









摘要
one-stage目标探测器通过同时优化分类损失和定位损失进行训练,前者由于锚的数量众多而遭受极端的前景-背景类别失衡问题。本文提出了一个新颖的框架,以分级任务代替one-stage检测器中的分类任务,并采用平均精度损失(AP-loss)解决分级问题,从而缓解了这一问题。由于其不可微性和非凸性,AP损耗无法直接优化。为此,我们开发了一种新颖的优化算法,该算法将感知器学习中的错误驱动更新方案与深度网络中的反向传播算法无缝结合。我们从理论和经验上验证了所提出算法的良好收敛性。实验结果表明,在不改变网络体系结构的情况下,基于APloss one-stage检测器在各种基准上效果可超过各种分类loss,从而显着提高了性能。
1、Introduction
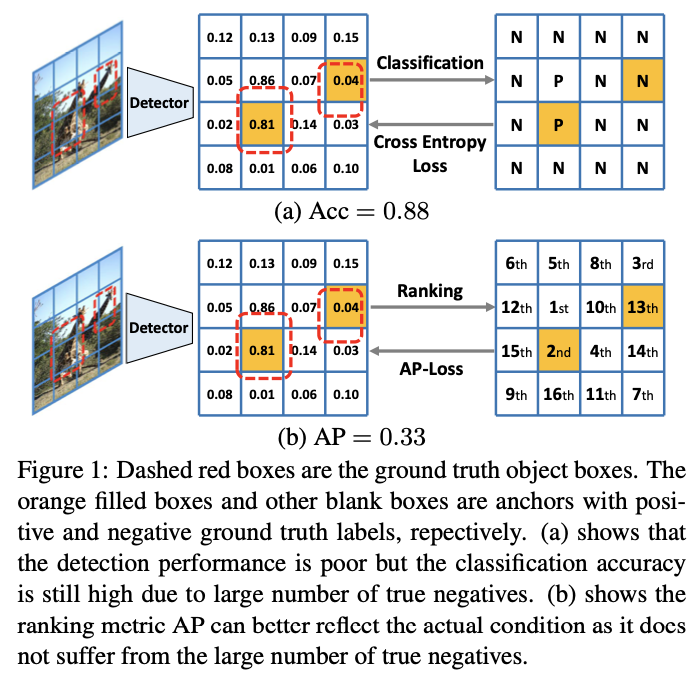
目标检测需要同时从大背景中定位和识别对象,由于前景和背景之间的不平衡,因此仍然具有挑战性。基于深度学习的检测解决方案通常采用多任务架构,该架构可处理具有不同损失功能的分类任务和定位任务。分类任务旨在识别给定框中的对象,而定位任务旨在预测对象的精确边界框。两级检测器[24、7、2、14]首先生成有限数量的对象框建议,因此可以通过对这些建议采用分类任务来解决检测问题。但是,对于one-stage检测器,情况有所不同,one-stage检测器需要直接从密集设计的候选框中直接预测对象类别。大量的框会导致前景和背景之间的不平衡,这会使分类任务的优化容易产生偏差,从而影响检测性能。可以看出,对于一个简单的解决方案,分类指标可能很高,该解决方案预测几乎所有候选框都带有负标签,而检测性能却很差。图1a展示了一个这样的例子。
为了解决one-stage目标检测器中的这一问题,一些工作引入了新的分类损失,例如平衡损失[22],焦点损失[15]以及量身定制的训练方法,例如在线硬示例挖掘(OHEM)[18,29] ]。这些损失独立地为每个样本(锚定框)建模,并尝试在分类损失中对前景样本和背景样本进行重新加权,以适应不平衡状况。这样做无需考虑不同样本之间的关系。设计的平衡权重是手工制作的超参数,无法在数据集中广泛推广。我们认为分类任务和检测任务之间的差距阻碍了one-stage检测器的性能。在本文中,我们建议在one-stage检测器中用分级任务代替分类任务,在分级检测器中,相关联的分级损失可以显式地建模样本关系,并且不依赖于正样本与负样本的比率。如图1b所示,我们采用平均精度(AP)作为我们的目标损耗,这在本质上与目标检测的评估指标更加一致。
但是,由于不可微性和不可分解性,直接优化AP损失并非易事,因此标准梯度下降方法不适用于这种情况。 这个问题有三个方面的研究。 首先,在结构化SVM模型中研究了基于AP的损耗[34,19],它限制了线性SVM模型,从而限制了性能。 其次,提出了一种结构化的铰链损耗[20]来优化AP损耗的上限而不是损耗本身。 第三,提出了近似梯度法[31,9]来优化AP损失,由于AP的非凸性和非准凸性,即使对于线性模型,效率也较低,并且容易陷入局部最优 -失利。 因此,对于AP损耗的优化仍然是一个未解决的问题。
