







先知识点(scdn)–再视频B站视频----练习题
窗口函数
0、用处:在组内排名、组内取topn值等需求。处理相对复杂的报表统计分析场景
排名问题:每个品牌的商品按销售额来排名
topN问题:找出每个品牌排名前N的商品
1、定义:窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),作用于一个数据集合。窗口函数的一个概念就是当前行,当前行属于某个窗口就是从整个数据集选取一部分数据进行聚合/排名等操作。
窗口–类似窗户,限定一个空间范围
窗口函数–应用在窗口内的函数
2、语法:
基本用法:函数名()over()
over 是关键字,用来指定函数执行的窗口范围,包括3个子句:分组(partition by),排序(order by),窗口(rows),如果后面括号什么都不写,则窗口包含满足where条件的所有行
window_function_name(window_name/expression)
OVER (
[partition_defintion]
[order_definition]
[frame_definition])
窗口函数名(窗口名/)
over(partition by <要分列的组> order by <要排序的列> rows between <数据范围> )
3、语法中的元素:
3.1、window_function_name窗口函数名
静态窗口函数 vs 滑动窗口函数
静态窗口函数:rank() , dense_rank() , row_number()
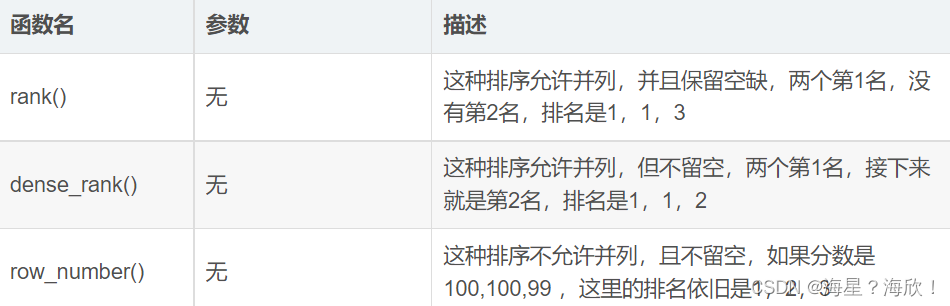
滑动窗口函数:
- 聚合函数 sum,avg ,count , max, min , percent_rank(), cum_dist()
- 取值函数 first_value() ,last_value() , nth_value() ,lag() , lead() ,ntile()

3.2、分区partition_defintion
partition by 指定字段 :窗口函数功能在分区内执行,并在跨越分区边界时重新初始化。
如果没有指定 partition by 语句,且没有后面的frame元素限制,就把所有数据当做一整个区。
3.3、排序order_definition
order by 指定字段 :和partition by 子句配合使用,就是对分区后的数据进行排序
3.3、框架frame_definition
窗口框架的作用是对分区进一步细分
frame_unit有两种,分别是rows和range,ROWS是基于行号,RANGE是基于值的范围
between frame_start and frame_end :用来表示行范围,frame_start和frame_end可以支持如下关键字:
- current row 当前行
- unbounded preceding 区间的第一行 (unbounded无边界)
- unbounded following 区间最后一行
- expr npreceding :当前行之前的N行,可以是数字,也可以是一个能计算出数字的表达式
- expr nfollowing : 当前行之后的N行,可以是数字,也可以是一个能计算出数字的表达式
例子:
rows between 2 preceding and current row #每次都取当前行和前面两行,然后不断移动
rows between unbounded preceding and current row #包括本行和之前的所有行
rows between current row and unbounded following # 包括本行和之后的所有行
rows between 3 preceding and 1 following # 包括前三行和下一行,一共5行
rows类似分区中的子集
3.4 、案例
创建表
drop table if exists score;
create table if not exists 'score' (
'学号' int(5) zerofill not null,
'姓名' varchar(10) not null,
'课程号' varchar(15) not null,
'成绩' int(5) not null default 0)
ending = InnoDB default charset=utf8 collate=utf8_unicode_ci comment='成绩单';
插入数据
insert into 'score'(`学号`, `姓名`, `课程号`, `成绩`)
values
( '0005', '范若若', '00001', '99' ),( '0005', '范若若', '00002', '81' ),..
