







贝叶斯估计与有监督学习
如何用贝叶斯估计解决有监督学习问题?
对于有监督学习,我们的目标实际上是估计一个目标函数f : X->Y,,或目标分布P(Y|X),其中X是样本的各个feature组成的多维变量,Y是样本的实际分类结果。假设样本X的取值为xk,那么,根据贝叶斯定理,分类结果为yi的概率应该为:
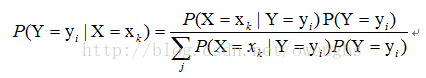
因此,要估计P(Y=yi|X=xk),只要根据样本,求出P(X=xk|Y=yi)的所有估计,以及P(Y=yi)的所有估计,就可以了。此后的分类过程,就是求另P(Y=yi|X=xk)最大的那个yi就可以了。那么由此可见,利用贝叶斯估计,可以解决有监督学习的问题。
分类器的“朴素”特性
何为“朴素”?
从第3节的分析里,我们知道,要求得P(Y=yi|X=xk),就需要知道P(X=xk|Y=yi)的所有估计,以及P(Y=yi)的所有估计,那么假设X为N维变量,其每一维变量都有两种取值(如文本分类中常见的各个term出现与否对应的取值0/1),而Y也有两种类别,那么就需要求出2*(2^N - 1)个估计(注意,由于在给定Y为某一类别的情况下,X的各个取值的概率和为1,所以实际需要估计的值为2^N - 1)。可以想象,对于N很大的情况(文本分类时,term的可能取值是非常大的),这一估计的计算量是巨大的。那么如何减少需要估计的量,而使得贝叶斯估计方法具有可行性呢?这里,就引入一种假设:
假设:在给定Y=yi的条件下,X的各维变量彼此相互独立。
那么,在这一假设的条件下,P(X=xk|Y=yi)=P(X1=x1j1|Y=yi)P(X2=x2j2|Y=yi)…P(Xn=xnjn|Y=yi),也就是说,此时只需要求出N个估计就可以了。因此,这一假设将贝叶斯估计的计算量从2*(2^N - 1)降为了N,使这一分类器具有了实际可行性。那么这一假设就成为朴素特性。
贝叶斯分类器特点:
1.需要知道先验概率先验概率是计算后验概率的基础。在传统的概率理论中,先验概率可以由大量的重复实验所获得的各类样本出现的频率来近似获得,其基础是“大数定律”,这一思想称为“频率主义”。而在称为“贝叶斯主义”的数理统计学派中,他们认为时间是单向的,许多事件的发生不具有可重复性,因此先验概率只能根据对置信度的主观判定来给出,也可以说由“信仰”来确定。
2、按照获得的信息对先验概率进行修正
在没有获得任何信息的时候,如果要进行分类判别,只能依据各类存在的先验概率,将样本划分到先验概率大的一类中。而在获得了更多关于样本特征的信息后,可以依照贝叶斯公式对先验概率进行修正,得到后验概率,提高分类决策的准确性和置信度。
3、分类决策存在错误率
由于贝叶斯分类是在样本取得某特征值时对它属于各类的概率进行推测,并无法获得样本真实的类别归属情况,所以分类决策一定存在错误率,即使错误率很低,分类错误的情况也可能发生。
参数的估计
只要知道先验概率和独立概率分布,就可以设计出一个贝叶斯分
类器。先验概率不是一个分布函数,仅仅是一个值,它表达了样本空间中各个类的样本所占数量的比例。依据大数定理,当训练集中样本数量足够多且来自于样本空间的随机选取时,可以以训练集中各类样本所占的比例来估计。
极大似然估计和最大后验概率
极大似然估计法应用于朴素贝叶斯分类器的求解过程。
上面说了,P(X=xk|Y=yi)的求解,可以转化为对P(X1=x1j1|Y=yi)、P(X2=x2j2|Y=yi)、… P(Xn=xnjn|Y=yi)的求解,那么如何利用极大似然估计法求这些值呢?
首选我们需要理解什么是极大似然估计,实际上,在我们的概率论课本里,关于极大似然估计的讲解,都是在解决无监督学习问题,而看完本节内容后,你应该明白,在朴素特性下,用极大似然估计解决有监督学习问题,实际上就是在各个类别的条件下,用极大似然估计解决无监督学习问题。
朴素贝叶斯分类的目标是寻找“最佳”的类别
§最佳类别是指具有最大后验概率(maximum a posteriori -MAP)的类别 cmap:

极大似然假设与贝叶斯估计的区别:
最大似然估计只考虑某个模型能产生某个给定观察序列的概率。而未考虑该模型本身的概率。这点与贝叶斯估计区别。
Map与ML的区别:
最大后验估计是根据经验数据获得对难以观察的量的点估计。与最大似然估计类似,但是最大的不同时,最大后验估计的融入了要估计量的先验分布在其中。故最大后验估计可以看做规则化的最大似然估计。
极大后验MAP什么时候等于极大似然ML
不知道关于假设的任何概率,所有的hi假设拥有相同的概率,then MAP is Maximum Likelihood (hML极大似然假设),如果数据量足够大,最大后验概率和最大似然估计趋向于一致。
Map和朴素贝叶斯有什么关系
If independent attribute condition is satisfied, then vMAP = vNB 如果独立的属性条件是满足的vmap=vNB
、请描述极大似然估计 MLE 和最大后验估计 MAP 之间的区别。请解释为什么 MLE 比 MAP更容易过拟合。
MLE:取似然函数最大时的参数值为该参数的估计值,ymle=argmax[p(x|y)];MAP:取后验函数(似然与先验之积)最大时的参数值为该参数的估计值,ymap=argmax[p(x|y)p(y)]。因为MLE 只考虑训练数据拟合程度没有考虑先验知识,把错误点也加入模型中,导致过拟合。
















 4978
4978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