在本文中,我们通过用分级任务代替one-stage检测器中的分类任务来解决这一难题,以便我们使用基于分级的损失AP-loss来处理类不平衡问题。此外,我们提出了一种新颖的错误驱动学习算法,可以有效地优化基于不可微AP的目标函数。更具体地说,将一些额外的变换添加到one-stage检测器的得分输出中以获得AP损失,其中包括将得分转换为成对差异的线性变换以及非线性且不可微的“激活函数”将成对的差异转换为AP损失的主要条件。然后,可以通过主要项和标记向量之间的点积获得AP损失。值得注意的是,对AP损失使用梯度法的困难在于使梯度通过不可微分的激活函数。受感知器学习算法启发[25],我们采用错误驱动的学习方案,将更新信号直接通过不可微分的激活函数传递。与梯度方法不同,我们的学习方案为每个变量提供一个与其所产生的误差成比例的更新信号。然后,我们采用反向传播算法将更新信号传递给神经网络的权重。我们从理论上和实验上证明了所提出的优化算法不会遭受目标函数的不可微性和非凸性。本文的主要贡献概述如下:
- 我们提出了一种在one-stage对象检测器中的新颖框架,该框架采用排名损失来处理类不平衡问题。
- 我们提出了一种错误驱动的学习算法,该算法可以通过理论和实验验证来有效地优化基于不可微和非凸AP的目标函数。
- 在不改变模型架构的情况下,针对不同种类的分类损失,采用最新的one-stage检测器提出的方法,我们显示出显着的性能提升。
2. Related Work
3. Method
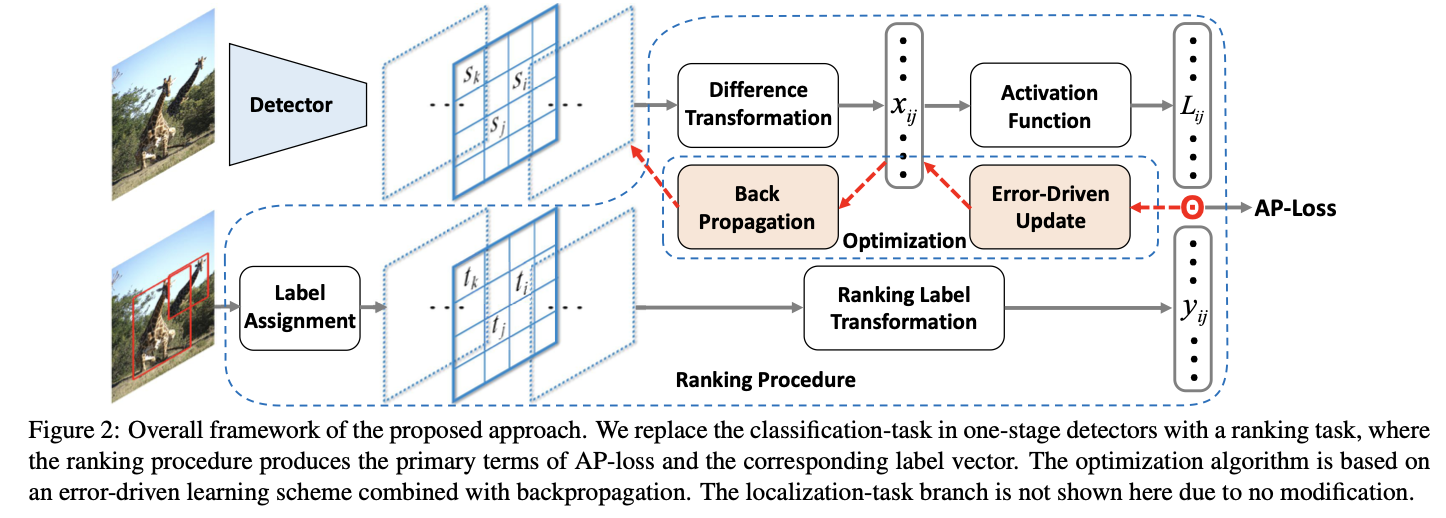
我们的目标是在RetinaNet [15]等一级检测器中用基于AP损失的排名任务代替分类任务。 图2显示了我们方法的两个关键组成部分,即排名程序和错误驱动的优化算法。 下面,我们将首先介绍如何从传统得分输出中得出AP损失。 然后,我们将介绍误差驱动的优化算法。 最后,我们还对提出的优化算法进行了理论分析,并概述了训练细节。 请注意,所有更改都是在分类分支的损失部分进行的,而不更改主干模型和定位分支。
3.1. Ranking Task and AP-Loss
3.1.1 Ranking Task
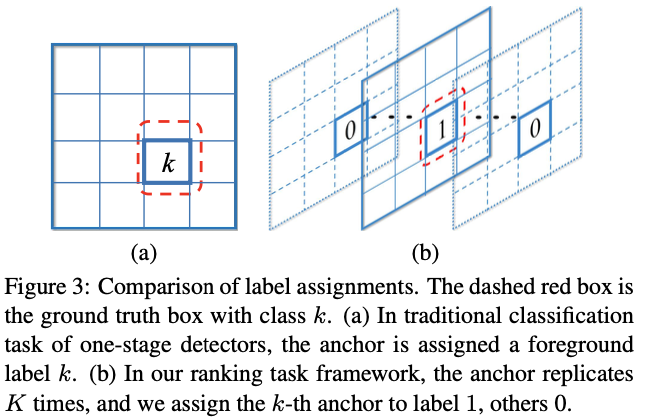
在传统的一级检测器中,给定输入图像I,假设预定义的框(也称为锚)集为B,每个框bi∈B将被分配标签ti∈{-1,0,1,。 。 。 ,K}基于GT和IoU策略[7,24],其中标签1〜K表示对象类别ID,标签“ 0”表示背景,标签“ -1”表示忽略的框。在训练和测试阶段,检测器为每个box bi输出一个得分矢量(s0i,…,sKi)。
在我们的框架中,不是用一个具有K + 1个维度得分预测的盒子,而是将每个盒子bi复制了K次以获得bik,其中k = 1,···,K和第k个盒子负责第k类。通过相同的IoU策略(标记-1不计入排名损失),将为每个box bik分配标签tik∈{-1,0,1}。因此,在训练和测试阶段,检测器将仅预测每个盒形块的一个标量得分sik。图3说明了我们的标签配方以及与传统包装的区别。
排名任务规定,每个肯定框的排名应高于所有负面框的得分。请注意,我们的排名结果的AP是根据所有类的分数计算得出的。这与对象检测系统的评估指标meanAP略有不同,后者针对每个类别计算AP并获得平均值。我们之所以这样计算AP,是因为应该为所有班级统一分数分布,而对每个类分别排名不能达到此目标。
3.1.2 AP-Loss
