







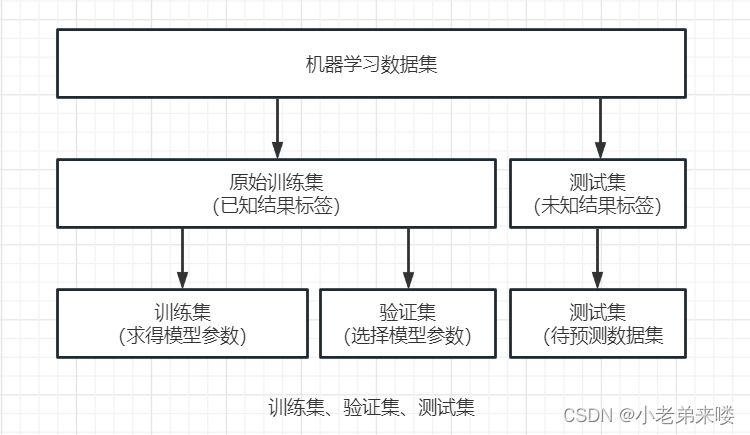
 文章讲述了模型选择和超参数优化的过程,包括数据集的切分,如训练集、验证集和测试集的常见比例设置。介绍了使用Python的sklearn库进行数据划分以及S折交叉验证的方法,以KNeighborsClassifier模型为例展示了如何通过交叉验证选择最佳的超参数K。最后,文章强调了交叉验证在提升模型泛化能力中的重要性。
文章讲述了模型选择和超参数优化的过程,包括数据集的切分,如训练集、验证集和测试集的常见比例设置。介绍了使用Python的sklearn库进行数据划分以及S折交叉验证的方法,以KNeighborsClassifier模型为例展示了如何通过交叉验证选择最佳的超参数K。最后,文章强调了交叉验证在提升模型泛化能力中的重要性。
模型选择,又称超参数选择,目的是确定模型使用的超参数
具体的过程:首先在训练集和验证集上对多种模型选择(超参数选择)进行验证,选出平均误差最小的模型(超参数)。选出合适的模型(超参数)后,可以把训练集和验证集合并起来,重新把模型训练一遍,得到最终模型,然后再用测试集测试其泛化能力。
1.1 数据集切分
在有监督学习问题中,一般会给两个数据集:训练集(Training Set)和测试集(Test Set)
训练集是已知结果标签的数据集,主要用来训练模型
测试集是未知结果标签的数据集,需要我们用模型去预测结果标签
在进行模型训练时我们一般会对原始训练集按比例进行划分,一部分作为训练集,另一部分作为验证集
对于数据集在万这个数量级的,通常采用的比例为 训练集:验证集:测试集 = 6:2:2
对于百万级的数据集,通常采用 98:1:1,或 99.5:0.3:0.2的比例
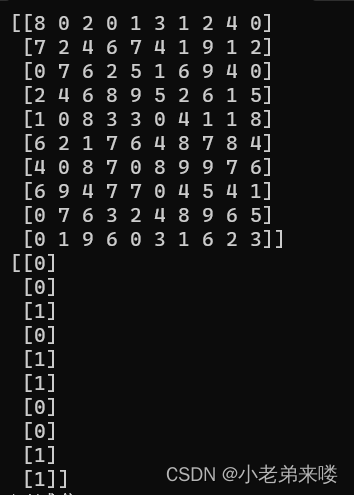
Python实现:
import numpy as np
#生成数据集
X = np.random.randint(low = 0,high = 10,size = (10,10)) #原始训练集特征
y = np.random.randint(low = 0,high = 2, size = (10,1)) #原始训练集类别标签
print(X)
print(y)原始训练集:
使用model_selection类中的train_test_split函数将原始数据按照指定比例切成训练集(train)和验证集(test),如下:
from sklearn.model_selection import train_test_split
X_train,X_test, y_train, y_test= train_test_split(X, y, test_size = 0.3) #数据集切分
| X_train | 划分的训练集数据 |
| X_test | 划分的验证集数据 |
| y_train | 划分的训练集标签 |
| y_test | 划分的验证集标签 |
train_test_split()函数的参数: train_data:还未划分的数据集
train_target:还未划分的标签
test_size:分割比例,默认为0.25,即测试集占完整数据集的比例
random_state:随机数种子,应用于分割前对数据的洗牌;可以是int,RandomState实例或None,默认值=None,设成定值意味着,对于同一个数据集,只有第一次运行是随机的,随后多次分割只要rondom_state相同,则划分结果也相同。
shuffle:是否在分割前对完整数据进行洗牌(打乱),默认为True,打乱
划分后的训练集:
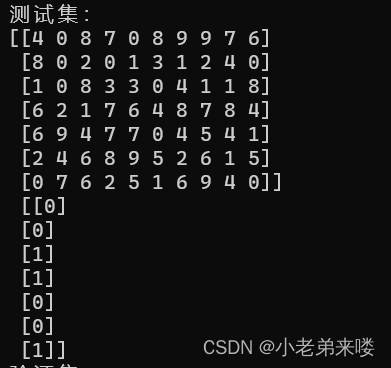
划分后的验证集:

