






HIVE:
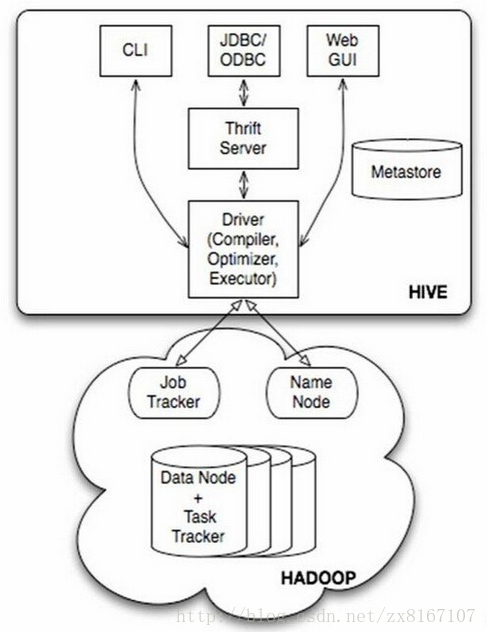
hive,是一款开源的数据仓库
1、hive不是数据库,而是数据仓库,主要依赖于hadoop来实现
2、底层文件系统是hadoop的hdfs,实现对hdfs上结构化数据的SQL操作HQL,速度较慢
3、计算引擎是hadoop的mapreduce
4、依靠存储在其他关系型数据库metastore来对hdfs结构化数据进行管理,实现类似数据库的功能
5、不具备数据库的一些主键、索引、update操作等特性,但是提供了分区、块索引、SQL等特性
6、比较适合存储海量的全量(历史+更新)轨迹数据,比对数据进行批量的挖掘、分析等操作
总结一下,hive是基于hadoop实现的数据仓库,适合存储海量全量数据,支持类SQL操作,性能相对较差,数据存储
有一定的限制,不支持更新、索引等事务。适合海量数据的挖掘和分析,通俗一点来说,hive其实就是借助mysql等数据库在
hadoop上层套了一个壳,来实现对hdfs上结构化数据的映射,为上层提供sql服务。
HBASE:
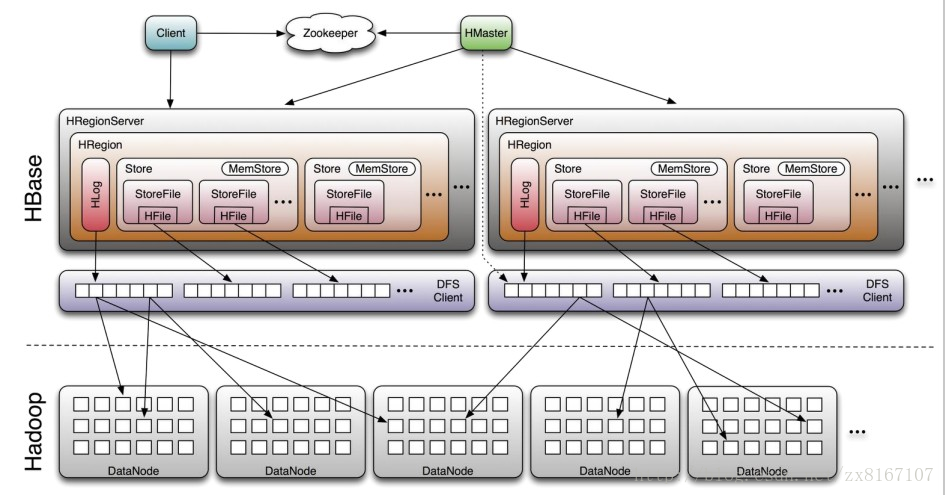
即Hadoop databse,顾名思义就是一个hadoop的数据库
1、nosql数据库之一,基于列式存储(列族),适合海量半结构化数据的存储和检索
2、不支持SQL、适合海量、带时间序列的数据的存储和检索、性能较好
3、原生支持基于rowkey的一级索引,rowkey按照字典序进行排序
4、运算执行引擎是hbase自身提供、底层存储基于hdfs
总结一下,hbase是NOSQL数据库的一种,基于分布式列式存储,适合海量半结构化带时间序列的数据的存储和检索,性能较优秀,hbase底层存储依赖于hdfs,与rdbms的区别与其他nosql类似,比如不支持SQL、事务性相对较差等等。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
综上,hbase是数据库、hive是数据仓库,而这有很大的区别、也有很多类似的地方比如都属于hadoop生态圈、存储都基于hdfs等。一般来说用hive作为海量结构化全量数据的存储、运算、挖掘、分析;hbase用来作为海量半结构化数据的存储、检索;这二者可以很好协同工作,hive上计算完的结果放在hbase中供检索,也可以将hbase里面的结构化数据和hive相结合,实现对hbase的sql操作等等。
--------------------- 作者:zx8167107 来源:CSDN 原文:https://blog.csdn.net/zx8167107/article/details/79265537?utm_source=copy 版权声明:本文为博主原创文章,转载请附上博文链接!














 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