为简单起见,我们仍使用B表示复制后的锚框集,而bi表示不带复制下标的第i个锚框。 因此,每个框bi对应于一个标量分数si和一个二进制标签ti。 如图2所示,需要进行一些转换以形成等级损失。首先,差异转换将分数si转换为差异形式。
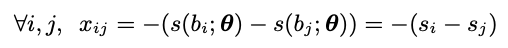
其中s(bi;θ)是基于CNN的得分函数,其中框bi具有权重θ。 排序标签转换将标签ti转换为相应的成对排序形式。
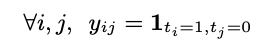
其中1是一个指标函数,仅当下标条件成立(即ti = 1,tj = 0)时才等于1,否则为0。然后,我们定义向量值激活函数L(·)来生成主要项 AP损失为
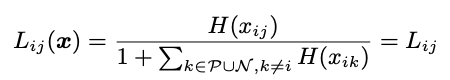
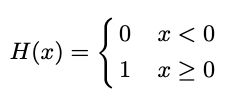
当不存在两个均等得分的样本时(即),则该排名被称为适当排名。 在不失一般性的前提下,我们将通过任意打破联系来将所有排名视为适当的排名。 现在,我们可以将AP-lossLAP公式表示为
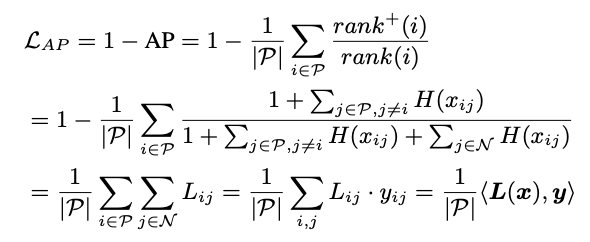
这里直接看公式理解还是很有难度,我看了好几遍才勉强理解一点。可以参考一下https://cloud.tencent.com/developer/article/1633043里的介绍。
首先明确这个AP-Loss核心是通过对score进行排名来,这里这个Lij分母是得分大于等于它的数量+1,实际上就是它的排名。当j对应的得分大于等于它时分子为1,否则为0。LAP就很好理解了,直接看最后一行的公式,其实就是负样本的中的score如果大于正样本则会产生loss,最终计算的是每个正样本被负样本超过的平均loss。
作者后来还提出了一种AUC-loss,但是证明AP-Loss更好。
3.2. Optimization Algorithm
3.2.1 Error-Driven Update
要做反向传播首先要有target和output差距的衡量。
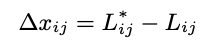
可以优化为下面的式子:
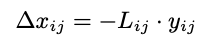
3.2.2 Backpropagation
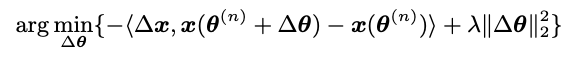
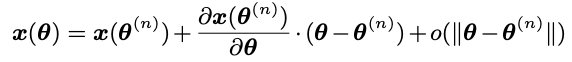
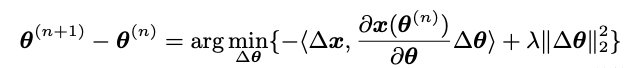
这里参考泰勒展开的思想吧。
通过找到静止点可以获得最佳解决方案。 然后,最优∆θ的形式与导数链规则相一致,这意味着可以通过将xij的梯度设置为-∆xij(参见公式9)并进行反向传播来直接实现。 因此,可以通过通过差值变换向后传播梯度来获得分数si的梯度:
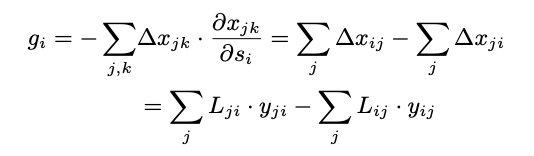
3.3. Analyses
收敛性:为了更好地理解AP-Loss的特性,我们首先对优化算法的收敛性进行理论分析,这是从原始感知学习算法的收敛性中得出的。