查询表
select * from score order by 学号;
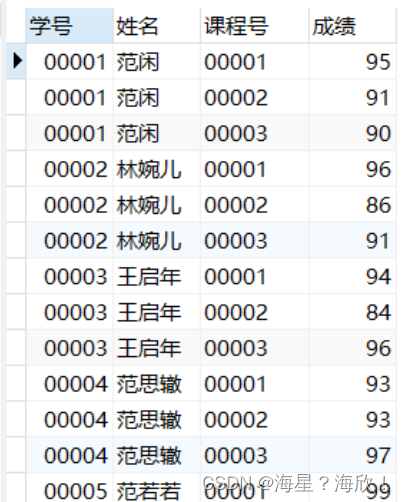
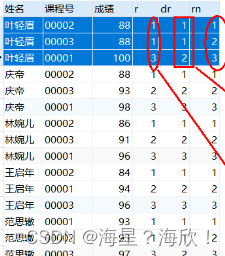
- rank(),dense_rank(),row_number() 静态窗口 (这三个是专有的窗口函数)
select 姓名,课程号,成绩
rank() over (partition by 姓名 order by 成绩) as r,
dense_rank() over (partition by 姓名 order by 成绩) as dr,
row_number() over (partition by 姓名 order by 成绩) as rn
from score;
2)聚合函数avg()、count()、sum()、min()、max()、percent_rank()、cume_dist()
这些聚合函数用法:1,与group by一起使用 (多条数据输出一个) 2,当作聚合类窗口函数应用(多到多)
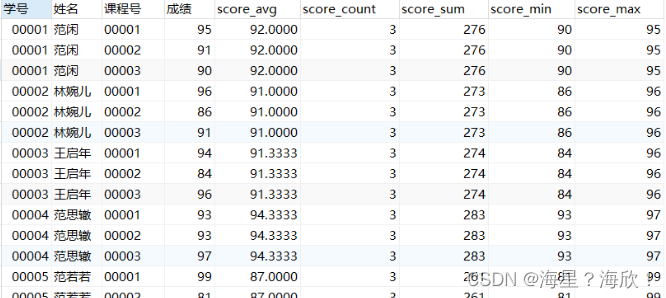
利用窗口函数+聚合函数 求每个人成绩的均值、个数、总分、最小值和最大值。
select *,
avg(成绩) over w as score_avg,
count() over w as score_count,
sum() over w as score_sum,
min() over w score_min,
max() over w score_max
from score
WINDOW w as (partition by 姓名)
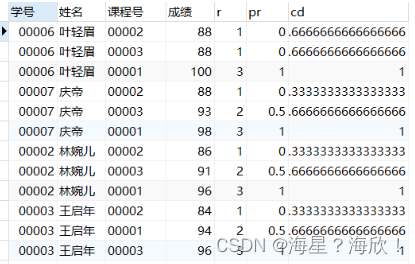
3)聚合函数percent_rank():累计百分比、cume_dist():累计分布值函数
percent_rank(),和之前的rank()函数相关,每条记录按照如下公式计算:(rank-1)/(rows-1)其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。(第一个一定为0,最后一个一定为1)
cume_dist(),和之前的rank()函数也相关,每条记录按照如下公式计算:相对位置(行排名)/rows (开头不为0,最后一定为1)
#percent_rank累计百分比、cume_dist累计分布值
select *,
rank() over w r,
percent_rank() over w as pr,
cume_dist() over w as cd
from score
window w as (partition by 姓名 order by 成绩);
5)取值函数
前后函数lag()、lead()
用途:分区中位于当前行前n行/后n行的记录值。(分组前后移动n行)
使用场景:查询上一个订单距离当前订单的时间间隔等
select *,lag(成绩,1) over w as first_row,
lead(成绩,1) over w as lat_row
from score
window w as (partition by 课程号);
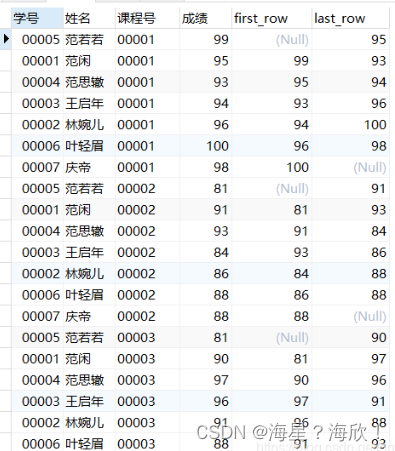
可能会有空值的,每一个分组n个空值,类似于把该列值向前/后移动n个位置
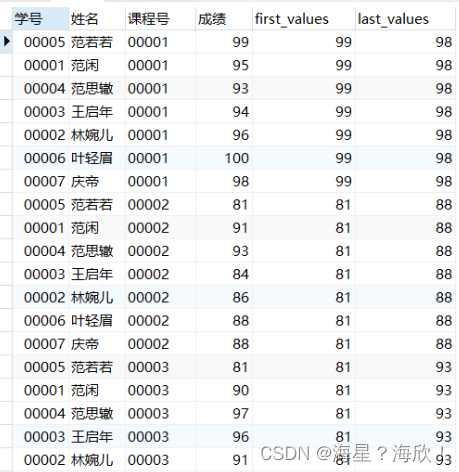
头尾函数first_val() last_val()
用途:返回分区中的第一个/最后一个记录值
#展示按照课程号分区的第一个和最后一个成绩分数
select *,first_value(成绩) over w as first_values,
last_value(成绩) over w as last_values
from score
window w as (partition by 课程号);
其他函数nth_value()、ntile()
(1)nth_value()
用途:返回窗口中第N个expr的值,expr可以是表达式,也可以是列名;
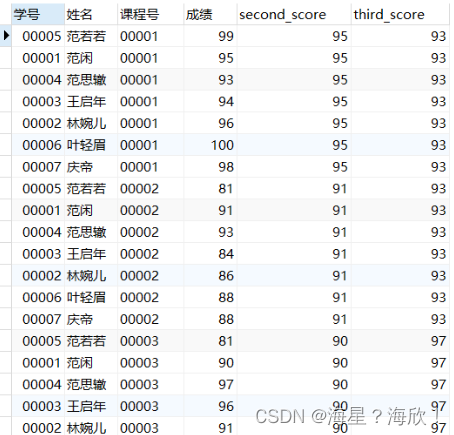
#按照课程号分区取每个分区成绩的第2和第3个值
SELECT *,
nth_value(成绩, 2) over w as second_score,
nth_value(成绩, 3) over w as third_score
FROM score
WINDOW w AS (partition by 课程号);
(2)ntile()
用途:将分区中的有序数据分为n个桶,记录桶号;
#按照课程号分区并按成绩升序排序,将各分区分为3桶
SELECT *,
ntile(3) over w as nt
FROM score
WINDOW w AS (partition by 课程号 order by 成绩 asc);
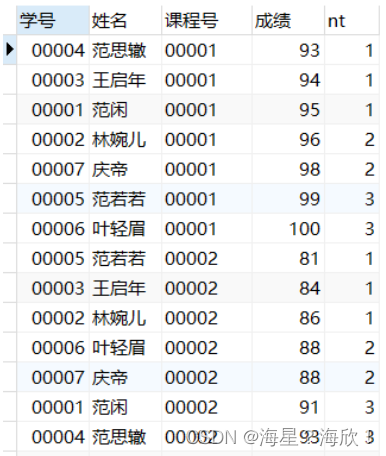
排序后分成n份
