode(x);
SL* cur = *phead;
if (*phead == pos)
{
SlPushFront(phead, x);
}
else
{
while ((cur->next) != pos)
{
cur = cur->next;
}
cur->next = newnode;
newnode->next = pos;
}
}
void SlErase(SL** phead, SL* pos)//删除pos位置处的数据
{
assert(*phead);
assert(phead);
SL* cur = *phead;
if (pos == *phead)
{
SlPopFront(phead);
}
else
{
while (cur->next != pos)
{
cur = cur->next;
}
cur->next = pos->next;
free(pos);
pos = NULL;
}
}
void SlDestroy(SL** phead)
{
assert(phead);
SL* cur = *phead;
while (cur)
{
SL* next = cur->next;
free(cur);
cur = next;
}
}
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











