



 文章介绍了数据库迁移过程中表结构转换的重要性,分析了从元数据采集、映射到DDL生成的三个关键步骤,并提出了核心设计,包括查询器、映射器和生成器的模块化设计,以及扩展性设计以适应不同场景和个性化需求。该工具支持多种数据库间的转换,包括Oracle、MySQL、Postgres等,并处理了数据类型、字段映射、分区等复杂问题。
文章介绍了数据库迁移过程中表结构转换的重要性,分析了从元数据采集、映射到DDL生成的三个关键步骤,并提出了核心设计,包括查询器、映射器和生成器的模块化设计,以及扩展性设计以适应不同场景和个性化需求。该工具支持多种数据库间的转换,包括Oracle、MySQL、Postgres等,并处理了数据类型、字段映射、分区等复杂问题。
目录
-
前言
表结构转换一般是数据迁移的第一步,它一般需要先评估两个数据库之间的差异,然后再根据这些差异修改表定义,或根据目标库的一些特点优化部分表结构,最后在目标库上创建所需要的对象。
经过充分分析差异、定义良好的目标表结构是后续数据迁移的基础,因此这一步骤的重要性不言而喻。
然而目前各数据库厂商以自身为出发点,虽然提供了自身不同版本之间的迁移工具,却很少有提供异构数据库之间元数据迁移功能。
开源或免费的相关数据库迁移工具方面,大多数也是囿于其中的某一方面且不够完善。比如sqlines专注于Oracle到MySQL的表结构转换但却不支持分区和注释等信息及个性化;再比如sqluldr2支持Oracle到MySQL的全量数据迁移,但却已长久未更新且不支持字段映射等功能。
为了解决这一难题,我们的迁移工具补全了数据迁移过程中的这一片重要拼图,基于良好的设计,可以实现轻松、灵活、高效地异构数据库之间表结构转换,后文我们将详细展开分析介绍。
-
场景分析
将从一个数据库到另一个数据库的结构转换过程进行抽象和简化,会不难发现它们都涉及三个方面的内容,即:
- 源数据库元数据采集
- 源数据库到目标数据库元数据映射
- 目标数据库DDL生成
下面我们将从这三个方面来分别分析。
- 元数据采集
一般来说,所需要采集的元数据主要为表和字段信息,表的信息主要包括:表名称、所属用户、所属SCHEMA、所在表空间、主键、外键、索引、索引表空间、其它约束、是否分区表、分区表信息、注释、字符集等,部分数据库比如MySQL还有存储引擎等其它信息。字段的信息主要包括:字段名称、数据类型、长度(精度)、是否可为空、缺省值、索引、注释等。
当然对于索引、主键、外键等对象,还需要进一步地采集更多的元数据信息,如索引列顺序、类型等等。
在采集阶段的关注点是如何全面、准确地采集到所需的元数据,因为不同的数据库,元数据的组织形式、存储方式等各有不同,这就需要对数据库有充分的了解。