命题1如果满足以下条件,则AP损耗优化算法可保证以有限的步长收敛:
(1)学习模型是线性的;
(2)训练数据是线性可分离的。
该提议的证据在附录的附录1中提供。尽管由于强条件的需要收敛性较弱,但它是不平凡的,因为即使对于线性模型和线性可分离的数据,AP损失函数也不是凸或拟凸的,因此基于梯度下降的算法可能仍然会失败即使在如此强的条件下也可以收敛于平滑的AP损失功能。附录2给出了这样一个例子。这意味着,在这种情况下,我们的算法对于AP损失的优化效果仍优于近似梯度下降算法。此外,即使进行了一些细微的修改,即使训练数据不是不可分离的,累积的AP损失也可以通过学习模型的最佳性能来按比例限制。更多详细信息,请参见附录的附录3。
一致性:除了收敛以外,我们观察到所提出的优化算法与广泛使用的分类损失函数具有内在的一致性。
观察1:当激活函数L(·)采取softmax函数和损失增加阶跃函数的形式时,我们的优化算法可以表示为关于交叉熵损失和铰链损失的梯度下降算法。
该意见的详细分析在附录的附录4中提供。 我们认为观察到的一致性是基于“错误驱动”属性的。 众所周知,那些广泛使用的损失函数的梯度与它们的预测误差成正比,这里的预测是指激活函数的输出。 换句话说,它们的激活函数具有良好的特性:预测误差的矢量场是保守的,从而使其成为某些替代损耗函数的梯度。 但是,我们的激活函数不具有此属性,这使得我们的优化无法用任何代理损失函数表示为梯度下降。
3.4. Details of Training Algorithm

小型批处理训练小型批处理策略广泛用于深度学习框架[8、18、15],因为它比批处理大小等于1的情况具有更高的稳定性。小型批处理训练有助于我们的优化算法逃脱了所谓的“分数转换”场景。可以从一批图像和具有多个锚框的单个图像中计算AP损耗。考虑一个极端的情况:我们的检测器可以预测图像I1和图像I2的完美排名,但是图像I1中的最低分数甚至大于图像I2中的最高分数。两幅图像之间存在“得分偏移”,因此在计算每幅图像的AP损失时检测性能较差。在小批量中对图像进行分数汇总可以避免此类问题,因此小批量训练对于良好的收敛性和良好的性能至关重要。
分段步进函数在训练的早期阶段,分数si彼此非常接近(即,几乎对Heaviside步进函数H(x)的所有输入都接近零),因此输入的较小变化将导致较大的输出差异,这会破坏更新过程的稳定性。为了解决这个问题,我们用分段式步函数代替H(x):
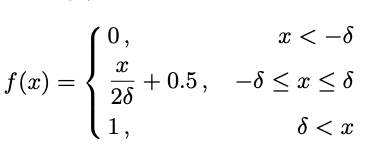
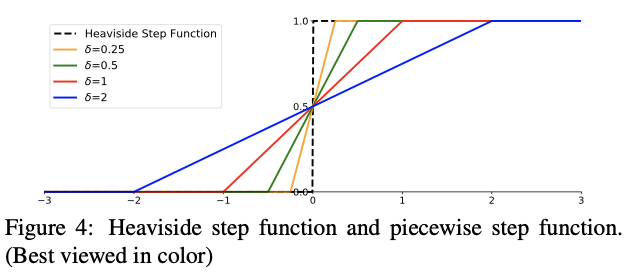
具有不同δ的分段步进函数如图4所示。当δ接近+0时,分段步进函数接近原始步进函数。请注意,f(·)仅与零点附近的H(·)不同。我们认为分段式步进函数的精确形式并不关键。其他仅与零点附近的H(·)不同的单调和对称平滑函数可能同样有效。 δ的选择与CNN优化中的权重衰减超参数密切相关。直观地,参数δ控制正样本与负样本之间的决策边界宽度。较小的δ会强制执行较窄的决策边界,这会导致权重相应地收缩(与权重衰减引起的效果相似)。实验中提供了更多细节。
