







数据分组
import pandas as pd
#读入数据
path3 = "E:/kaggle数据/exercise_data/drinks.csv"
df3 = pd.read_csv(path3)
df3.head()
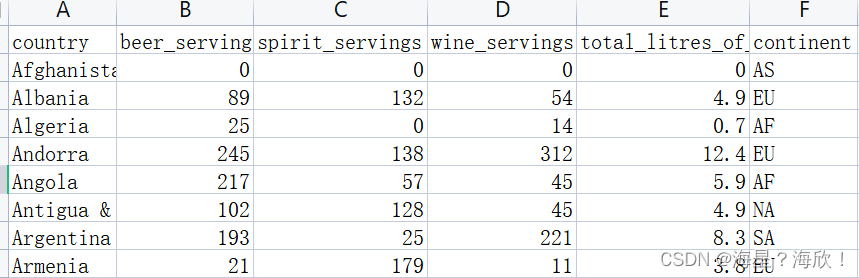
#哪个大陆(continent)平均消耗的啤酒(beer)更多?
df3.groupby('continent').beer_servings.mean() #按continent分组求beer_servings的和/均值/最大值。。
#打印出每个大陆(continent)的红酒消耗(wine_servings)的描述性统计值
df3.groupby('continent').wine_servings.describe()
#打印出每个大陆每种酒类别的消耗平均值、中位数
df3.groupby('continent').mean() #continent分组后求其他列的均值
df3.groupby('continent').median() #continent分组后求其他列的中位数
#打印出每个大陆对spirit_servings的平均值,最大值和最小值?
df3.groupby('continent').spirit_servings.agg(['mean','min','max'])
Apply函数
import numpy as np
import pandas as pd
path4 = "E:/kaggle数据/exercise_data/US_Crime_Rates_1960_2014.csv"
df4 = pd.read_csv(path4)
df4.head()
df4.info() #每列类型
#将Year的数据类型转换为 datetime64?
df4.Year = pd.to_datetime(df4.Year,format='%Y')
df4.info()
#将列Year设置为数据框的索引
df4 = df4.set_index('Year',drop = True)
df4.head()
#删除名为Total的列
del df4['Total']
df4.head()
resample()函数
Pandas中 resample()函数用于在频率转换期间执行重采样操作。
1,向下采样和执行聚合
下采样是将一个时间序列数据集重新采样到一个更大的时间框架。例如,从几分钟到几小时,从几天到几年。结果的行数将减少,并且可以使用mean()、min()、max()、sum()等聚合值。
例子:这样一张df_sales表
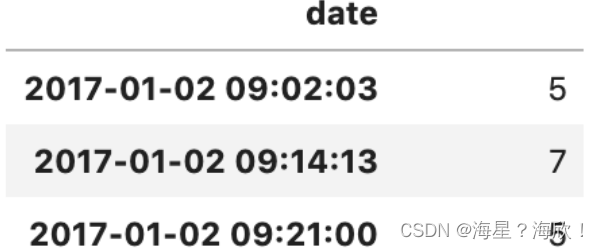
要获得每2小时添加的总销售额,只需使用resample()将DataFrame向下采样到2小时的容器中,并将落入容器中的时间戳的值相加。
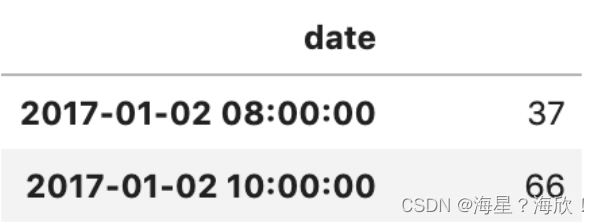
df_sales.resample(‘2H’).sum()
输出:(最小日期是01-02 9点多,默认是这样间隔:00:00:00,02:00:00,04:00:00,…,22:00:00,8点-10点才开始有数据,所以从8点开始的)
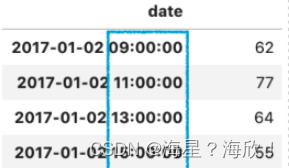
2,使用自定义基数向下采样
df_sales.resample(‘2H’, base=1).sum() #从9点开始