- 元数据映射
获取到了源数据库的元数据,就相当于手中已经有了原始建筑材料,映射阶段的主要任务就是要将这些材料进行裁剪和加工,以方便在目标库中使用。
对数据库稍行了解就可得知,不同数据库的数据类型、索引类型、分区类型、约束类型等可能各不相同,这些不同点自然就是本阶段的关注重点,简要列述如下:
- 字段(列)映射,重点关注数据类型、长度(精度)、缺省值等
- 分区映射
- 主键、外键、索引及其他约束映射
以上三点中,最为复杂和需要精细处理的是字段映射,后文中我们会再做进一步分析。
- DDL生成
映射完成之后,就相当于已经有了构建目标数据库DDL的所有信息,只需按照目标数据库语法要求生成DDL即可,此时最重要的问题可能就是对目标数据库DDL语法的熟悉了。另外就是元数据的取舍,例如Oracle支持的二级分区在MySQL中不支持该如何处理?(对于这个问题我们平台采用了舍弃子分区只保留主分区的方式)。
-
核心设计
根据上文我们抽象出的模型,可以很容易将系统架构设计为元数据查询、元数据映射和DDL生成三大模块,而在实际应用时,考虑到易用性和扩展性等因素,我们将系统大体设计为如下模式:
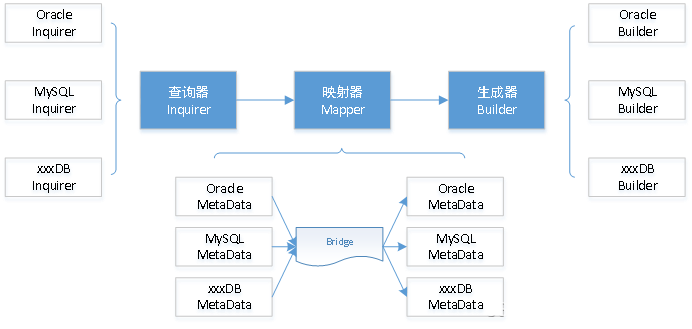
图中蓝色部分是核心接口,其它部分则是具体实现,xxxDB代表其它支持的数据库,下面分别进行说明。
- 查询器设计
由于不同数据库其元数据的组织形式不同,所以对于不同族的数据库必然有不同的查询器。因此在设计上仅规划了统一查询器接口,然后针对每个数据库实现其自身的元数据查询器。
此处只需要参考各数据库的官方文档,如实、准确地完成所有元数据采集即可。
- 映射器设计
映射器涉及的方面较多,为本功能中最为复杂的部分,受限于篇幅本文不一一介绍,后文我们将以表结构转换中最重要的部分(字段映射)为例进行分析。
假设有N个数据库,如果要实现互转,且采用一对一的方式进行“傻转”,那么我们就需要实现N*(N-1)个映射器。这对于我们平台立致力于实现多数据库之间互转来说是不可接受的。因为若如此设计,工作量将会随着数据库支持种类的增多而急剧增加,而且也会使得系统毫无扩展性和可维护性可言。
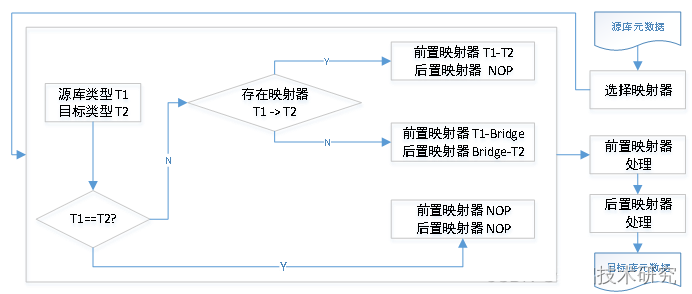
因此我们在设计时采用了先转换为中间元数据(后文称为Bridge),再由Bridge转为目标库的方式。这样一来,每增加一个数据库,只需要实现该库自身的查询器、生成器及该库到Bridge和Bridge到该库的映射器即可(如上图)。其中该库到Bridge映射器用于将该库转换到其它数据库,反之则使用Bridge到该库的映射器。
那么Bridge该如何设计呢?