插值AP插值AP [26]被许多对象检测基准(例如PAS-CAL VOC [5]和MS COCO [16])广泛采用。内插精确召回曲线[5]的常见理由是“减少由于示例等级的微小变化而导致的“摆动”对精确召回曲线的影响”。在相同的考虑下,我们采用插值AP代替了原始版本。具体而言,对Lij进行插值,以使第k个最小正样本的精度随k单调增加,其中精度为(1- −jj∈N Lij),其中i是第k个最小正样本的索引样品。值得注意的是,内插的AP是实际AP的平滑近似值,因此它是一种实用的选择,有助于稳定渐变并减少更新信号中“摆动”的影响。算法1中总结了基于插值AP的算法的详细信息。
4. Experiments
4.1. Experimental Settings
我们在最先进的one-stage检测器RetinaNet上评估提出的方法[15]。除非明确说明,实现细节与[15]中的相同。我们的实验是在两个基准数据集上执行的:PAS-CAL VOC [5]和MS COCO [16]。 PASCAL VOC数据集有20个类别,VOC2007包含9,963个图像的火车/阀门/测试,而VOC2012包含11,530个图像的火车/阀门。 MS COCO数据集有80个类别,其中包含123,287张用于火车/火车的图像。我们使用MXNET框架实现代码,并在具有两个NVidia TitanX GPU的工作站上进行实验。
PASCAL VOC:在VOC2007测试集上进行评估时,将在VOC2007和VOC2012训练集上训练模型。在VOC2012测试集上进行评估时,将在VOC2007和VOC2012训练集以及VOC2007测试集上训练模型。与MS COCO基准中使用的评估指标类似,我们还报告了在多个IoU阈值0.50:0.05:0.95上平均得到的AP。我们在公式14中设置δ=1。我们使用ResNet [8]作为骨干模型,该模型在ImageNet-1k分类数据集[4]上进行了预训练。在FPN的每个级别[14],锚点都有2个八度音阶(2k / 2,k≤1)和3个宽高比[0.5、1、2]。我们将批次标准化层固定为在训练阶段冻结。我们在2个GPU上采用了minibatch训练,每个GPU有8张图像。对所有评估模型进行了160个时期的训练,初始学习率为0.001,然后在110个时期除以10,然后在140个epoch再次除以10。使用0.0001的重量衰减和0.9的动量。我们采用与[18]相同的数据扩充策略,而在测试阶段不使用任何数据扩充。在训练阶段,输入图像固定为512×512,而在测试阶段,我们保持原始宽高比并调整图像大小,以确保短边有600像素。我们对每个类别应用非最大抑制,IoU为0.5。
MS COCO:所有模型都在广泛使用的trainval35k集(80k火车图像和val图像的35k子集)上进行训练,并在minival集(val图像的5k子集)或测试开发集上进行测试。我们为网络训练了100个epoch,初始学习率为0.001,然后在60个时epoch时将其除以10,然后在80个epoch再次除以10。其他细节与PASCAL VOC相似。
4.2. Ablation Study
我们首先调查设计框架对建议框架的影响。 我们将ResNet-50固定为骨骼,并在PASCAL VOC2007测试仪上进行了一些受控实验(如果有说明,则为COCO minival),以进行该消融研究。
4.2.1 Comparison on Different Parameter Settings