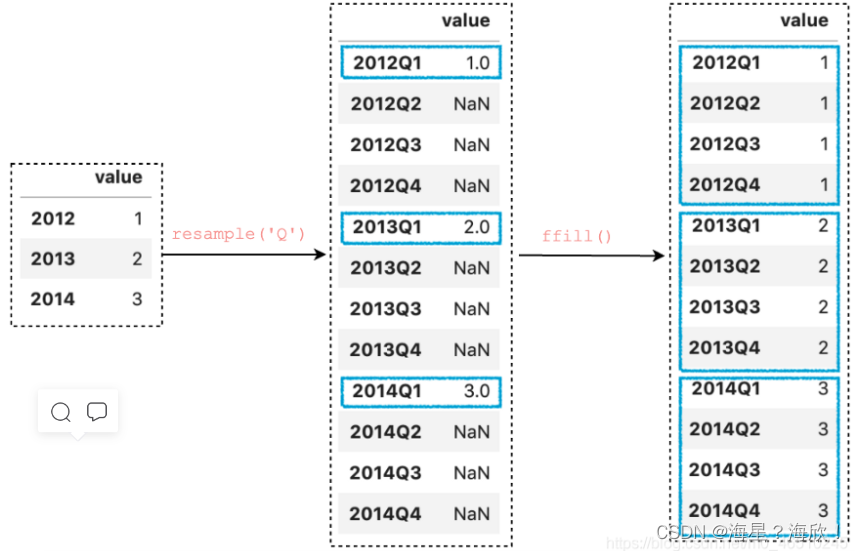
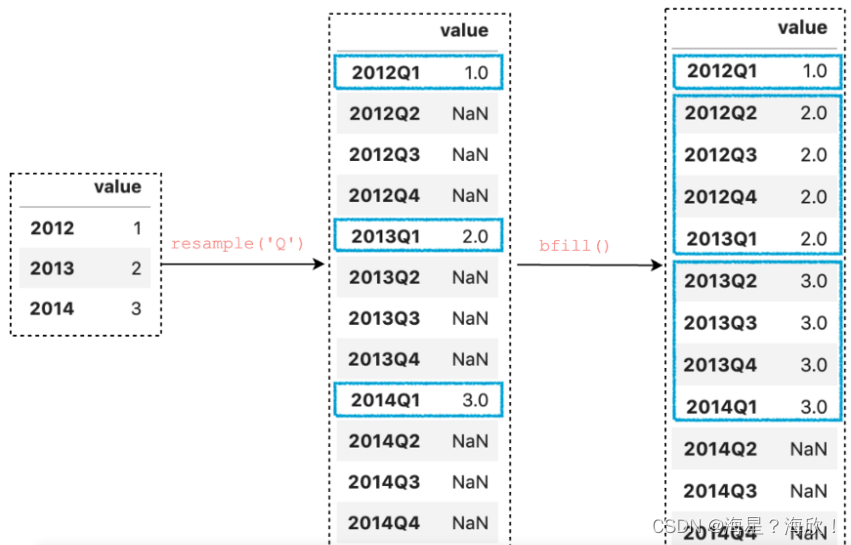
3,上采样和填充值
ffill()和bfill()通常用于执行前向填充或后向填充来替代NaN。
原数据:
df.resample(‘Q’).ffill()
df.resample(‘Q’).bfill()
#按照Year对数据框进行分组并求和
df4 = df4.resample('10AS').sum()
population = df4['Population'].resample('10AS').max()
df4['Population'] = population
df4
df4.idxmax(0)
idxmax() 计算能够获得到最大值的索引位置(整数)
合并
import numpy as np
import pandas as pd
raw_data_1 = {
'subject_id': ['1', '2', '3', '4', '5'],
'first_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'last_name': ['Anderson', 'Ackerman', 'Ali', 'Aoni', 'Atiches']}
raw_data_2 = {
'subject_id': ['4', '5', '6', '7', '8'],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']}
raw_data_3 = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_id': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
#创建数据框
data1 = pd.DataFrame(raw_data_1, columns = ['subject_id', 'first_name', 'last_name'])
data2 = pd.DataFrame(raw_data_2, columns = ['subject_id', 'first_name', 'last_name'])
data3 = pd.DataFrame(raw_data_3, columns = ['subject_id','test_id'])
#两数据框上下合并(行维度合并)
all_data = pd.concat([data1,data2])
all_data
#两数据框左右合并(列维度合并)
all_data_col = pd.concat([data1, data2],axis = 1)
all_data_col
#按照subject_id的值对all_data和data3作合并(merge类似SQL里的join)
pd.merge(all_data,data3,on='subject_id')
#对data1和data2按照subject_id作内连接
pd.merge(data1, data2, on='subject_id', how='inner')
#找到 data1 和 data2 合并之后的所有匹配结果
pd.merge(data1, data2, on='subject_id', how='outer')














 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









