







图像大小
文件头+图像(+调色板)
色位图像
包括:单色位图、16色位图、256色位图
文件头大小(字节):40+14=54
图像:色图像存储采用调色板方式存储,将一张图片试做一个二维矩阵,那么每一个点的值,存的是调色板表的索引值,每一个值对应调色板里的一种颜色,以此来表示图像中点的颜色。
调色板:一般多少色的图像,调色板就有多少种颜色,每种颜色存储需要4个字节,那么调色板的大小就是 颜色数 x 4 个字节。那么存储这么多种的颜色,就需要对应个数的二进制位。如:16色图像,我们要想在矩阵中表示出他的颜色,就需要24,也就是4位来存储,记录所有的这16种颜色的索引;又如256色图像,我们就需要28,也就是8位来表示出所有的256种颜色对应的索引值。
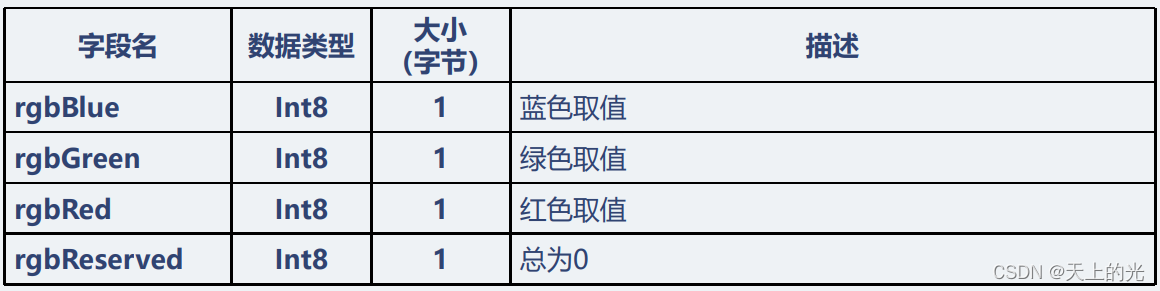
调色板的思路是:先用一定的空间,把颜色存储起来,每种对应一个数字;那么我们在图像矩阵的每一个位置,就不用存储这个像素点的颜色信息了,只要存代表这种颜色的序号就可以了。那么在一定情况下,就可以达到节省空间的效果。
首先我们做一道题先来感受一下:
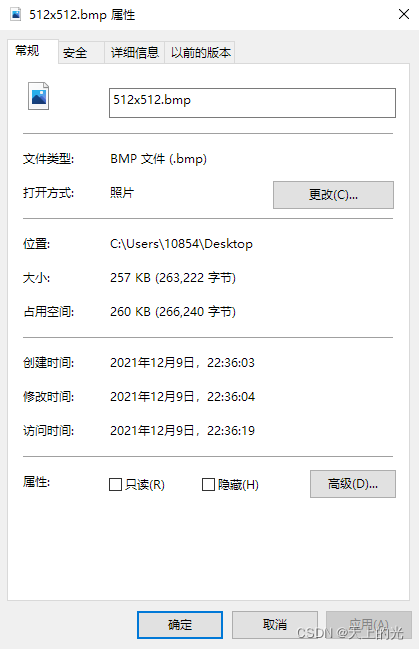
假定windows下的一 幅 256色 bmp图像的分辨率大小为512*512,试计算图像的存储大小(包含文件头、文件信息头和调色板) ,并给出详细的计算过程。
在这里,头文件占54个字节,调色板大小占256 x 4个字节
那么,对于这道题,根据理论逻辑就应该是:
像素大小 = 头文件 + 调色板 + 图像矩阵
(40+14) + 256 x 4+ (8 x 512 x 512) / 8 = 263222 字节
(注意:单位是字节。计算存储大小一定要时刻注意单位到底是bits还是字节!)
实际演示图如下:
还是可以理解的吧?然后接下来,我们在此基础上引入一个概念补齐原则(又称:对齐原则)。对于数据的存储,我们在计算机组成原理中曾经讲到,如果信息以字节为单位存储,我们知道读写速度是很快的。在Windows下,我们像素的最小存储单位是一个字节,而如果行的最后位数不足一个字节(8位),则需要补齐一个字节,这个过程我们称做补齐原则。
补齐原则
Windows默认的扫描的最小单位是4字节,如果数据的对齐满足这个值,对于数据的获取速度等会有很大的增益。
因此,BMP图像顺应了这个要求,要求每行的数据的长度必须是4的倍数,如果不够,需要进行比特填充(以0填充),以达到按行的快速存取。这时,位图数据区的大小就需要重新计算。
注意:补齐原则只关注行元素,对于列则无需补齐。
那么,有了以上的信息,我们就做一道题计算一下。
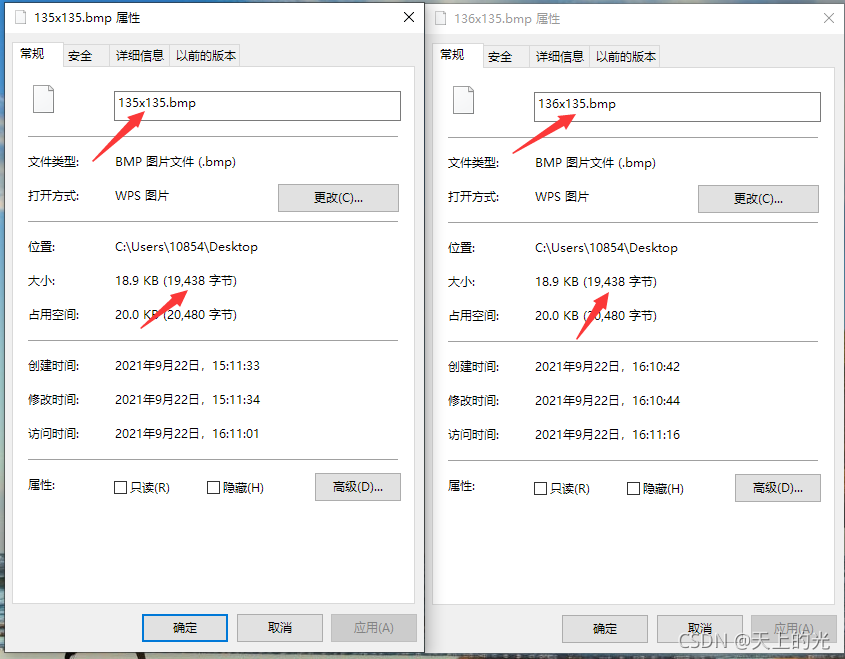
假定windows下的一 幅 256色 bmp图像的分辨率大小为135*135,试计算图像的存储大小(包含文件头、文件信息头和调色板) ,并给出详细的计算过程。
在这里,头文件占54个字节,调色板大小占256 x 4个字节
公式为:
头文件 + 调色板 + [ (行像素 x 位数 + 31 ) / 32 ] x 4 x 列像素
那么,对于这道题,最终结果就应该是:
(40+14)+256 x 4+[ (135 x 8+31) /32 ]x 4 x 135=19438
好,那我们512x512的那一道题是不是算错了呢?我们发现,因为其满足倍数要求,自然无需补齐,所以也就是正确的。
回过头来,我们将 135x135 与 135x136 进行比较也可以发现,行135 与 行136 最终图像大小相同,说明 列 不实行补齐原则。
那么我们把上题做一些改动,将256色改为16色,计算如下:
(40+14)+16 x 4+[(135 x 4+31 ) / 32] x 4 x 135=9298