6)frame语句
preceding :区间的前面
following :区间的后面
(1)
#根据姓名分组后,按成绩降序排列,再求移动平均和移动求和
select 姓名,课程号,成绩,
avg(成绩) over (partition by 姓名 order by 成绩 asc rows 1 preceding) as moving_avg,
sum(成绩) over (partition by 姓名 order by 成绩 asc rows 1 preceding) as moving_sum
from score;

该行与前一行的平均数,以及求和
(2)
#计算每个分区内从第一行到当前行的平均值以及和
select 姓名,课程号,成绩,
avg(成绩) over (PARTITION BY 姓名 ORDER BY 成绩 ASC range between unbounded preceding and current row) AS moving_avg,
sum(成绩) OVER (PARTITION BY 姓名 ORDER BY 成绩 ASC RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS moving_sum
FROM score;
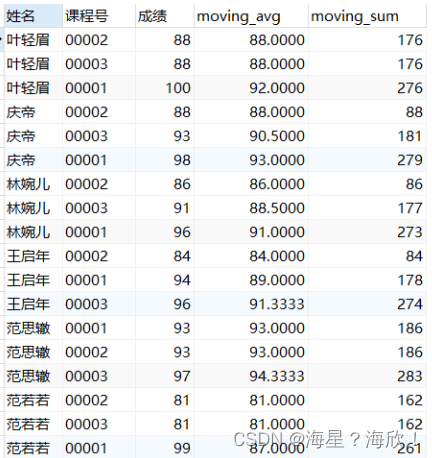
分组后,从第一行到当前行的累计平均与累计求和
(3)
-- 计算每个分区内从当前行到最后一行的平均值以及和
SELECT 姓名,课程号,成绩,
avg(成绩) OVER (PARTITION BY 姓名 ORDER BY 成绩 ASC RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS moving_avg,
sum(成绩) OVER (PARTITION BY 姓名 ORDER BY 成绩 ASC RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS moving_sum
FROM score;
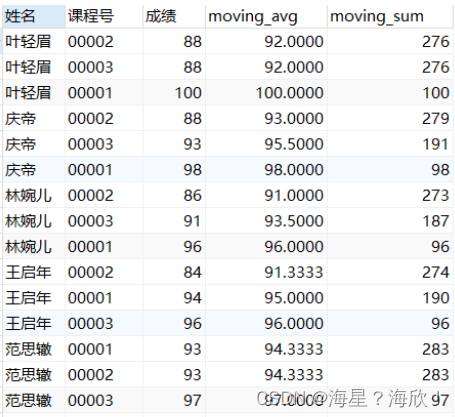
分组后,从最后一行到当前行的累计平均与累计和
练习题
例子:订单信息表user_trade (user_name 用户名,piece 购买数量,price 价格 ,pay_amount 支付金额 ,goods_category 商品品类, pay_time 支付时间)
累计求和
1)查询出2019年每月的支付总额和当年累计支付总额
select *,窗口函数 from (把每月值先求出来)
#range between unbounded preceding and current row 这段可以不要,因为默认地从第一行到当前行
select *,sum(mon_pay) over(order by ym rows between unbounded preceding and current row) as moving_sum
from
(select date_format(pay_time,'%Y%m') as ym,sum(pay_amount) as mon_pay
from user_trade
where year(pay_time) = 2019
group by date_format(pay_time,'%Y%m')) t
2)查询出2018-2019年每月的支付总额和当年累计支付总额
select *,sum(mon_pay) over(partition by year(ym) order by ym ) as moving_sum
from
(select date_format(pay_time,'%Y%m') as ym,sum(pay_amount) as mon_pay
from user_trade
where year(pay_time) in (2019,2018)
group by year(pay_time),month(pay_time)) t
3)查询出2019年每个月的近三月移动平均支付金额
select *,sum(mon_pay) over(order by ym rows between 2 preceding and current row) as moving_sum
from
(select date_format(pay_time,'%Y%m') as ym,sum(pay_amount) as mon_pay
from user_trade
where year(pay_time) = 2019
group by date_format(pay_time,'%Y%m')) t
4)查询出每4个月的最大月总支付金额(当月+前3个月)
select *,max(mon_pay) over(order by ym rows between 3 preceding and current row) as moving_max
from
