







目录
前言
我在学习算法和写代码的过程中喜欢先自己做一遍,想一遍,虽然有时候做的又慢又烂,程序冗余不说,逻辑还很混乱,但是我觉得,独立思考带来的成长原比直接消化答案来的多。如果每次写代码都是先看别人写好的在去抄思路,思维是会被局限的。
我这从次写Huffman构造函数的时候和课本想的思路一致但是确是两条不一样的思路和方法,也希望我的经验可以帮助到大家,开拓视野思维。
深度解析课本——选择排序
学c的大家都知道,我们最早学的两个算法就是冒泡排序和选择排序。有些同学看课本可能觉得书上的方法看着唬人,但就是选择排序:

我们的选择排序是这样的:
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
if (arr[i] < arr[j]) {
arr[i] <-> arr[j];
}
}
}选择排序外层循环限定范围,内层循环寻找到最小值放到指定位置。我们观察可以发现,书上构造算法是在第二层for之前定义了一些变量,第二个for之内一样通过if语句找两个最小值。一模一样,时间复杂度是O(n^2)。
我的优化思路
对于顺序存储Huffman树的一些见解:
根据以上代码我们可以确定其实这个构造本质就是排序,不过书上的算法并没有对存储位置进行排序,而是通过树的定义让他们有相对次序。以下是个人的一些见解:
既然采用了顺序结构,那顺序结构随机存取的优势我们应该更好的运用,哈夫曼树的顺序结构是通过索引寻址的方式存储,本质上和指针没什么区别,不利用顺序结构的优势那不如直接使用链表,递归起来更简单。
所以我遍通过排序的方式让他们在存储上有顺序,有又树定义的相对次序。
选择排序在这的缺点:
我们正常的选择排序在经过我们一次次搜索后,范围会逐渐缩小,但是这一题因为哈夫曼树的构造,结点数量越来越多,范围比较范围越来越大,效率遍低了,虽然还是n^2级别,但是算下来大概是二分之三n^2的样子,是正常选排时间的3倍。
使用索引表的思路:
我们如果提前将元素从小到大排序好,n个元素,就算是选排时间也是上述方法的1/3,然后通过索引访问的方式,我们只需遍历一遍不需要回溯就构造完成,构造哈夫曼树的时间复杂度是O(n),不过还要看排序的时间复杂度,选择冒泡O(n^2),快速O(n*log2 n)。
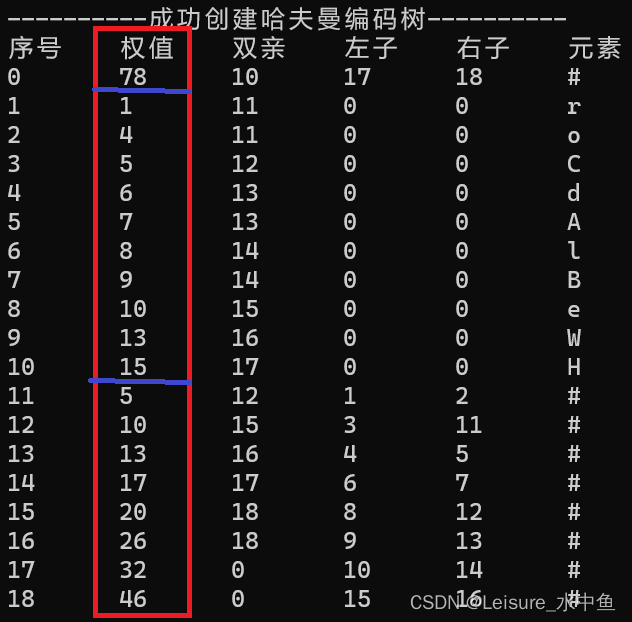
如图可以看到效果,0单元存储的是根节点,这是个人习惯,根节点的双亲闲着也是闲着,可以随时访问我便存放叶子结点数量,1-10单元存放的是叶子结点,权值小到大,11-18单元存放的是非叶子结点,也是从小到大排序。
所以我们的思路很明确使用两个索引指针index1和index2,index1访问权限是从1-10,index2访问权限是从11开始到权值为0之前,因为初始化权值为0,非叶子结点需要等匹配后分配权值。
我们只需要现在index1找到前两个权值记录下来,然后与index2的进行比较,index2访问如果index2较小元素大于index1较大元素,或者index指向的结点未分配,都可以直接使用index的两个结点进行匹配。否则进行比较一下。还需要一个指针j从11单元开始为9个非叶子结点赋值。
每一次最多3次可以选出小的两个,平均是2次。index1和index2是不进行回溯的,意思是访问过的结点都处理完成了。
索引构建Huffman树代码:
//num记录了叶子结点数量,*eht是全局变量
//优化后构造哈夫曼树(快排+索引查表)
EnHTree CreateEnHTree() {
//哈夫曼树初始化
eht = (EnHTree)malloc((2*num-1)*sizeof(EnHTNode));
if (!eht) {
printf("!!!malloc Error!!!\n");
exit(1);
}
int i, j = 0;
for (i = 0; i < 2 * num - 1; i++) {
eht[i].weight = eht[i].parent = eht[i].lChild = eht[i].rChild = 0;
if (i > 0 && i < num + 1) { //如果是叶子结点权,元素也给赋上
while (!count[j]) j++;
eht[i].data = (char)j;
eht[i].weight = count[j++];
}
else eht[i].data = '#';
}
eht[0].parent = num; //根节点没有父母拿来存叶子结点数量
