









写在前面的
经过了一个多星期的学习,在不断的测试下终于用一致性哈希实现了分布式存储(无法分配权重),可喜可贺~可喜可贺~
提到分布式存储,可能对于初学者来讲Redis、MySQL等接触的比较多,(仅本人观点,因为这两个东西本身集成了一些分布式的模块,所以比较学习起来比较简单)但是对于Memcached来讲,我是第一次接触,只知道这个玩意儿仍然是一个数据“缓存”机制,并且可以通过它来实现“秒杀”。听起来简单,做起来难,或不多说,我们先从原理入手。
想要通过Memcached来实现分布式存储,我们首先要明白一致性哈希和取模这两个概念,简单来讲就是Memcached实现分布式存储的两种算法,通过这两种算法Memcached就能自己对目标服务器进行存取,下面我们来介绍这两种算法。
一致性哈希
概念
- 这个算法的具体思路就是,通过获取目标服务器和存入的数据的HashCode(哈希值)来进行比较,如果要存入的数据的哈希值比目标服务器的哈希值大,则存入这个服务器,如果小,则可以存入下一台服务器,(也可以反过来,这个可以在算法内部自定义)这样进行循环,直到数据全部存储完毕。
实现方法
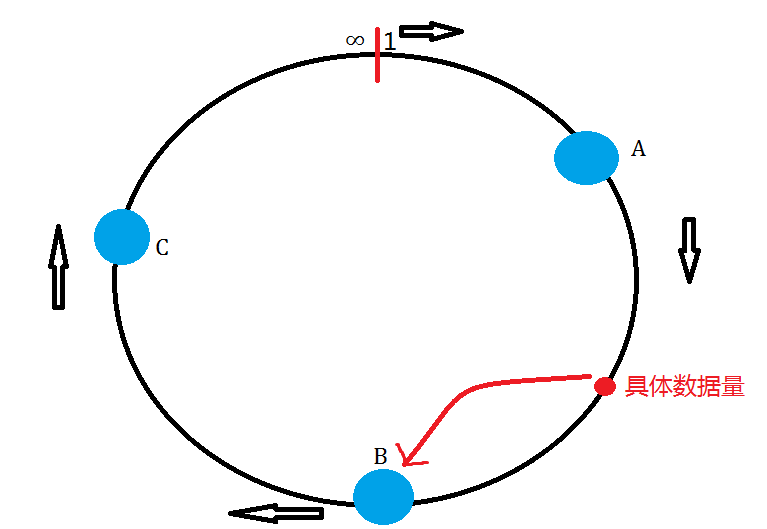
想要实现一致性哈希,我们首先要理解一下“一致性哈希圆”,这个哈希圆的目的就是为了将索要存储的数据尽最大的可能平均分配到服务端上,如图所示:
图中的A,B,C代表了现实中真正存在的服务器,根据数据量的大小我们可以根据算法将数据自动分配到其中的某一台上去,比如图中所示,数据量的大小落到了A,B服务器中间,根据我们的安排,A服务器承受数据量为10以下,B为30以下,所以处于A,B服务器之间的数据量就自然存入了B服务器中。
这里需要注意的是,按照图中的方法,我们并不能把实际的数据量真正的“平均”分配到所部属的服务器中。为什么这样讲?假设,我们的数据量一直维持在A,B之间,那么我们的B服务器是不是压力太大了?虽然服务器都是365 x 24的工作模式,但是也不能让一台负担太大,要不我们研究分布式存储也就没有意义了。到了这里可能有人会讲,我们改变一下A,B,C的接受数据的范围不就可以了。但是这样真的可以解决问题吗?答案是否定的。
因为,如果我们缩小了A,B,C的接受范围,那么仔细想一想,我们画出来的图是不是还和上面的一样?所以,并不能从根本上解决平均分配的问题。(这里说的平均是近乎“收敛”的“平均”并不是绝对的平均。)所以我们可以为部署的服务器添加虚拟节点来达到这一目的,如图:
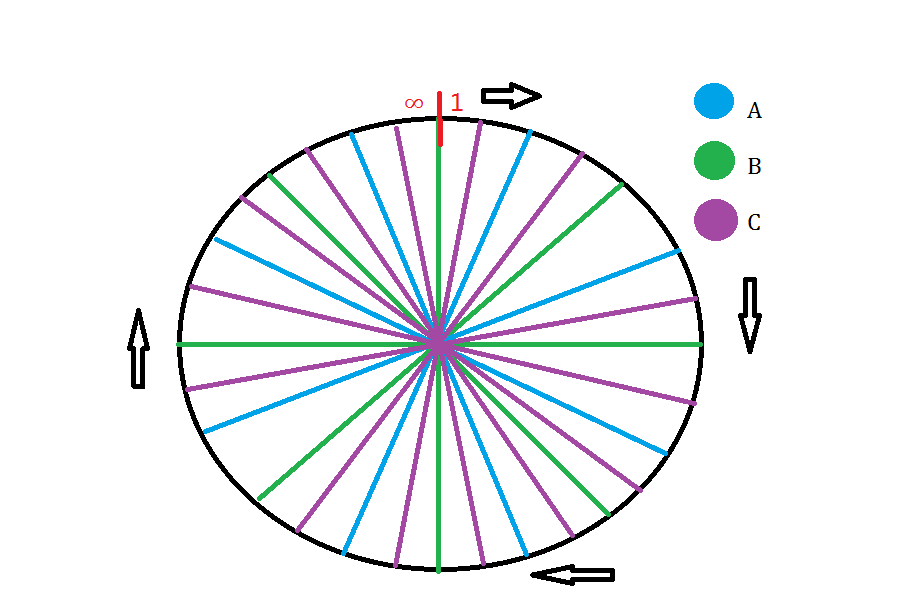
如图所示,我们在实际部署的服务器上近乎无限的添加了虚拟节点,这样,当某一个数据落到这个哈希圆上的时候这个数据被A,B,C服务器接受到的可能性就近乎平均了,大致接近于1/3。(这里的虚拟节点在实际应用中称为“端口”,基于MEM的特性,我们可以开很多端口,前提是你的内存够大的话)
这里需要说明的一点就是,如果你的公司足够的有钱,那么可以不用考虑添加虚拟节点,直接部署N多服务器就行了,但是恐怕没有哪一个公司能土豪成这样吧= =。考虑到物尽其用,所以我们才引入了虚拟节点。
取模
概念
- 相比于一致性哈希,取模算法就比较简单了。将需要存入的数据条数对实际部署的服务器的个数取余数,然后然后按照余数的值,分别存到已经编号序号的服务器当中去。
实现方法
- 如同概念中提到的那样,现在假设我们有30条要存储的数据,并且我们有6台已经部署好的服务器,分别对应的编码为0#,1#,2#,3#,4#,5#。接下来从第一条数据开始循环,直到把三十条数据全部存入指定的服务器当中,然后结束。
