







目录
1.规约Combiner概念
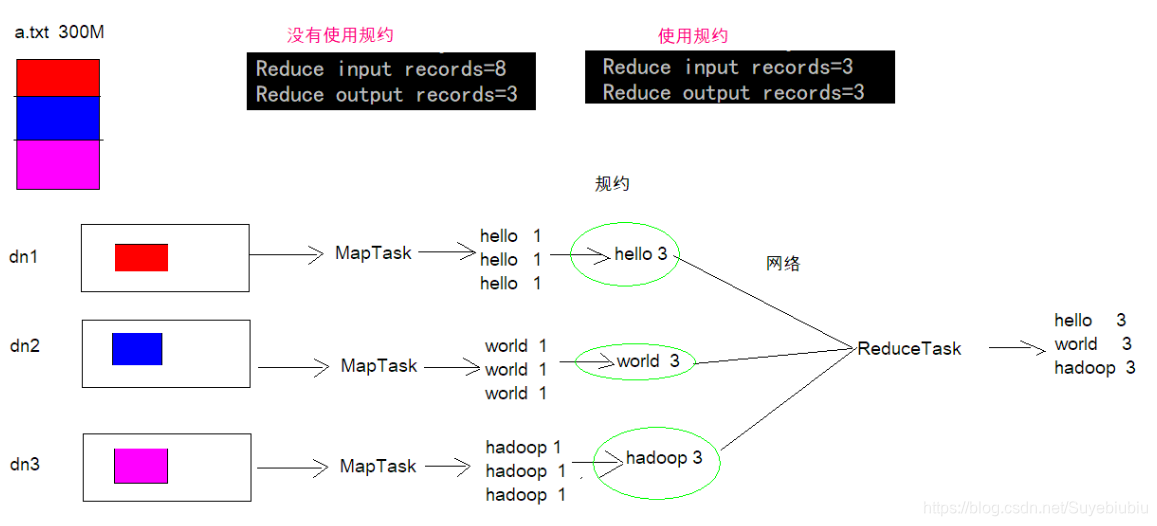
每一个 map 都可能会产生大量的本地输出,Combiner 的作用就是对 map 端的输出先做 一次合并,以减少在 map 和 reduce 节点之间的数据传输量,以提高网络IO 性能,是 MapReduce 的一种优化手段之一
- combiner 是 MR 程序中 Mapper 和 Reducer 之外的一种组件
- combiner 组件的父类就是 Reducer
- combiner 和 reducer 的区别在于运行的位置
- Combiner 是在每一个 maptask 所在的节点运行
- Reducer 是接收全局所有 Mapper 的输出结果
- combiner 的意义就是对每一个 maptask 的输出进行局部汇总,以减小网络传输量
2.规约Combiner图示
3.规约Combiner实现步骤

3.1 运行之前的wordcount
运行命令:hadoop jar day04_mapreduce_combiner-1.0-SNAPSHOT.jar ucas.mapredece.JobMain

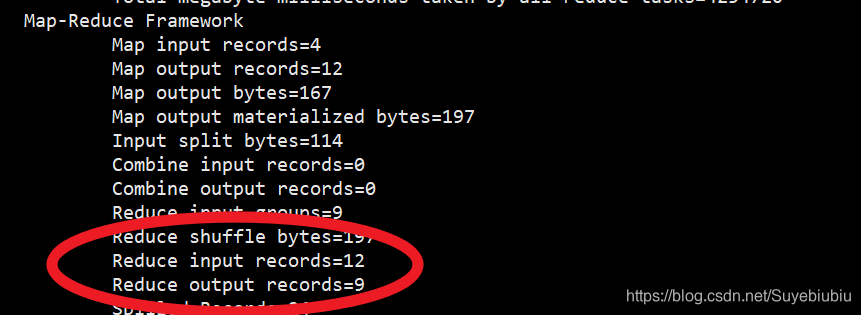
查看计数器:
3.2 规约代码
3.2.1 MyCombiner
package ucas.mapredece;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author GONG
* @version 1.0
* @date 2020/10/10 15:17
*/
public class MyCombiner extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
//1:遍历values集合
for (LongWritable value : values) {
//2:将集合中的值相加
count += value.get();
}
//3:将k3和v3写入上下文中
context.write(key, new LongWritable(count));
}
}
3.2.2 JobMain
package ucas.mapredece;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), JobMain.class.getSimpleName());
//打包到集群上面运行时候,必须要添加以下配置,指定程序的main函数
job.setJarByClass(JobMain.class);
//第一步:读取输入文件解析成key,value对
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://192.168.0.101:8020/wordcount"));
//第二步:设置我们的mapper类
job.setMapperClass(WordCountMapper.class);
//设置我们map阶段完成之后的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//第三步,第四步,第五步,第六步
//设置规约类
job.setCombinerClass(MyCombiner.class);
//第七步:设置我们的reduce类
job.setReducerClass(WordCountReducer.class);
//设置我们reduce阶段完成之后的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//两个分区用到两个reduce,设置reduce个数
//第八步:设置输出类以及输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.101:8020/wordcount_out"));
//上面那个路径时不允许存在的,会帮我们自动创建这个文件夹
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
/**
* 程序main函数的入口类
*
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Tool tool = new JobMain();
int run = ToolRunner.run(configuration, tool, args);
System.exit(run);
}
}
查看计数器:
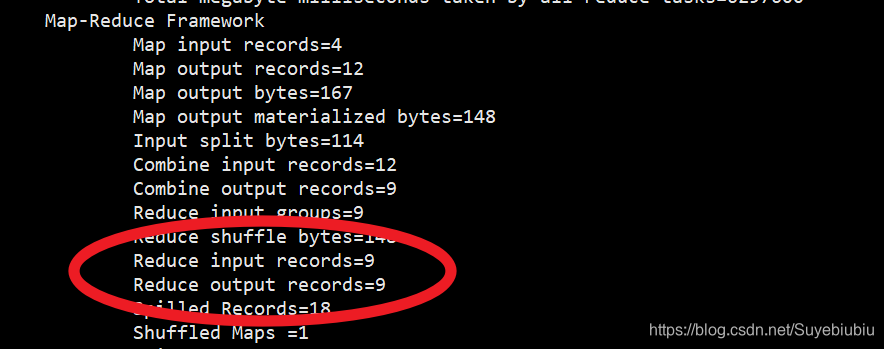
使用规约之后,reduce输入变少了,经过规约网络传输数据量大幅减少。
规约可以减少我们map阶段向reduce阶段传递的数据量,进而提高网络传输效率。














 1661
1661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