那么对于公式,我们就可以这么理解(个人分析,可不看):
行像素 x 位数 可以算出一行像素的总位数
+31是为了实现向上取整对向下取整的转化 /32再向下取整,可理解为求行像素的字的个数(32位系统,1字=4字节)
再*4就是行像素的字节数
然后 x 列像素 就是整个图像存储所需的字节数
最后加上 文件头 + 调色板,即为所求。
彩色位图
包括:16位高彩色位图(16位位图)、24位真彩色位图(24位位图)、32位增强真彩色位图(32位位图)。
文件头大小(字节):40+14=54
图像:这几种位图,意为:图像中的某个像素,可以用。。位来表示其颜色种类数。
如:24位图,就是每一个像素点,都有24位来表示它的颜色。那么也就是说一个像素可以有224种颜色。
16位图像使用2字节保存颜色值,常见有两种格式:5位红5位绿5位蓝和5位红6位绿5位蓝, 即555格式(最后一位保留设为0)和565格式。
24位图像使用3字节保存颜色值,每一个字节代表一种颜色,按红、绿、蓝排列。
32位图像使用4字节保存颜色值,每一个字节代表一种颜色,除了原来的红、绿、蓝,还有 Alpha通道,即透明色。
其实这种程度的图像颜色就已经十分丰富,已经不是人眼可以分辨的了。所以,我们称为:高彩色、真彩色。那么颜色丰富,代价自然也就是存储空间的需求加大。除此之外,这种图像的存储是不需要调色板的,所以我们就可以得到图像的大小计算公式为:
头文件 + [ (行像素 x 位数 + 31) / 32] x 4 x 列像素
那么接下来看一道例题,我们用135 x 135来举例:
假定windows下的一 幅 24位位的 bmp图像的分辨率大小为135*135,试计算图像的存储大小(包含文件头、文件信息头和调色板) ,并给出详细的计算过程
就应该是:54 + [ (135 x 24 + 31 ) / 32 ] x 4 x 135 = 55134



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