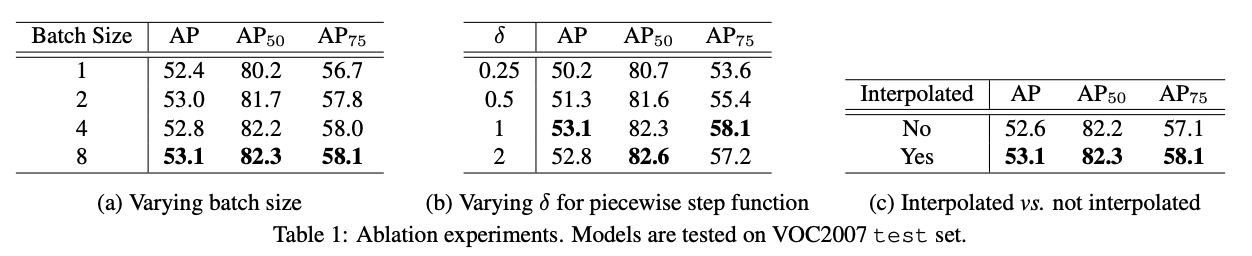
在这里,我们研究第3.4节中介绍的实际修改的影响。所有结果如表1所示。小批量训练:首先,我们研究小批量训练,并在表1a中报告不同批次大小的检测器结果。它表明较大的批处理大小(即8)优于所有其他较小的批处理大小。这验证了我们先前的假设,即大型小批量训练有助于消除不同图像的“得分偏移”,从而通过稳健的梯度计算来稳定AP损失。因此,在我们的进一步研究中将使用批处理大小= 8。
分段步进函数:其次,我们研究分段步进函数,并在表1b中报告检测器在具有不同δ的分段步进函数上的性能。如前所述,我们认为δ的选择是微不足道的,并且取决于其他网络超参数,例如权重衰减。较小的δ会使函数更尖锐,从而在初始阶段产生不稳定的训练。较大的δ会使函数偏离原始AP损耗的属性,这也会使性能恶化。 δ= 1是我们进一步研究中使用的一个很好的选择。
插值AP:第三,我们研究插值AP在优化算法中的影响,并在表1c中列出结果。相对于标准AP,观察到插值AP的边际收益,因此我们在以下所有研究中都使用插值AP。
4.2.2 Comparison on Different Losses
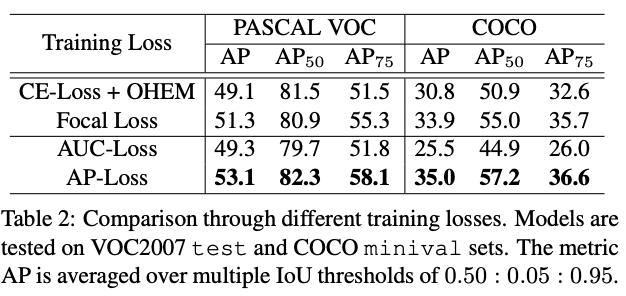
我们在RetinaNet上评估了不同的损失[15]。结果显示在表2中。我们将基于分类的传统损失(如焦点损失[15]和OHEM的交叉熵损失(CE损失)[18])与基于排名的损失(如AUC损失和AP损失)进行了比较。尽管在COCO数据集上,焦点损失明显优于使用OHEM的CE损失,但有趣的是,在PASCAL VOC上,焦点损失的性能并没有优于AP50的CE损失。这可能是因为焦距损失的超参数被设计为适合不适合PASCAL VOC的COCO数据集上的不平衡条件,因此如果不调整其超参数,焦距损失将不能很好地推广到PASCAL VOC。拟议的AP损失在这两个数据集上的表现均优于其他所有损失,这证明了其在处理不平衡问题上的有效性和更强的泛化能力。值得注意的是,AUC损失的表现要比AP损失差得多,这可能是由于AUC对每个错序对的惩罚相等,而AP在预测排名较高的位置对错序的惩罚更大。显而易见,对象检测评估对具有更高置信度的对象的关注更多,这就是AP提供更好的损耗度量的原因。此外,如图5a所示,在不同的训练迭代中对检测性能的评估概述了AP丢失对于快照时间点的优越性。
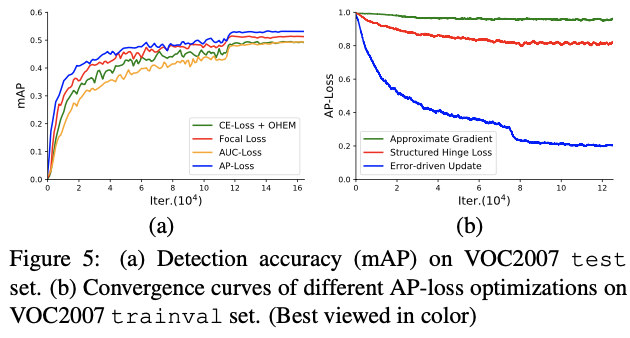
4.2.3 Comparison on Different Optimization Methods
我们还将优化方法与近似梯度法[31,9]和结构化铰链损耗法[20]进行了比较。两者[31,9]分别用平滑的期望值和包络函数近似估计AP损耗。按照他们的指导,我们用S形函数代替AP损失中的阶跃函数,以将梯度限制为零或未定义,同时仍保持形状类似于原始函数。与[9]相同,我们采用对数空间目标函数,即log(AP +ε),以使模型能够从初始状态快速逃脱。我们在VOC2007训练集上训练检测器,并关闭边界框回归任务。图5b中所示的收敛曲线揭示了一些基本观察结果。可以看出,通过近似梯度法优化的AP损失甚至没有收敛,这可能是因为其非凸性和非准凸性在直接梯度下降法上失败了。同时,通过结构化铰链损失方法[20]优化的AP损失收敛缓慢并稳定在0.8附近,这比通过我们的错误驱动更新方案优化的AP损失的渐近极限差。我们相信,这种方法并不能直接优化AP损失,而是可以优化其上限,这是由判别函数控制的[20]。在排序任务中,该判别函数是手工挑选的,并且具有类似AUC的形式,这可能会导致优化过程中的可变性。