实际上JDBC中已经做了类似工作,即它将数据类型归纳为了自己的一个集合,不过这个集合在迁移场景下适用性有所欠缺,因此我们在Bridge中将数据类型归纳为CHAR、VARCHAR、INTEGER、LONG、DECIMAL、CLOB等16大类,实现了Oracle、MySQL族、DB2、Postgres族等数据库之间核心数据类型的兼容。
在实际应用中,为了提高转换精度,我们又针对此模型进行了进一步优化,既支持数据库之间的直接映射器,如果存在则优先使用。如下图所示,其中NOP映射器为空操作,其输出永远等同于输入:
下面我们将关注点转移到映射器本身,映射器需要解决非常多的问题,下面仅给出一个我们主要内容的高阶设计:
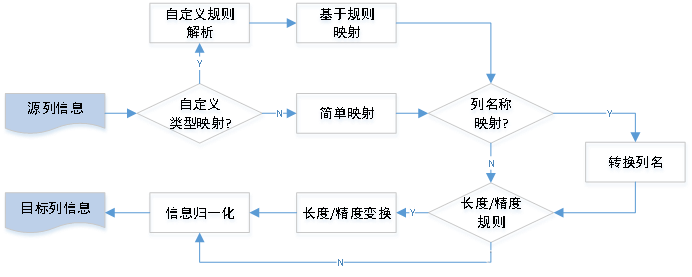
从上图中可以看到,我们的工具很好地处理了两个数据库之间数据类型的不同、精度或长度变化,表字段名称转换等诸多复杂的转换需求。
- 生成器设计
最后是生成器,即生成目标库上可执行的DDL语句,这一部分也依赖于具体的数据库,因此同样仅规划了统一生成器接口,然后针对每个数据库实现其自身的DDL生成器。
此处同样需要以各数据库的官方文档为依据,来生成相应的DDL语句。
-
扩展设计
针对每一次的数据库迁移,其表结构转换的需求都不尽相同,例如某些情况下需要迁移表分区,某些情况下不需要迁移表约束等等。这些因素必须在设计之初就进行考虑,要在满足大多数常见需求的同时,提供对特色化定制的支持。
因此我们从三个维度上进行了扩展性设计:
- 抽取可变因素为控制变量,常见需求以缺省值形式固化入内核;
- 可针对不同数据库或不同批次转换定制缺省参数文件,平台自动识别加载;
- 支持在命令行直接指定所有控制参数,覆盖缺省设置。
具体如下图所示:
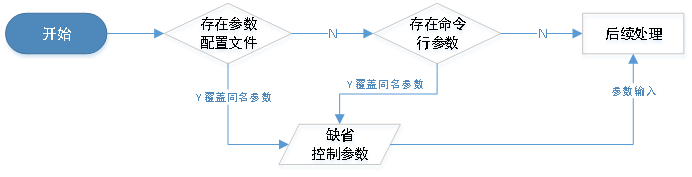
基于如上设计,一次表结构转换所必须输入的信息可缩小到仅为两端数据库的连接信息及待转换表范围。
同时针对一些复杂或“额外”需求,我们还设计了一套简单的脚本语言,以支持个性化需求。例如要在转换后MySQL数据库中将所有的表名类似于 MYTAB%TEST且存在ID字段的表自动附加基于ID的哈希分区,可以简单的指定如下自定义分区规则,如有兴趣的读者可私下沟通,本文中不多做赘述:
|
TAB(MYTAB%TEST)&&COL(ID) PARTITION BY HASH(ID) PARTITIONS 3 |
-
适用范围
最后,简单介绍一下我们基于上述架构设计完成的迁移平台在表结构转换方面所支持的主要功能。
目前平台支持自动转换的主要元数据包括:
- SCHEMA映射
- 表基本信息,如表名映射、表空间、注释等
- 字段基本属性,如是字段名映射、否可为空、缺省值、注释等
- 字段数据类型映射(基于自定义规则)
- 字段数据长度、精度转换(基于自定义规则)
- 主键
- 外键
- 索引
- 分区表
- 自定义分区规则自动生成
目前支持的可以互相转换的数据库范围为:
- Oracle
- MySQL
- Postgres
- DB2(仅作为源)
- GoldiLocks
- GaussDB(openGauss/DWS)
- 兼容MySQL的其它数据库
- 兼容Postgres的其它数据库
-
小结
然而“细节是魔鬼”,在我们基于上述设计实现迁移平台的过程中,还考虑和解决了非常多的问题,正是这些问题的解决,才使得平台更加稳定和可靠,限于篇幅此处不再详细展开,如果读者感兴趣,欢迎与我们联系。
本系列的后续文章将会继续对全量迁移、增量同步等功能进行进一步探索,敬请继续关注。

















 2349
2349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









