







Natural Language-centered Inference Network for Multi-modal Fake News Detection
文章来源:https://www.ijcai.org/proceedings/2024/0281.pdf
摘要
互联网上带有图片和文本的假新闻的激增已经引发了广泛的关注。现有的研究在跨模态信息交互和融合方面做出了重要贡献,但未能从根本上解决新闻图像、文本和新闻相关外部知识表征之间的模态差距。在本文中,我们提出了一种新的以自然语言为中心的推理网络(NLIN)用于多模态假新闻检测,通过将多模态新闻内容与自然语言空间对齐,并引入一种编码解码器架构来充分理解新闻。特别地,我们通过将新闻图像和与新闻相关的外部知识转换为纯文本内容,将多模式的新闻内容统一为文本模式。然后,我们设计了一个多模态特征推理模块,它由一个多模态编码器、一个单模态上下文编码器和一个具有提示短语的推理解码器组成。该框架不仅充分提取了跨模态新闻内容的潜在表现,而且利用提示短语来刺激预先训练好的大型语言模型强大的上下文学习能力,来推理新闻内容的真实性。此外,为了支持多模态假新闻检测领域的研究,我们开发了一个具有挑战性的大规模、多平台、多域多模态中国假新闻检测(CFND)数据集。大量的实验表明,我们的CFND数据集是具有挑战性的,并且所提出的NLIN优于最先进的方法。
1.介绍
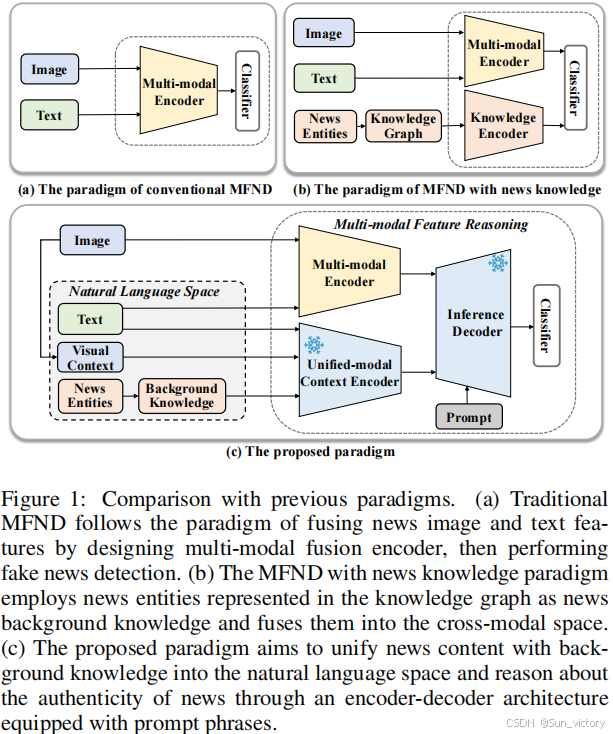
为了解决这一问题,人们提出了一系列多模态假新闻检测器来探索跨模态信息交互和融合,以识别假新闻中的异常。之前的大部分工作都遵循了融合新闻图像和文本特征的范式通过多模态编码器随后进行假新闻检测(如图1(a)所示)。这些方法只是利用连接操作,注意机制或辅助任务来捕捉图像和文本特征之间的潜在语义相关性。然而,这些方法由于缺乏与外部事实的联系,因此无法获得具有说服力和可解释的结果。因此,为了验证新闻的真实性在知识层面上,一些方法挖掘背景知识信息的新闻和作为客观证据的来源通过提取新闻实体和链接到知识图,这是结构如图1 (b).所示。例如,其中一些人将新闻实体及其上下文作为外部知识,并利用注意机制来评估新闻实体表征的权重或在知识层面上发现不一致的语义信息。然而,上述方法忽略或没有从根本上解决了图像、文本和新闻知识表示之间的模态差距的棘手问题,导致该模型无法充分提取新闻内容的跨模态相关特征。因此,为了克服这一困境,一个潜在的有效的解决方案是统一多模态新闻内容到文本模式,利用强大的上下文学习能力和丰富的隐式知识的大型语言模型(LLM)提取新闻交叉相关特性和原因新闻内容的真实性。
虽然假新闻跨越了地理和语言的边界,但大多数现有的工作和数据集都集中在英语领域,在其他语言领域的内容有限。以中国领域为例,现有的多模态假新闻检测数据集只有微博和微博-21且他们的数据源往往局限在一个平台,这使得假新闻的表示往往更加均匀。同时,其数据规模受到限制,新闻内容更加过时,不利于检测当前的新闻内容,给中国假新闻检测的发展带来了一定的限制。因此,迫切需要一个大规模、多平台、多领域的中国假新闻检测数据集。
为了支持多模态假新闻检测领域的研究,我们制作了一个具有挑战性的多模态中国假新闻检测(CFND)数据集,该数据集从多个平台收集,包含来自多个领域的新闻。CFND由26,665个新闻样本组成,明显大于以前的中国数据集。此外,我们提出了一种新的以自然语言为中心的推理网络(NLIN)用于多模态假新闻检测,其一般结构如图1 ©.所示这种检测范式主要分为三个阶段: (1)新闻预处理阶段,我们采用图像标题、密集标注和OCR三种方法提取视觉上下文,从而在信息损失最小的情况下实现图像到文本的转换。在新闻相关的外部知识方面,我们从视觉上下文中提取视觉实体集,从新闻文本中提取文本实体集。然后将新闻实体链接到维基达数据库,获取每个实体的上下文描述,构建新闻背景知识。(2)在编码阶段,我们使用与LoRA结合的LLM编码器,将统一嵌入到自然语言空间的新闻内容,以获得新闻视觉上下文特征和文本上下文特征。同时,为了防止原始新闻信息的丢失,我们使用CLIP模型提取新闻多模态特征,并利用多模态映射网络将其映射到文本嵌入空间。(3)在解码阶段,我们引入了一个具有提示短语的推理解码器。该模块利用提示短语使LLM的解码器根据先前获得的新闻视觉上下文特征、文本上下文特征和多模态特征来推断新闻内容的真实性,同时将生成问题转化为分类问题,即解码器的位置指定输出作为语言分类的输入特征。大量的实验表明,我们的CFND数据集是具有挑战性的,并且所提出的NLIN优于最先进的方法。
本文的主要贡献如下:1.我们将所有的与新闻相关的信息(图像、文本和与新闻相关的外部知识)统一到自然语言空间中,从而从根本上解决了模态差距的影响。2.我们引入了一个编码-解码器体系结构,配备了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