(select date_format(pay_time,'%Y%m') as ym,sum(pay_amount) as mon_pay
from user_trade
group by date_format(pay_time,'%Y%m')) t
排序函数
5)2020年1月,购买商品品类数的用户排名
select user_name,count(distinct goods_category),
rank() over(order by count(distinct goods_category)) as r1,
row_number() over(order by count(distinct goods_category)) as r2,
dense_rank() over(order by count(distinct goods_category)) r3
from user_trade
where date_format(pay_time,'%Y%m)= 202001
group by user_name;
时间限制的用法:
- date_format(pay_time,'%Y%m)= 202001
- substring (pay_time,1,7) = ‘2020-01’
6)查询出将2020年2月的支付用户,按照支付金分成5组后的结果
ntile(n) over(…)
select user_name,sum(pay_amount) as pa,ntile(5) over (order by sum(pay_amount) desc) as lev
from user_trade
where substring(pay_time,1,7) = '2020-02'
group by user_name;
7)查询出2020年支付金额排名前30%的所有用户
select *
from
(select user_name,sum(pay_amount) as pa,ntile(10) over (order by sum(pay_amount) desc) as lev
from user_trade
where substring(pay_time,1,7) = '2020-02'
group by user_name) t
where lev in (1,2,3);
偏移分析函数
8)查询出名字为king与west的时间偏移(前n行)
lag(…) over(…) 向上偏移n行
lead(…) over (…) 向下偏移n行
应用:有时候需要同时显示昨天和今天的数据,就用该函数
select user_name,pay_time,
lag(pay_time,1,pay_time) over(partition by user_name order by pay_time) lag1
from user_trade
where user_name in ('king','west');
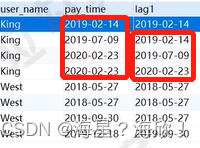
lag(pay_time,1,pay_time)是指向上偏移一行,上一行没有的用pay_time当前行的值补充
lag(pay_time,1)则是向上偏移一行,上一行没有的会显示为空
10)查询出支付时间间隔超过100天的用户数(时间间隔:上一次与这一次的时间差)
select count(distinct user_name)
from
(select user_name,pay_time,lag(pay_time,1)over(partition by user_name order by pay_time) lag1
from user_trade
group by user_name ) t
where datediff(pay_time,lag1) >100 ;
11)查询出每年支付时间间隔最长的用户
分别2018,2019,2020年,支付时间间隔最大的人
select b.years,b.user_name,b.interval_days
from
(
select a.years,a.user_name,datediff(pay_time,lag1) as interval_days,
rank()over (partition by a.years order by datediff(pay_time,lag1) desc) rank1
from
(select year(pay_time) as years,user_name,pay_time,lag(pay_time,1,pay_time)over(partition by user_name,year(pay_time) order by pay_time asc) lag1
from user_trade ) a
) b
where b.rank1=1;
可以嵌套三次,rank()或者lag()后要进行筛选,都要外套一个select后再筛才行














 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









