







什么是对抗样本?
从2013年开始,深度学习模型在多种应用上已经能达到甚至超过人类水平,比如人脸识别,物体识别,手写文字识别等等。 在之前,机器在这些项目的准确率很低,如果机器识别出错了,没人会觉得奇怪。但是现在,深度学习算法的效果好了起来,去研究算法犯的那些不寻常的错误变得有价值起来。其中一种错误叫对抗样本(adversarial examples)。
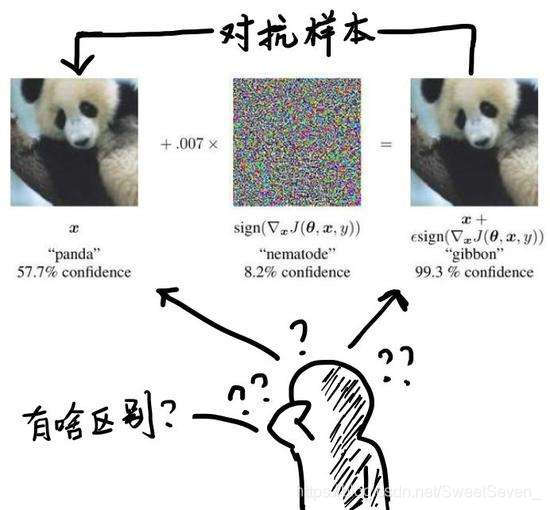
对抗样本(Adversarial examples)是指为了发现某些不被人们注意的特征而使最大化模型的损失函数,从而在数据集中通过故意添加细微的干扰(往往是人类肉眼所无法察觉的干扰)所形成的输入样本,会导致模型以高置信度给出一个错误的输出。
在图像识别中,可以理解为原来被一个卷积神经网络(CNN)分类为一个类(比如“熊猫”)的图片,经过非常细微甚至人眼无法察觉的改动后,突然被误分成另一个类(比如“长臂猿”)。
对抗样本存在的普遍性
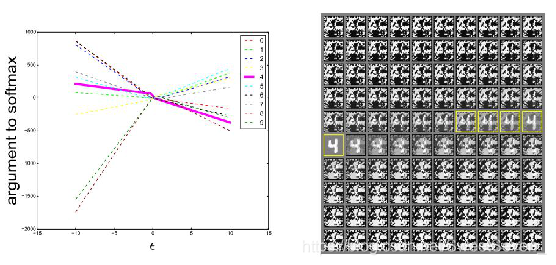
上图表明,在不同的 ϵ 下,可以看到FGSM可以在一维的连续子空间内产生对抗样本,而不是特定的区域。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