4.3. Benchmark Results
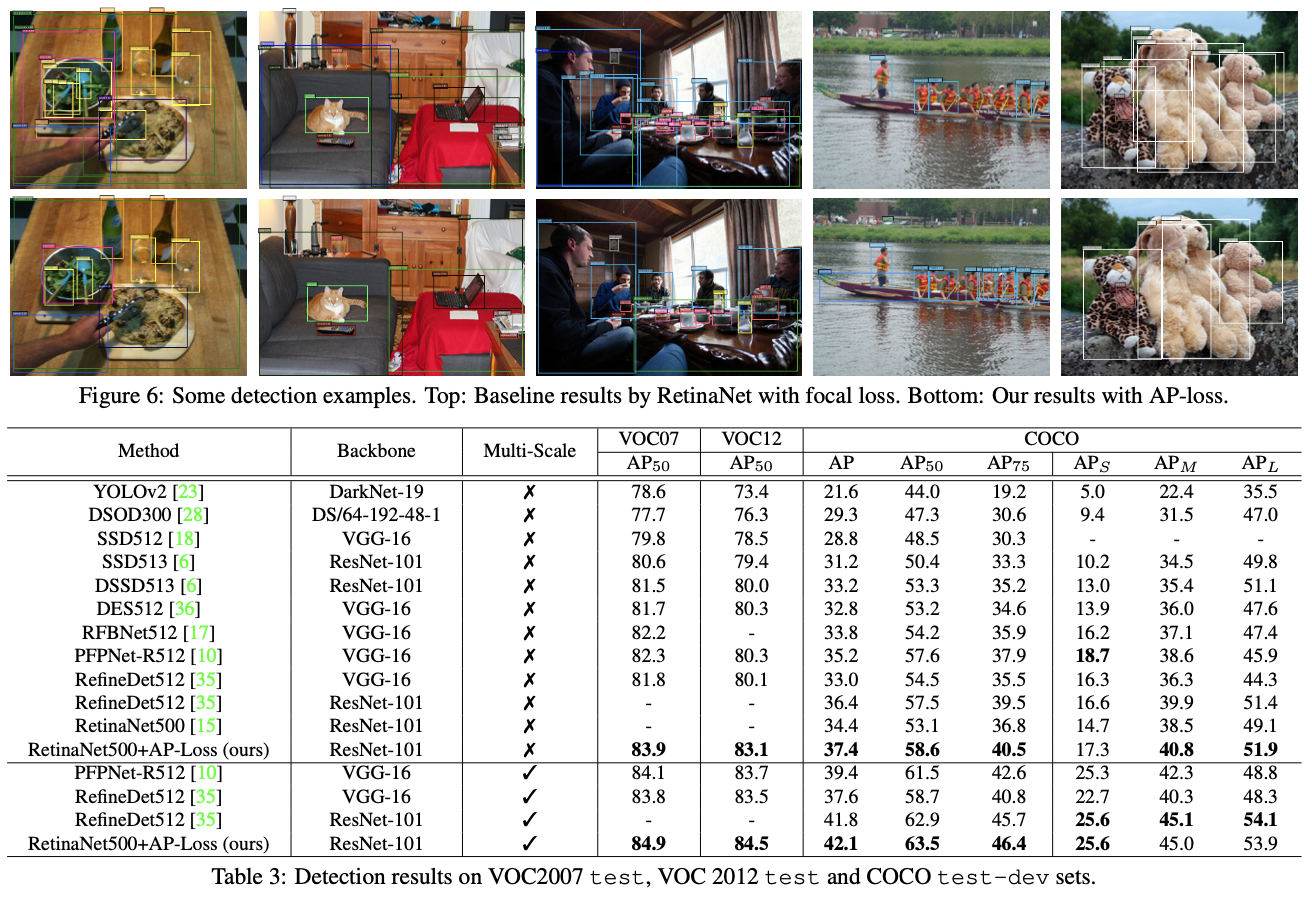
利用消融研究中选择的设置,我们进行了实验,以在三种广泛使用的基准(即VOC2007测试,VOC2012测试和COCO测试开发集)上将建议的检测器与最新的一级检测器进行比较。在消融研究中,我们使用ResNet-101作为骨干网络,而不是ResNet-50。我们使用500像素的图像比例进行测试。表3列出了与最新的一级检测器(例如SSD [18],YOLOv2 [23],DSSD [6],DSOD [28],DES [36],RetinaNet [15])相比较的基准结果。 ],RefineDet [35],PF-PNet [10],RFBNet [17]。与基线模型RetinaNet500 [15]相比,我们的检测器在COCO数据集上实现了3.0%的改进(37.4%对34.4%)。图6展示了RetinaNet的一些检测结果,包括焦距损失和AP损失。此外,我们的检测器在所有三个基准测试中均优于其他所有用于单标度和多标度测试的方法。我们应该强调的是,这证明了我们的AP损失的巨大有效性,因为我们的检测器仅用RetinaNet中的AP损失替换了焦点损失,而无需使用哨声和钟声,而无需使用先进的技术即可实现如此出色的性能提升。例如可变形卷积[3],SNIP [30],群组规范化[33]等。使用这些技术和其他可能的技巧可以进一步提高性能。我们的检测器具有与RetinaNet500 [15]相同的检测速度(即,一个NVidia TitanX GPU上约为11 fps),因为它不会改变推理的网络架构。
5. Conclusion
在本文中,我们通过用分类子任务替换分类子任务,并提出用AP-Loss解决分类任务,来解决一阶段目标检测器中的类不平衡问题。 由于AP损失的不可微性和非凸性,我们提出了一种基于感知器学习的基于错误驱动的更新方案来对其进行优化的新颖算法。 我们对所提出的优化算法进行了扎根的理论分析。 实验结果表明,我们的方法可以显着改善最新的一级检测器。
总结
实现思路
作为one-stage目标检测,作者总体框架仍然使用了RetinaNet,只是其将classification替换为了ranking,将交叉熵替换为了AP-Loss,并且设计了相应的反向传播计算方式。localization部分没有进行更改。
另外,label也从每个anchor box可能的k + 2个值改为将anchor box复制k倍,每个值为0或1.表示是否属于这一类。
核心贡献与步骤创新
作者针对目标检测中分类问题的局限性,将分类任务替换为了排序问题,提出了一种AP-Loss,又由于该loss无法直接进行反向传播,作者还设计了其反向传播策略。简单来说,作者设计了一种rank-loss来进行one-stage目标检测,并提出了其错误驱动的学习算法,能够有效的优化该loss,并取得了SOTA。