1.2 交叉验证
S折交叉验证(S-fold Cross Validation),一种更为可靠的数据集处理方式,用来对多种模型选择(超参数选择)进行验证
基本操作:首先将原始训练集随机划分为 S 个相互无交集的数据子集,然后每次使用 S-1 个子集数据作为训练集,剩下的那 1 个子集作为验证集,将模型的训练和验证过程重复 S 次,最终选择在 S 次测评中平均测试误差最小的模型
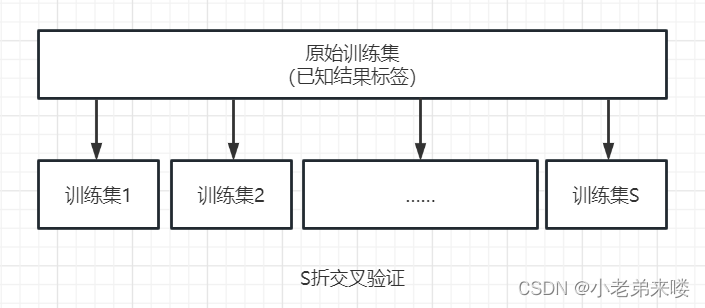
使用model_selection类中的cross_val_score()函数来完成S折交叉验证
Python实现:
from sklearn import datasets #自带数据集
from sklearn.model_selection import train_test_split #划分数据
from sklearn.model_selection import cross_val_score #交叉验证
from sklearn.neighbors import KNeighborsClassifier #一个简单的模型,只有K一个参数,类似K-means
import matplotlib.pyplot as plt
iris = datasets.load_iris() #加载sklearn自带的数据集
X = iris.data #这是数据
y = iris.target #这是每个数据所对应的标签
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=1/3,random_state=3) #这里划分数据以1/3的来划分训练集训练结果 验证集测试结果
k_range = range(1,31)
cv_scores = [] #用来放每个模型的结果值
for n in k_range:
knn = KNeighborsClassifier(n) #knn模型,这里一个超参数可以做预测,当多个超参数时需要使用另一种方法GridSearchCV
scores = cross_val_score(knn,X_train,y_train,cv=10,scoring='accuracy') #cv:选择每次测试折数 accuracy:评价指标是准确度,可以省略使用默认值,具体使用参考下面。
cv_scores.append(scores.mean())
plt.plot(k_range,cv_scores)
plt.xlabel('K')
plt.ylabel('Accuracy') #通过图像选择最好的参数
plt.show()
best_knn = KNeighborsClassifier(n_neighbors=3) # 选择最优的K=3传入模型
best_knn.fit(X_train,y_train) #训练模型
print(best_knn.score(X_test,y_test)) #看看评分输出:


Iris数据集,又称鸢尾花数据集,是在模式识别研究领域中最知名的数据集,将其按 2:1 的比率划分为训练集和验证集
交叉验证所使用的模型是KNeighborsClassifier(),K临近分类模型
cross_val_score()函数参数:
knn:指定的模型
X_train:训练集样本特征
y_train:训练集样本标签
cv:指定S折交叉验证中的S值,默认为5
scoring:指定模型采用的评估标准,默认为None
根据折线图可以看出,在 K=3、K=4、K=6 的时候,模型得分最高,于是我们选取超参数K=3,再次训练模型,并将验证集带入验证得模型得分0.94,预测还是较为准确的
经过交叉验证,我们选择出了超参数为3的K临近分类模型


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