//快速排序
QuickSort(1, num);
//构造哈夫曼树
unsigned int index1 = 1, index2 = num + 1;
j = num;
for (i = num + 1; i < 2 * num; i++) {
unsigned int min1 = -1, min2 = -1, lNode, rNode;
//找index1最小的两个、一个;只要最后一个叶子结点没有匹配那就继续
if (index1 <= num) {
lNode = index1;
min1 = eht[lNode].weight;
if (index1 < num) {
rNode = index1 + 1;
min2 = eht[rNode].weight;
}
}
//再与index2中已经匹配过的结点且小于min2的比较
while (eht[index2].weight && eht[index2].weight < min2) {
if (eht[index2].weight >= min1) {
min2 = eht[index2].weight;
rNode = index2++;
}
else {
min2 = min1; rNode = lNode;
min1 = eht[index2].weight;
lNode = index2++;
}
}
//对index1索引进行移动,回溯容易出事,所以不回溯
if (index1 == rNode || index1 == lNode) {
index1++;
if (index1 == rNode) index1++;
}
if (min1 + min2 < min1 || min1 + min2 < min2) {
printf("!!!Error Overflow!!!%d %d\n", min1, min2);
exit(1);
}
j = (j + 1) % (2 * num - 1);
eht[j].weight = min1 + min2;
eht[j].lChild = lNode;
eht[j].rChild = rNode;
eht[lNode].parent = j;
eht[rNode].parent = j;
}
printf("\n----------成功创建哈夫曼编码树----------\n");
return eht;
}
我将哈夫曼树的初始化也放在了一起,这样看着思路更清晰,不然没头没尾的。测试大量的数据没有出错,目前测试下来这个算法逻辑上和实验上暂时没有什么问题。还有一个重要的点,在后面对大量字符串编码的时候,无序表每次查找元素都需要全部遍历一遍,但是排序过后完全可以用二分查找大大减少时间。
总结
概要
选择排序的方法我理解上是暴力思维的解题,我自认为,接触数据结构也有3个月了,算法也学了很多,我们更应概去考虑更优方案了,而不是只单纯是解决问题,需要上升到怎么更好的解决问题上去了。
选择排序优缺点
选择排序非常简单容易理解,暴力思维,不需要花费太多脑子,很容易上手,不过简单既是优点,也是缺点。相比较索引,选择排序最大的优点就是不用考虑太多。
缺点1.是时间相对花费多一些,2.是没排序不方便后续有更多的操作,3.是没有发挥出顺序存储的优点,不如直接上链表。
索引建表优缺点
优点自然是更省时间,合理利用了顺序结构随机存取的特点,对后续的诸多操作有便利,查找上更加容易。
缺点是代码相对复杂,原理理解起来也不是那么容易,需要多花一些脑子功夫。2.是需要单独写排序的算法
自我总结
这一次感觉算法的设计是真的不容易,很多时候拿着别人现成的算法感觉很简单,但是自己设计算法的时候,原理都懂,但是在算法运行的时候总会有些许小bug,有些在小量数据看不出来,我上大量数据的时候查出一些bug,修改啥的,我自己也没想到,调试这么一小段代码我花了十个小时。
中间很大一部分时间是卡在我感觉我的思路,和我的算法按照我的思路推下去完全没问题,但是跑起来就是不太对,后来察觉是我最开始其实是index1进行赋值min1,min2的时候就增值,后来换掉之后回溯,我感觉是回溯回出问题了,把回溯给取消掉,index1的增长单独拿出来计算才弄好的。
这算是一次很棒的算法设计经历吧,希望我的分享对各位一起还在学习路上的小伙伴们有一丝帮助。
















 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