- 循环方法:拿前6条数据来说,1 mod 6 =1,2 mod 6 =2,3 mod 6 =3,4 mod 6 =4,5 mod 6 =5,6 mod 6 =0。所以对应的服务器为:1=>1#,2=>2#,3=>3#, 4=>4#,5=>5#,6=>0#。这样就实现了我们的取模算法。
对比
俗话说的好,有对比才有价值。这两种方法看起来都差不多,一致性哈希算起来那么麻烦,取模这么简单,那么肯定是取模算法效率跟高咯,而且,既然是分布式存储,那么我们服务器的数量越多,岂不是性能更好?答案是否定的。
不可否认的是,当数据量比较小的时候,取模算法的性能是比一致性哈希算法效率高,但是我们忽略了一点——“服务器是会宕机的”。考虑到这点因素,我们就必须引入一个概念,服务器的命中率,即服务器对数据的存储情况统计(我们往服务器中存储数据为Set,取数据为Get,由于各种原因,我们并不能每次都准确GET到键值,那么Get/Set的值就是命中率),下面我们分别对取模和一致性哈希在服务器宕机之后的命中率进行数学分析。
首先,我们先来分析取模算法宕机之后的命中率。我们就假设其中5#服务器宕机,那么我们现在就剩下了0#——4#服务器,这里需要注意的是,接下来我们不考虑宕机的5#服务器丢了多少数据,我们只考虑当我们GET数据的时候能否在原来存储这条数据的服务器上获取到。有了这个前提,那么我接下来可以这样计算,由于现在只存在5台服务器,那么我们所有的数据取余的对象由原来的6台变成了现在的5台,继续用前六条数据举例: 1 mod 5 =1,2 mod 5 =2,3 mod 5 =3,4 mod 5 =4,5 mod 5 =0,6 mod 5 =1,怎么样?出错了吧。所以我们现在的数据存储变成了:1=>1#,2=>2#,3=>3#,4=>4#,5=>0#,6=>1#也就是说,第五条和第六条数据现在我们已经GET不到了,因为原来没有存在这两台服务器上,而我偏偏就去这两台服务器上找,那结果是显而易见的。那我们把这个结论推广一下,也就是服务器宕机前和宕机后的个数的最小公倍数作为需要存储的数据量。(5和6的最小公倍数为30)从宕机后的服务器个数的为标记的那条数据开始往后,我们就GET不到了。(也就是从第五条数据往后就GET不到了)所以我们可以这样写一个命中率公式:N/N*(N+1),(即1/(N+1))N代表宕机后服务器的个数,同样也代表第几条数据。所以,从这个公式不难看出,当你的服务器部署的越多,宕机后的命中率越低!
然后,我们再从一致性哈希算法的角度计算宕机之后的命中率。与取模算法不同的是,一致性哈希算法的命中率计算就比较简单了。当一台服务器宕机之后,根据算法内部的构造,我们的数据会继续去和下个数据节点比较,从而确定新的数据存放位置,当GET的时候也会去找到相应的服务器,所以我们丢失掉的数据洽洽就是在服务器宕机之前,存入这台服务器的数据,所以我们原来取模算法的命中率在一致性哈希里变成了数据的丢失率。则一致性哈希算法的数据丢失率为:N/N*(N+1)。(即1/(N+1))所以在一致性哈希算法中实现的分布式存储才能符合“服务器越多,性能越好,数据的丢失率越低”这一条宗旨。
总结
了解了上面的两种算法,我相信对于如何将数据存入指定的服务器认真看过的朋友已经有所思路了。下面就是实际的测试和使用了。
但是由于篇幅有限,这篇文章并没有对两种算法进行代码的测试,只是介绍了为了实现Memcached的分布式存储的一些算法的原理,在接下来的文章中我会把我自己做测试的一些例子和实际的性能分析都一一总结出来。
TO BE CONTINUE……















 191
191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