读完本文感觉难度还是很大的,因为其相对于一般的cv论文有较多的数学推导与算法,其创新也主要是从这个层面。
作者去思考了one-stage存在的问题,发现由于前景背景的比例不平衡,经常出现分类效果不错但是检测表现就很差的问题。一般来说是分类然后通过交叉熵来优化,而作者用排序来替换了分类,令正样本的序号位置更靠前。如果从分类的角度出发,由于背景比例很高,所以前景个别地方出错了也不会有太大的影响,而rank这种思路就将其放大了,能够更有效地优化。这也是发现问题解决的问题的过程吧。
rank说起来简单,作者这种基于rank的loss也是经过了精心的设计,无论是其意义还是数学计算角度,其反向传播过程也是经过了数学的推导。
实验目的
one-stage目标检测需要同时进行识别和定位两个过程,由于前景和背景的不平衡,经常出现分类效果很好但检测效果很差的现象。针对这个问题也有很多新的loss函数提出。作者工作的目的便是设计了一种新的loss。
衡量指标
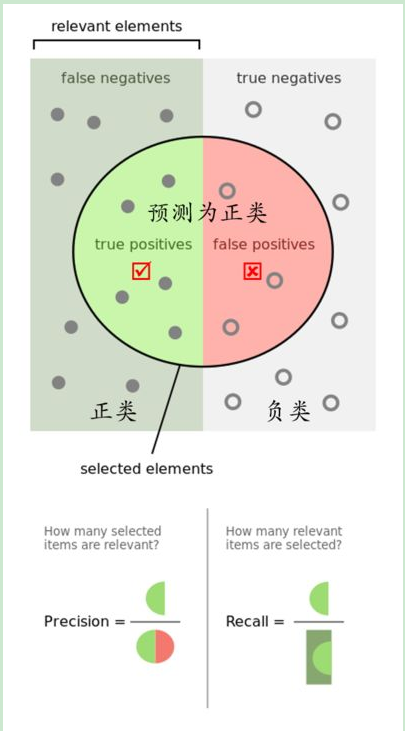
AP是指average precision,平均精确率,即多类预测的时候每一类的precision取平均。而AP50,AP60,AP70等等指的是取detector的IoU阈值大于0.5,大于0.6,大于0.7等等,数值越高,精确率越低,表明越难。
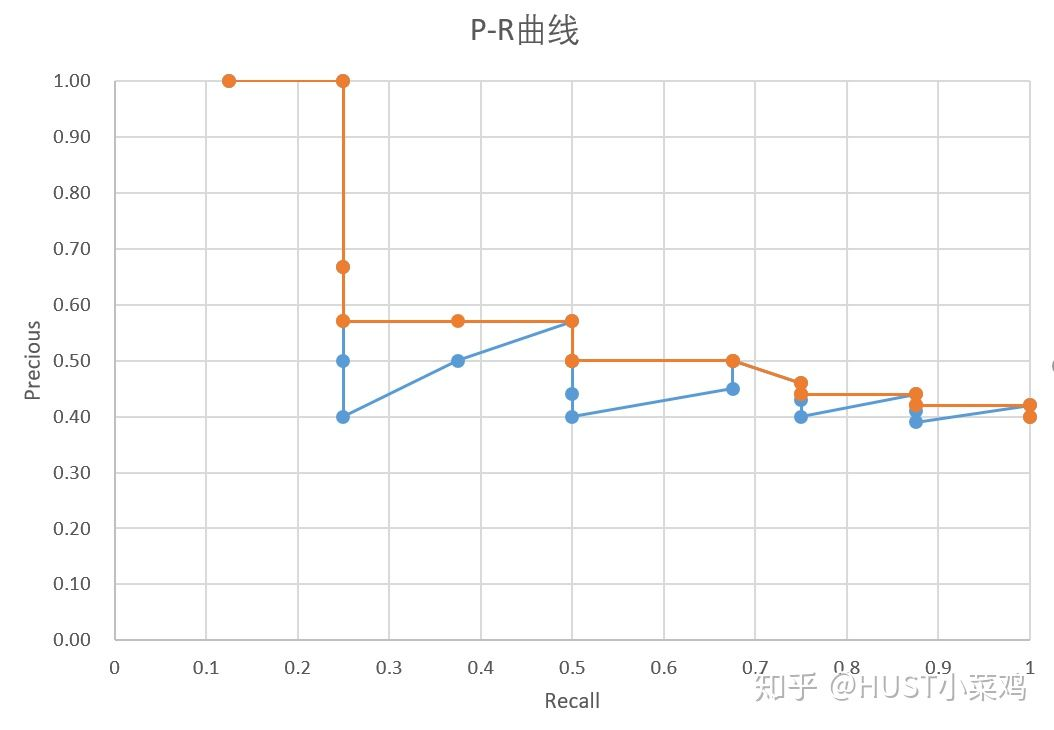
计算出AP之后,对所有的类别的AP求平均就可以得出整个数据集上的mAP。
Interplolated AP(Pascal Voc 2008 的AP计算方式)
Pascal VOC 2008中设置IoU的阈值为0.5,如果一个目标被重复检测,则置信度最高的为正样本,另一个为负样本。在平滑处理的PR曲线上,取横轴0-1的10等分点(包括断点共11个点)的Precision的值,计算其平均值为最终AP的值。
https://zhuanlan.zhihu.com/p/88896868
实验设计
作者的实验思路还是比较清晰的。
对比不同参数设计,包括batch size, δ和是否Interpolated。
然后对比不同的loss值,包括CE-Loss + OHEM、FocalLoss、AUC-Loss和AP-Loss。
然后就是对比不同的优化方法,包括本文提出的优化方法与近似梯度法[31,9]和结构化铰链损耗法对比,效果如图:
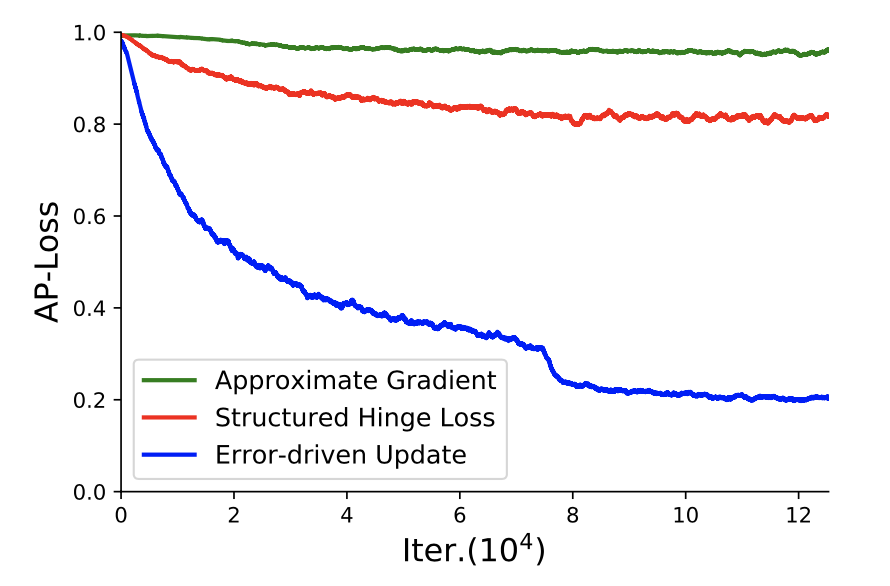
最后就是与一些baseline对比了,各种backbone,各种目标检测方法,确实是达到了SOTA。
所以从设计实验的角度,也就是把本文提出的东西与之前的对比一下,比如提出了AP-Loss和其反向传播算法,那么就对比一下其他loss与其他优化算法。然后作为目标检测,再与baseline比较一下,包括自己实验内的东西也可以比较一下参数。简单说就是实验内与实验间两个层面。
改进方案
这篇文章确实挺难的,要改进也不好改。但首先可以跟进一下对心的目标检测模型啊,估计会有点提高。比较深层的改进还是需要去发现问题解决问题。















 3742
3742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









